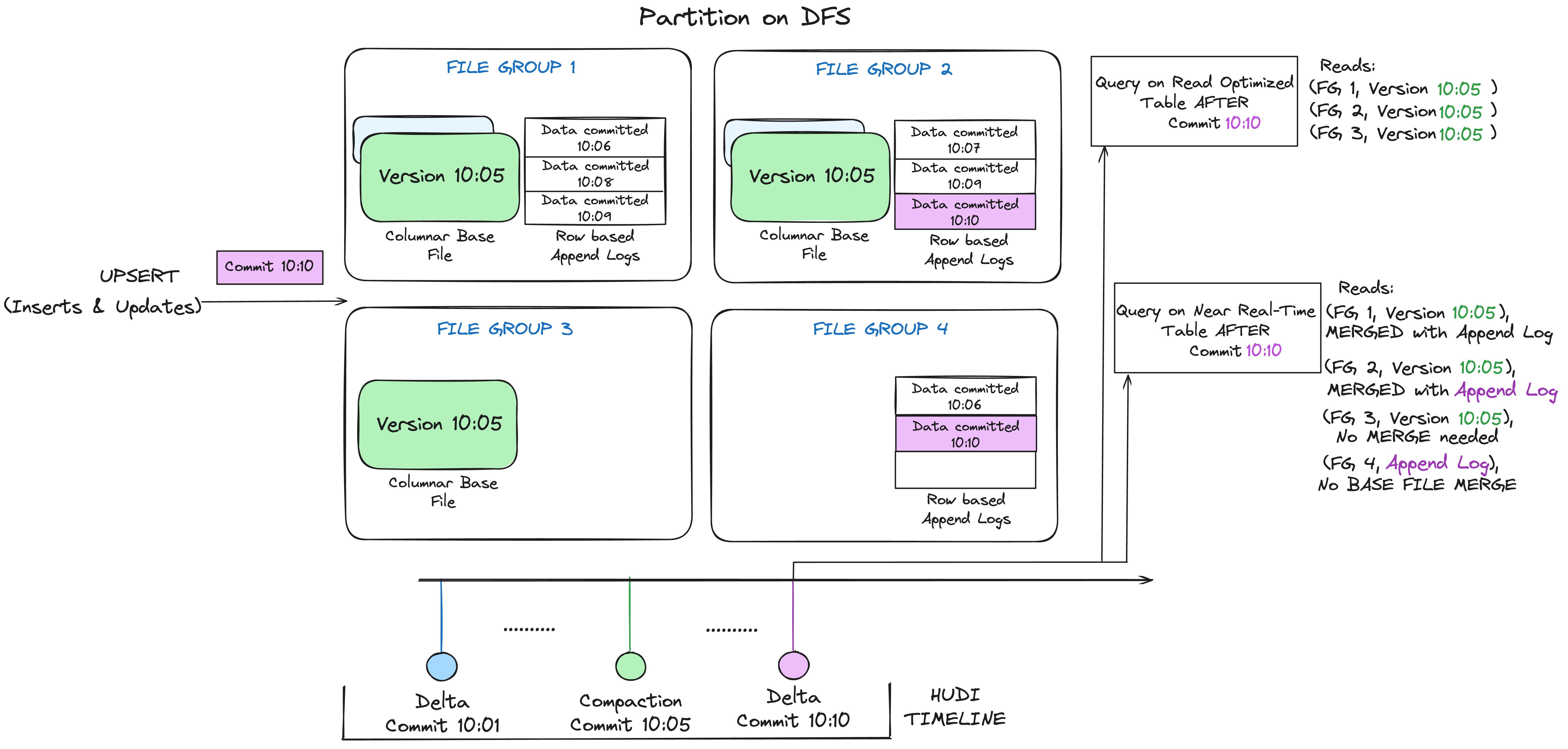
File Layouts
The following describes the general file layout structure for Apache Hudi. Please refer the tech spec for a more detailed description of the file layouts.
- Hudi organizes data tables into a directory structure under a base path on a distributed file system
- Tables are broken up into partitions
- Within each partition, files are organized into file groups, uniquely identified by a file ID
- Each file group contains several file slices
- Each slice contains a base file (.parquet/.orc) (defined by the config - hoodie.table.base.file.format ) produced at a certain commit/compaction instant time, along with set of log files (.log.) that contain inserts/updates to the base file since the base file was produced.
Hudi adopts Multiversion Concurrency Control (MVCC), where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on the file system.
Configs
Please refer here for additional configs that control storage layout and data distribution, which defines how the files are organized within a table.