Change Capture Using AWS Database Migration Service and Hudi

One of the core use-cases for Apache Hudi is enabling seamless, efficient database ingestion to your data lake. Even though a lot has been talked about and even users already adopting this model, content on how to go about this is sparse.
In this blog, we will build an end-end solution for capturing changes from a MySQL instance running on AWS RDS to a Hudi table on S3, using capabilities in the Hudi 0.5.1 release
We can break up the problem into two pieces.
- Extracting change logs from MySQL : Surprisingly, this is still a pretty tricky problem to solve and often Hudi users get stuck here. Thankfully, at-least for AWS users, there is a Database Migration service (DMS for short), that does this change capture and uploads them as parquet files on S3
- Applying these change logs to your data lake table : Once there are change logs in some form, the next step is to apply them incrementally to your table. This mundane task can be fully automated using the Hudi DeltaStreamer tool.
The actual end-end architecture looks something like this.

Let's now illustrate how one can accomplish this using a simple orders table, stored in MySQL (these instructions should broadly apply to other database engines like Postgres, or Aurora as well, though SQL/Syntax may change)
CREATE DATABASE hudi_dms;
USE hudi_dms;
CREATE TABLE orders(
order_id INTEGER,
order_qty INTEGER,
customer_name VARCHAR(100),
updated_at TIMESTAMP DEFAULT NOW() ON UPDATE NOW(),
created_at TIMESTAMP DEFAULT NOW(),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
);
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(1, 10, 'victor');
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(2, 20, 'peter');
In the table, order_id is the primary key which will be enforced on the Hudi table as well. Since a batch of change records can contain changes to the same primary key, we also include updated_at and created_at fields, which are kept upto date as writes happen to the table.
Extracting Change logs from MySQL
Before we can configure DMS, we first need to prepare the MySQL instance for change capture, by ensuring backups are enabled and binlog is turned on.

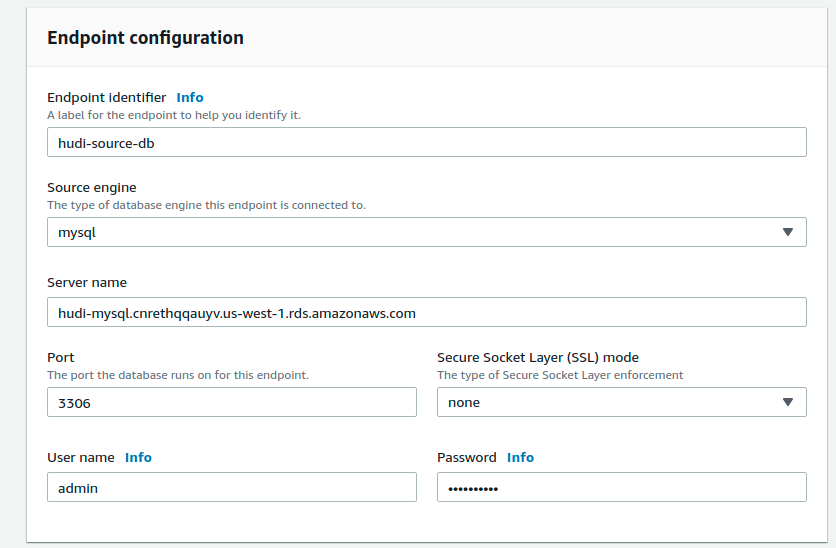
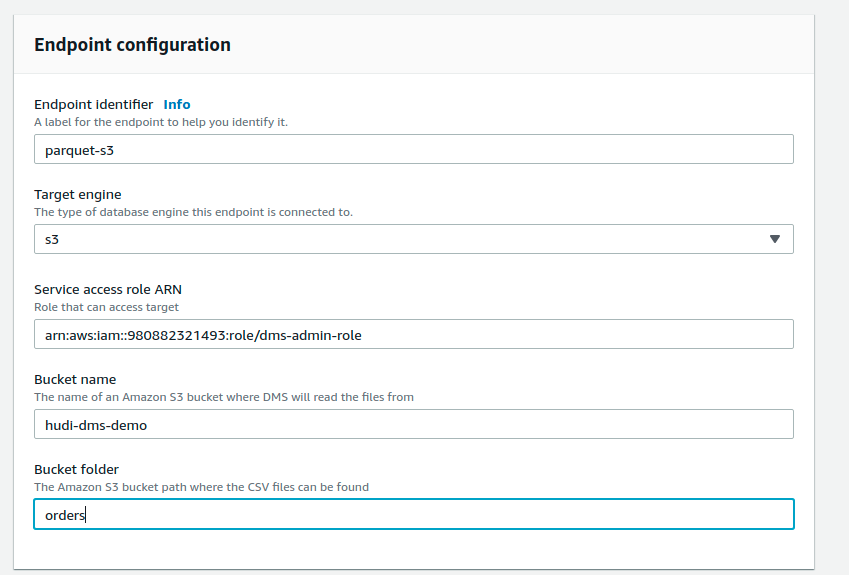
Now, proceed to create endpoints in DMS that capture MySQL data and store in S3, as parquet files.
- Source hudi-source-db endpoint, points to the DB server and provides basic authentication details
- Target parquet-s3 endpoint, points to the bucket and folder on s3 to store the change logs records as parquet files
Then proceed to create a migration task, as below. Give it a name, connect the source to the target and be sure to pick the right Migration type as shown below, to ensure ongoing changes are continuously replicated to S3. Also make sure to specify, the rules using which DMS decides which MySQL schema/tables to replicate. In this example, we simply whitelist orders table under the hudi_dms schema, as specified in the table SQL above.
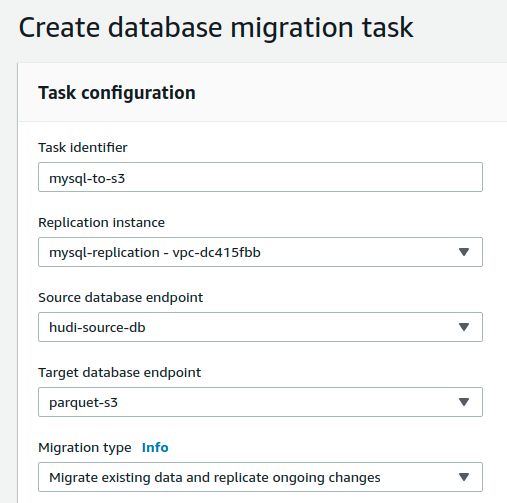
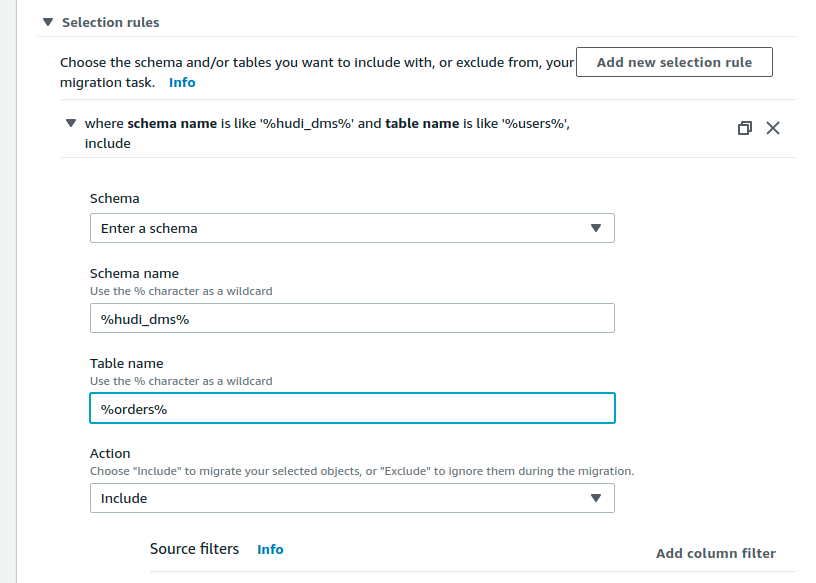
Starting the DMS task and should result in an initial load, like below.
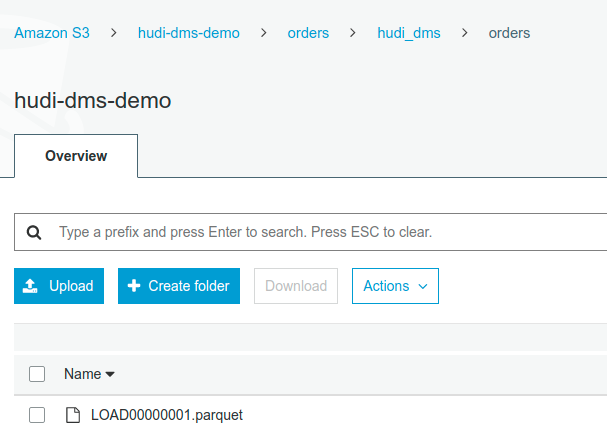
Simply reading the raw initial load file, shoud give the same values as the upstream table
scala> spark.read.parquet("s3://hudi-dms-demo/orders/hudi_dms/orders/*").sort("updated_at").show
+--------+---------+-------------+-------------------+-------------------+
|order_id|order_qty|customer_name| updated_at| created_at|
+--------+---------+-------------+-------------------+-------------------+
| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22|
| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
+--------+---------+-------------+-------------------+-------------------+
Applying Change Logs using Hudi DeltaStreamer
Now, we are ready to start consuming the change logs. Hudi DeltaStreamer runs as Spark job on your favorite workflow scheduler (it also supports a continuous mode using --continuous flag, where it runs as a long running Spark job), that tails a given path on S3 (or any DFS implementation) for new files and can issue an upsert to a target hudi dataset. The tool automatically checkpoints itself and thus to repeatedly ingest, all one needs to do is to keep executing the DeltaStreamer periodically.
With an initial load already on S3, we then run the following command (deltastreamer command, here on) to ingest the full load first and create a Hudi dataset on S3.
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.spark:spark-avro_2.11:2.4.4 \
--master yarn --deploy-mode client \
hudi-utilities-bundle_2.11-0.5.1-SNAPSHOT.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field updated_at \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3://hudi-dms-demo/hudi_orders --target-table hudi_orders \
--transformer-class org.apache.hudi.utilities.transform.AWSDmsTransformer \
--payload-class org.apache.hudi.payload.AWSDmsAvroPayload \
--hoodie-conf hoodie.datasource.write.recordkey.field=order_id,hoodie.datasource.write.partitionpath.field=customer_name,hoodie.deltastreamer.source.dfs.root=s3://hudi-dms-demo/orders/hudi_dms/orders
A few things are going on here
- First, we specify the --table-type as COPY_ON_WRITE. Hudi also supports another _MERGE_ON_READ ty_pe you can use if you choose from.
- To handle cases where the input parquet files contain multiple updates/deletes or insert/updates to the same record, we use updated_at as the ordering field. This ensures that the change record which has the latest timestamp will be reflected in Hudi.
- We specify a target base path and a table table, all needed for creating and writing to the Hudi table
- We use a special payload class - AWSDMSAvroPayload , to handle the different change operations correctly. The parquet files generated have an Op field, that indicates whether a given change record is an insert (I), delete (D) or update (U) and the payload implementation uses this field to decide how to handle a given change record.
- You may also notice a special transformer class AWSDmsTransformer , being specified. The reason here is tactical, but important. The initial load file does not contain an Op field, so this adds one to Hudi table schema additionally.
- Finally, we specify the record key for the Hudi table as same as the upstream table. Then we specify partitioning by customer_name and also the root of the DMS output.
Once the command is run, the Hudi table should be created and have same records as the upstream table (with all the _hoodie fields as well).
scala> spark.read.format("org.apache.hudi").load("s3://hudi-dms-demo/hudi_orders/*/*.parquet").show
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|order_id|order_qty|customer_name| updated_at| created_at| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
| 20200120205028| 20200120205028_0_1| 2| peter|af9a2525-a486-40e...| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22| |
| 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31| |
+-------------------+--------------------+------------------+----------------------+--------------------+--------+---------+-------------+-------------------+-------------------+---+
Now, let's do an insert and an update
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(3, 30, 'sandy');
UPDATE orders set order_qty = 20 where order_id = 2;
This will add a new parquet file to the DMS output folder and when the deltastreamer command is run again, it will go ahead and apply these to the Hudi table.
So, querying the Hudi table now would yield 3 rows and the hoodie_commit_time accurately reflects when these writes happened. You can notice that order_qty for order_id=2, is updated from 10 to 20!
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| Op|order_id|order_qty|customer_name| updated_at| created_at|
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
| 20200120211526| 20200120211526_0_1| 2| peter|af9a2525-a486-40e...| U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22|
| 20200120211526| 20200120211526_1_1| 3| sandy|566eb34a-e2c5-44b...| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24|
| 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| | 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
A nice debugging aid would be read all of the DMS output now and sort it by update_at, which should give us a sequence of changes that happened on the upstream table. As we can see, the Hudi table above is a compacted snapshot of this raw change log.
+----+--------+---------+-------------+-------------------+-------------------+
| Op|order_id|order_qty|customer_name| updated_at| created_at|
+----+--------+---------+-------------+-------------------+-------------------+
|null| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22|
|null| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24|
| U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22|
+----+--------+---------+-------------+-------------------+-------------------+
Initial load with no Op field value , followed by an insert and an update.
Now, lets do deletes an inserts
DELETE FROM orders WHERE order_id = 2;
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(4, 40, 'barry');
INSERT INTO orders(order_id, order_qty, customer_name) VALUES(5, 50, 'nathan');
This should result in more files on S3, written by DMS , which the DeltaStreamer command will continue to process incrementally (i.e only the newly written files are read each time)
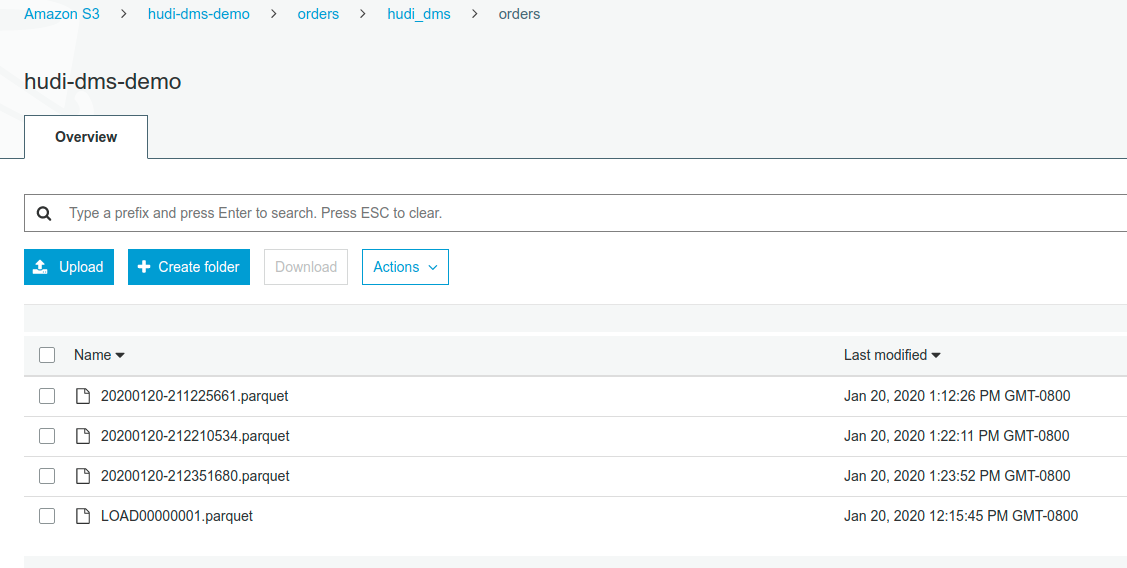
Running the deltastreamer command again, would result in the follow state for the Hudi table. You can notice the two new records and that the order_id=2 is now gone
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| Op|order_id|order_qty|customer_name| updated_at| created_at|
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
| 20200120212522| 20200120212522_1_1| 5| nathan|3da94b20-c70b-457...| I| 5| 50| nathan|2020-01-20 21:23:00|2020-01-20 21:23:00|
| 20200120212522| 20200120212522_2_1| 4| barry|8cc46715-8f0f-48a...| I| 4| 40| barry|2020-01-20 21:22:49|2020-01-20 21:22:49|
| 20200120211526| 20200120211526_1_1| 3| sandy|566eb34a-e2c5-44b...| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24|
| 20200120205028| 20200120205028_1_1| 1| victor|8e431ece-d51c-4c7...| | 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
+-------------------+--------------------+------------------+----------------------+--------------------+---+--------+---------+-------------+-------------------+-------------------+
Our little informal change log query yields the following.
+----+--------+---------+-------------+-------------------+-------------------+
| Op|order_id|order_qty|customer_name| updated_at| created_at|
+----+--------+---------+-------------+-------------------+-------------------+
|null| 2| 10| peter|2020-01-20 20:12:22|2020-01-20 20:12:22|
|null| 1| 10| victor|2020-01-20 20:12:31|2020-01-20 20:12:31|
| I| 3| 30| sandy|2020-01-20 21:11:24|2020-01-20 21:11:24|
| U| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22|
| D| 2| 20| peter|2020-01-20 21:11:47|2020-01-20 20:12:22|
| I| 4| 40| barry|2020-01-20 21:22:49|2020-01-20 21:22:49|
| I| 5| 50| nathan|2020-01-20 21:23:00|2020-01-20 21:23:00|
+----+--------+---------+-------------+-------------------+-------------------+
Note that the delete and update have the same updated_at, value. thus it can very well order differently here.. In short this way of looking at the changelog has its caveats. For a true changelog of the Hudi table itself, you can issue an incremental query.
And Life goes on ..... Hope this was useful to all the data engineers out there!