Reliable ingestion from AWS S3 using Hudi

In this post we will talk about a new deltastreamer source which reliably and efficiently processes new data files as they arrive in AWS S3. As of today, to ingest data from S3 into Hudi, users leverage DFS source whose path selector would identify the source files modified since the last checkpoint based on max modification time. The problem with this approach is that modification time precision is upto seconds in S3. It maybe possible that there were many files (beyond what the configurable source limit allows) modifed in that second and some files might be skipped. For more details, please refer to HUDI-1723. While the workaround is to ignore the source limit and keep reading, the problem motivated us to redesign so that users can reliably ingest from S3.
Design
For use-cases where seconds granularity does not suffice, we have a new source in deltastreamer using log-based approach. The new S3 events source relies on change notification and incremental processing to ingest from S3. The architecture is as shown in the figure below.
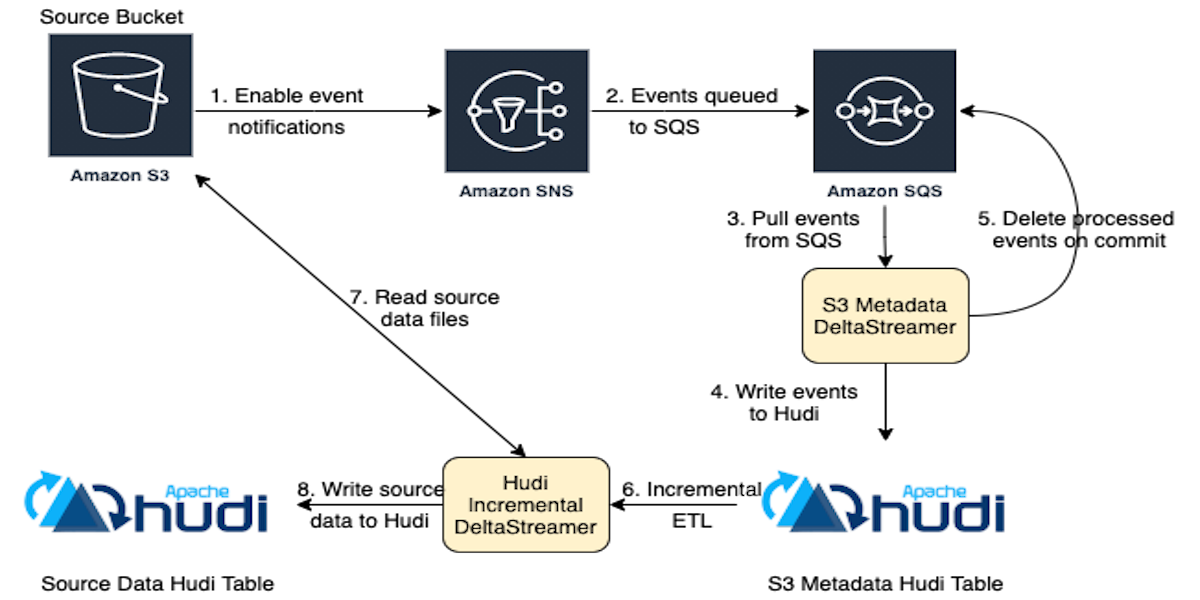
In this approach, users need to enable S3 event notifications. There will be two types of deltastreamers as detailed below.
- S3EventsSource: Create Hudi S3 metadata table.
This source leverages AWS SNS and SQS services that subscribe to file events from the source bucket.
- Events from SQS will be written to this table, which serves as a changelog for the subsequent incremental puller.
- When the events are committed to the S3 metadata table they will be deleted from SQS.
- S3EventsHoodieIncrSource and uses the metadata table written by S3EventsSource.
- Read the S3 metadata table and get the objects that were added or modified. These objects contain the S3 path for the source files that were added or modified.
- Write to Hudi table with source data corresponding to the source files in the S3 bucket.
Advantages
- Decoupling: Every step in the pipeline is decoupled. The two sources can be started independent of each other. We imagine most users run a single deltastreamer to get all changes for a given bucket and can fan-out multiple tables off that.
- Performance and Scale: The previous approach used to list all files, sort by modification time and then filter based on checkpoint. While it did prune partition paths, the directory listing could still become a bottleneck. By relying on change notification and native cloud APIs, the new approach avoids directory listing and scales with the number of files being ingested.
- Reliability: Since there is no longer any dependency on the max modification time and the fact that S3 events are being recorded in the metadata table, users can rest assured that all the events will be processed eventually.
- Fault Tolerance: There are two levels of fault toerance in this design. Firstly, if some of the messages are not committed to the S3 metadata table, then those messages will remain in the queue so that they can be reprocessed in the next round. Secondly, if the incremental puller fails, then users can query the S3 metadata table for the last commit point and resume the incremental puller from that point onwards (kinda like how Kafka consumers can reset offset).
- Asynchronous backfills: With the log-based approach, it becomes much easier to trigger backfills. See the "Conclusion and Future Work" section for more details.
Configuration and Setup
Users only need to specify the SQS queue url and region name to start the S3EventsSource (metadata source).
hoodie.deltastreamer.s3.source.queue.url=https://sqs.us-west-2.amazonaws.com/queue/url
hoodie.deltastreamer.s3.source.queue.region=us-west-2
There are a few other configurations for the metadata source which can be tuned to suit specific requirements:
hoodie.deltastreamer.s3.source.queue.long.poll.wait: Value can range in [0, 20] seconds. If set to 0 then metadata source will consume messages from SQS using short polling. It is recommended to use long polling because it will reduce false empty responses and reduce the cost of using SQS. By default, this value is set to 20 seconds.hoodie.deltastreamer.s3.source.queue.visibility.timeout: Value can range in [0, 43200] seconds (i.e. max 12 hours). SQS does not automatically delete the messages once consumed. It is the responsibility of metadata source to delete the message after committing. SQS will move the consumed message to in-flight state during which it becomes invisible for the configured timeout period. By default, this value is set to 30 seconds.hoodie.deltastreamer.s3.source.queue.max.messages.per.batch: Maximum number of messages in a batch of one round of metadata source run. By default, this value is set to 5.
To setup the pipeline, first enable S3 event notifications. Download the aws-java-sdk-sqs jar. Then start the S3EventsSource and S3EventsHoodieIncrSource using the HoodieDeltaStreamer utility as shown in sample commands below.
# To start S3EventsSource
spark-submit \
--jars "/home/hadoop/hudi-utilities-bundle_2.11-0.9.0.jar,/usr/lib/spark/external/lib/spark-avro.jar,/home/hadoop/aws-java-sdk-sqs-1.12.22.jar" \
--master yarn --deploy-mode client \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /home/hadoop/hudi-packages/hudi-utilities-bundle_2.11-0.9.0-SNAPSHOT.jar \
--table-type COPY_ON_WRITE --source-ordering-field eventTime \
--target-base-path s3://bucket_name/path/for/s3_meta_table \
--target-table s3_meta_table --continuous \
--min-sync-interval-seconds 10 \
--hoodie-conf hoodie.datasource.write.recordkey.field="s3.object.key,eventName" \
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator \
--hoodie-conf hoodie.datasource.write.partitionpath.field=s3.bucket.name --enable-hive-sync \
--hoodie-conf hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor \
--hoodie-conf hoodie.datasource.write.hive_style_partitioning=true \
--hoodie-conf hoodie.datasource.hive_sync.database=default \
--hoodie-conf hoodie.datasource.hive_sync.table=s3_meta_table \
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=bucket \
--source-class org.apache.hudi.utilities.sources.S3EventsSource \
--hoodie-conf hoodie.deltastreamer.s3.source.queue.url=https://sqs.us-west-2.amazonaws.com/queue/url
--hoodie-conf hoodie.deltastreamer.s3.source.queue.region=us-west-2
# To start S3EventsHoodieIncrSource use following command along with ordering field, record key(s) and
# partition field(s) from the source s3 data.
spark-submit \
--jars "/home/hadoop/hudi-utilities-bundle_2.11-0.9.0.jar,/usr/lib/spark/external/lib/spark-avro.jar,/home/hadoop/aws-java-sdk-sqs-1.12.22.jar" \
--master yarn --deploy-mode client \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /home/hadoop/hudi-packages/hudi-utilities-bundle_2.11-0.9.0-SNAPSHOT.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field <ordering key from source data> --target-base-path s3://bucket_name/path/for/s3_hudi_table \
--target-table s3_hudi_table --continuous --min-sync-interval-seconds 10 \
--hoodie-conf hoodie.datasource.write.recordkey.field="<record key from source data>" \
--hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.SimpleKeyGenerator \
--hoodie-conf hoodie.datasource.write.partitionpath.field=<partition key from source data> --enable-hive-sync \
--hoodie-conf hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor \
--hoodie-conf hoodie.datasource.write.hive_style_partitioning=true \
--hoodie-conf hoodie.datasource.hive_sync.database=default \
--hoodie-conf hoodie.datasource.hive_sync.table=s3_hudi_v6 \
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=bucket \
--source-class org.apache.hudi.utilities.sources.S3EventsHoodieIncrSource \
--hoodie-conf hoodie.deltastreamer.source.hoodieincr.path=s3://bucket_name/path/for/s3_meta_table \
--hoodie-conf hoodie.deltastreamer.source.hoodieincr.read_latest_on_missing_ckpt=true
Conclusion and Future Work
This post introduced a log-based approach to ingest data from S3 into Hudi tables reliably and efficiently. We are actively improving this along the following directions.
- One stream of work is to add support for other cloud-based object storage like Google Cloud Storage, Azure Blob Storage, etc. with this revamped design.
- Another stream of work is to add resource manager that allows users to setup notifications and delete resources when no longer needed.
- Another interesting piece of work is to support asynchronous backfills. Notification systems are evntually consistent and typically do not guarantee perfect delivery of all files right away. The log-based approach provides enough flexibility to trigger automatic backfills at a configurable interval e.g. once a day or once a week.
Please follow this GitHub issue to learn more about active development on this issue. We look forward to contributions from the community. Hope you enjoyed this post.
Put your Hudi on and keep streaming!