Building an ExaByte-level Data Lake Using Apache Hudi at ByteDance
Ziyue Guan from Bytedance shares the experience of building an ExaByte(EB)-level data lake using Apache Hudi at Bytedance.
This blog is a translated version of the same blog originally in Chinese/中文. Here are the original slides in Chinese/中文 and the translated slides in English.

Next, I will explain how we use Hudi in Bytedance’s recommendation system in five parts: scenario requirements, design decisions, functionality support, performance tuning, and future work.
Scenario Requirements

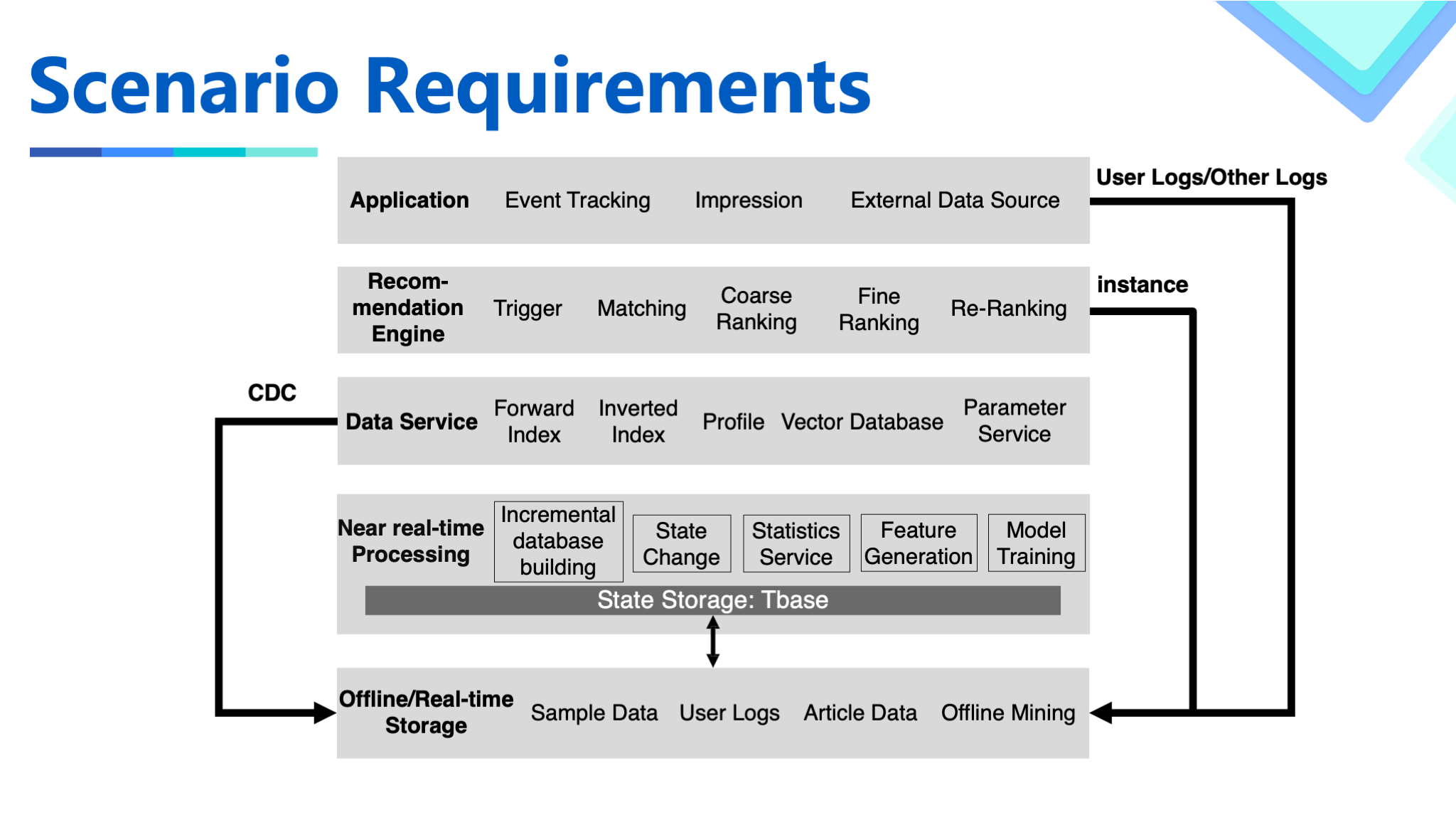

In the recommendation system, we use the data lake in the following two scenarios:
-
We use BigTable as the data storage for the near real-time processing in the entire system. There is an internally developed component TBase, which provides the semantics of BigTable and the abstraction of some requirements in the search advertisement recommendation scenarios, and shields the differences in underlying storage. For a better understanding, it can be directly regarded as an HBase. In this process, in order to serve offline data analysis and mining needs, the data needs to be exported to offline storage. In the past, users either use MR/Spark to directly access the storage, or obtain data by scanning the database, which do not meet the data access characteristics in the OLAP scenario. Therefore, we build BigTable's CDC based on the data lake to improve data timeliness, reduce the access pressure of the near real-time system, and provide efficient OLAP access and user-friendly SQL consumption methods.
-
In addition, we also use data lakes in the scenarios of feature engineering and model training. We obtain two types of real-time data streams from internal and external sources. One is the instances returned from the system, which includes the features obtained when the recommendation system is serving. The other is the feedback from event tracking at vantage points and a variety of complex external data sources. This type of data is used as labels and forms a complete machine learning data sample with the previously mentioned features. For this scenario, we need to implement a merging operation based on the primary key to merge the instance and label together. The time window range may be as long as tens of days, with the volume at the order of hundreds of billions of rows. The system needs to support efficient column selection and predicate pushdown. At the same time, it also needs to support concurrent updates and other related capabilities.
These two scenarios pose the following challenges:
-
The data is very irregular. Compared with Binlog, WAL cannot obtain all the information of a row, and the data size changes significantly.
-
The throughput is relatively large. The throughput of a single table exceeds 100 GB/s, and the single table needs PB-level storage.
-
The data schema is complex. The data is highly dimensional and sparse. The number of table columns ranges from 1000 to 10000+. And there are a lot of complex data types.
Design Decisions

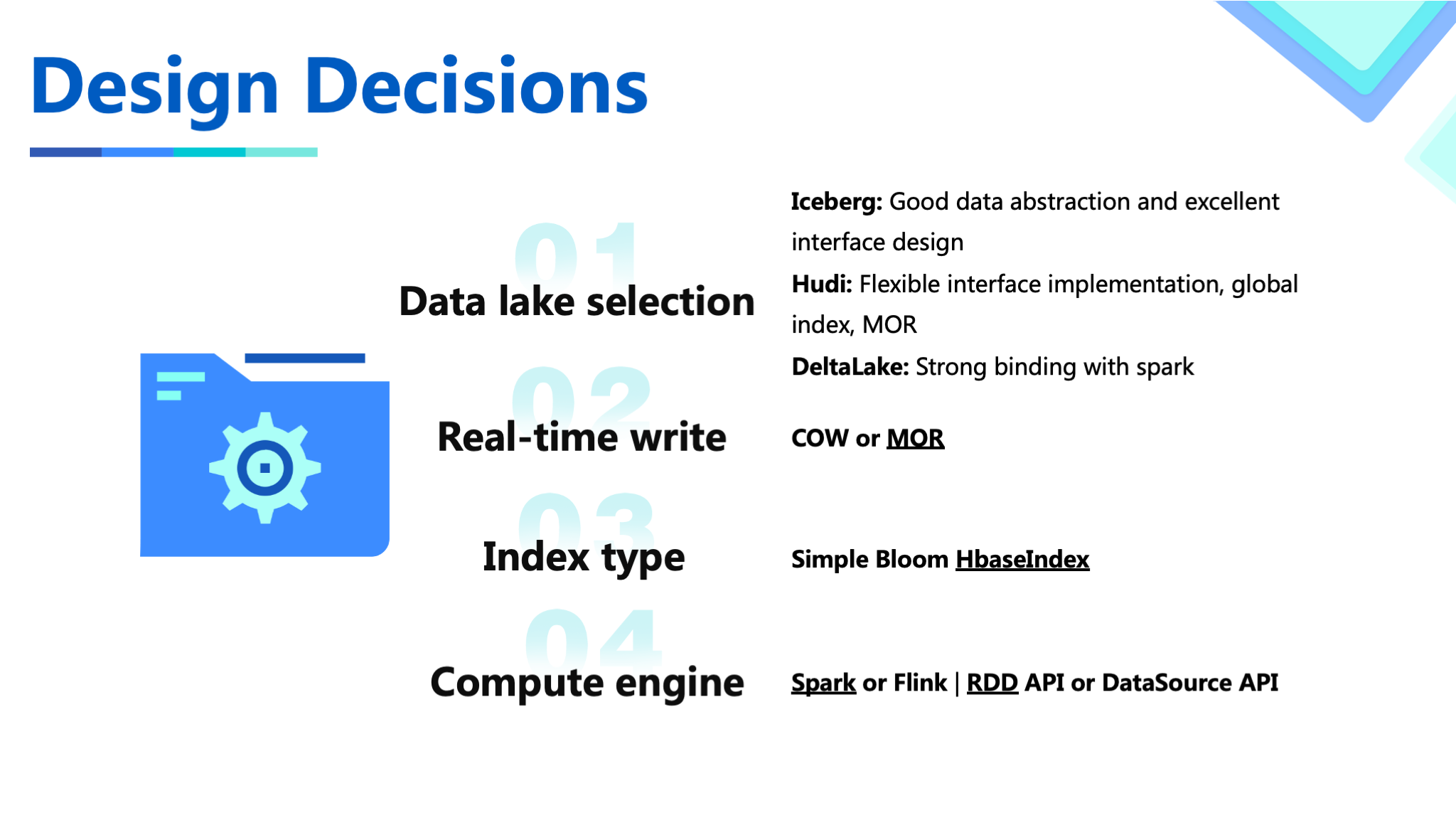
When making the decision on the engine, we examine three of the most popular data lake engines, Hudi, Iceberg, and DeltaLake. These three have their own advantages and disadvantages in our scenarios. Finally, Hudi is selected as the storage engine based on Hudi's openness to the upstream and downstream ecosystems, support for the global index, and customized development interfaces for certain storage logic.
-
For real-time writing, MOR with better timeliness is selected.
-
We examine the index type. First of all, because WAL can't get the partition of the data each time, it must use a global index. Among several global index implementations, in order to achieve high-performance writing, HBase is the only choice. The other two implementations have major performance gaps from HBase.
-
Regarding the computing engine and API, Hudi's support for Flink was not perfect at the time, so we choose Spark which has more mature support. In order to flexibly implement some customized functionality and logic, and because the DataFrame API has more semantic restrictions, we choose the lower-level RDD API.
Functionality Support

Functionality support includes MVCC and Schema registration systems that store semantics.
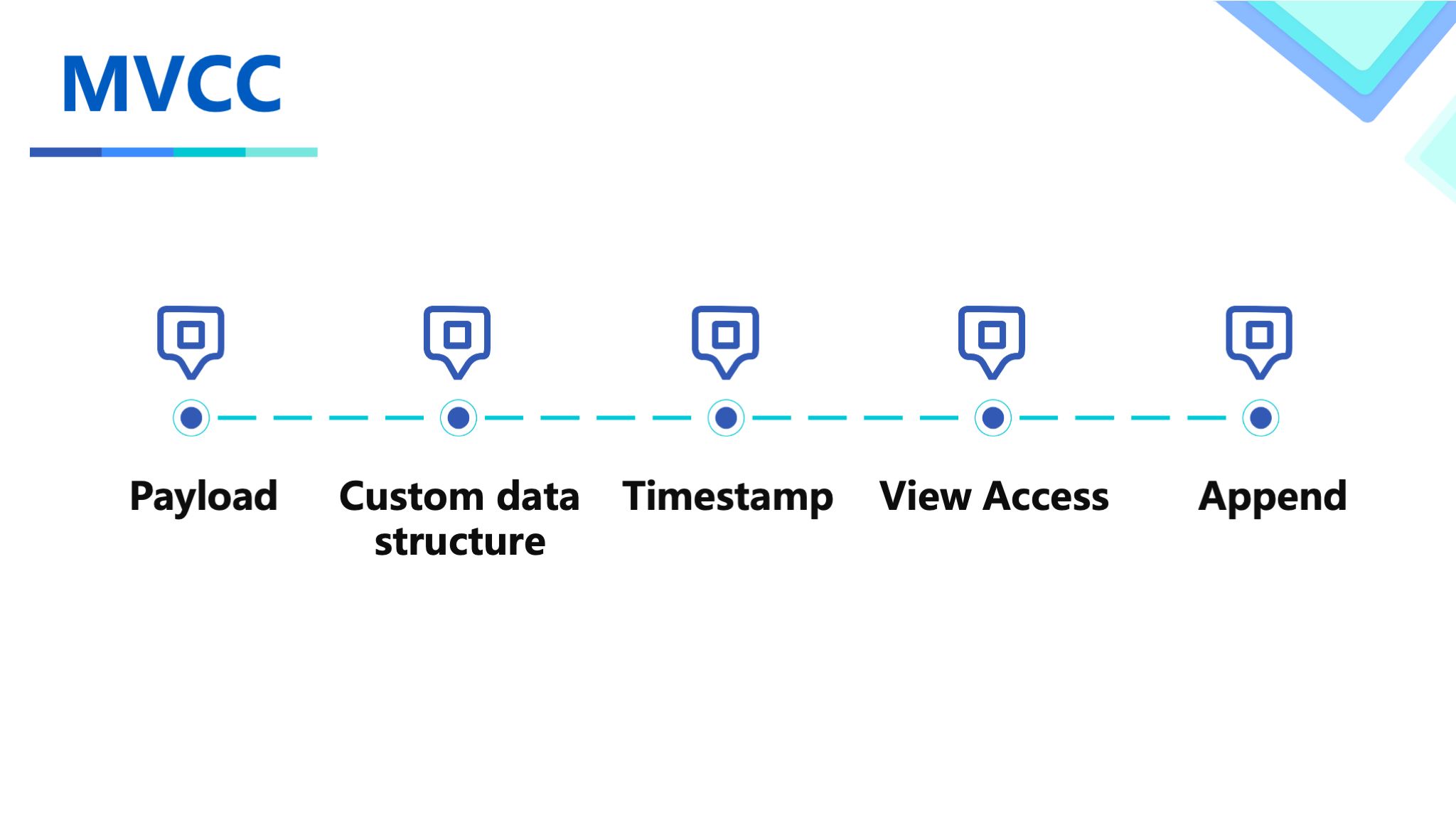
First of all, in order to support WAL write, we implement the payload for MVCC, and based on Avro, we customized a set of data structure implementation with timestamp. This logic is hidden from users through view access. In addition, we also implement the HBase append semantics, which realizes the appending to the List type instead of overwriting.
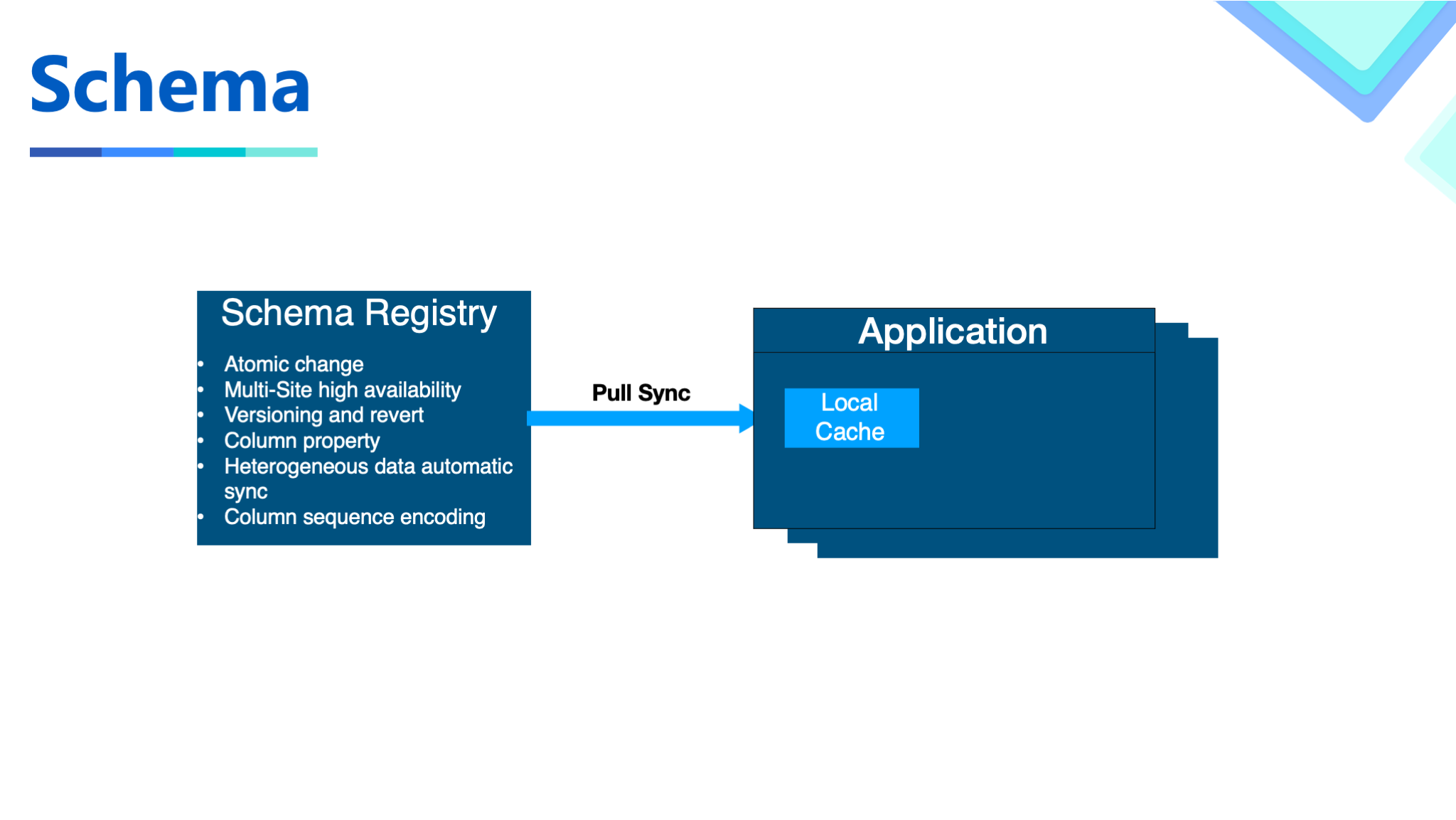
Because Hudi obtains the schema from write data, it is not convenient for working with other systems. We also need some extensions based on the schema, so we build a metadata center to provide metadata-related operations.
-
First of all, we realized atomic changes and multi-site high availability based on the semantics provided by internal storage. Users can atomically trigger schema changes through the interface and get the results immediately.
-
Achieves versioning of the Schema by adding the version number. After having the version number, we can easily use the schema instead of passing JSON object back and forth. With multiple versions, schema evolution can also be flexibly achieved.
-
We also support additional information encoding at the column level to help the business achieve special extended functionality in some scenarios. We replace column names with IDs to save the cost in the storage process.
-
When the Spark job with Hudi is running, it builds a local cache at the JVM level and syncs the data with the metadata center through the pull method, to achieve rapid access to the schema and singleton instance of the in-process schema.
Performance Tuning

In our scenario, the performance challenges are huge. The maximum data volume of a single table reaches 400PB+, the daily volume increase is PB level, and the total data volume reaches EB level. Therefore, we have done some work to improve performance based on the performance and data characteristics.
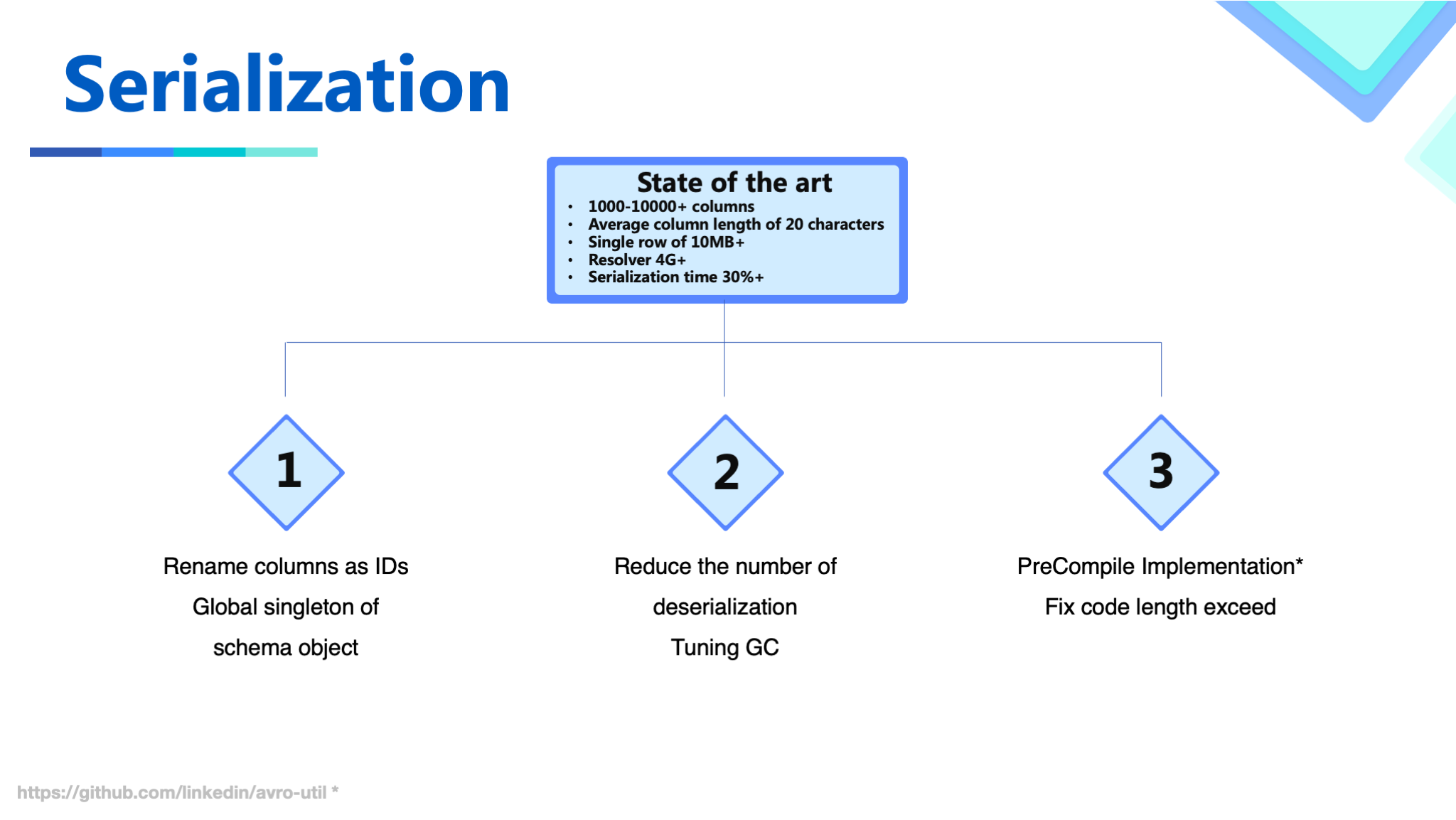
Serialization includes the following optimizations:
-
Schema: the cost of data serialization using Avro is very expensive which consumes a lot of compute resources. To address this problem, we first use the singleton schema instance in JVM to avoid CPU-consuming comparison operations during the serialization process.
-
By optimizing the payload logic, the number of times of running serialization is reduced.
-
With the help of a third-party Avro serialization implementation, the serialization process is compiled into bytecode to improve the speed of SerDe and reduce memory usage. The serialization process has been modified to ensure that our complex schema can also be compiled properly.
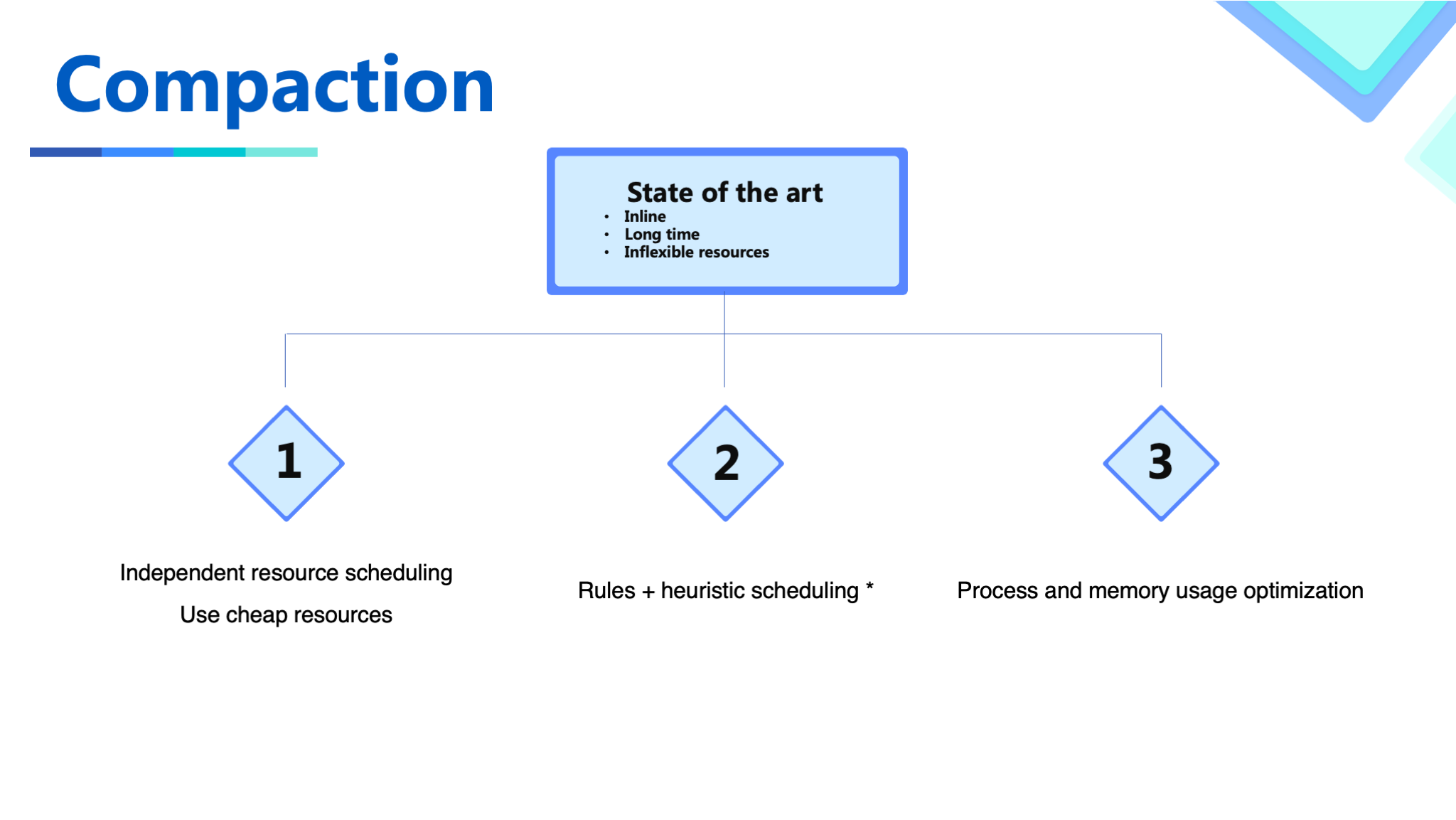
The optimization of the compaction process is as follows.
-
In addition to the default Inline/Async compaction options, Hudi also supports flexible deployment of compaction. The characteristics of the compaction job are quite different from the ingestion job. In the same Spark application, it not only is impossible to set targeted settings but also has the problem of insufficient resource flexibility. We first build an independently deployed script so that the compaction job can be triggered and run independently. A low-cost mixed queue is used for resource scheduling for the compaction plan. In addition, we have also developed a compaction strategy based on rules and heuristics. The user's requirement is usually to guarantee a day-level or hour-level SLA, and targeted compression of data in certain partitions, so targeted compression capabilities are provided.
-
In order to shorten the time of critical compaction, we usually do compaction in advance to avoid all work being completed in a single compaction job. However, if a FileGroup compacted has a new update, it has to be compacted again. In order to optimize the overall efficiency, we made a heuristic scheduling of when a FileGroup should be compacted based on business logic to reduce additional compaction costs. The actual benefits of this feature are still being evaluated.
-
Finally, we made some process optimizations for the compaction, such as not using WriteStatus's Cache and so on.
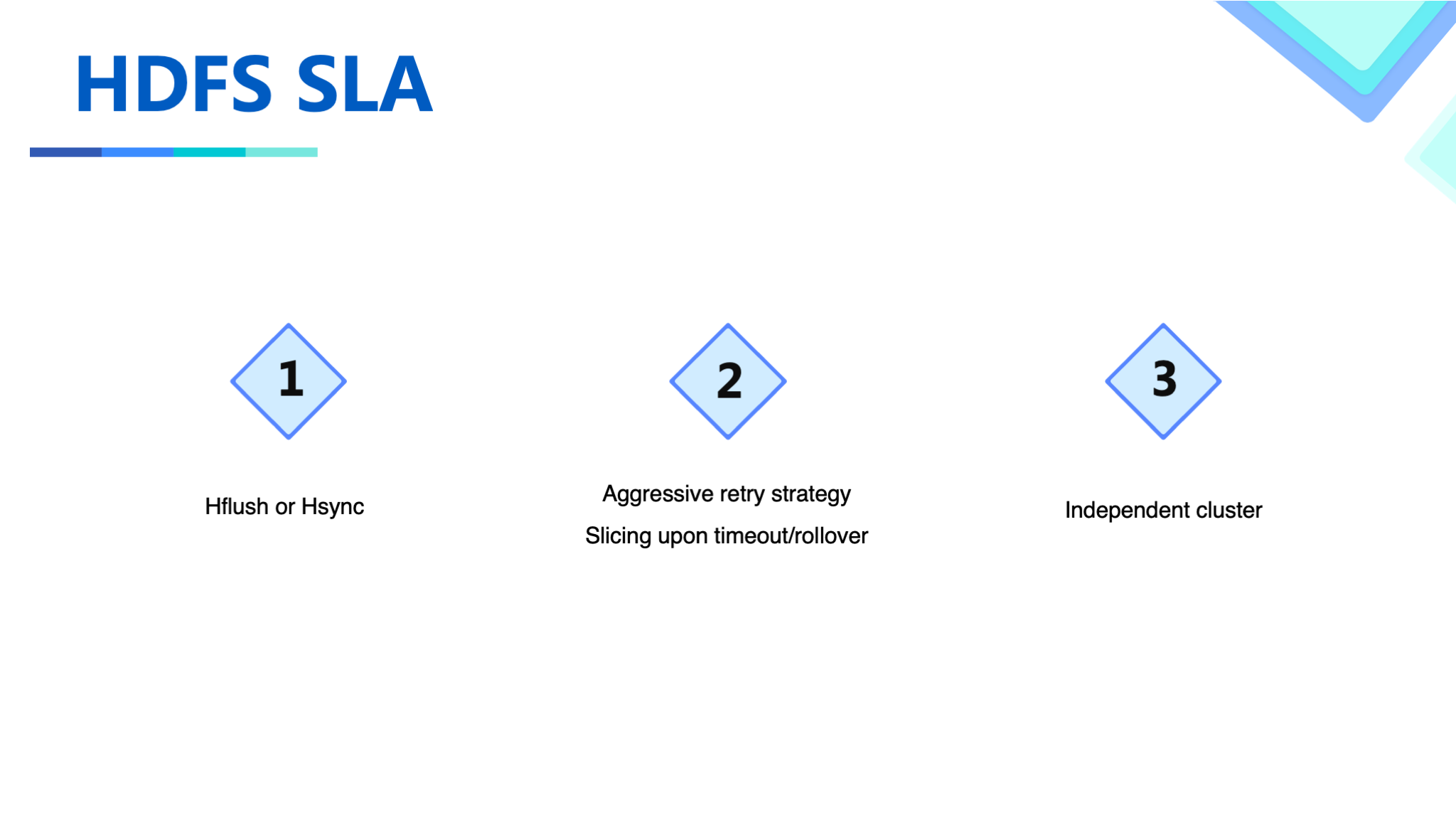
As storage designed for throughput, HDFS has serious real-time write glitches when the cluster usage level is relatively high. Through communication and cooperation with the HDFS team, some improvements have been done.
-
First, we replace the original data HSync operation with HFlush to avoid disk I/O write amplification caused by distributed updates.
-
We make aggressive pipeline switching settings based on the scenario tuning, and the HDFS team has developed a flexible API that can control the pipeline to achieve flexible configurations in this scenario.
-
Finally, the timeliness of real-time writing is ensured through independent I/O isolation of log files.

There are also some small performance improvements, process modifications, and bug fixes. If you are interested, feel free to discuss that with me.
Future Work

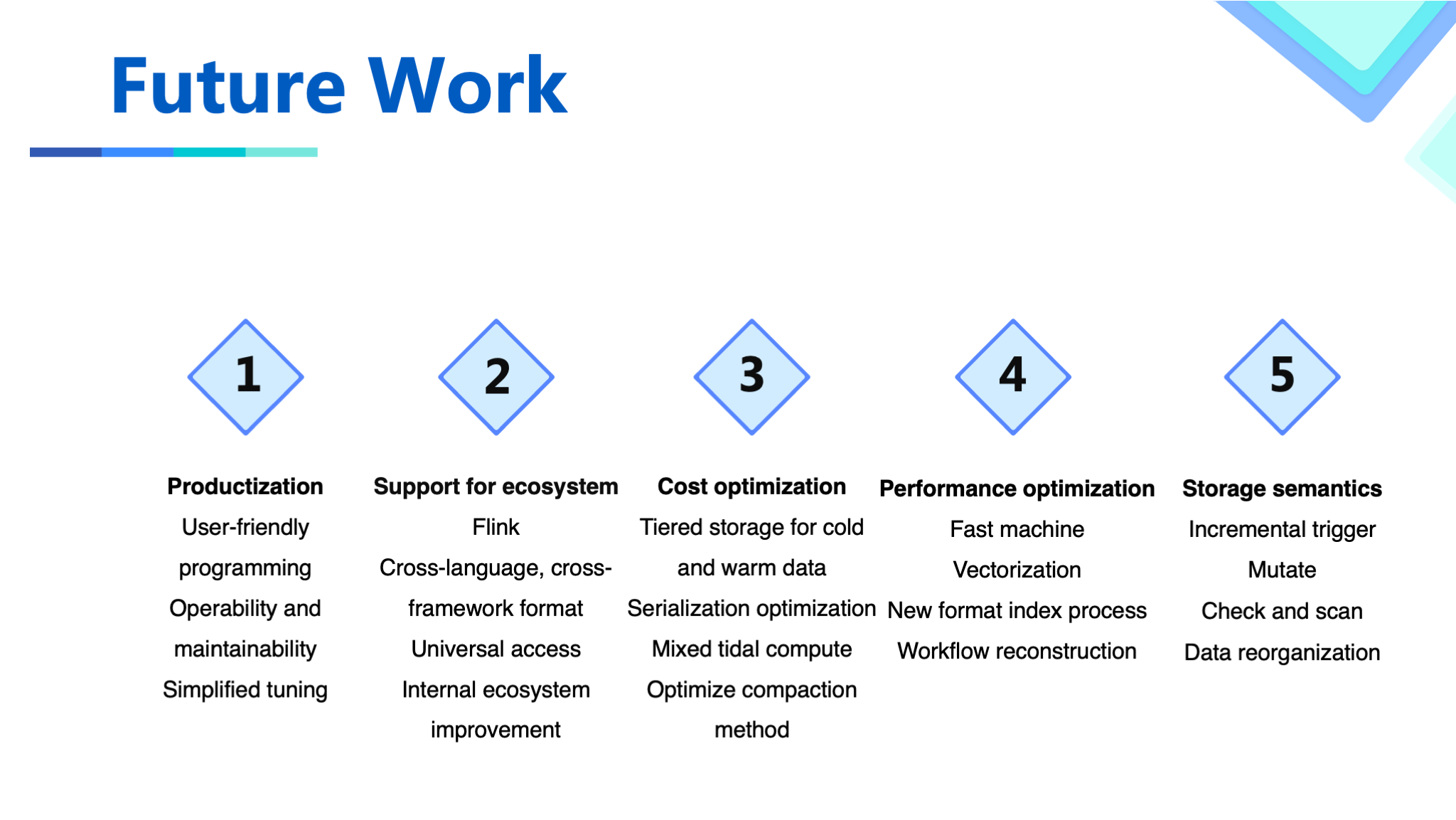
In the future, we will continue to iterate in the following aspects.
-
Productization issues: The current way of using APIs and tuning parameters are highly demanding for the users, especially for the tuning, operation, and maintenance, which requires a deep understanding of Hudi principles to complete. This hinders the promotion of that to users.
-
Support issues for ecosystems: In our scenario, the technology stack is mainly on Flink, and the use of Flink will be explored in the future. In addition, the applications and environments used in upstream and downstream are complex, which requires cross-language and universal interface implementation. The current binding with Spark is cumbersome.
-
Cost and performance issues: a common topic, since our scenario is relatively broad, the benefits from optimization are highly considerable.
-
Storage semantics: We use Hudi as storage rather than a table format. Therefore, in the future, we plan to expand scenarios using Hudi, and need richer storage semantics. We'll do more work in this area.

Finally, an advertisement, our recommendation architecture team is responsible for the recommendation architecture design and development for products such as Douyin, Toutiao, and Xigua Video. The challenges are big and the growth is fast. Now we are hiring people and the working locations include: Beijing/Shanghai/Hangzhou/Singapore/Mountain View. If you are interested, you are welcomed to add WeChat qinglingcannotfly or send your resume to the email: guanziyue.gzy@bytedance.com.