Change Data Capture with Debezium and Apache Hudi

As of Hudi v0.10.0, we are excited to announce the availability of Debezium sources for Deltastreamer that provide the ingestion of change capture data (CDC) from Postgres and Mysql databases to your data lake. For more details, please refer to the original RFC.
Background

When you want to perform analytics on data from transactional databases like Postgres or Mysql you typically need to bring this data into an OLAP system such as a data warehouse or a data lake through a process called Change Data Capture (CDC). Debezium is a popular tool that makes CDC easy. It provides a way to capture row-level changes in your databases by reading changelogs. By doing so, Debezium avoids increased CPU load on your database and ensures you capture all changes including deletes.
Now that Apache Hudi offers a Debezium source connector, CDC ingestion into a data lake is easier than ever with some unique differentiated capabilities. Hudi enables efficient update, merge, and delete transactions on a data lake. Hudi uniquely provides Merge-On-Read writers which unlock significantly lower latency ingestion than typical data lake writers with Spark or Flink. Last but not least, Apache Hudi offers incremental queries so after capturing changes from your database, you can incrementally process these changes downstream throughout all of your subsequent ETL pipelines.
Design Overview
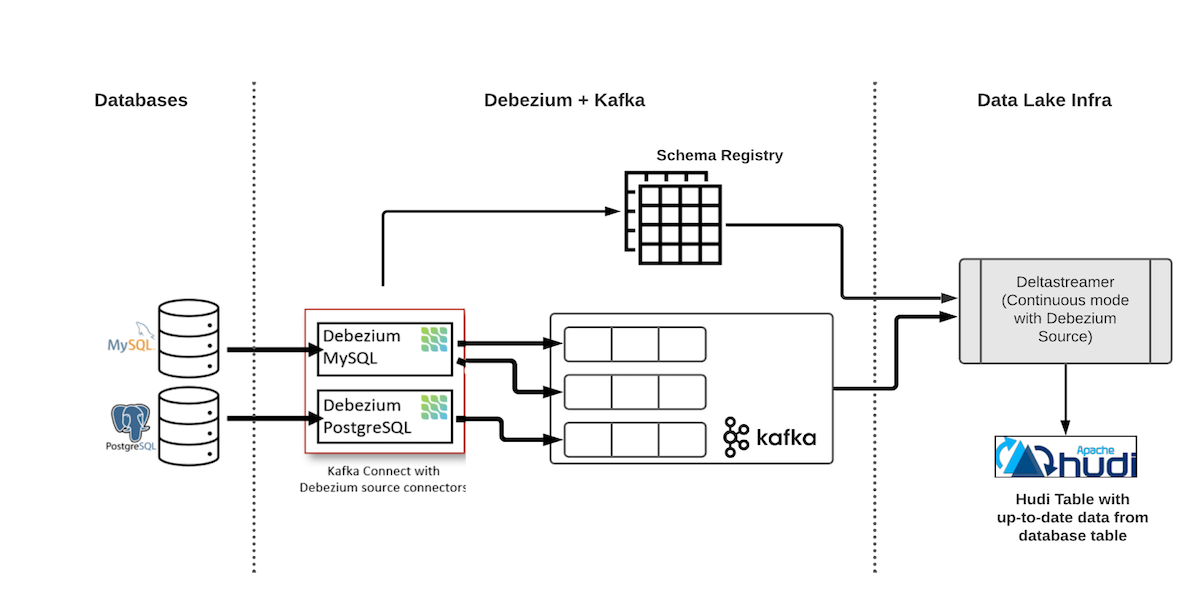
The architecture for an end-to-end CDC ingestion flow with Apache Hudi is shown above. The first component is the Debezium deployment, which consists of a Kafka cluster, schema registry (Confluent or Apicurio), and the Debezium connector. The Debezium connector continuously polls the changelogs from the database and writes an AVRO message with the changes for each database row to a dedicated Kafka topic per table.
The second component is Hudi Deltastreamer that reads and processes the incoming Debezium records from Kafka for each table and writes (updates) the corresponding rows in a Hudi table on your cloud storage.
To ingest the data from the database table into a Hudi table in near real-time, we implement two classes that can be plugged into the Deltastreamer. Firstly, we implemented a Debezium source. With Deltastreamer running in continuous mode, the source continuously reads and processes the Debezium change records in Avro format from the Kafka topic for a given table, and writes the updated record to the destination Hudi table. In addition to the columns from the database table, we also ingest some meta fields that are added by Debezium in the target Hudi table. The meta fields help us correctly merge updates and delete records. The records are read using the latest schema from the Schema Registry.
Secondly, we implement a custom Debezium Payload that essentially governs how Hudi records are merged when the same row is updated or deleted. When a new Hudi record is received for an existing row, the payload picks the latest record using the higher value of the appropriate column (FILEID and POS fields in MySql and LSN fields in Postgres). In the case that the latter event is a delete record, the payload implementation ensures that the record is hard deleted from the storage. Delete records are identified using the op field, which has a value of d for deletes.
Apache Hudi Configurations
It is important to consider the following configurations of your Hudi deployments when using the Debezium source connector for CDC ingestion.
- Record Keys - The Hudi record key(s) for a table should be set as the Primary keys of the table in the upstream database. This ensures that updates are applied correctly as record key(s) uniquely identify a row in the Hudi table.
- Source Ordering Fields - For de-duplication of changelog records the source ordering field should be set to the actual position of the change event as it happened on the database. For instance, we use the FILEID and POS fields in MySql and LSN fields in Postgres databases respectively to ensure records are processed in the correct order of occurrence in the original database.
- Partition Fields - Don’t feel restricted to matching the partitioning of your Hudi tables with the same partition fields as the upstream database. You can set partition fields independently for the Hudi table as needed.
Bootstrapping Existing tables
One important use case might be when CDC ingestion has to be done for existing database tables. There are two ways we can ingest existing database data prior to streaming the changes:
- By default on initialization, Debezium performs an initial consistent snapshot of the database (controlled by config snapshot.mode). After the initial snapshot, it continues streaming updates from the correct position to avoid loss of data.
- While the first approach is simple, for large tables it may take a long time for Debezium to bootstrap the initial snapshot. Alternatively, we could run a Deltastreamer job to bootstrap the table directly from the database using the JDBC source. This provides more flexibility to the users in defining and executing more optimized SQL queries required to bootstrap the database table. Once the bootstrap job finishes successfully, another Deltastreamer job is executed that processes the database changelogs from Debezium. Users will have to use checkpointing in Deltastreamer to ensure the second job starts processing the changelogs from the correct position to avoid data loss.
Example Implementation
The following describes steps to implement an end-to-end CDC pipeline using an AWS RDS instance of Postgres, Kubernetes-based Debezium deployment, and Hudi Deltastreamer running on a spark cluster.
Database
A few configuration changes are required for the RDS instance to enable logical replication.
SET rds.logical_replication to 1 (instead of 0)
psql --host=<aws_rds_instance> --port=5432 --username=postgres --password -d <database_name>;
CREATE PUBLICATION <publication_name> FOR TABLE schema1.table1, schema1.table2;
ALTER TABLE schema1.table1 REPLICA IDENTITY FULL;
Debezium Connector
Strimzi is the recommended option to deploy and manage Kafka connectors on Kubernetes clusters. Alternatively, you have the option to use the Confluent managed Debezium connector.
kubectl create namespace kafka
kubectl create -f https://strimzi.io/install/latest?namespace=kafka -n kafka
kubectl -n kafka apply -f kafka-connector.yaml
An example for kafka-connector.yaml is shown below:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: debezium-kafka-connect
annotations:
strimzi.io/use-connector-resources: "false"
spec:
image: debezium-kafka-connect:latest
replicas: 1
bootstrapServers: localhost:9092
config:
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
The docker image debezium-kafka-connect can be built using the following Dockerfile that includes the Postgres Debezium Connector.
FROM confluentinc/cp-kafka-connect:6.2.0 as cp
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-avro-converter:6.2.0
FROM strimzi/kafka:0.18.0-kafka-2.5.0
USER root:root
RUN yum -y update
RUN yum -y install git
RUN yum -y install wget
RUN wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.6.1.Final/debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN tar xzf debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN mkdir -p /opt/kafka/plugins/debezium && mkdir -p /opt/kafka/plugins/avro/
RUN mv debezium-connector-postgres /opt/kafka/plugins/debezium/
COPY --from=cp /usr/share/confluent-hub-components/confluentinc-kafka-connect-avro-converter/lib /opt/kafka/plugins/avro/
USER 1001
Once the Strimzi operator and the Kafka connect are deployed, we can start the Debezium connector.
curl -X POST -H "Content-Type:application/json" -d @connect-source.json http://localhost:8083/connectors/
The following is an example of a configuration to setup Debezium connector for generating the changelogs for two tables, table1, and table2.
Contents of connect-source.json:
{
"name": "postgres-debezium-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "database",
"plugin.name": "pgoutput",
"database.server.name": "postgres",
"table.include.list": "schema1.table1,schema1.table2",
"publication.autocreate.mode": "filtered",
"tombstones.on.delete":"false",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "<schema_registry_host>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<schema_registry_host>",
"slot.name": "pgslot"
}
}
Hudi Deltastreamer
Next, we run the Hudi Deltastreamer using spark that will ingest the Debezium changelogs from kafka and write them as a Hudi table. One such instance of the command is shown below that works for Postgres database. A few key configurations are as follows:
- Set the source class to PostgresDebeziumSource.
- Set the payload class to PostgresDebeziumAvroPayload.
- Configure the schema registry URLs for Debezium Source and Kafka Source.
- Set the record key(s) as the primary key(s) of the database table.
- Set the source ordering field (dedup) to _event_lsn
spark-submit \\
--jars "/home/hadoop/hudi-utilities-bundle_2.12-0.10.0.jar,/usr/lib/spark/external/lib/spark-avro.jar" \\
--master yarn --deploy-mode client \\
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /home/hadoop/hudi-packages/hudi-utilities-bundle_2.12-0.10.0-SNAPSHOT.jar \\
--table-type COPY_ON_WRITE --op UPSERT \\
--target-base-path s3://bucket_name/path/for/hudi_table1 \\
--target-table hudi_table1 --continuous \\
--min-sync-interval-seconds 60 \\
--source-class org.apache.hudi.utilities.sources.debezium.PostgresDebeziumSource \\
--source-ordering-field _event_lsn \\
--payload-class org.apache.hudi.common.model.debezium.PostgresDebeziumAvroPayload \\
--hoodie-conf schema.registry.url=https://localhost:8081 \\
--hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=https://localhost:8081/subjects/postgres.schema1.table1-value/versions/latest \\
--hoodie-conf hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer \\
--hoodie-conf hoodie.deltastreamer.source.kafka.topic=postgres.schema1.table1 \\
--hoodie-conf auto.offset.reset=earliest \\
--hoodie-conf hoodie.datasource.write.recordkey.field=”database_primary_key” \\
--hoodie-conf hoodie.datasource.write.partitionpath.field=partition_key \\
--enable-hive-sync \\
--hoodie-conf hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor \\
--hoodie-conf hoodie.datasource.write.hive_style_partitioning=true \\
--hoodie-conf hoodie.datasource.hive_sync.database=default \\
--hoodie-conf hoodie.datasource.hive_sync.table=hudi_table1 \\
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=partition_key
Conclusion
This post introduced the Debezium Source for Hudi Deltastreamer to ingest Debezium changelogs into Hudi tables. Database data can now be ingested into data lakes to provide a cost-effective way to store and analyze database data.
Please follow this JIRA to learn more about active development on this new feature. I look forward to more contributions and feedback from the community. Come join our Hudi Slack channel or attend one of our community events to learn more.