Apache Hudi 2022 - A year in Review


Apache Hudi Momentum
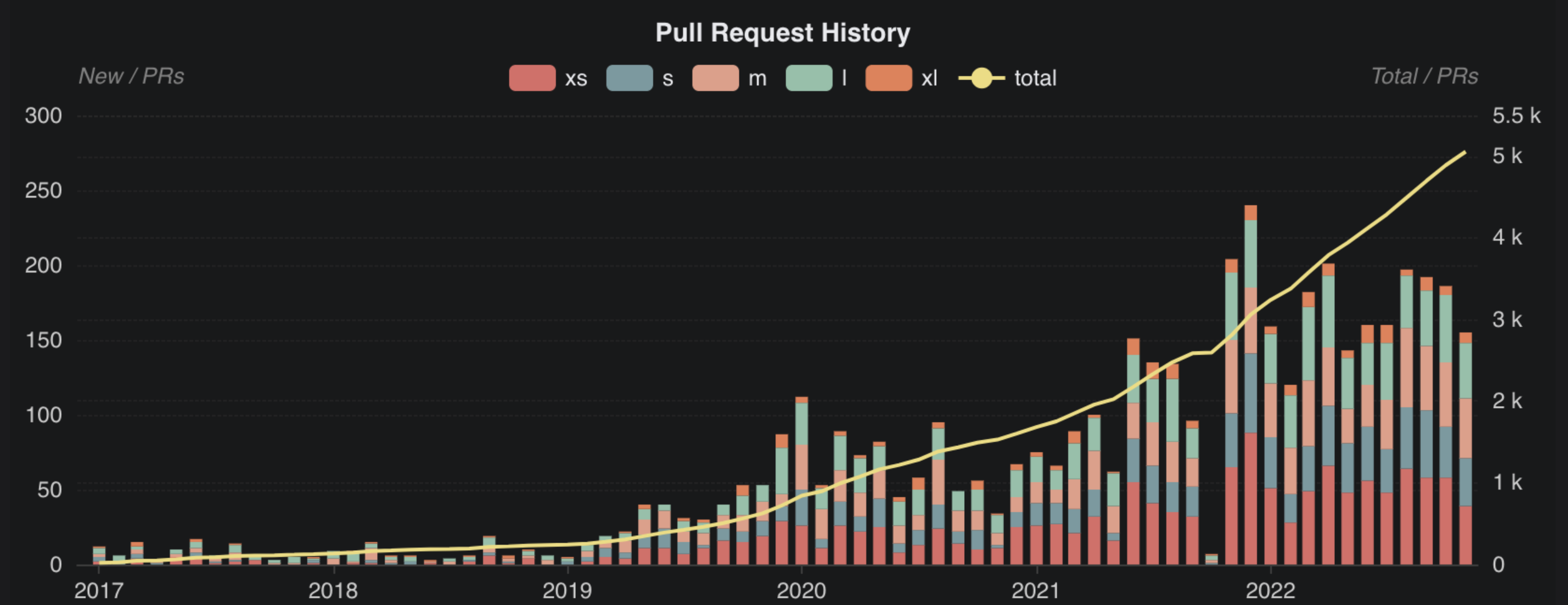
As we wrap up 2022 I want to take the opportunity to reflect on and highlight the incredible progress of the Apache Hudi project and most importantly, the community. First and foremost, I want to thank all of the contributors who have made 2022 the best year for the project ever. There were over 2,200 PRs created (+38% YoY) and over 600+ users engaged on Github. The Apache Hudi community slack channel has grown to more than 2,600 users (+100% YoY growth) averaging nearly 200 messages per month! The most impressive stat is that with this volume growth, the median response time to questions is ~3h. Come join the community where people are sharing and helping each other!
Key Releases in 2022
2022 has been a year jam packed with exciting new features for Apache Hudi across 0.11.0 and 0.12.0 releases. In addition to new features, vendor/ecosystem partnerships and relationships have been strengthened across many in the community. AWS continues to double down on Apache Hudi, upgrading versions in EMR, Athena, Redshift, and announcing a new native connector inside Glue. Presto and Trino merged native Hudi connectors for interactive analytics. DBT, Confluent, Datahub, and several others have added support for Hudi tables. While Google has supported Hudi for a while in BigQuery and Dataproc, it also announced plans to add Hudi in BigLake. The first tutorial for Hudi on Azure Synapse Analytics was published.
While there are too many features added in 2022 to list them all, take a look at some of the exciting highlights:
- Multi-Modal Index is a first-of-its-kind high-performance indexing subsystem for the Lakehouse. It improves metadata lookup performance by up to 100x and reduces overall query latency by up to 30x. Two new indices were added to the metadata table - Bloom filter index that enables faster upsert performance and column stats index along with Data skipping helps speed up queries dramatically.
- Hudi added support for asynchronous indexing to assist building such indices without blocking ingestion so that regular writers don't need to scale up resources for such one off spikes.
- A new type of index called Bucket Index was introduced this year. This could be game changing for deterministic workloads with partitioned datasets. It is very light-weight and allows the distribution of records to buckets using a hash function.
- Filesystem based Lock Provider - This implementation avoids the need of external systems and leverages the abilities of underlying filesystem to support lock provider needed for optimistic concurrency control in case of multiple writers. Please check the lock configuration for details.
- Deltastreamer Graceful Completion - Users can now configure a post-write completion strategy with deltastreamer continuous mode for graceful shutdown.
- Schema on read is supported as an experimental feature since 0.11.0, allowing users to leverage Spark SQL DDL support for evolving data schema needs(drop, rename etc). Added support for a lot of CALL commands to invoke an array of actions on Hudi tables.
- It is now feasible to encrypt your data that you store with Apache Hudi.
- Pulsar Write Commit Callback - On new events to the Hudi table, users can get notified via Pulsar.
- Flink Enhancements: We added metadata table support, async clustering, data skipping, and bucket index for write paths. We also extended flink support to versions 1.13.x, 1.14.x and 1.15.x.
- Presto Hudi integration: In addition to the hive connector we have had for a long time, we added native Presto Hudi connector. This enables users to get access to advanced features of Hudi faster. Users can now leverage metadata table to reduce file listing cost. We also added support for accessing clustered datasets this year.
- Trino Hudi integration: We also added native Trino Hudi connector to assist in querying Hudi tables via Trino Engine. Users can now leverage metadata table to make their queries performant.
- Performance enhancements: Many performance optimizations were landed by the community throughout the year to keep Hudi on par with competition or better. Check out this TPC-DS benchmark comparing Hudi vs Delta Lake.
- Long Term Support: We start to maintain 0.12 as the Long Term Support releases for users to migrate to and stay for a longer duration. In lieu of that, we have made 0.12.1 and 0.12.2 releases to assist users with stable release that comes packed with a lot of stability and bug fixes.
Community Events
Apache Hudi is a global community and thankfully we live in a world today that empowers virtual collaboration and productivity. In addition to connecting virtually this year we have seen the Apache Hudi community gather at many events in person. Re:Invent, Data+AI Summit, Flink Forward, Alluxio Day, Data Council, PrestoCon, Confluent Current, DBT Coalesce, Cinco de Trino, Data Platform Summit, and many more.

You don’t have to travel far to meet and collaborate with the Hudi community. We hold monthly virtual meetups, weekly office hours, and there are plenty of friendly faces on Hudi Slack who like to talk shop. Join us via Zoom for the next Hudi meetup!
Community Content
A wide diversity of organizations around the globe use Apache Hudi as the foundation of their production data platforms. Over 800+ organizations have engaged with Hudi (up 60% YoY) Here are a few highlights of content written by the community sharing their experiences, designs, and best practices:
- Build your Hudi data lake on AWS - Suthan Phillips and Dylan Qu from AWS
- Soumil Shah Hudi Youtube Playlist - Soumil Shah from JobTarget
- SCD-2 with Apache Hudi - Jayasheel Kalgal from Walmart
- Hudi vs Delta vs Iceberg comparisons - Kyle Weller from Onehouse
- Serverless, real-time analytics platform - Kevin Chun from NerdWallet
- DBT and Hudi to Build Open Lakehouse - Vinoth Govindarajan from Apple
- TPC-DS Benchmarks Hudi vs Delta Lake - Alexey Kudinkin from Onehouse
- Key Learnings Using Hudi building a Lakehouse - Jitendra Shah from Halodoc
- Growing your business with modern data capabilities - Jonathan Hwang from Zendesk
- Low-latency data lake using MSK, Flink, and Hudi - Ali Alemi from AWS
- Fresher data lakes on AWS S3 - Balaji Varadarajan from Robinhood
- Experiences with Hudi from Uber meetup - Sam Guleff from Walmart and Vinay Patil from Disney+ Hotstar
What to look for in 2023
Thanks to the strength of the community, Apache Hudi has a bright future for 2023. Check out this recording from our Re:Invent meetup where Vinoth Chandar talks about exciting new features to expect in 2023.
0.13.0 will be the next major release, with a package of exciting new features. Here are a few highlights:
- Record-key-based index to speed up the lookup of records for UUID-based updates and deletes, well tested with 10+ TB index data for hundreds of billions of records at Uber;
- Consistent Hashing Index with dynamically-sized buckets to achieve fast upsert performance with no data skew among file groups compared to existing Bucket Index;
- New CDC format with Debezium-like database change logs to provide before and after image and operation field for streaming changes from Hudi tables, friendly to engines like Flink;
- New Record Merge API to support engine-specific record representation for more efficient writes;
- Early detection of conflicts among concurrent writers to give back compute resources proactively.
The long-term vision of Apache Hudi is to make streaming data lake the mainstream, achieving sub-minute commit SLAs with stellar query performance and incremental ETLs. We plan to harden the indexing subsystem with Table APIs for easy integration with query engines and access to Hudi metadata and indexes, Indexing Functions and a Federated Storage Layer to eliminate the notion of partitions and reduce I/O, and new secondary indexes. To realize fast queries, we will provide an option of a standalone MetaServer serving Hudi metadata to plan queries in milliseconds and a Hudi-aware lake cache that speeds up the read performance of MOR tables along with fast writes for updates. Incremental and streaming SQL will be enhanced in Spark and Flink. For Hudi on Flink, we plan to make the multi-modal indexing production-ready, bring read and write compatibility between Flink and Spark engines, and harden the streaming capabilities, including CDC, streaming ETL semantics, pre-aggregation models and materialized views.
Check out Hudi Roadmap for more to come in 2023!
If you haven't tried Apache Hudi yet, 2023 is your year! Here are a few useful links to help you get started:
If you enjoyed Hudi in 2022 don't forget to give it a little star on Github ⭐