Schema evolution with DeltaStreamer using KafkaSource
The schema used for data exchange between services can change rapidly with new business requirements. Apache Hudi is often used in combination with kafka as a event stream where all events are transmitted according to a record schema. In our case a Confluent schema registry is used to maintain the schema and as schema evolves, newer versions are updated in the schema registry.
What do we want to achieve?
We have multiple instances of DeltaStreamer running, consuming many topics with different schemas ingesting to multiple Hudi tables. Deltastreamer is a utility in Hudi to assist in ingesting data from multiple sources like DFS, kafka, etc into Hudi. If interested, you can read more about DeltaStreamer tool here
Ideally every topic should be able to evolve the schema to match new business requirements. Producers start producing data with a new schema version and the DeltaStreamer picks up the new schema and ingests the data with the new schema. For this to work, we run our DeltaStreamer instances with the latest schema version available from the Schema Registry to ensure that we always use the freshest schema with all attributes.
A prerequisites is that all the mentioned Schema evolutions must be BACKWARD_TRANSITIVE compatible (see Schema Evolution and Compatibility of Avro Schema changes. This ensures that every record in the kafka topic can always be read using the latest schema.
What is the problem?
The normal operation looks like this. Multiple (or a single) producers write records to the kafka topic.
In regular flow of events, all records are in the same schema v1 and is in sync with schema registry.

Things get complicated when a producer switches to a new Writer-Schema v2 (in this case Producer A). Producer B remains on Schema v1. E.g. an attribute myattribute was added to the schema, resulting in schema version v2.
Deltastreamer is capable of handling such schema evolution, if all incoming records were evolved and serialized with evolved schema. But the complication is that, some records are serialized with schema version v1 and some are serialized with schema version v2.
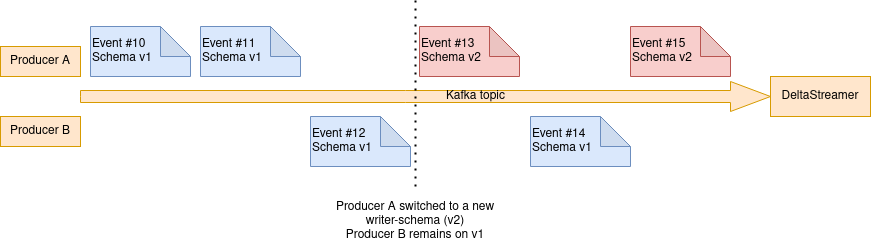
The default deserializer used by Hudi io.confluent.kafka.serializers.KafkaAvroDeserializer uses the schema that the record was serialized with for deserialization. This causes Hudi to get records with multiple different schema from the kafka client. E.g. Event #13 has the new attribute myattribute, Event #14 does not have the new attribute myattribute. This makes things complicated and error-prone for Hudi.

Solution
Hudi added a new custom Deserializer KafkaAvroSchemaDeserializer to solve this problem of different producers producing records in different schema versions, but to use the latest schema from schema registry to deserialize all the records.
As first step the Deserializer gets the latest schema from the Hudi SchemaProvider. The SchemaProvider can get the schema for example from a Confluent Schema-Registry or a file.
The Deserializer then reads the records from the topic using the schema the record was written with. As next step it will convert all the records to the latest schema from the SchemaProvider, in our case the latest schema. As a result, the kafka client will return all records with a unified schema i.e. the latest schema as per schema registry. Hudi does not need to handle different schemas inside a single batch.

Configurations
As of upcoming release 0.9.0, normal Confluent Deserializer is used by default. One has to explicitly set KafkaAvroSchemaDeserializer as below, in order to ensure smooth schema evolution with different producers producing records in different versions.
hoodie.deltastreamer.source.kafka.value.deserializer.class=org.apache.hudi.utilities.deser.KafkaAvroSchemaDeserializer
Conclusion
Hope this blog helps in ingesting data from kafka into Hudi using Deltastreamer tool catering to different schema evolution needs. Hudi has a very active development community and we look forward for more contributions. Please check out this link to start contributing.