Marker Mechanism
Purpose of Markers
A write operation can fail before it completes, leaving partial or corrupt data files on storage. Markers are used to track and cleanup any partial or failed write operations. As a write operation begins, a marker is created indicating that a file write is in progress. When the write commit succeeds, the marker is deleted. If a write operation fails part way through, a marker is left behind which indicates that the file is incomplete. Two important operations that use markers include:
- Removing duplicate/partial data files:
- In Spark, the Hudi write client delegates the data file writing to multiple executors. One executor can fail the task, leaving partial data files written, and Spark retries the task in this case until it succeeds.
- When speculative execution is enabled, there can also be multiple successful attempts at writing out the same data into different files, only one of which is finally handed to the Spark driver process for committing. The markers help efficiently identify the partial data files written, which contain duplicate data compared to the data files written by the successful trial later, and these duplicate data files are cleaned up when the commit is finalized.
- Rolling back failed commits: If a write operation fails, the next write client will roll back the failed commit before proceeding with the new write. The rollback is done with the help of markers to identify the data files written as part of the failed commit.
If we did not have markers to track the per-commit data files, we would have to list all files in the file system, correlate that with the files seen in timeline and then delete the ones that belong to partial write failures. As you could imagine, this would be very costly in a very large installation of a datalake.
Marker structure
Each marker entry is composed of three parts, the data file name,
the marker extension (.marker), and the I/O operation created the file (CREATE - inserts, MERGE - updates/deletes,
or APPEND - either). For example, the marker 91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet.marker.CREATE indicates
that the corresponding data file is 91245ce3-bb82-4f9f-969e-343364159174-0_140-579-0_20210820173605.parquet and the I/O type is CREATE.
Marker Writing Options
There are two ways to write Markers:
- Directly writing markers to storage, which is a legacy configuration.
- Writing markers to the Timeline Server which batches marker requests before writing them to storage (Default). This option improves write performance of large files as described below.
Direct Write Markers
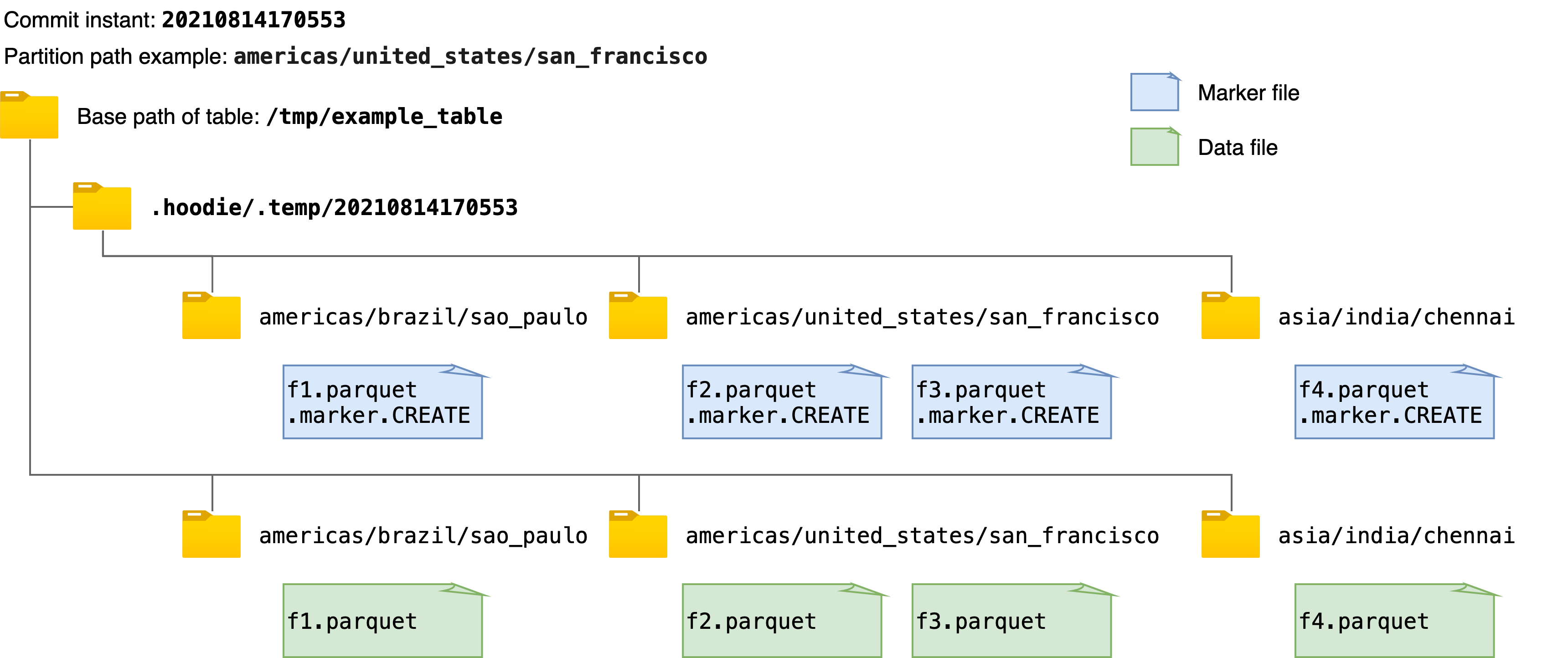
Directly writing to storage creates a new marker file corresponding to each data file, with the marker filename as described above.
The marker file does not have any content, i.e., empty. Each marker file is written to storage in the same directory
hierarchy, i.e., commit instant and partition path, under a temporary folder .hoodie/.temp under the base path of the Hudi table.
For example, the figure below shows one example of the marker files created and the corresponding data files when writing
data to the Hudi table. When getting or deleting all the marker file paths, the mechanism first lists all the paths
under the temporary folder, .hoodie/.temp/<commit_instant>, and then does the operation.
While it's much efficient over scanning the entire table for uncommitted data files, as the number of data files to write increases, so does the number of marker files to create. For large writes which need to write significant number of data files, e.g., 10K or more, this can create performance bottlenecks for cloud storage such as AWS S3. In AWS S3, each file create and delete call triggers an HTTP request and there is rate-limiting on how many requests can be processed per second per prefix in a bucket. When the number of data files to write concurrently and the number of marker files is huge, the marker file operations could take up non-trivial time during the write operation, sometimes on the order of a few minutes or more.
Timeline Server Markers (Default)
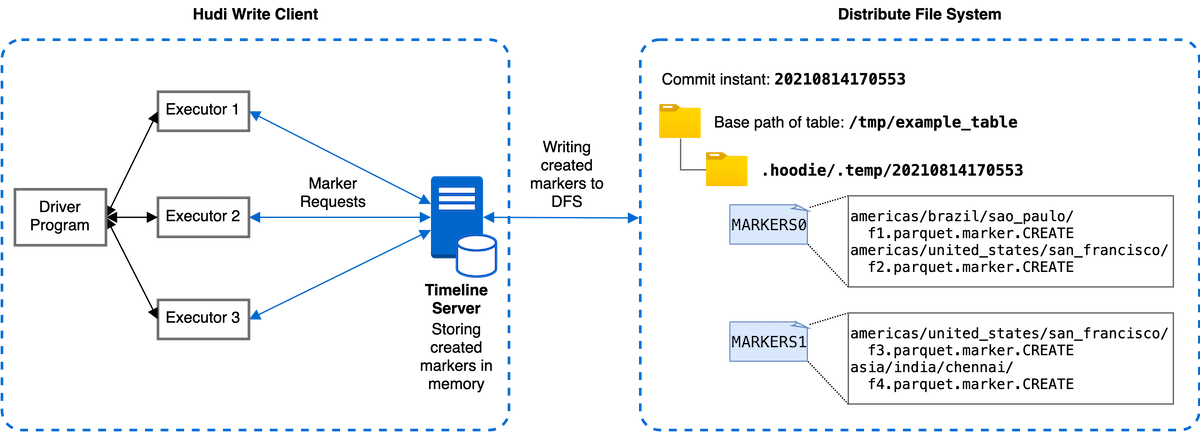
To address the performance bottleneck due to rate-limiting of AWS S3 explained above, we introduce a new marker mechanism leveraging the timeline server, which optimizes the marker-related latency for storage with non-trivial file I/O latency. In the diagram below you can see the timeline-server-based marker mechanism delegates the marker creation and other marker-related operations from individual executors to the timeline server for centralized processing. The timeline server batches the marker creation requests and writes the markers to a bounded set of files in the file system at configurable batch intervals (default 50ms). In this way, the number of actual file operations and latency related to markers can be significantly reduced even with a huge number of data files, leading to improved performance of large writes.
Each marker creation request is handled asynchronously in the Javalin timeline server and queued before processing. For every batch interval, the timeline server pulls the pending marker creation requests from the queue and writes all markers to the next file in a round robin fashion. Inside the timeline server, such batch processing is multi-threaded, designed and implemented to guarantee consistency and correctness. Both the batch interval and the batch concurrency can be configured through the write options.
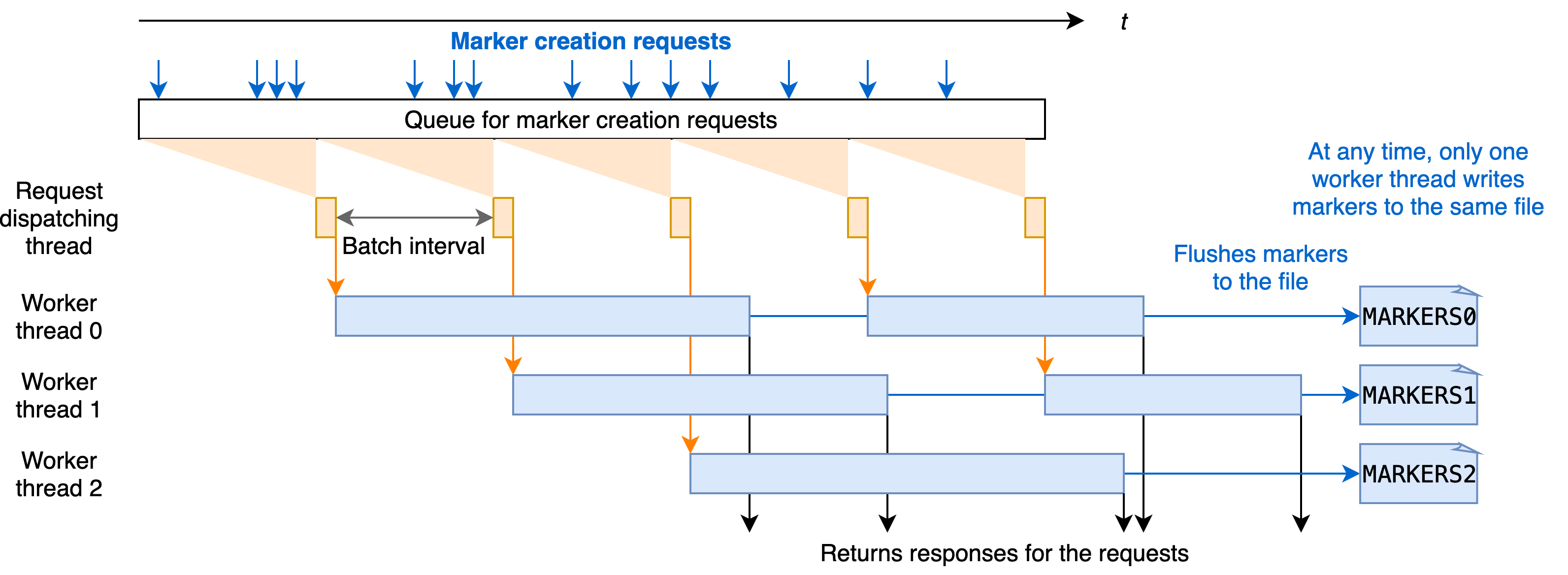
Note that the worker thread always checks whether the marker has already been created by comparing the marker name from the request with the memory copy of all markers maintained at the timeline server. The underlying files storing the markers are only read upon the first marker request (lazy loading). The responses of requests are only sent back once the new markers are flushed to the files, so that in the case of the timeline server failure, the timeline server can recover the already created markers. These ensure consistency between storage and the in-memory copy, and improve the performance of processing marker requests.
NOTE: Timeline based markers are not yet supported for HDFS, however, users may barely notice performance challenges with direct markers because the file system metadata is efficiently cached in memory and doesn't face the same rate-limiting as S3.
Marker Configuration Parameters
| Property Name | Default | Meaning |
|---|---|---|
hoodie.write.markers.type | timeline_server_based | Marker type to use. Two modes are supported: (1) direct: individual marker file corresponding to each data file is directly created by the executor; (2) timeline_server_based: marker operations are all handled at the timeline service which serves as a proxy. New marker entries are batch processed and stored in a limited number of underlying files for efficiency. |
hoodie.markers.timeline_server_based.batch.num_threads | 20 | Number of threads to use for batch processing marker creation requests at the timeline server. |
hoodie.markers.timeline_server_based.batch.interval_ms | 50 | The batch interval in milliseconds for marker creation batch processing. |