Table Metadata
Hudi tracks metadata about a table to remove bottlenecks in achieving great read/write performance, specifically on cloud storage.
-
Avoid list operations to obtain set of files in a table: A fundamental need for any engine that wants to read or write Hudi tables is to know all the files/objects that are part of the table, by performing listing of table partitions/folders. Unlike many distributed file systems, such operation scales poorly on cloud storage taking few seconds or even many minutes on large tables. This is particularly amplified when tables are large and partitioned multiple levels deep. Hudi tracks the file listings so they are readily available for readers/writers without listing the folders containing the data files.
-
Expose columns statistics for better query planning and faster queries: Query engines rely on techniques such as partitioning and data skipping to cut down on the amount of irrelevant data scanned for query planning and execution. During query planning phase, file footer statistics like column value ranges, null counts are read from all data files to determine if a particular file needs to be read to satisfy the query. This approach is expensive since reading footers from all files can increase cloud storage API costs and even be subject to throttling issues for larger tables. Hudi enables relevant query predicates to be efficiently evaluated on operate on column statistics without incurring these costs.
Metadata Table
Hudi employs a special metadata table, within each table to provide these capabilities. The metadata table implemented as a single internal Hudi Merge-On-Read table that hosts different types of table metadata in each partition. This is similar to common practices in databases where metadata is tracked using internal tables. This approach provides the following advantages.
-
Scalable: The table metadata must scale to large sizes as well (see Big Metadata paper from Google). Different types of indexes should be easily integrated to support various use cases with consistent management of metadata. By implementing metadata using the same storage format and engine used for data, Hudi is able to scale to even TBs of metadata with built-in table services for managing metadata.
-
Flexible: The foundational framework for multi-modal indexing is built to enable and disable new indexes as needed. The async indexing protocol index building alongside regular writers without impacting the write latency.
-
transactional updates: Tables data, metadata and indexes must be upto-date and consistent with each other as writes happen or table services are performed. and table metadata must be always up-to-date and in sync with the data table. The data and metadata table's timelines share a parent-child relationship, to ensure they are always in sync with each other. Furthermore, the MoR table storage helps absorb fast changes to metadata from streaming writes without requiring rewriting of all table metadata on each write.
-
Fast lookups: By employing a SSTable like base file format (HFile) in the metadata table, query engines are able to efficiently perform lookup scans for only specific parts of metadata needed. For e.g. query accessing only 10 out of 100 columns in a table can read stats about only the 10 columns it's interested in, during down planning time and costs. Further, these metadata can also be served via a centralized/embedded timeline server which caches the metadata, further reducing the latency of the lookup from executors.
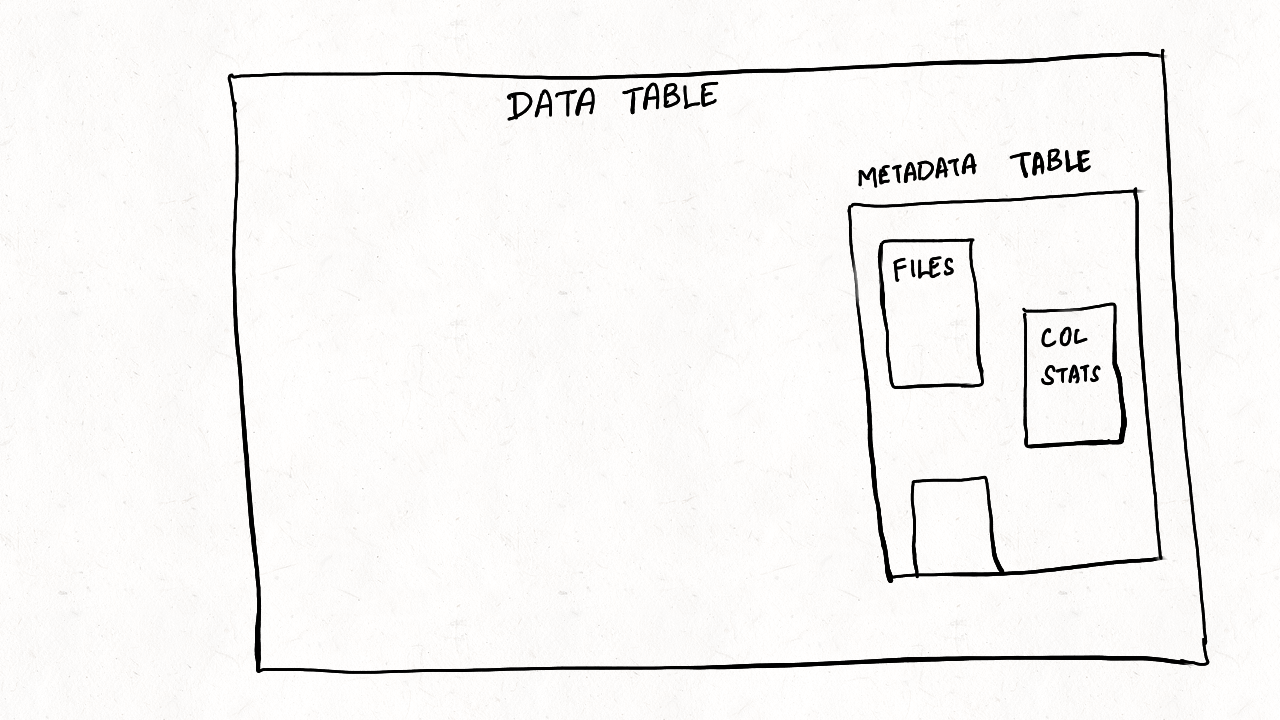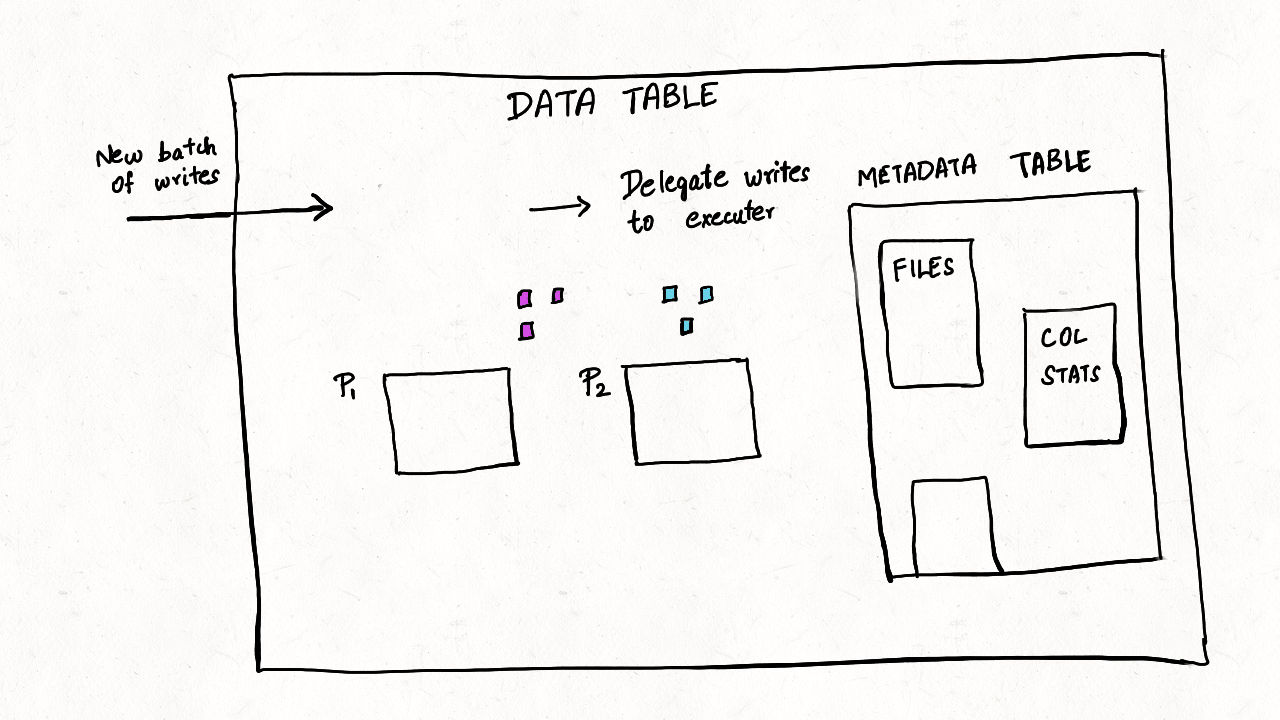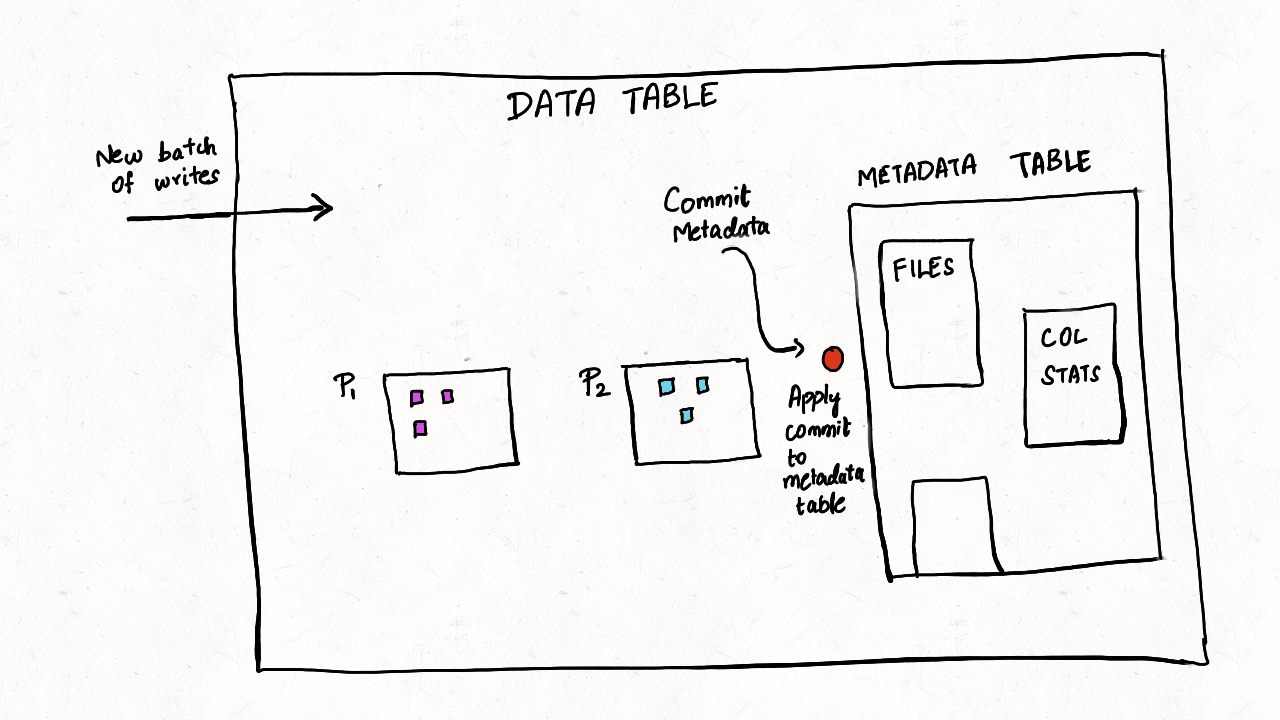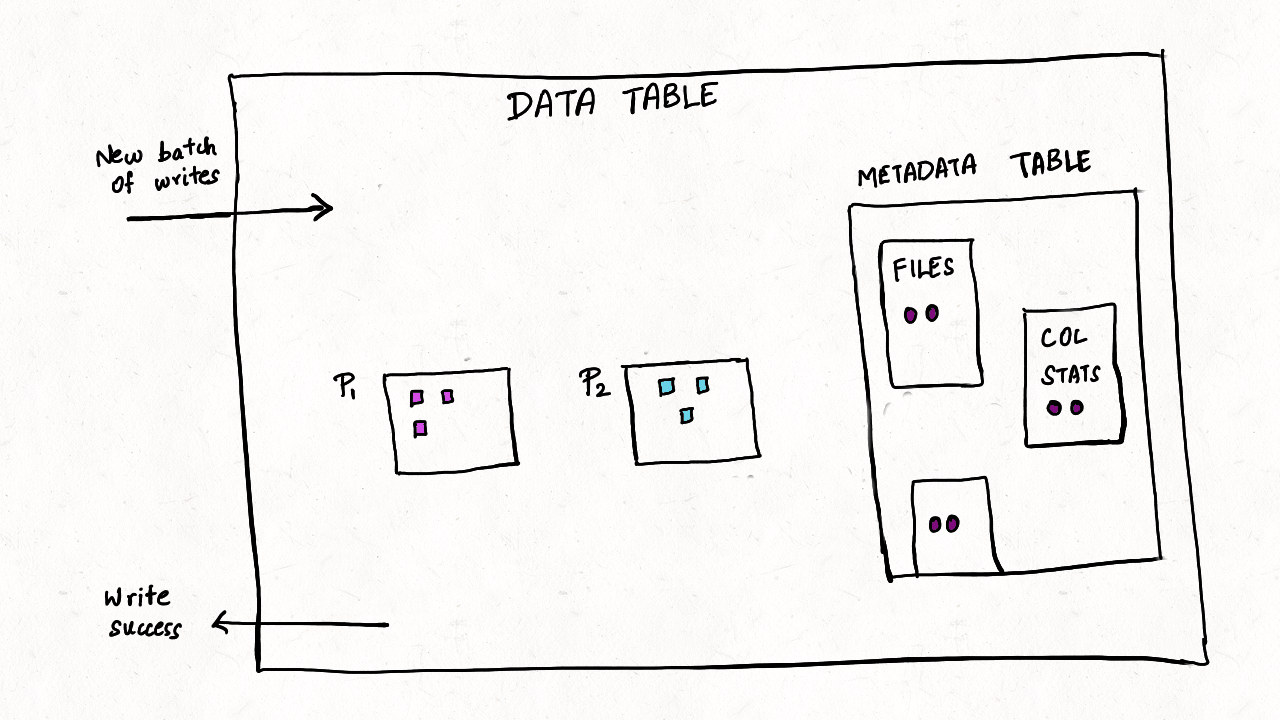
Figure: Mechanics for Metadata Table in Hudi
Types of table metadata
Following are the different types of metadata currently supported.
-
files listings: Stored as files partition in the metadata table. Contains file information such as file name, size, and active state for each partition in the data table, along with list of all partitions in the table. Improves the files listing performance by avoiding direct storage calls such as exists, listStatus and listFiles on the data table.
-
column statistics: Stored as column_stats partition in the metadata table. Contains the statistics for a set of tracked columns, such as min and max values, total values, null counts, size, etc., for all data files and are used while serving queries with predicates matching interested columns. This is heavily used by techniques like data skipping to speed up queries by orders of magnitude, by skipping irrelevant files.
-
Partition Statistics: Partition stats index aggregates statistics at the partition level for the columns tracked by the column statistics for which it is enabled. This helps in efficient partition pruning by skipping entire folders very quickly, even without examining column statistics at the file level. The partition stats index is stored in partition_stats partition in the metadata table. Partition stats index can be enabled using the following configs (note it is required to specify the columns for which stats should be aggregated).
To try out these features, refer to the SQL guide.
Metadata Tracking on Writers
Following are based basic configs that are needed to enable metadata tracking. For advanced configs please refer here.
| Config Name | Default | Description |
|---|---|---|
| hoodie.metadata.enable | true (Optional) Enabled on the write side | Enable the internal metadata table serving file listings. For 0.10.1 and prior releases, metadata table is disabled by default and needs to be explicitly enabled.Config Param: ENABLESince Version: 0.7.0 |
| hoodie.metadata.index.column.stats.enable | false (Optional) | Enable column statistics tracking of files under metadata table. When enabled, metadata table will have a partition to store the column ranges and will be used for pruning files during data skipping.Config Param: ENABLE_METADATA_INDEX_COLUMN_STATSSince Version: 0.11.0 |
| hoodie.metadata.index.column.stats.columns | all columns in the table | Comma separated list of columns to track column statistics on. |
| hoodie.metadata.index.partition.stats.enable | false (Optional) | Enable the partition stats tracking, on the same columns tracked by column stats metadata. |
For Flink, following are the basic configs of interest to enable metadata tracking. Please refer here for advanced configs
| Config Name | Default | Description |
|---|---|---|
| metadata.enabled | true (Optional) | Enable the internal metadata table which serves table metadata like level file listings, default enabledConfig Param: METADATA_ENABLED |
If you turn off the metadata table after enabling, be sure to wait for a few commits so that the metadata table is fully cleaned up, before re-enabling the metadata table again.
Auto-Delete of Disabled MDT Partitions
When an index is disabled in the write config, Hudi automatically deletes the corresponding metadata table partition. Available since Hudi 1.2.0, this behavior is configurable.
| Config Name | Default | Description |
|---|---|---|
hoodie.metadata.auto.delete.partitions | true | When enabled (default), metadata table partitions (indexes) that are disabled in the write config are automatically deleted. Set to false to prevent accidental deletion in multi-writer environments where not all writers may have the same config — users must then drop indexes explicitly via Hudi CLI or DROP INDEX. |
Leveraging metadata during queries
files index
Metadata based listing using files_index can be leveraged on the read side by setting appropriate configs/session properties from different engines as shown below:
| Readers | Config | Description |
|---|---|---|
| Spark DataSource, Spark SQL, Strucured Streaming | hoodie.metadata.enable | When set to true enables use of the spark file index implementation for Hudi, that speeds up listing of large tables. |
| Flink DataStream, Flink SQL | metadata.enabled | When set to true from DDL uses the internal metadata table to serves table metadata like level file listings |
| Presto | hudi.metadata-table-enabled | When set to true fetches the list of file names and sizes from Hudi’s metadata table rather than storage. |
| Trino | N/A | Support for reading from the metadata table has been dropped in Trino 419. |
| Athena | hudi.metadata-listing-enabled | When this table property is set to TRUE enables the Hudi metadata table and the related file listing functionality |
column_stats index and data skipping
Enabling metadata table and column stats index is a prerequisite to enabling data skipping capabilities. Following are the corresponding configs across Spark and Flink readers.
| Readers | Config | Description |
|---|---|---|
| Spark DataSource, Spark SQL, Strucured Streaming |
|
|
| Flink DataStream, Flink SQL |
|
|
Concurrency Control for Metadata Table
To ensure that metadata table stays up to date and table metadata is tracked safely across concurrent write and
table operations, there are some additional considerations. If async table services are enabled for the table (i.e. running a separate compaction (HoodieCompactor) or
clustering (HoodieClusteringJob) job), even with just a single writer, lock providers
must be configured. Please refer to concurrency control for more details.
Before enabling metadata table for the first time, all writers on the same table must and table services must be stopped. If your current deployment model is multi-writer along with a lock provider and other required configs set for every writer as follows, there is no additional configuration required. You can bring up the writers sequentially after stopping the writers for enabling metadata table. Applying the proper configurations to only a subset of writers or table services is unsafe and can lead to loss of data. So, please ensure you enable metadata table across all writers.
MDT Cleaner and Compaction
Hudi 1.2.0 introduced a config that lets the metadata table's cleaner derive its retention policy directly from the data table, rather than requiring a separate configuration.
| Config Name | Default | Description |
|---|---|---|
hoodie.metadata.derive.from.datatable.clean.policy | true | When enabled, the metadata table's cleaner uses the same cleaning policy (retention count, hours, etc.) as the data table. See also cleaning. |
The metadata table's compaction and log compaction can also be delegated to an external table service platform. See compaction for the full config reference.
Timeline Archival Controls
Hudi 1.2.0 added two configs in HoodieArchivalConfig to fine-tune how the timeline manifest and archival interact
with the most recent clean.
| Config Name | Default | Description |
|---|---|---|
hoodie.timeline.manifest.retained.versions | 3 | Number of timeline manifest file versions to retain. Older manifest versions are pruned during archival. |
hoodie.archive.block.on.latest.clean.ectr | false | When enabled, archival stops at the Earliest Commit To Retain (ECTR) from the last completed clean. This prevents archiving commits whose data files still exist on storage, avoiding inconsistencies between the timeline and actual data. |