Table & Query Types
Hudi table types define how data is stored and how write operations are implemented on top of the table (i.e how data is written). In turn, query types define how the underlying data is exposed to the queries (i.e. how data is read).
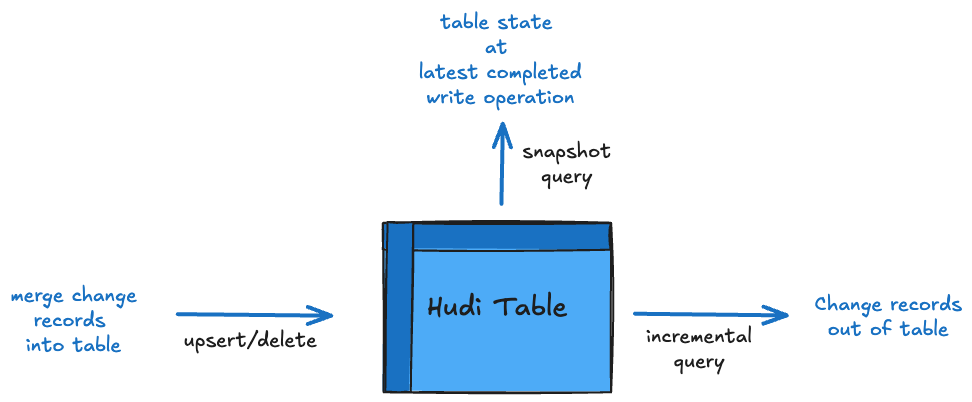
Figure: Tables & Queries
Hudi introduced the following table types, which are now used industry-wide, to reason about similar trade-offs.
Copy On Write : The Copy-on-Write (CoW) table type is optimized for read-heavy workloads. In this mode, record updates or deletes trigger the creation of new base files in a file group and there are no log files written. This ensures that each query reads only the base files, offering high read performance with no need to merge log files dynamically. While CoW tables are ideal for OLAP scans/queries, their write operations can be slower due to the overhead of rewriting base files during updates or deletes, even if small percentage of records are modified in each file.
Merge On Read : The Merge-on-Read (MoR) table type balances the write and read performance by combining lightweight log files with the base file using periodic compaction. Data updates and deletes are written to log files (in row based formats like Avro or columnar/base file formats) and these changes in log files are then merged dynamically with base files during query execution. This approach reduces write latency and supports near real-time data availability. However, query performance may vary depending on whether the log files are compacted.
Core transactional capabilities like atomic writes, indexes as well as unique new features like incremental queries, automatic file-sizing and scalable table metadata tracking, are provided across both, independent of the table type.
Copy On Write Table
Following illustrates how this works conceptually, when data is written into copy-on-write table and two queries running on top of it.
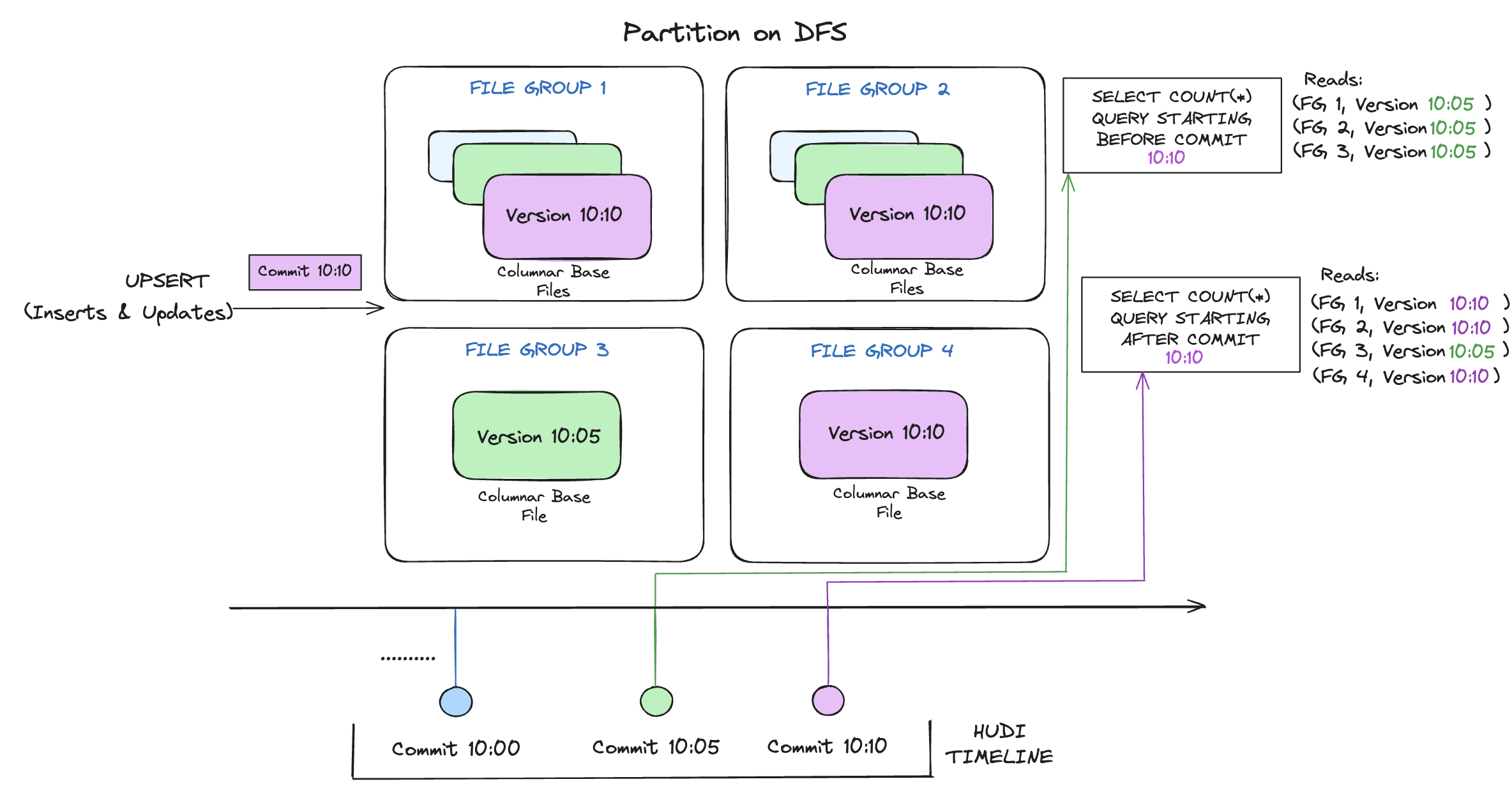
As data gets written, updates to existing file groups produce a new slice for that file group stamped associated with the commit's requested instant time,
while inserts allocate a new file group and write its first slice for that file group. These file slices and their commit completed instant times are color coded above.
SQL queries running against such a table (eg: select count(*) counting the total records in that partition), first checks the timeline for the completed writes
and filters all but latest file slices of each file group. As you can see, the older query does not see the current inflight commit's files (color coded in pink)
but a new query starting after the commit picks up the new data. Thus, queries are immune to any write failures/partial writes and only read committed data.
Following are good use-cases for CoW tables.
-
Batch ETLs/Data Pipelines: Provides a simple, easy to operate option for moving SQL based ETLs from data warehouses or authoring complex code based pipelines that run every few hours. These typically tend to be tables derived from raw/ingestion layer downstream.
-
Data Warehousing on Data Lakes: Given the excellent read performance, CoW tables can be used for running fast OLAP queries combined with other table services to optimize the layout based on these queries.
-
Static or Slowly Changing Data: Owing to their simplicity, CoW tables are an excellent choice for reference tables, or very slowly updates tables that rarely change.
Merge On Read Table
Following illustrates how a MoR table works, and shows two types of queries - snapshot query and a read optimized query.
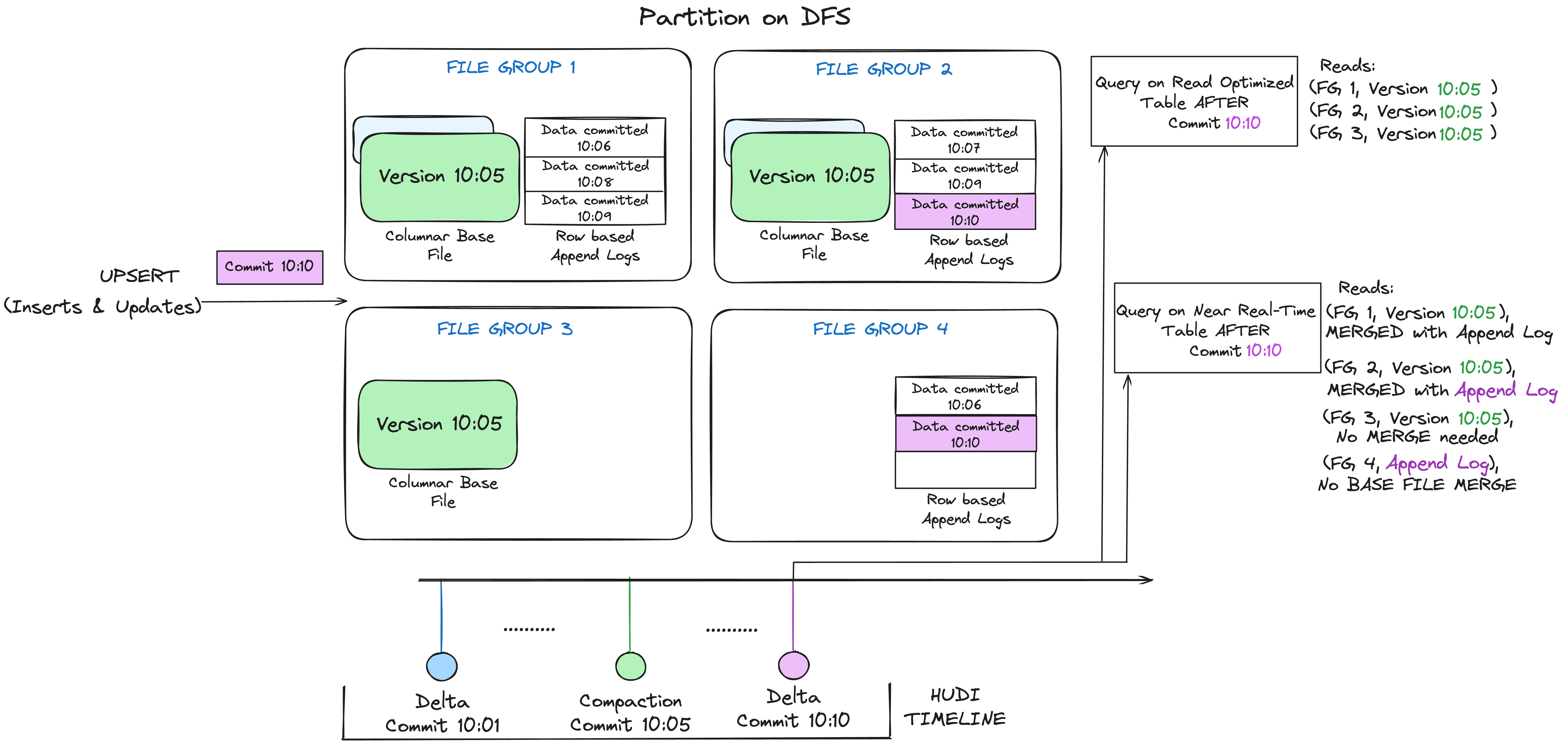
There are a lot of interesting things happening in this example, which bring out the subtleties in the approach.
-
We now have more frequent commits every 1 minute or so, given the writing is lighter weight.
-
Within each file group, now there are delta log files, which holds incoming updates to records in the base columnar files. In the example, the delta log files hold all the data written by commits completed from 10:05 to 10:10.
-
The base columnar files are versioned with the compaction (commit action). Thus, if one were to simply look at base files alone, then the table layout looks exactly like a copy on write table.
-
A periodic compaction process reconciles these changes from the delta log and produces a new version of base file, just like what happened at 10:05 in the example.
-
There are two ways of querying the same underlying table: Read Optimized query and Snapshot query, depending on whether we chose query performance or freshness of data.
-
The semantics around when data from a commit is available to a query changes in a subtle way for a read optimized query. Note, that such a query running at 10:10, wont see data after 10:05 above, while a snapshot query always sees the freshest data. So, it's important to align this with how you choose to compact the table.
-
When we trigger compaction & what it decides to compact hold all the key to solving these hard problems. By implementing a compacting strategy, where we aggressively compact the latest partitions compared to older partitions, we could ensure the read optimized queries see data published within X minutes in a consistent fashion.
The intention of merge on read table is to enable near real-time processing directly on top of DFS, as opposed to copying data out to specialized systems, which may not be able to handle the data volume. There are also a few secondary side benefits to this table such as reduced write amplification by avoiding synchronous merge of data, i.e, the amount of data written per 1 bytes of data in a batch
MoR tables are a great fit for the following use-cases:
-
Change Data Capture Pipelines: Combined with the right index selection, MoR tables provide industry-leading performance that keep up with change capture streams from the most demanding write patterns in upstream RBDMS or NoSQL stores.
-
Streaming Data Ingestion: MoR tables do a great job at landing data as quickly as possible into row-oriented formats, while still leveraging async background compaction to batch convert them into columnar formats (e.g Hudi Kafka Connect Sink/Flink integrations). This ensures great data freshness as well better compression ratio and thus excellent query performance for columnar files longer term.
-
Hybrid Batch + Streaming workloads: MoR tables can bring latencies down to minute-levels often eliminating the need for specialized streaming storage, Serving both low-latency operational queries and batch analytics on the same dataset. Also, given the streaming-friendly nature of MoR (think of a delta log as reading from a Kafka segment) some of the existing stream processing jobs can be run more cost-effectively on Hudi source/sink tables versus Kafka.
-
Frequent Updates and Deletes: Tables with high-frequency updates, such as user activity logs, transaction tracking, payment consolidation or inventory tracking can all benefit from MoR tables. Similarly, enforcing compliance programmes like GDPR/CCPA which require data deletion, can benefit from MoR's ability to accumulate deletes trickling in through the day and later do one compaction to amortize the cost of rewriting base files, lowering overall costs 10x or even more.
Comparison
Following table summarizes the trade-offs between these two table types at a high-level.
| Trade-off | Copy-On-Write | Merge-On-Read |
|---|---|---|
| Write Latency | Higher | Lower |
| Query Latency | Lower | Higher |
| Update cost | Higher (rewrite entire base files) | Lower (append to delta log) |
| Base File Size | Needs to be smaller to avoid high update(I/0) cost | Can be larger, since update cost is low and amortized |
| Read Amplification | 0 | For file groups read by queries: O(records_changed) |
| Write Amplification | Highest for given update/delete pattern, O(file_groups_written) | For file groups written: O(records_changed) |
Here, read amplification is defined as number of bytes read for 1 byte of actual data and write amplification is defined as number of bytes written into storage for every 1 byte of actual change data.
Query types
Hudi supports the following query types.
-
Snapshot Queries : Queries see the latest snapshot of the table as of the latest completed action. These are the regular SQL queries everyone is used to running on a table. Hudi storage engine accelerates these snapshot queries with indexes whenever possible, on supported query engines.
-
Time Travel Queries : Queries a snapshot of a table as of a given instant in the past. Time-Travel queries help access multiple versions of a table (for e.g. Machine learning feature stores, to score algorithms/models on exact data used to train them) on instants in the active timeline or savepoints in the past.
-
Read Optimized Queries (Only MoR tables) : Read-optimized queries provides excellent snapshot query performance via purely columnar files (e.g. Parquet base files). Users typically use a compaction strategy that aligns with a transaction boundary, to provide older consistent views of table/partitions. This is useful to integrate Hudi tables from data warehouses that typically only query columnar base files as external tables or latency insensitive ML/AI training jobs that favor efficiency over data freshness.
-
Incremental Queries (Latest State) : Incremental queries only return new data written to the table since an instant on the timeline. Provides latest value of records inserted/updated (i.e 1 record output by query for each record key), since a given point in time of the table. Can be used to "diff" table states between two points in time.
-
Incremental Queries(CDC) : These are another type of incremental queries, that provides database like change data capture streams out of Hudi tables. Output of a CDC query contain records inserted or updated or deleted since a point in time or between two points in time with both before and after images for each change record, along with operations that caused the change.
Following table summarizes the trade-offs between the Snapshot and Read Optimized query types.
| Trade-off | Snapshot | Read Optimized |
|---|---|---|
| Data Latency | Lower | Higher |
| Query Latency | Higher (merge base / columnar file + row based delta / log files) | Lower (raw base / columnar file performance) |
Incremental Queries
For users new to streaming systems or change data capture, this section provides a small example to put incremental queries into perspective. When employed correctly to data pipelines, these queries have the power to dramatically lower costs and increase efficiency many folds.
To do this, we take a Hudi table storing orders with hourly partitions denoting that hour the order was placed. The table is continuously
getting updates from an upstream source.
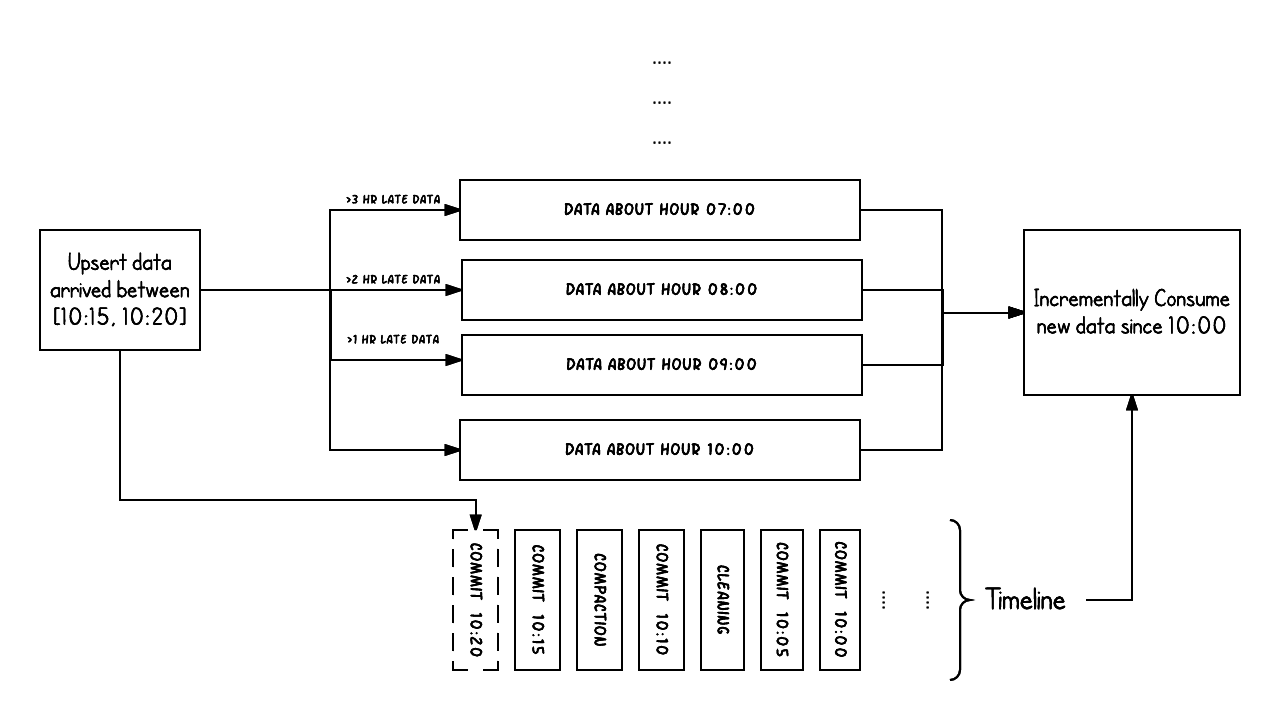
Example above shows upserts happenings between 10:00 and 10:20 on a Hudi table, roughly every 5 mins, leaving commit metadata on the Hudi timeline, along
with other background cleaning/compactions. Two key concepts in the streaming world beyond batch processing
are easily understood based on this simple example. When there is late arriving data (orders created for hour 9:00 updated/inserted >1 hr late at 10:20), we can see the upsert
producing new data into older hourly partitions. The commit instant in the timeline indicates the arrival time of the data (10:20 AM), while the actual data organization
reflects the actual time value the record belongs to or event time, the data was intended for (hourly buckets from 09:00).
Knowing what records have changed across both event and arrival time helps author very efficient incremental processing pipelines. With the help of the timeline and record level metadata, an incremental query attempting to get all new data that was committed successfully since 10:00 hours, is able to very efficiently consume only the changed records without say scanning all the time buckets > 07:00, which is typical approach in batch ETL jobs/sql. Further, it lets easy filtering based on event time using regular filters (e.g. where hourly_partition='09').
For configs related to query types refer below.
Query configs
Following are the configs relevant to different query types.
Spark configs
| Config Name | Default | Description |
|---|---|---|
| hoodie.datasource.query.type | snapshot (Optional) | Whether data needs to be read, in incremental mode (new data since an instantTime) (or) read_optimized mode (obtain latest view, based on base files) (or) snapshot mode (obtain latest view, by merging base and (if any) log files)Config Param: QUERY_TYPE |
| hoodie.datasource.read.begin.instanttime | N/A (Required) | Required when hoodie.datasource.query.type is set to incremental. Represents the instant time to start incrementally pulling data from. The instanttime here need not necessarily correspond to an instant on the timeline. New data written with an instant_time > BEGIN_INSTANTTIME are fetched out. For e.g: ‘20170901080000’ will get all new data written after Sep 1, 2017 08:00AM. Note that if hoodie.datasource.read.handle.hollow.commit set to USE_STATE_TRANSITION_TIME, will use instant's stateTransitionTime to perform comparison. Accepted formats: yyyyMMddHHmmss[SSS], yyyy-MM-dd, yyyy-MM-dd HH:mm:ss[.SSS], yyyy-MM-ddTHH:mm:ss[.SSS], epoch seconds (10-digit), epoch millis (13-digit), or earliest. Invalid values throw an error immediately.Config Param: BEGIN_INSTANTTIME |
| hoodie.datasource.read.end.instanttime | N/A (Required) | Used when hoodie.datasource.query.type is set to incremental. Represents the instant time to limit incrementally fetched data to. When not specified latest commit time from timeline is assumed by default. When specified, new data written with an instant_time <= END_INSTANTTIME are fetched out. Point in time type queries make more sense with begin and end instant times specified. Note that if hoodie.datasource.read.handle.hollow.commit set to USE_STATE_TRANSITION_TIME, will use instant's stateTransitionTime to perform comparison. Accepted formats: yyyyMMddHHmmss[SSS], yyyy-MM-dd, yyyy-MM-dd HH:mm:ss[.SSS], yyyy-MM-ddTHH:mm:ss[.SSS], epoch seconds (10-digit), epoch millis (13-digit), or earliest. Invalid values throw an error immediately.Config Param: END_INSTANTTIME |
| hoodie.datasource.query.incremental.format | latest_state (Optional) | This config is used alone with the 'incremental' query type.When set to latest_state, it returns the latest records' values. When set to cdc, it returns the cdc data.Config Param: INCREMENTAL_FORMATSince Version: 0.13.0 |
| as.of.instant | N/A (Required) | The query instant for time travel. Required only in the context of time travel queries. If not specified, query will return the latest snapshot. Accepted formats: yyyyMMddHHmmss[SSS], yyyy-MM-dd, yyyy-MM-dd HH:mm:ss[.SSS], yyyy-MM-ddTHH:mm:ss[.SSS], epoch seconds (10-digit), epoch millis (13-digit). Invalid values throw an error immediately.Config Param: TIME_TRAVEL_AS_OF_INSTANT |
Refer here for more details
Flink Configs
| Config Name | Default | Description |
|---|---|---|
| hoodie.datasource.query.type | snapshot (Optional) | Decides how data files need to be read, in 1) Snapshot mode (obtain latest view, based on row & columnar data); 2) incremental mode (new data since an instantTime). If cdc.enabled is set incremental queries on cdc data are possible; 3) Read Optimized mode (obtain latest view, based on columnar data) .Default: snapshotConfig Param: QUERY_TYPE |
| read.start-commit | N/A (Required) | Required in case of incremental queries. Start commit instant for reading, the commit time format should be 'yyyyMMddHHmmss', by default reading from the latest instant for streaming readConfig Param: READ_START_COMMIT |
| read.end-commit | N/A (Required) | Used in the context of incremental queries. End commit instant for reading, the commit time format should be 'yyyyMMddHHmmss'Config Param: READ_END_COMMIT |
Refer here for more details.