Hudi Z-Order and Hilbert Space Filling Curves
As of Hudi v0.10.0, we are excited to introduce support for an advanced Data Layout Optimization technique known in the database realm as Z-order and Hilbert space filling curves.
Background
Amazon EMR team recently published a great article show-casing how clustering your data can improve your query performance.
To better understand what's going on and how it's related to space-filling curves, let's zoom in to the setup in that article:
In the article, 2 Apache Hudi tables are compared (both ingested from the well-known Amazon Reviews dataset):
amazon_reviewstable which is not clustered (ie the data has not been re-ordered by any particular key)amazon_reviews_clusteredtable which is clustered. When data is clustered by Apache Hudi the data is lexicographically ordered (hereon we will be referring to this kind of ordering as linear ordering) by 2 columns:star_rating,total_votes(see screenshot below)

Screenshot of the Hudi configuration (from Amazon EMR team article)
To showcase the improvement in querying performance, the following queries are executed against both of these tables:


Screenshots of the queries run against the previously setup tables (from Amazon EMR team article)
The important consideration to point out here is that the queries were specifying both of the columns latter table is ordered by (both star_rating and total_votes).
And this is unfortunately a crucial limitation of the linear/lexicographic ordering, the value of the ordering diminishes very quickly as you add more columns. It's not hard to see why:
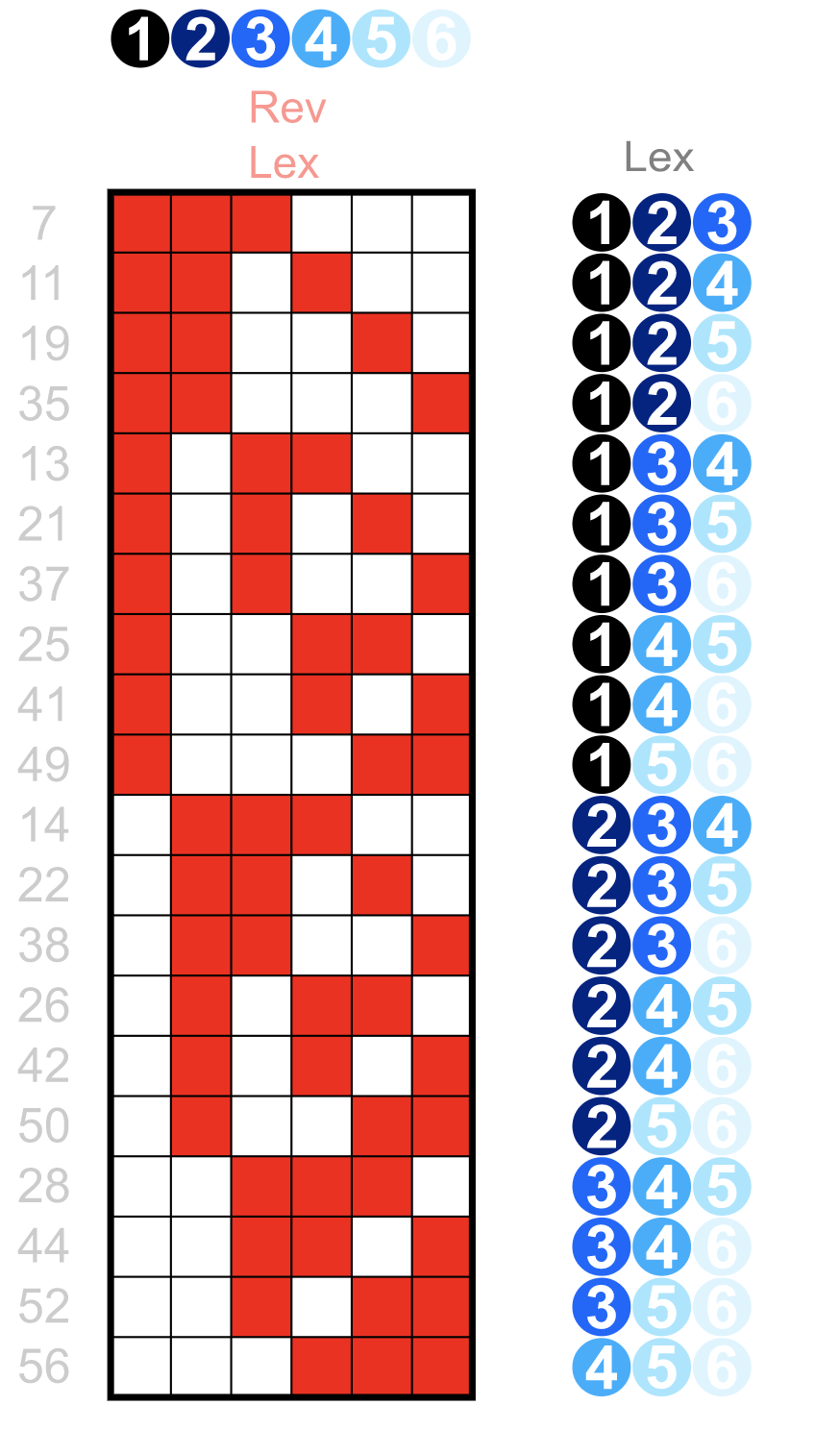
Courtesy of Wikipedia, Lexicographic Order article
From this image you can see that with lexicographically ordered 3-tuples of integers, only the first column is able to feature crucial property of locality for all of the records having the same value: for ex, all of the records wit values starting with "1", "2", "3" (in the first columns) are nicely clumped together. However if you try to find all the values that have "5" as the value in their third column you'd see that those are now dispersed all over the place, not being localized at all.
The crucial property that improves query performance is locality: it enables queries to substantially reduce the search space and the number of files that need to be scanned, parsed, etc.
But... does this mean that our queries are doomed to do a full-scan if we're filtering by anything other than the first (or more accurate would be to say prefix) of the list of columns the table is ordered by?
Not exactly: luckily, locality is also a property that space-filling curves enable while enumerating multi-dimensional spaces (records in our table could be represented as points in N-dimensional space, where N is the number of columns in our table)
How does it work?
Let's take Z-curve as an example: Z-order curves fitting a 2-dimensional plane would look like the following:
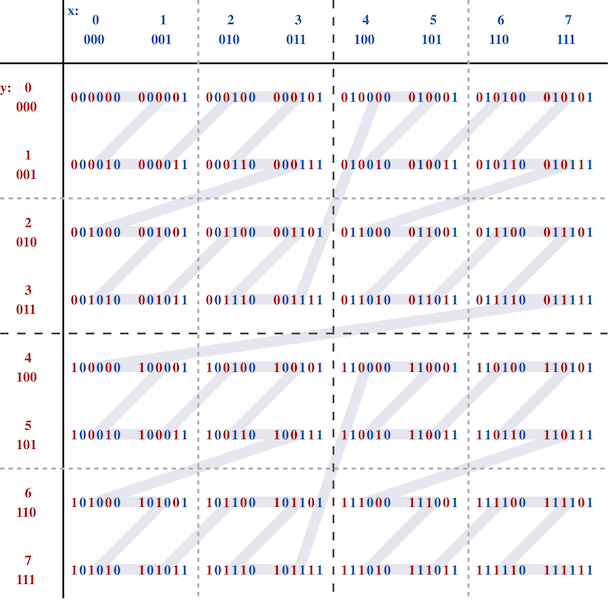
Courtesy of Wikipedia, Z-order curve article
As you can see following its path, instead of simply ordering by one coordinate ("x") first, following with the other, it's actually ordering them as if the bits of those coordinates have been interwoven into a single value:
| Coordinate | X (binary) | Y (binary) | Z-values (ordered) |
|---|---|---|---|
| (0, 0) | 000 | 000 | 000000 |
| (1, 0) | 001 | 000 | 000001 |
| (0, 1) | 000 | 001 | 000010 |
| (1, 1) | 001 | 001 | 000011 |
This allows for that crucial property of locality (even though a slightly "stretched" one) to be carried over to all columns as compared to just the first one in case of linear ordering.
In a similar fashion, Hilbert curves also allow you to map points in a N-dimensional space (rows in our table) onto 1-dimensional curve, essentially ordering them, while still preserving the crucial property of locality. Read more details about Hilbert Curves here. Our personal experiments so far show that ordering data along a Hilbert curve leads to better clustering and performance outcomes.
Now, let's check it out in action!
Setup
We will use the Amazon Reviews dataset again, but this time we will use Hudi to Z-Order by product_id, customer_id columns tuple instead of Clustering or linear ordering.
No special preparations are required for the dataset, you can simply download it from S3 in Parquet format and use it directly as an input for Spark ingesting it into Hudi table.
Launch Spark Shell
./bin/spark-shell --master 'local[4]' --driver-memory 8G --executor-memory 8G \
--jars ../../packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.10.0.jar \
--packages org.apache.spark:spark-avro_2.12:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Paste
import org.apache.hadoop.fs.{FileStatus, Path}
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.common.fs.FSUtils
import org.apache.hudi.common.table.HoodieTableMetaClient
import org.apache.hudi.common.util.ClusteringUtils
import org.apache.hudi.config.HoodieClusteringConfig
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.DataFrame
import java.util.stream.Collectors
val layoutOptStrategy = "z-order"; // OR "hilbert"
val inputPath = s"file:///${System.getProperty("user.home")}/datasets/amazon_reviews_parquet"
val tableName = s"amazon_reviews_${layoutOptStrategy}"
val outputPath = s"file:///tmp/hudi/$tableName"
def safeTableName(s: String) = s.replace('-', '_')
val commonOpts =
Map(
"hoodie.compact.inline" -> "false",
"hoodie.bulk_insert.shuffle.parallelism" -> "10"
)
////////////////////////////////////////////////////////////////
// Writing to Hudi
////////////////////////////////////////////////////////////////
val df = spark.read.parquet(inputPath)
df.write.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL)
.option("hoodie.table.name", tableName)
.option(PRECOMBINE_FIELD.key(), "review_id")
.option(RECORDKEY_FIELD.key(), "review_id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD.key(), "product_category")
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
// NOTE: Small file limit is intentionally kept _ABOVE_ target file-size max threshold for Clustering,
// to force re-clustering
.option("hoodie.clustering.plan.strategy.small.file.limit", String.valueOf(1024 * 1024 * 1024)) // 1Gb
.option("hoodie.clustering.plan.strategy.target.file.max.bytes", String.valueOf(128 * 1024 * 1024)) // 128Mb
// NOTE: We're increasing cap on number of file-groups produced as part of the Clustering run to be able to accommodate for the
// whole dataset (~33Gb)
.option("hoodie.clustering.plan.strategy.max.num.groups", String.valueOf(4096))
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_ENABLE.key, "true")
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_STRATEGY.key, layoutOptStrategy)
.option(HoodieClusteringConfig.PLAN_STRATEGY_SORT_COLUMNS.key, "product_id,customer_id")
.option(DataSourceWriteOptions.OPERATION.key(), DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)
.option(BULK_INSERT_SORT_MODE.key(), "NONE")
.options(commonOpts)
.mode(ErrorIfExists)
Testing
Please keep in mind, that each individual test is run in a separate spark-shell to avoid caching getting in the way of our measurements.
////////////////////////////////////////////////////////////////
// Reading
///////////////////////////////////////////////////////////////
// Temp Table w/ Data Skipping DISABLED
val readDf: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "false").format("hudi").load(outputPath)
val rawSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot")
readDf.createOrReplaceTempView(rawSnapshotTableName)
// Temp Table w/ Data Skipping ENABLED
val readDfSkip: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "true").format("hudi").load(outputPath)
val dataSkippingSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot_skipping")
readDfSkip.createOrReplaceTempView(dataSkippingSnapshotTableName)
// Query 1: Total votes by product_category, for 6 months
def runQuery1(tableName: String) = {
// Query 1: Total votes by product_category, for 6 months
spark.sql(s"SELECT sum(total_votes), product_category FROM $tableName WHERE review_date > '2013-12-15' AND review_date < '2014-06-01' GROUP BY product_category").show()
}
// Query 2: Average star rating by product_id, for some product
def runQuery2(tableName: String) = {
spark.sql(s"SELECT avg(star_rating), product_id FROM $tableName WHERE product_id in ('B0184XC75U') GROUP BY product_id").show()
}
// Query 3: Count number of reviews by customer_id for some 5 customers
def runQuery3(tableName: String) = {
spark.sql(s"SELECT count(*) as num_reviews, customer_id FROM $tableName WHERE customer_id in ('53096570','10046284','53096576','10000196','21700145') GROUP BY customer_id").show()
}
//
// Query 1: Is a "wide" query and hence it's expected to touch a lot of files
//
scala> runQuery1(rawSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
scala> runQuery1(dataSkippingSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
//
// Query 2: Is a "pointwise" query and hence it's expected that data-skipping should substantially reduce number
// of files scanned (as compared to Baseline)
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will have similar effect on performance reducing
// total # of Parquet files scanned, since we're querying on the prefix of the ordering key
//
scala> runQuery2(rawSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
scala> runQuery2(dataSkippingSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
//
// Query 3: Similar to Q2, is a "pointwise" query, but querying other part of the ordering-key (product_id, customer_id)
// and hence it's expected that data-skipping should substantially reduce number of files scanned (as compared to Baseline, Linear Ordering).
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will _NOT_ have similar effect on performance reducing
// total # of Parquet files scanned, since we're NOT querying on the prefix of the ordering key
//
scala> runQuery3(rawSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+
scala> runQuery3(dataSkippingSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+
Results
We've summarized the measured performance metrics below:
| Query | Baseline (B) duration (files scanned / size) | Linear Sorting (S) | Z-order (Z) duration (scanned) | Hilbert (H) duration (scanned) |
|---|---|---|---|---|
| Q1 | 14s (543 / 31.4Gb) | 15s (533 / 28.8Gb) | 15s (543 / 31.4Gb) | 14s (541 / 31.3Gb) |
| Q2 | 21s (543 / 31.4Gb) | 10s (533 / 28.8Gb) | 8s (243 / 14.4Gb) | 7s (237 / 13.9Gb) |
| Q3 | 17s (543 / 31.4Gb) | 15s (533 / 28.8Gb) | 6s (224 / 12.4Gb) | 6s (219 / 11.9Gb) |
As you can see multi-column linear ordering is not very effective for the queries that do filtering by columns other than the first one (Q2, Q3).
Which is a very clear contrast with space-filling curves (both Z-order and Hilbert) that allow to speed up query time by up to 3x!
It's worth noting that the performance gains are heavily dependent on your underlying data and queries. In benchmarks on our internal data we were able to achieve queries performance improvements of more than 11x!
Epilogue
Apache Hudi v0.10 brings new layout optimization capabilities Z-order and Hilbert to open source. Using these industry leading layout optimization techniques can bring substantial performance improvement and cost savings to your queries!