Clustering
Background
Apache Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing. In a data lake/warehouse, one of the key trade-offs is between ingestion speed and query performance. Data ingestion typically prefers small files to improve parallelism and make data available to queries as soon as possible. However, query performance degrades poorly with a lot of small files. Also, during ingestion, data is typically co-located based on arrival time. However, the query engines perform better when the data frequently queried is co-located together. In most architectures each of these systems tend to add optimizations independently to improve performance which hits limitations due to un-optimized data layouts. This doc introduces a new kind of table service called clustering [RFC-19] to reorganize data for improved query performance without compromising on ingestion speed.
How is compaction different from clustering?
Hudi is modeled like a log-structured storage engine with multiple versions of the data. Particularly, Merge-on-Read tables in Hudi store data using a combination of base file in columnar format and row-based delta logs that contain updates. Compaction is a way to merge the delta logs with base files to produce the latest file slices with the most recent snapshot of data. Compaction helps to keep the query performance in check (larger delta log files would incur longer merge times on query side). On the other hand, clustering is a data layout optimization technique. One can stitch together small files into larger files using clustering. Additionally, data can be clustered by sort key so that queries can take advantage of data locality.
Clustering Architecture
At a high level, Hudi provides different operations such as insert/upsert/bulk_insert through it’s write client API to be able to write data to a Hudi table. To be able to choose a trade-off between file size and ingestion speed, Hudi provides a knob hoodie.parquet.small.file.limit to be able to configure the smallest allowable file size. Users are able to configure the small file soft limit to 0 to force new data to go into a new set of filegroups or set it to a higher value to ensure new data gets “padded” to existing files until it meets that limit that adds to ingestion latencies.
To be able to support an architecture that allows for fast ingestion without compromising query performance, we have introduced a ‘clustering’ service to rewrite the data to optimize Hudi data lake file layout.
Clustering table service can run asynchronously or synchronously adding a new action type called “REPLACE”, that will mark the clustering action in the Hudi metadata timeline.
Overall, there are 2 steps to clustering
- Scheduling clustering: Create a clustering plan using a pluggable clustering strategy.
- Execute clustering: Process the plan using an execution strategy to create new files and replace old files.
Schedule clustering
Following steps are followed to schedule clustering.
- Identify files that are eligible for clustering: Depending on the clustering strategy chosen, the scheduling logic will identify the files eligible for clustering.
- Group files that are eligible for clustering based on specific criteria. Each group is expected to have data size in multiples of 'targetFileSize'. Grouping is done as part of 'strategy' defined in the plan. Additionally, there is an option to put a cap on group size to improve parallelism and avoid shuffling large amounts of data.
- Finally, the clustering plan is saved to the timeline in an avro metadata format.
Incremental Scheduling
Hudi supports incremental scheduling for clustering operations, which significantly improves performance on tables with a large number of partitions. Instead of scanning all partitions during each clustering scheduling run, incremental scheduling only processes partitions that have changed since the last completed clustering operation.
This feature is enabled by default via hoodie.table.services.incremental.enabled. When enabled, clustering scheduling will:
- Identify partitions that have been modified since the last completed clustering operation by analyzing commit metadata within the time window between the last completed clustering and the current scheduling instant
- Include any partitions that were marked as missing from previous scheduling runs (e.g., due to IO limits or group size restrictions)
- Only scan and process those incremental partitions
- Fall back to scanning all partitions if the last completed clustering instant cannot be found (e.g., due to archival) or if an exception occurs during incremental partition retrieval
For tables with many partitions, this optimization can dramatically reduce scheduling overhead and improve overall job stability.
Execute clustering
- Read the clustering plan and get the ‘clusteringGroups’ that mark the file groups that need to be clustered.
- For each group, we instantiate appropriate strategy class with strategyParams (example: sortColumns) and apply that strategy to rewrite the data.
- Create a “REPLACE” commit and update the metadata in HoodieReplaceCommitMetadata.
Clustering Service builds on Hudi’s MVCC based design to allow for writers to continue to insert new data while clustering action runs in the background to reformat data layout, ensuring snapshot isolation between concurrent readers and writers.
NOTE: Clustering can only be scheduled for tables / partitions not receiving any concurrent updates. In the future, concurrent updates use-case will be supported as well.
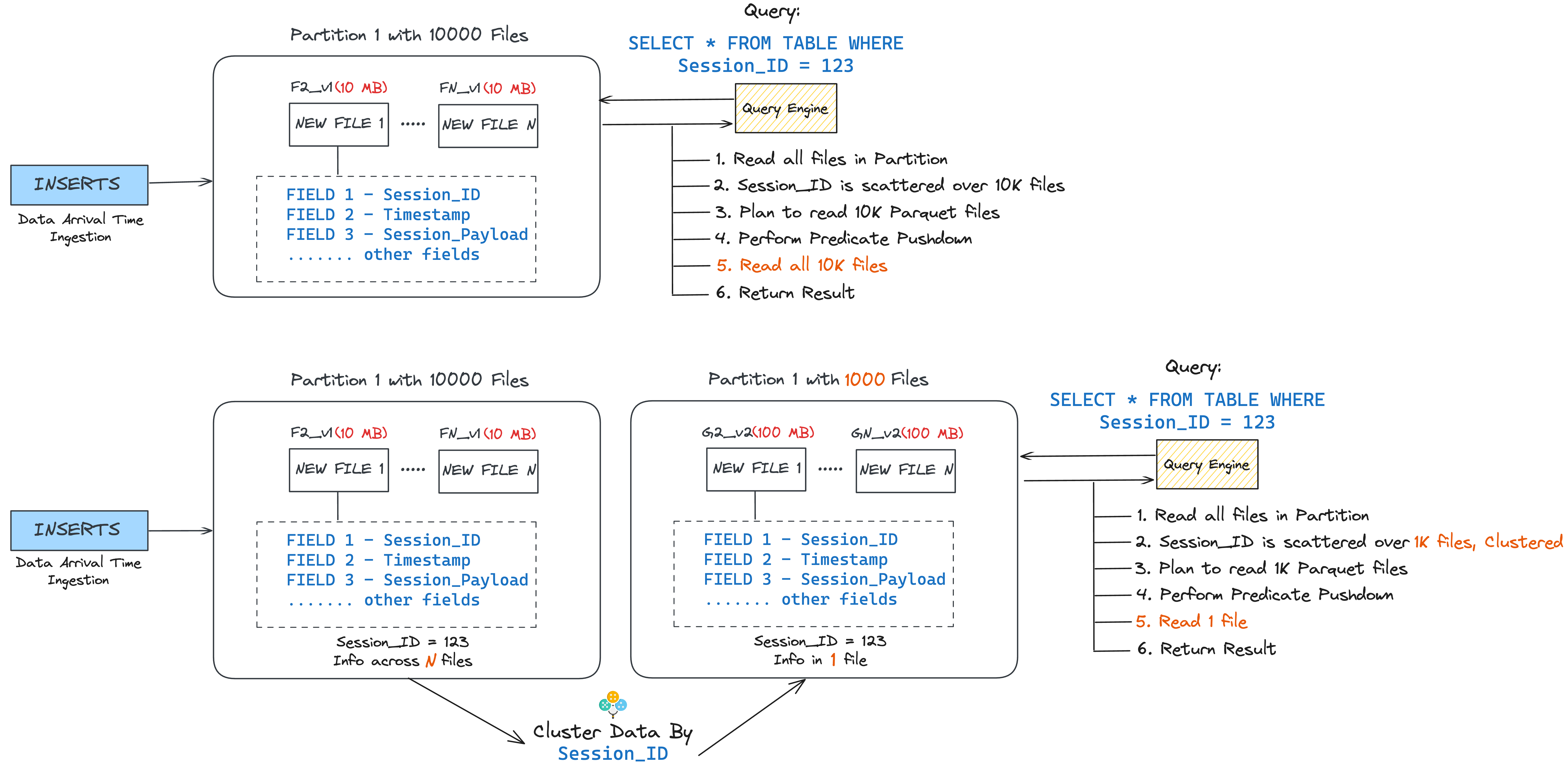 Figure: Illustrating query performance improvements by clustering
Figure: Illustrating query performance improvements by clustering
Clustering Usecases
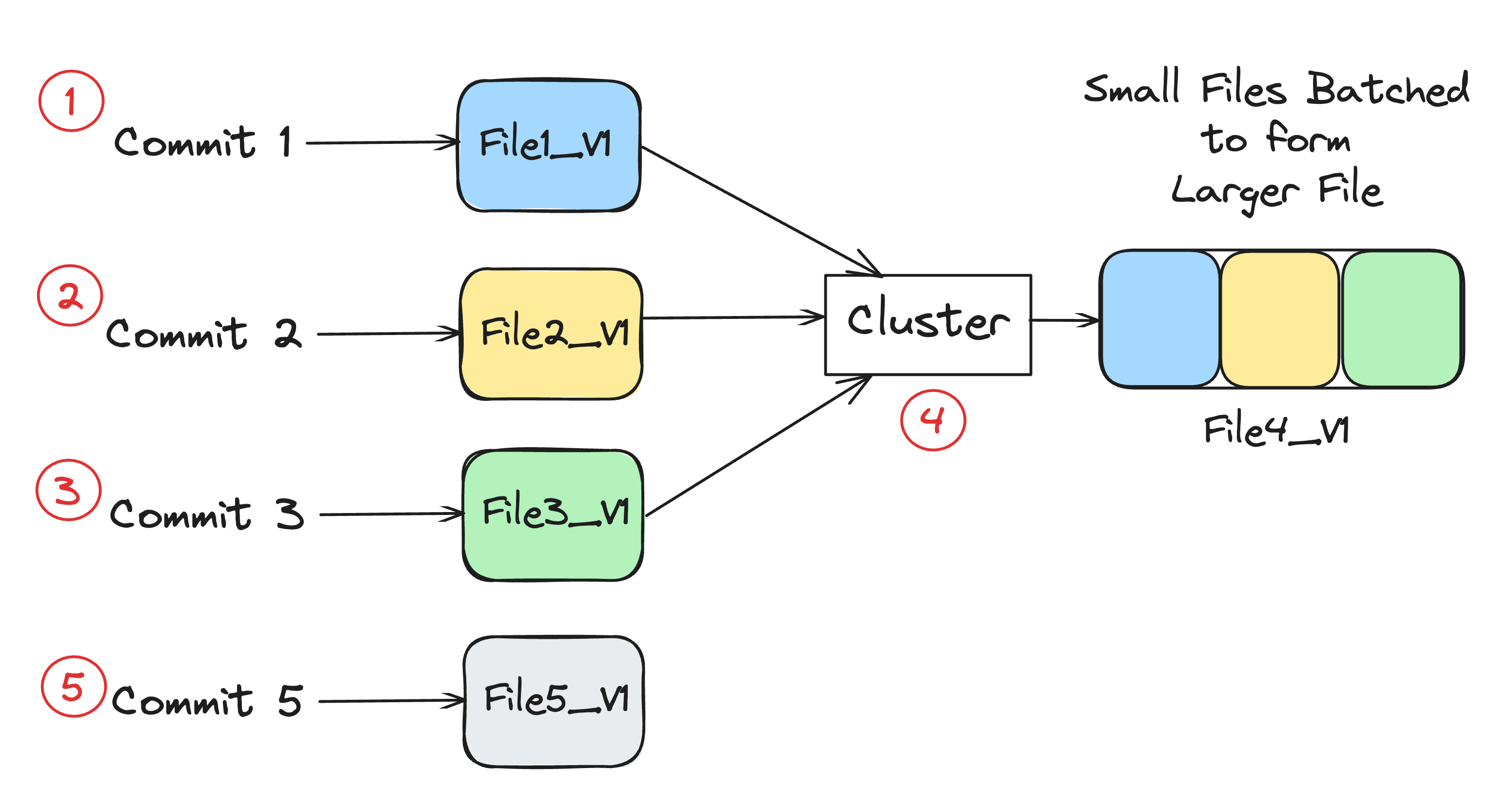
Batching small files
As mentioned in the intro, streaming ingestion generally results in smaller files in your data lake. But having a lot of such small files could lead to higher query latency. From our experience supporting community users, there are quite a few users who are using Hudi just for small file handling capabilities. So, you could employ clustering to batch a lot of such small files into larger ones.
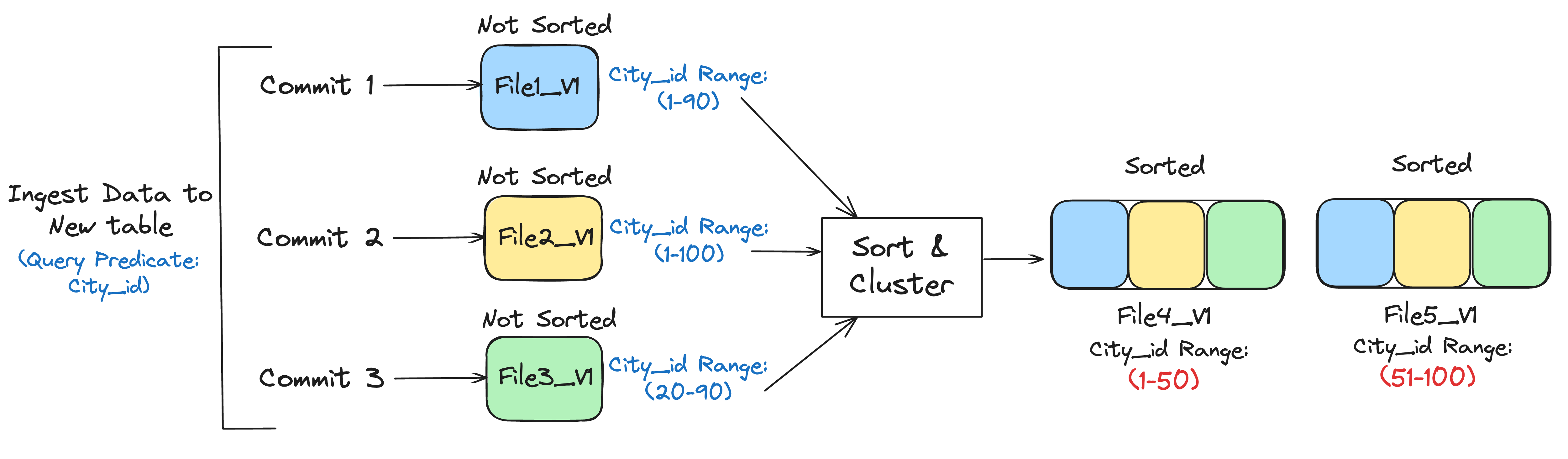
Cluster by sort key
Another classic problem in data lake is the arrival time vs event time problem. Generally you write data based on arrival time, while query predicates do not sit well with it. With clustering, you can re-write your data by sorting based on query predicates and so, your data skipping will be very efficient and your query can ignore scanning a lot of unnecessary data.
Clustering Strategies
On a high level, clustering creates a plan based on a configurable strategy, groups eligible files based on specific criteria and then executes the plan. As mentioned before, clustering plan as well as execution depends on configurable strategy. These strategies can be broadly classified into three types: clustering plan strategy, execution strategy and update strategy.
Plan Strategy
This strategy comes into play while creating clustering plan. It helps to decide what file groups should be clustered and how many output file groups should the clustering produce. Note that these strategies are easily pluggable using the config hoodie.clustering.plan.strategy.class.
Different plan strategies are as follows:
Size-based clustering strategies
This strategy creates clustering groups based on max size allowed per group. Also, it excludes files that are greater
than the small file limit from the clustering plan. Available strategies depending on write client
are: SparkSizeBasedClusteringPlanStrategy, FlinkSizeBasedClusteringPlanStrategy
and JavaSizeBasedClusteringPlanStrategy. Furthermore, Hudi provides flexibility to include or exclude partitions for
clustering, tune the file size limits, maximum number of output groups. Please refer to hoodie.clustering.plan.strategy.small.file.limit
, hoodie.clustering.plan.strategy.max.num.groups, hoodie.clustering.plan.strategy.max.bytes.per.group
, hoodie.clustering.plan.strategy.target.file.max.bytes for more details.
| Config Name | Default | Description |
|---|---|---|
| hoodie.clustering.plan.strategy.partition.selected | N/A (Required) | Comma separated list of partitions to run clusteringConfig Param: PARTITION_SELECTEDSince Version: 0.11.0 |
| hoodie.clustering.plan.strategy.partition.regex.pattern | N/A (Required) | Filter clustering partitions that matched regex patternConfig Param: PARTITION_REGEX_PATTERNSince Version: 0.11.0 |
| hoodie.clustering.plan.partition.filter.mode | NONE (Optional) | Partition filter mode used in the creation of clustering plan. Possible values:
Config Param: PLAN_PARTITION_FILTER_MODE_NAMESince Version: 0.11.0 |
SparkSingleFileSortPlanStrategy
In this strategy, clustering group for each partition is built in the same way as SparkSizeBasedClusteringPlanStrategy
. The difference is that the output group is 1 and file group id remains the same,
while SparkSizeBasedClusteringPlanStrategy can create multiple file groups with newer fileIds.
SparkConsistentBucketClusteringPlanStrategy
This strategy is specifically used for consistent bucket index. This will be leveraged to expand your bucket index (from static partitioning to dynamic). Typically, users don’t need to use this strategy. Hudi internally uses this for dynamically expanding the buckets for bucket index datasets.
CommitBasedClusteringPlanStrategy
Hudi 1.2.0 introduced org.apache.hudi.table.action.cluster.strategy.CommitBasedClusteringPlanStrategy, a plan
strategy that schedules clustering based on commit patterns rather than just file size. It groups file slices by the
commits that produced them, making it easier to cluster data written in specific time windows or under specific commit
criteria.
| Config Name | Default | Description |
|---|---|---|
hoodie.clustering.plan.strategy.class | SparkSizeBasedClusteringPlanStrategy | Set to org.apache.hudi.table.action.cluster.strategy.CommitBasedClusteringPlanStrategy to use commit-based planning. |
hoodie.clustering.plan.strategy.earliest.commit.to.cluster | (none) | Earliest commit time (exclusive) to start clustering from. Only commits after this instant are considered. Useful for incrementally clustering new data while skipping already-clustered history. |
SparkStreamCopyClusteringPlanStrategy
Available since Hudi 1.2.0, org.apache.hudi.client.clustering.plan.strategy.SparkStreamCopyClusteringPlanStrategy
is a Spark-only plan strategy that performs binary file stitching (byte-level copy) rather than re-reading and
re-writing records. This can be significantly faster when the goal is simply to coalesce small files and sort order is
not required. It is paired with
org.apache.hudi.client.clustering.run.strategy.SparkStreamCopyClusteringExecutionStrategy.
Single-Group Clustering Control
| Config Name | Default | Description |
|---|---|---|
hoodie.clustering.plan.strategy.single.group.clustering.enabled | true | Whether to generate a clustering plan when only one file group is eligible. Set to false to skip clustering when there is nothing meaningful to consolidate (i.e., the partition already has a single file group). |
File-Slice Sort Order in Clustering Plan Generation
Since 1.2.0, the order in which file slices are packed into clustering groups is configurable, giving more control over which files are colocated and how groups are filled.
| Config Name | Default | Description |
|---|---|---|
hoodie.clustering.plan.strategy.file.slices.sort.by | SIZE | Comma-separated list of fields used to sort file slices when packing them into clustering groups within a partition. SIZE: sort by file size descending (largest first). INSTANT_TIME: sort by commit time ascending (oldest files first). Example: INSTANT_TIME,SIZE sorts by commit time then by size. |
Driver-Side Plan Generation
| Config Name | Default | Description |
|---|---|---|
hoodie.clustering.plan.generation.use.local.engine.context | false | When enabled, clustering group computation runs on the driver (local engine context) instead of being distributed across executors. Enable when there are only a few partitions with many files, where driver-local computation is more resource-efficient than allocating executor slots. |
Execution Strategy
After building the clustering groups in the planning phase, Hudi applies execution strategy, for each group, primarily based on sort columns and size. The strategy can be specified using the config hoodie.clustering.execution.strategy.class. By default, Hudi sorts the file groups in the plan by the specified columns, while meeting the configured target file sizes.
| Config Name | Default | Description |
|---|---|---|
| hoodie.clustering.execution.strategy.class | org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy (Optional) | Config to provide a strategy class (subclass of RunClusteringStrategy) to define how the clustering plan is executed. By default, we sort the file groups in th plan by the specified columns, while meeting the configured target file sizes.Config Param: EXECUTION_STRATEGY_CLASS_NAMESince Version: 0.7.0 |
The available strategies are as follows:
SPARK_SORT_AND_SIZE_EXECUTION_STRATEGY: Uses bulk_insert to re-write data from input file groups.- Set
hoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy. hoodie.clustering.plan.strategy.sort.columns: Columns to sort the data while clustering. This goes in conjunction with layout optimization strategies depending on your query predicates. One can set comma separated list of columns that needs to be sorted in this config.
- Set
JAVA_SORT_AND_SIZE_EXECUTION_STRATEGY: Similar toSPARK_SORT_AND_SIZE_EXECUTION_STRATEGY, for the Java and Flink engines. Sethoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.JavaSortAndSizeExecutionStrategy.SPARK_CONSISTENT_BUCKET_EXECUTION_STRATEGY: As the name implies, this is applicable to dynamically expand consistent bucket index and only applicable to the Spark engine. Sethoodie.clustering.execution.strategy.classtoorg.apache.hudi.client.clustering.run.strategy.SparkConsistentBucketClusteringExecutionStrategy.
Update Strategy
Currently, clustering can only be scheduled for tables/partitions not receiving any concurrent updates. By default,
the config for update strategy - hoodie.clustering.updates.strategy is set to SparkRejectUpdateStrategy. If some file group has updates during clustering then it will reject updates and throw an
exception. However, in some use-cases updates are very sparse and do not touch most file groups. The default strategy to
simply reject updates does not seem fair. In such use-cases, users can set the config to SparkAllowUpdateStrategy.
We discussed the critical strategy configurations. All other configurations related to clustering are listed clustering configurations. Out of this list, a few configurations that will be very useful for inline or async clustering are shown below with code samples.
Inline clustering
Inline clustering happens synchronously with the regular ingestion writer or as part of the data ingestion pipeline. This means the next round of ingestion cannot proceed until the clustering is complete With inline clustering, Hudi will schedule, plan clustering operations after each commit is completed and execute the clustering plans after it’s created. This is the simplest deployment model to run because it’s easier to manage than running different asynchronous Spark jobs. This mode is supported on Spark Datasource, Flink, Spark-SQL and Hudi Streamer in a sync-once mode.
For this deployment mode, please enable and set: hoodie.clustering.inline
To choose how often clustering is triggered, also set: hoodie.clustering.inline.max.commits.
Inline clustering can be setup easily using spark dataframe options. See sample below:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val df = //generate data frame
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option("hoodie.table.ordering.fields", "ts").
option("hoodie.datasource.write.recordkey.field", "uuid").
option("hoodie.datasource.write.partitionpath.field", "partitionpath").
option("hoodie.table.name", "tableName").
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "4").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "column1,column2"). //optional, if sorting is needed as part of rewriting data
mode(Append).
save("dfs://location");
Async Clustering
Async clustering runs the clustering table service in the background without blocking the regular ingestions writers. There are three different ways to deploy an asynchronous clustering process:
- Asynchronous execution within the same process: In this deployment mode, Hudi will schedule and plan the clustering operations after each commit is completed as part of the ingestion pipeline. Separately, Hudi spins up another thread within the same job and executes the clustering table service. This is supported by Spark Streaming, Flink and Hudi Streamer in continuous mode. For this deployment mode, please enable
hoodie.clustering.async.enabledandhoodie.clustering.async.max.commits. - Asynchronous scheduling and execution by a separate process: In this deployment mode, the application will write data to a Hudi table as part of the ingestion pipeline. A separate clustering job will schedule, plan and execute the clustering operation. By running a different job for the clustering operation, it rebalances how Hudi uses compute resources: fewer compute resources are needed for the ingestion, which makes ingestion latency stable, and an independent set of compute resources are reserved for the clustering process. Please configure the lock providers for the concurrency control among all jobs (both writer and table service jobs). In general, configure lock providers when there are two different jobs or two different processes occurring. All writers support this deployment model. For this deployment mode, no clustering configs should be set for the ingestion writer.
- Scheduling inline and executing async: In this deployment mode, the application ingests data and schedules the clustering in one job; in another, the application executes the clustering plan. The supported writers (see below) won’t be blocked from ingesting data. If the metadata table is enabled, a lock provider is not needed. However, if the metadata table is enabled, please ensure all jobs have the lock providers configured for concurrency control. All writers support this deployment option. For this deployment mode, please enable,
hoodie.clustering.schedule.inlineandhoodie.clustering.async.enabled.
Hudi supports multi-writers which provides snapshot isolation between multiple table services, thus allowing writers to continue with ingestion while clustering runs in the background.
| Config Name | Default | Description |
|---|---|---|
| hoodie.clustering.async.enabled | false (Optional) | Enable running of clustering service, asynchronously as inserts happen on the table.Config Param: ASYNC_CLUSTERING_ENABLESince Version: 0.7.0 |
| hoodie.clustering.async.max.commits | 4 (Optional) | Config to control frequency of async clusteringConfig Param: ASYNC_CLUSTERING_MAX_COMMITSSince Version: 0.9.0 |
Setup Asynchronous Clustering
Users can leverage HoodieClusteringJob to setup 2-step asynchronous clustering.
HoodieClusteringJob
By specifying the scheduleAndExecute mode both schedule as well as clustering can be achieved in the same step.
The appropriate mode can be specified using -mode or -m option. There are three modes:
schedule: Make a clustering plan. This gives an instant which can be passed in execute mode.execute: Execute a clustering plan at a particular instant. If no instant-time is specified, HoodieClusteringJob will execute for the earliest instant on the Hudi timeline.scheduleAndExecute: Make a clustering plan first and execute that plan immediately.
Available Options
In addition to the basic mode options, HoodieClusteringJob supports the following retry and timeout options (effective in scheduleAndExecute mode):
| Option Name | Short Flag | Default | Description |
|---|---|---|---|
--retry-last-failed-job | -rc | false | When set to true, checks, rolls back, and executes the last failed clustering plan instead of planning a new clustering job directly. This is useful for recovering from previous failures. |
--job-max-processing-time-ms | -jt | 0 | Maximum processing time in milliseconds before considering a clustering job as failed. If this time is exceeded and the job is still unfinished, Hudi will consider the job as failed and relaunch it (when used with --retry-last-failed-job). A value of 0 or negative disables the timeout check. |
These retry options are only effective when using --mode scheduleAndExecute. The --retry-last-failed-job option requires --job-max-processing-time-ms to be set to a positive value to detect stale inflight instants.
Automatic Expiration of Stale Clustering Instants
When a clustering job is scheduled but never successfully executed (e.g., due to a driver failure), the inflight
replacecommit instant blocks future clustering runs. Hudi 1.2.0 adds automatic expiration of such stale clustering
instants, complementing the manual retry options above.
Expired clustering plan cleanup requires hoodie.clean.failed.writes.policy=LAZY. With LAZY cleaning, the rollback of
failed writes (triggered on the next write) also rolls back expired clustering instants.
| Config Name | Default | Description |
|---|---|---|
hoodie.clustering.enable.expirations | false | When enabled, rollback of failed writes (under LAZY cleaning) also rolls back clustering replacecommit instants whose heartbeat has expired. Clustering jobs record a heartbeat before scheduling so other writers can detect stale attempts. |
hoodie.clustering.expiration.threshold.mins | 60 | A clustering instant is not considered expired unless its creation time is at least this many minutes old. Acts as a guardrail to avoid rolling back clustering attempts that are still in progress. |
Note that to run this job while the original writer is still running, please enable multi-writing:
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
A sample spark-submit command to setup HoodieClusteringJob is as below:
spark-submit \
--jars "packaging/hudi-utilities-slim-bundle/target/hudi-utilities-slim-bundle_2.12-1.2.0.jar,packaging/hudi-spark-bundle/target/hudi-spark3.5-bundle_2.12-1.2.0.jar" \
--class org.apache.hudi.utilities.HoodieClusteringJob \
/path/to/hudi-utilities-slim-bundle/target/hudi-utilities-slim-bundle_2.12-1.2.0.jar \
--props /path/to/config/clusteringjob.properties \
--mode scheduleAndExecute \
--base-path /path/to/hudi_table/basePath \
--table-name hudi_table_schedule_clustering \
--spark-memory 1g
A sample clusteringjob.properties file:
hoodie.clustering.async.enabled=true
hoodie.clustering.async.max.commits=4
hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
hoodie.clustering.plan.strategy.small.file.limit=629145600
hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
hoodie.clustering.plan.strategy.sort.columns=column1,column2
Hudi Streamer
This brings us to our users' favorite utility in Hudi. Now, we can trigger asynchronous clustering with Hudi Streamer.
Just set the hoodie.clustering.async.enabled config to true and specify other clustering config in properties file
whose location can be pased as —props when starting the Hudi Streamer (just like in the case of HoodieClusteringJob).
A sample spark-submit command to setup Hudi Streamer is as below:
spark-submit \
--jars "packaging/hudi-utilities-slim-bundle/target/hudi-utilities-slim-bundle_2.12-1.2.0.jar,packaging/hudi-spark-bundle/target/hudi-spark3.5-bundle_2.12-1.2.0.jar" \
--class org.apache.hudi.utilities.streamer.HoodieStreamer \
/path/to/hudi-utilities-slim-bundle/target/hudi-utilities-slim-bundle_2.12-1.2.0.jar \
--props /path/to/config/clustering_kafka.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--table-type COPY_ON_WRITE \
--target-base-path /path/to/hudi_table/basePath \
--target-table impressions_cow_cluster \
--op INSERT \
--hoodie-conf hoodie.clustering.async.enabled=true \
--continuous
Spark Structured Streaming
We can also enable asynchronous clustering with Spark structured streaming sink as shown below.
val commonOpts = Map(
"hoodie.insert.shuffle.parallelism" -> "4",
"hoodie.upsert.shuffle.parallelism" -> "4",
"hoodie.datasource.write.recordkey.field" -> "_row_key",
"hoodie.datasource.write.partitionpath.field" -> "partition",
"hoodie.table.ordering.fields" -> "timestamp",
"hoodie.table.name" -> "hoodie_test"
)
def getAsyncClusteringOpts(isAsyncClustering: String,
clusteringNumCommit: String,
executionStrategy: String):Map[String, String] = {
commonOpts + (DataSourceWriteOptions.ASYNC_CLUSTERING_ENABLE.key -> isAsyncClustering,
HoodieClusteringConfig.ASYNC_CLUSTERING_MAX_COMMITS.key -> clusteringNumCommit,
HoodieClusteringConfig.EXECUTION_STRATEGY_CLASS_NAME.key -> executionStrategy
)
}
def initStreamingWriteFuture(hudiOptions: Map[String, String]): Future[Unit] = {
val streamingInput = // define the source of streaming
Future {
println("streaming starting")
streamingInput
.writeStream
.format("org.apache.hudi")
.options(hudiOptions)
.option("checkpointLocation", basePath + "/checkpoint")
.mode(Append)
.start()
.awaitTermination(10000)
println("streaming ends")
}
}
def structuredStreamingWithClustering(): Unit = {
val df = //generate data frame
val hudiOptions = getClusteringOpts("true", "1", "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy")
val f1 = initStreamingWriteFuture(hudiOptions)
Await.result(f1, Duration.Inf)
}
Flink Offline Clustering
Offline clustering for Flink needs to be submitted as a Flink job on the command line. The program entry is in hudi-flink-bundle.jar: org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob
# Command line
./bin/flink run -c org.apache.hudi.sink.clustering.HoodieFlinkClusteringJob lib/hudi-flink-bundle.jar --path hdfs://xxx:9000/table
Options
| Option Name | Default | Description |
|---|---|---|
--path | n/a **(Required)** | The path where the target table is stored on Hudi |
--schedule | false (Optional) | Whether to execute the operation of scheduling clustering plan. When the write process is still writing, turning on this parameter has a risk of losing data. Therefore, it must be ensured that there are no write tasks currently writing data to this table when this parameter is turned on |
--service | false (Optional) | Whether to start a monitoring service that checks and schedules new clustering task in configured interval. |
--min-clustering-interval-seconds | 600(s) (optional) | The checking interval for service mode, by default 10 minutes. |
--retry | 0 (Optional) | Number of retries for clustering operation. Only effective in single-run mode (not service mode). Default is 0 (no retry). |
--retry-last-failed-job | false (Optional) | Check and retry last failed clustering job if the inflight instant exceeds max processing time. Only effective in single-run mode. Requires --job-max-processing-time-ms to be set to a positive value. |
--job-max-processing-time-ms | 0 (Optional) | Maximum processing time in milliseconds before considering a clustering job as failed. Used with --retry-last-failed-job. Default 0 means no timeout check. |
The retry options (--retry, --retry-last-failed-job, --job-max-processing-time-ms) are only effective in single-run mode, not in service mode. Service mode has implicit retry semantics via its continuous monitoring loop. A warning will be logged if --retry-last-failed-job is enabled but --job-max-processing-time-ms is not set to a positive value.
Java Client
Clustering is also supported via Java client. Plan strategy org.apache.hudi.client.clustering.plan.strategy.JavaSizeBasedClusteringPlanStrategy
and execution strategy org.apache.hudi.client.clustering.run.strategy.JavaSortAndSizeExecutionStrategy are supported
out-of-the-box. Note that as of now only linear sort is supported in Java execution strategy.