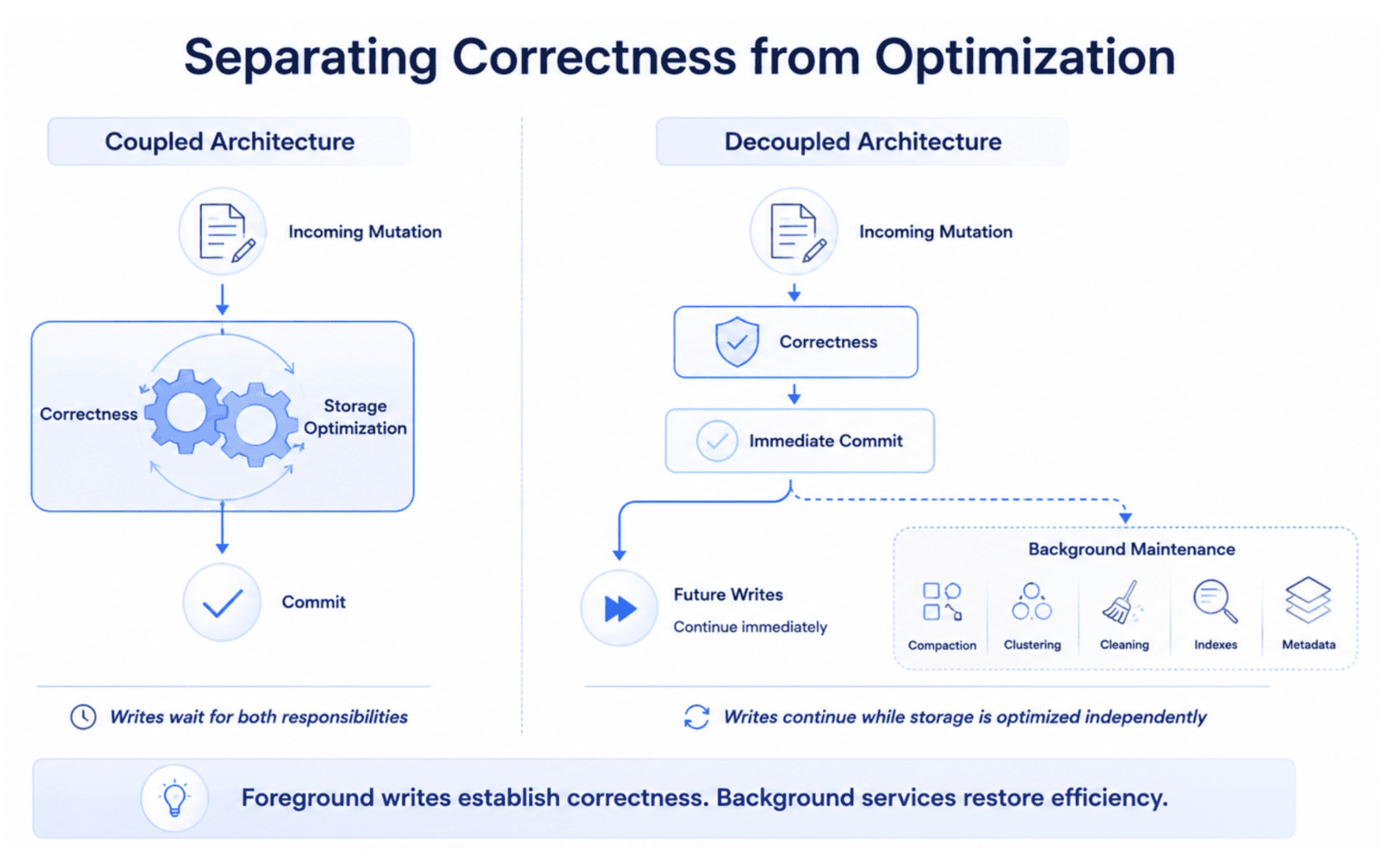
Can a Lakehouse Really Run Maintenance Without Blocking Writes?
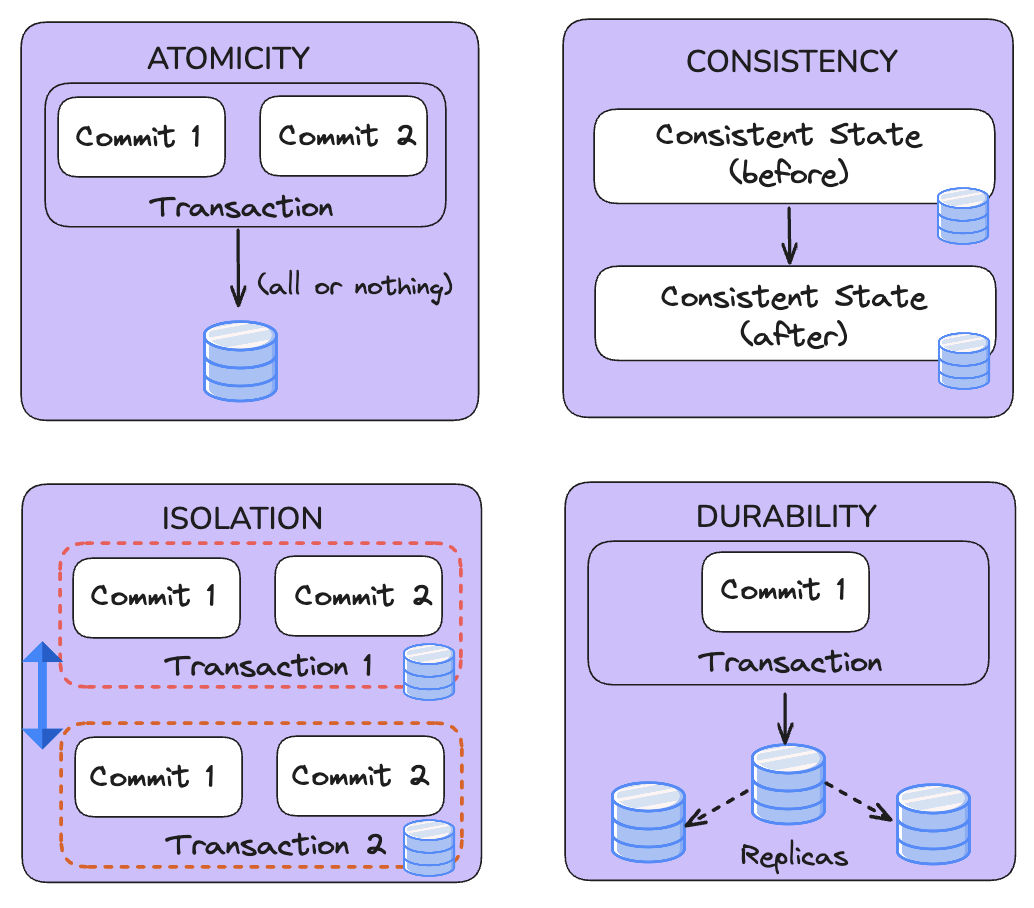
What is ACID on a Data Lake?
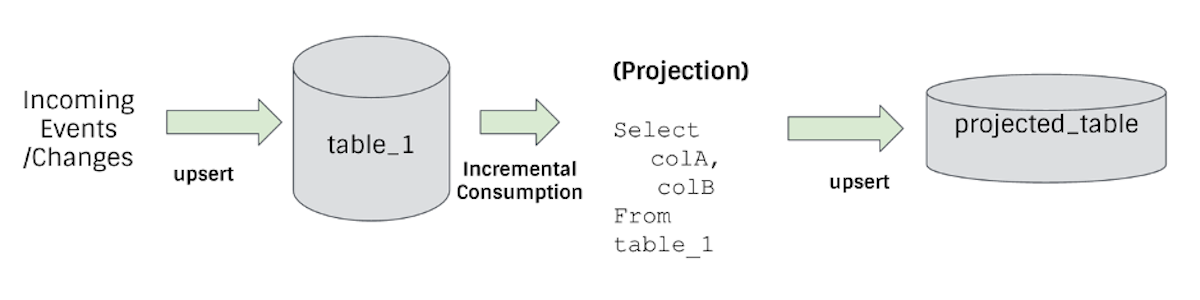
What is Incremental ETL on a Data Lake?

What is Upsert on a Data Lake?
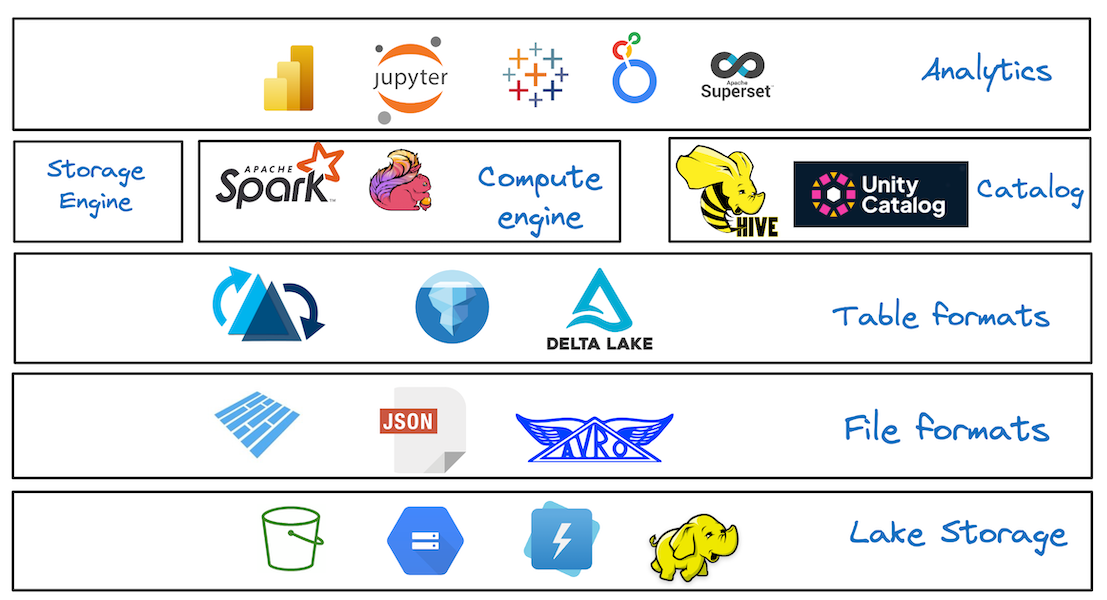
What is an Open Table Format?

Bringing Vector Search to the Lakehouse with Apache Hudi
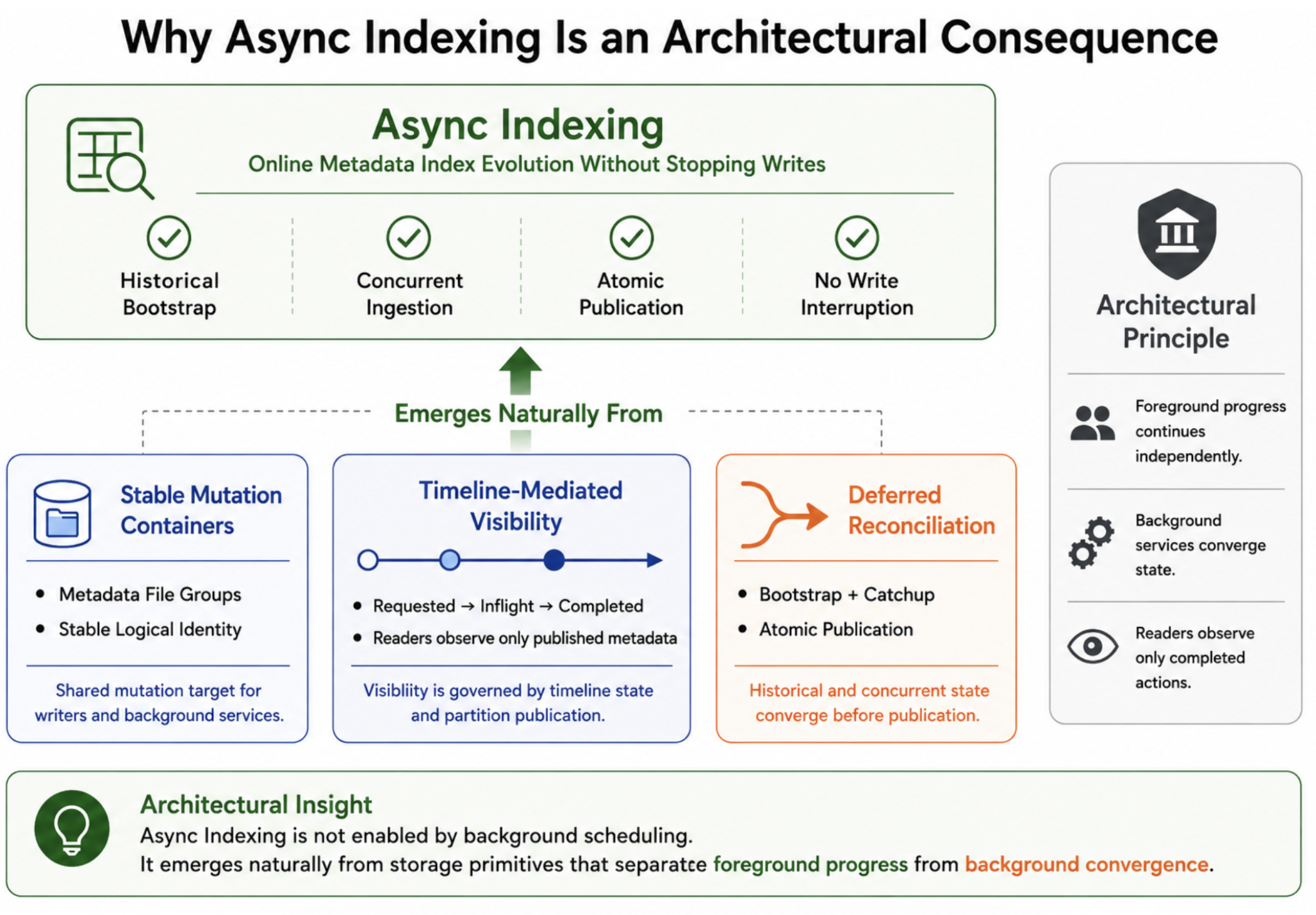
Building Indexes on a Moving Target

Accelerating Data Operations: Metica's Journey with Apache Hudi

From Concept to Reality: Apache Hudi at the Foundation of Penn Entertainment's Data Platform

Modernizing Data Infrastructure at Southwest with Apache Hudi
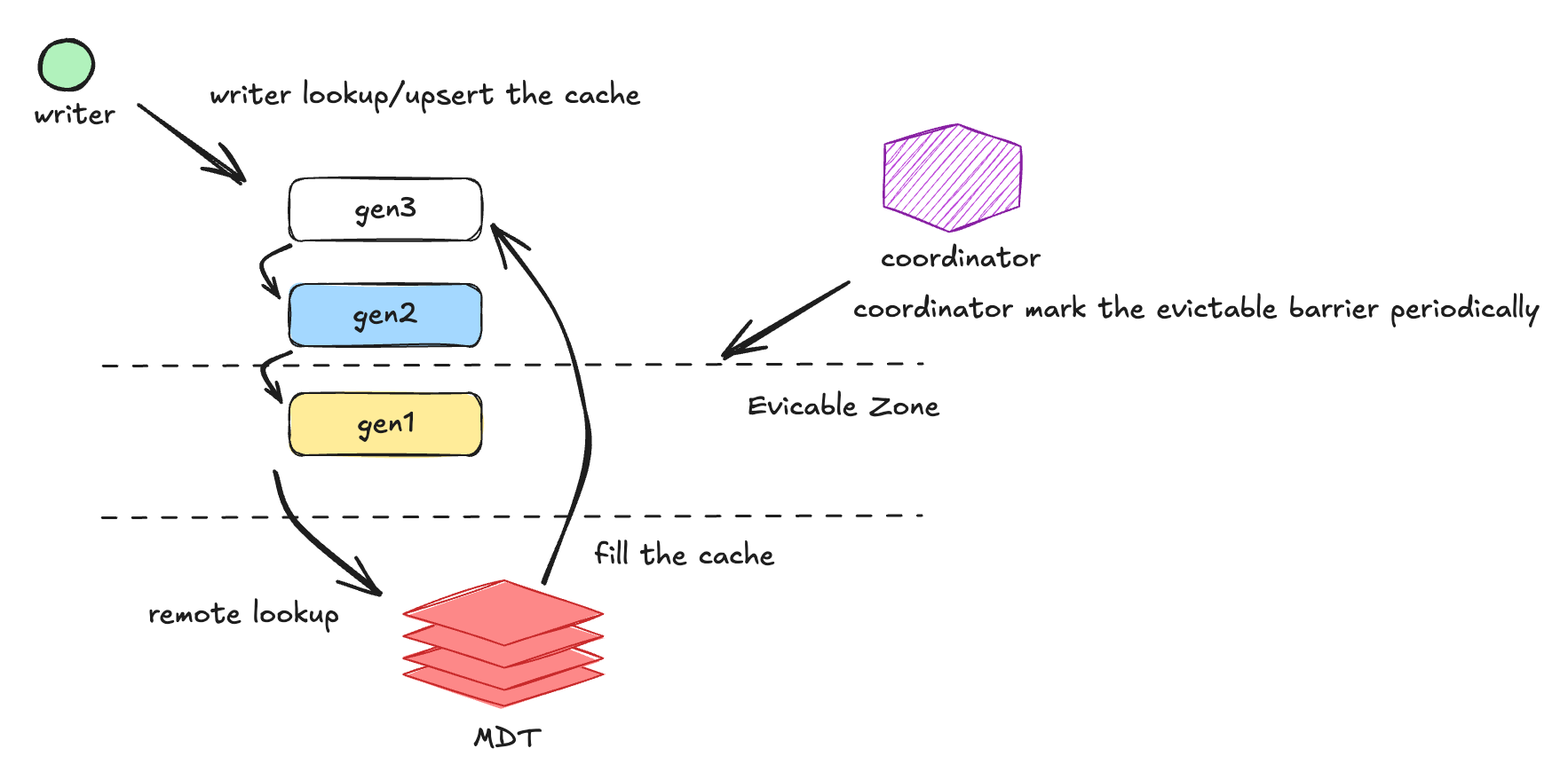
Stateless Global Upserts for Flink Streaming in Apache Hudi 1.2.0
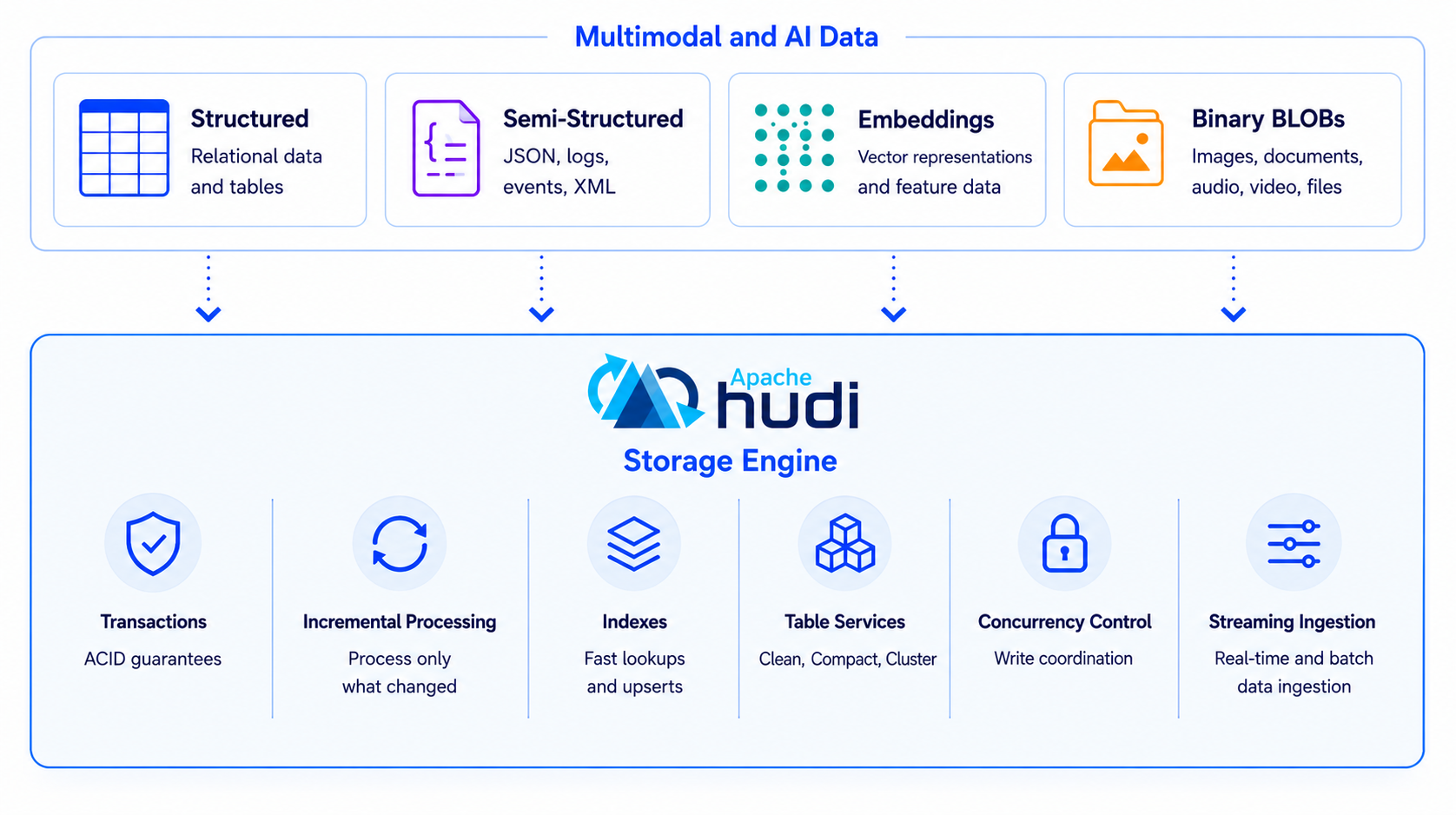
Apache Hudi 1.2: Expanding the Open Lakehouse for AI and Multimodal Data
Showing 1-12 of 323 posts