From Legacy to Leading: Funding Circle's Journey with Apache Hudi
This post summarizes Funding Circle's presentation at the Apache Hudi Community Sync. Watch the recording on YouTube.
Funding Circle is a lending company focused on helping small and medium-sized businesses access the funding they need to grow. Their instant decisioning engine allows customers to complete loan applications in minutes and receive decisions in seconds. To date, the company has supported more than 135,000 businesses with over £15 billion in loans.
In this community sync, Daniel Ford, Data Platform Engineer at Funding Circle, shared how his team built a modern data ingestion framework using Apache Hudi and the significant improvements they achieved.
Funding Circle's lending capability relies on a broad and complex data platform. The goal of the platform is to make data easy to work with, enabling users to drive business decisions without requiring specialized data engineering knowledge. Developers should be able to build quickly, while data consumers should be able to find and use information without constantly seeking support.
However, their existing legacy Kafka ingestion solution, developed back in 2018-2019, was actively undermining these goals.
Why the Legacy Ingestion System Needed to Change
The legacy ingestion tool suffered from multiple critical problems that made maintaining and scaling the platform difficult:
-
Schema Evolution Instability: Handling changes in data schemas was often unreliable or completely unviable, leading to frequent pipeline breaks and manual intervention.
-
Code Complexity and Age: The codebase was massively complex and dated, predating almost every current engineer on the Data Platform team, making maintenance and updates a slow, painful process.
-
Centralized Control vs. Data Mesh: The pipelines featured centralized deployment and management, which fundamentally opposed the company's strategic aim of achieving a data mesh architecture.
-
Lack of Ownership and Observability: There was no effective way to establish true end-to-end domain ownership for a data pipeline, and a general lack of observability made it hard to quickly diagnose and fix issues.
-
Prohibitive Backfilling Times: Syncing large Kafka topics took prohibitively long in the legacy solution, severely limiting the ability to correct or reload historical data.
-
Inability to Support Real-Time Data: The system was not designed to support near-real-time ingestion, trapping users in slow batch-processing cycles.
To move forward, the team defined clear goals: the new system needed to deliver data within ten minutes, support stable schema evolution, integrate with metadata systems like DataHub, and offer strong monitoring, scalability, and built-in PII masking. It also needed to shift ownership to individual teams by allowing decentralized pipeline definitions.
Introducing Project Kirby: The New Ingestion Framework
After six to seven months of development, the team created Kirby—short for "Kafka Ingestion Real-Time or Batch through YAML"—which provides a simple, configuration-driven interface built around Apache Hudi Streamer running on AWS EMR.
Architecture and User Experience
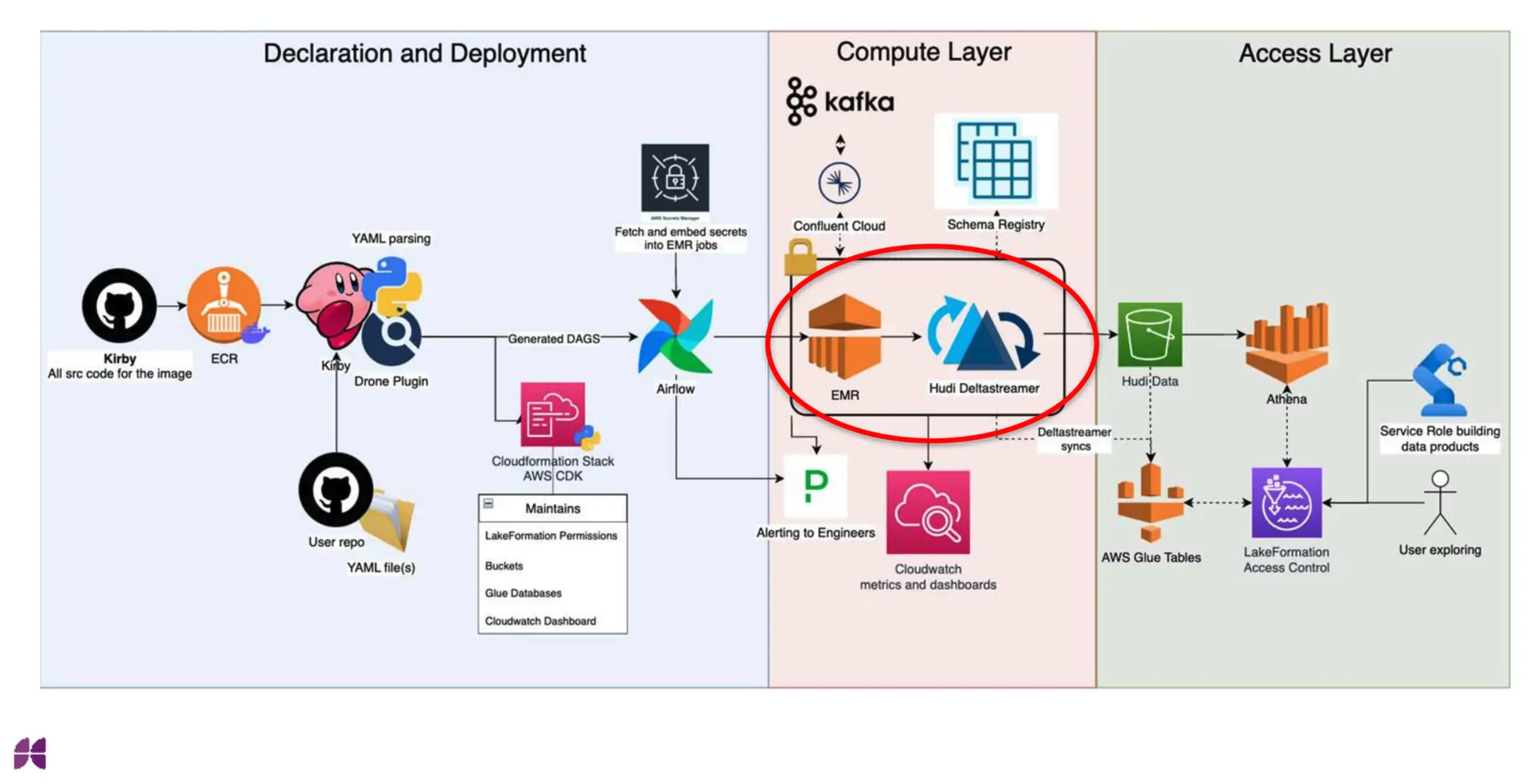
Kirby organizes ingestion into three major areas: declaration, compute, and access.
Pipeline Declaration and Deployment
Users define their pipeline in a simple YAML file stored in their own repository. This file specifies metadata such as region, domain ownership, and pipeline type. Users deploy the pipeline through GitHub Actions or Drone, depending on their existing CI/CD setup. Kirby converts the YAML definition into an Airflow DAG, letting users track the history and progress of their ingestion tasks. To safely manage secrets, the team extended the EMR step operator to load credentials from AWS Secrets Manager at runtime. Metadata embedded in the DAG also gives the central team visibility into how many pipelines exist, who owns them, and which versions are running.
Compute Layer
The actual ingestion jobs run via Hudi Streamer 0.11.1 on EMR 6.8, utilizing both batch and continuous streaming configurations. Hudi Streamer directly ingests data from Kafka on Funding Circle's centrally maintained EMR cluster.
Access Layer
Data is stored in S3 in the Hudi format and automatically registered with the Glue Data Catalog, making it instantly queryable via Athena.
The team currently serves approximately 80 topics with a range of batch and streaming workloads running simultaneously—some completing in minutes, others running continuously for hours.
Challenges and Lessons Learned
The team discovered several challenges in building the system:
EMR Learning Curve: Managing EMR required a deep understanding of Hadoop, YARN, HDFS, and Spark—knowledge the team initially lacked. For a young team of engineers with no prior domain knowledge, this was a significant hurdle to overcome. Issues still crop up occasionally, but the team now has a firm grasp on maintaining the cluster in a sustainable, scalable manner.
Debugging Complexity: Debugging proved difficult due to EMR cluster complexity. Without a deep understanding of Spark and Hadoop, investigations led to many red herrings and doubling back. Building proficiency with these underlying technologies was essential for efficient troubleshooting.
Scope Management: Initially excited by Hudi's extensive capabilities—such as time-travel querying and advanced table management—the team promised features that, while technically impressive, weren't core business requirements. This diluted the project scope and distracted from the primary goal: building a fast, simple Kafka ingestion pipeline. Through thorough testing and leveraging the Hudi community's expertise—which Daniel described as "the best I've ever encountered"—the team learned to align their scope more precisely with actual business needs.
The key lesson: properly assess business cases before committing to features. The team is now far more mature and capable of building future iterations, having gained this wealth of knowledge.
Concrete Achievements and Business Value
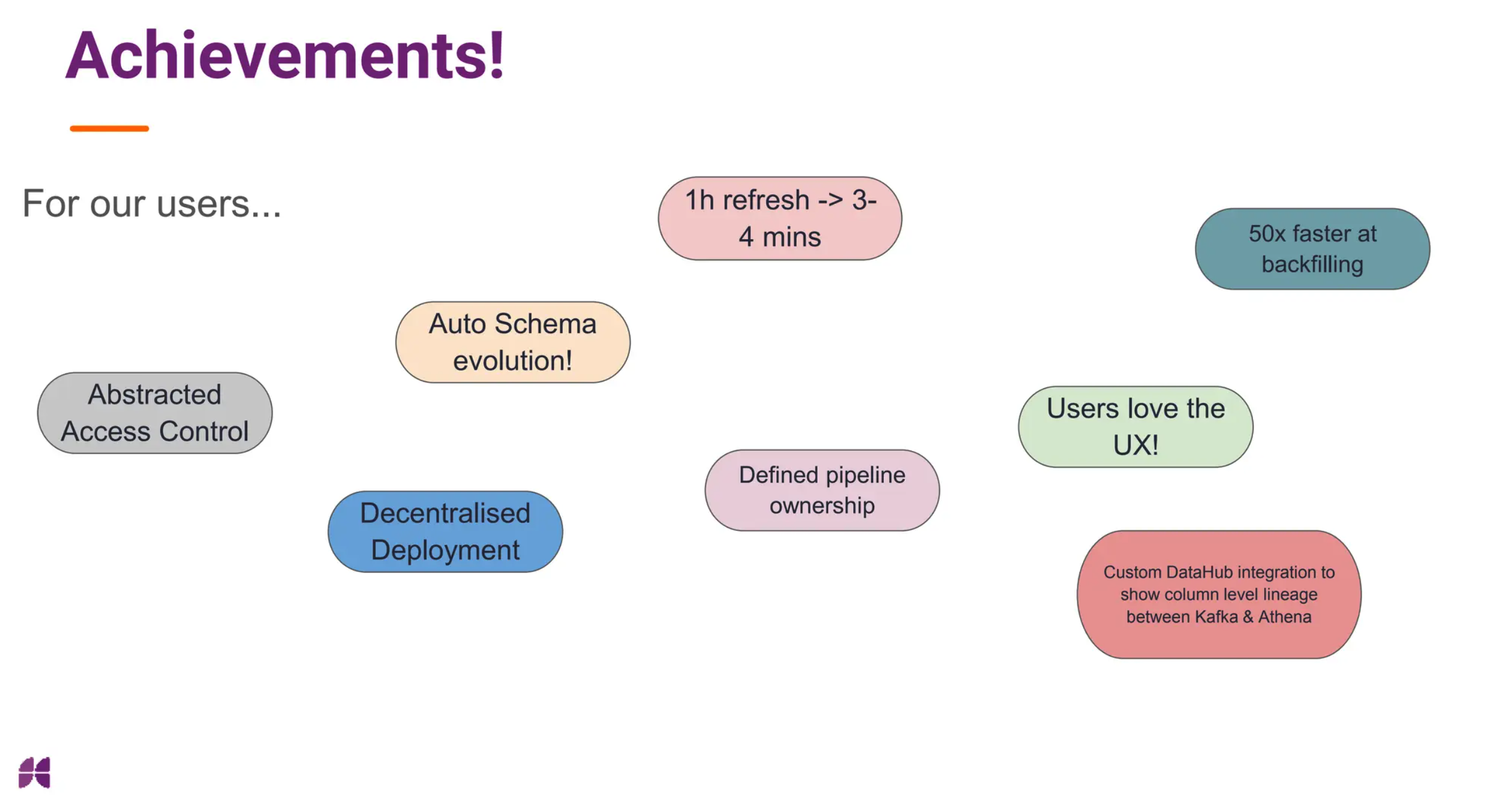
Despite the challenges, the transition to Kirby powered by Hudi delivered multiple benefits:
-
Real-Time Data Enablement: Pipeline refresh times dropped dramatically—from 30 to 60 minutes down to just 3 to 4 minutes. This enabled minute-level refreshes for analytics teams, providing fresher data and establishing a new paradigm for self-service analytics at the company.
-
Elimination of Backfilling Problems: Massive-scale backfills that previously took weeks now complete in hours. Instead of working around hacky solutions to backfill data into the lake, teams can now use the same tool for that task.
-
Automatic Schema Management: Schema evolution no longer requires manual work. What used to be an expensive full-load activity is now just an afterthought. Data producers have significantly increased confidence in their ability to evolve schemas without fear of breaking downstream pipelines.
-
Engineering Efficiency: The shift to decentralized ownership allows teams to build and maintain their own ingestion pipelines without relying on central platform engineers. Integration with DataHub enables automatic column-level lineage between Kafka topics and Athena tables. Engineering teams have drastically simplified their ingestion workflows, freeing up valuable time to focus on building quality data products.
-
Platform Modernization: Hudi served as the catalyst for the team to learn about and apply table formats to their platform for the first time. This knowledge has led them to identify a wealth of future use cases, such as migrating legacy pipelines to modern Change Data Capture (CDC) patterns using Hudi's upsert capabilities.
The Future with Hudi
Kirby currently serves approximately 80 topics across the UK and US, with a range of batch and streaming workloads. That volume is expected to grow to over 200 topics in the coming years. Future development focuses on stability and expansion:
-
Reduce EMR Reliance: The team hopes to move to lightweight compute services such as AWS Glue for less time-critical batch workloads.
-
S3 as a Source: To achieve 100% coverage, the team plans to leverage Hudi Streamer's S3 source capabilities, extending their unified ingestion interface to handle additional topic types beyond direct Kafka ingestion.
-
Extended Source Support: The team also wants to extend the familiar Kirby interface to support new source types, including SFTP, API-based sources, and other internal systems.
Project Kirby and Apache Hudi are poised to become the foundation of Funding Circle's future ingestion platform, transforming a complex, legacy system into a scalable, high-performance, and decentralized engine for data-driven decisions.
Conclusion
Funding Circle's presentation offered a clear and practical look at how adopting a modern data platform can solve significant real-world engineering challenges. By moving away from their legacy architecture and building Project Kirby around Apache Hudi, the team delivered a solution that is faster, more reliable, and far easier for teams across the organization to use. The core of their success was Hudi's ability to provide a unified data lake storage format, enabling crucial features like automatic schema evolution and near-real-time ingestion. Ultimately, Hudi catalyzed the maturation of the team's data platform and decentralized model, setting the stage for advanced use cases like Change Data Capture (CDC).