Scaling Autonomous Vehicle Data Infrastructure with Apache Hudi at Applied Intuition
This post summarizes Applied Intuition's talk from the Apache Hudi community sync. Watch the recording on YouTube.
Applied Intuition is the foremost enabler of autonomous vehicle (AV) systems, providing a suite of tools that help AV companies improve their entire stack—from simulation to data exploration. To support their mission, Applied Intuition built a unique data infrastructure that is flexible, scalable, and secure. After migrating to an Apache Hudi-powered data lakehouse, they transformed their data capabilities: query times dropped from 10 minutes to under 25 seconds, and they can now query 3-4 orders of magnitude more data than before.
Building a Unique Data Infrastructure
Applied Intuition's data infrastructure is designed to meet the specific needs of its diverse customer base, including 17 of the top 20 OEMs. Their infrastructure is built around four core principles.
First, schemas must be flexible. Each customer determines their own data schema, so the infrastructure must handle a wide variety of data points without requiring rigid upfront definitions.
Second, compute needs to be tunable. Some customers are more cost-sensitive while others have larger-scale needs, so the infrastructure can adjust compute resources on a per-customer basis.
Third, everything must be cloud agnostic. Because customers operate on different cloud providers, the infrastructure—built on Kubernetes—works seamlessly across all of them without relying on a single vendor.
Finally, security and privacy are paramount. All data and infrastructure live within the customer's own cloud accounts. This ensures that customers fully own and control their data, enabling strict security, privacy, and retention policies.
The Challenges Before Apache Hudi
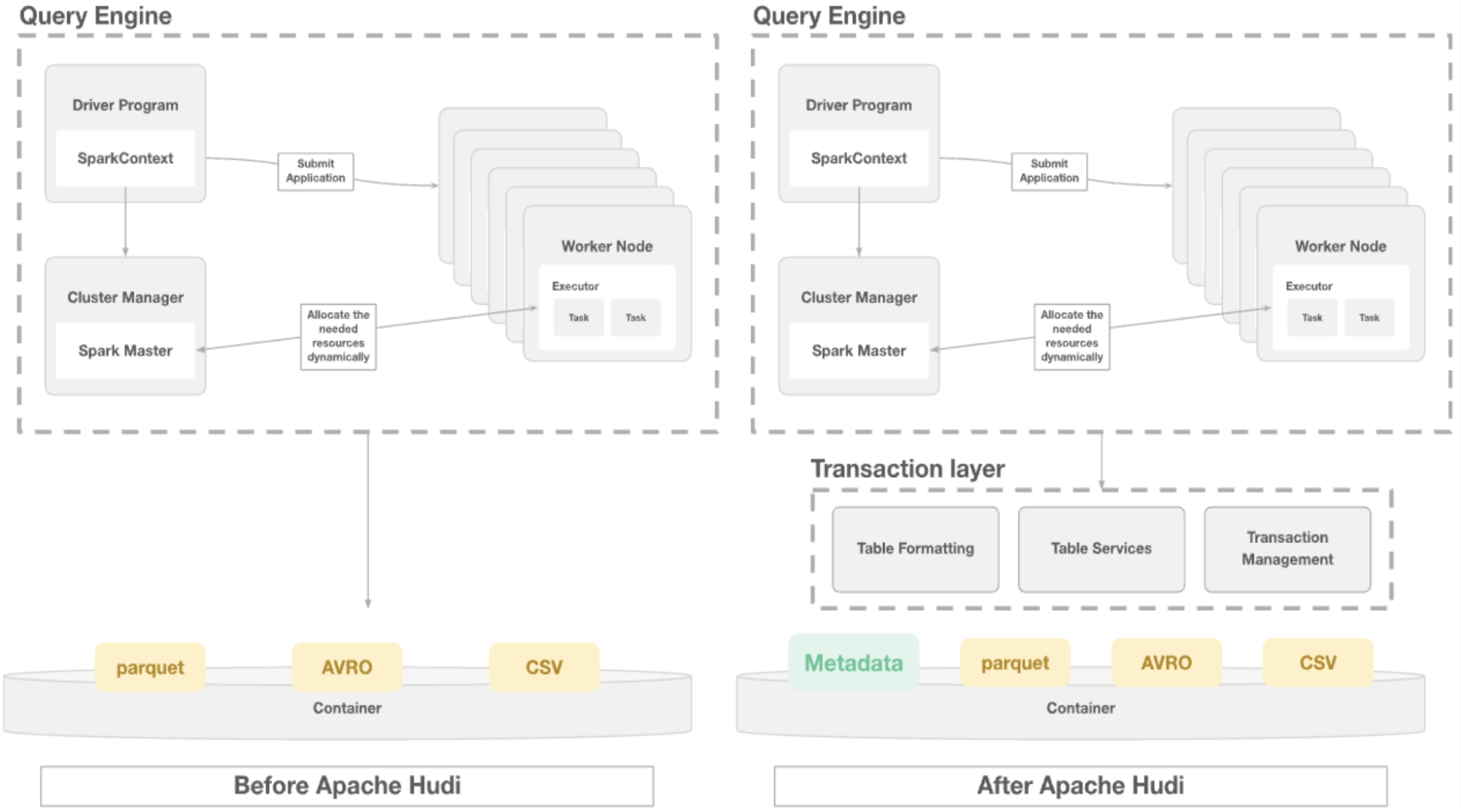
Before adopting Apache Hudi, Applied Intuition's data infrastructure directly queried a raw data lake on S3/ABFS using SQL engines. While this approach worked initially, significant issues emerged as scale increased.
The system struggled to provide ACID transaction guarantees critical for data integrity. Storage costs kept climbing because storing all data in raw format was expensive. As small files accumulated, query performance degraded dramatically due to the I/O overhead of opening and closing countless files.
To address these challenges, Applied Intuition adopted Apache Hudi, which introduced a transactional layer and metadata management to their data lake—transforming file system storage into a modern data lakehouse.
Applied Intuition primarily uses Copy-on-Write (COW) tables. While Hudi also offers Merge-on-Read (MOR) tables for faster ingestion, their main priority is query performance. With COW tables, they achieve fast query execution while accepting slightly higher write latency.
Leveraging Hudi Features to Shape Data Architecture
Applied Intuition leverages three core Hudi services to optimize its data infrastructure: file sizing, clustering, and metadata indexing.
File Sizing: Solving the Small File Problem
File sizing was the very first reason they started using Hudi. The company runs thousands of simulations daily, each generating numerous small files. This led to the classic "small file problem"—Spark queries would spend significant time just opening and closing files to read metadata. Spark SQL performs best with files around 512MB, but simulation files are often just kilobytes.
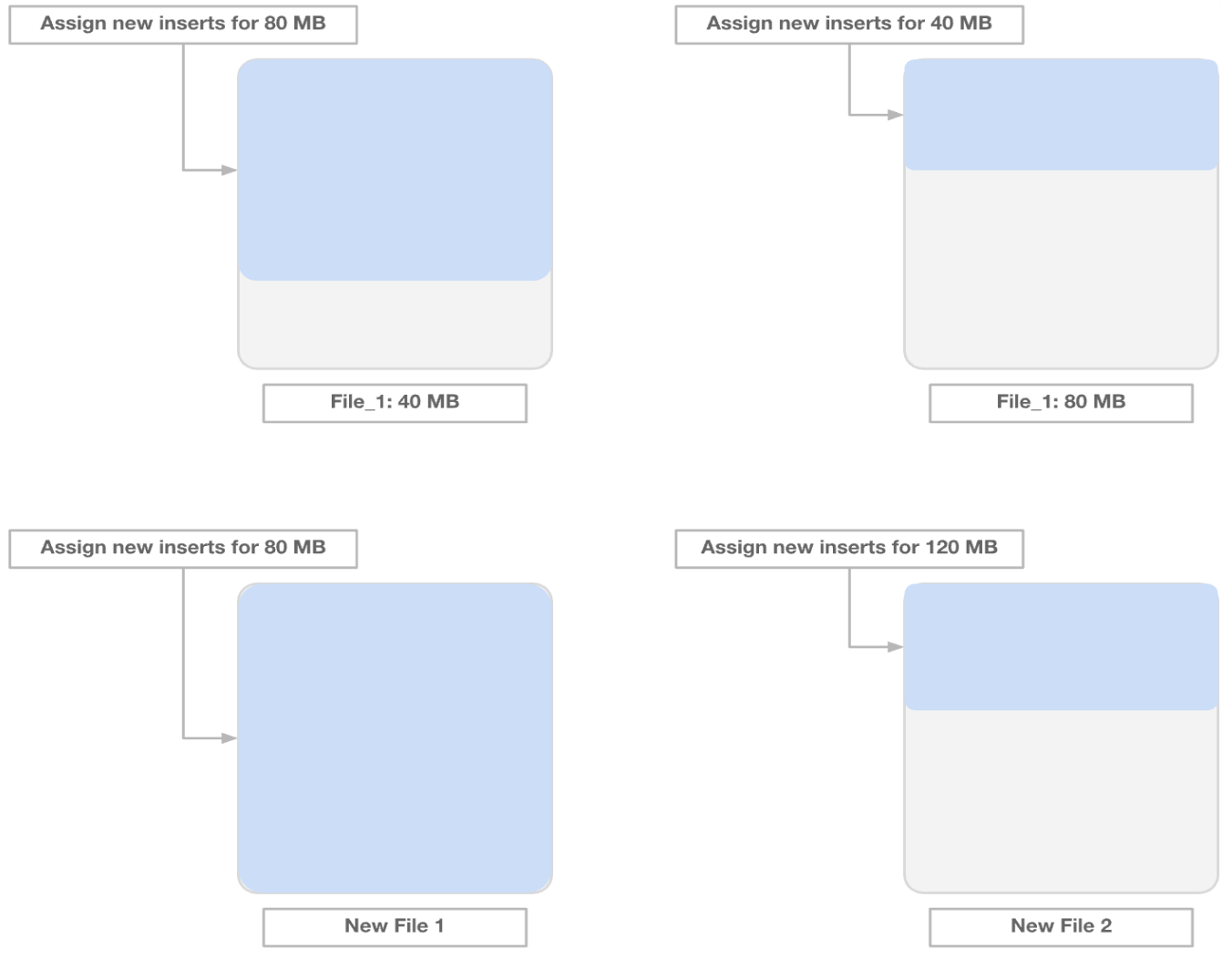
Hudi's file sizing service efficiently packs small files into optimally-sized files by analyzing previous commits and estimating the number of records per file. By combining countless kilobyte-sized files, Hudi drastically reduced I/O overhead and improved query performance. Their data now takes up 20x less space than with raw Parquet files, resulting in substantial S3 cost savings.
Rohit recalls this as the first "aha moment" with Hudi: "We had less than a gigabyte of data, but query performance was really slow. When we first tried file sizing, performance improved dramatically—and we saw all our data fit within megabytes. It was really cool to see that level of compression and query performance just out of the box."
Clustering: Optimizing for Query Patterns
Many of Applied Intuition's queries focus on specific chunks of data, or batches. Hudi's clustering feature improves data co-location by arranging related records together, minimizing the number of files touched per query.
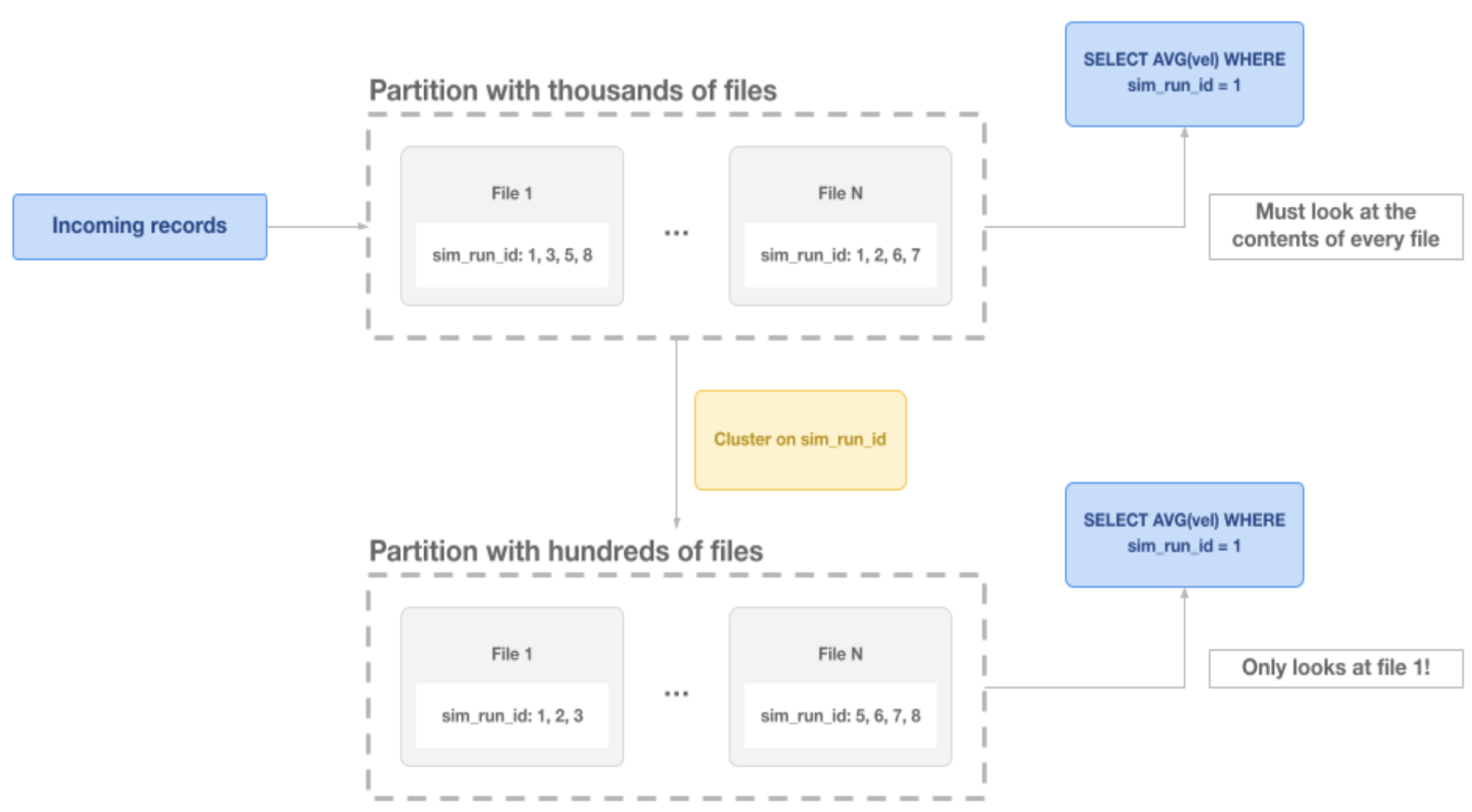
For example, by clustering all data from a single "simulation run ID" into just one or two files, Hudi allows queries to avoid scanning thousands of files. This has led to massive improvements in query performance. Applied Intuition runs clustering jobs asynchronously to maintain low write latency while keeping query performance high.
Metadata Indexing: From Minutes to Seconds
Before Hudi, loading data from raw cloud storage could take minutes, especially when listing millions of files. Hudi's metadata indexing creates a file index that allows the dataframe to load in under two seconds—a huge UX improvement for their customers.
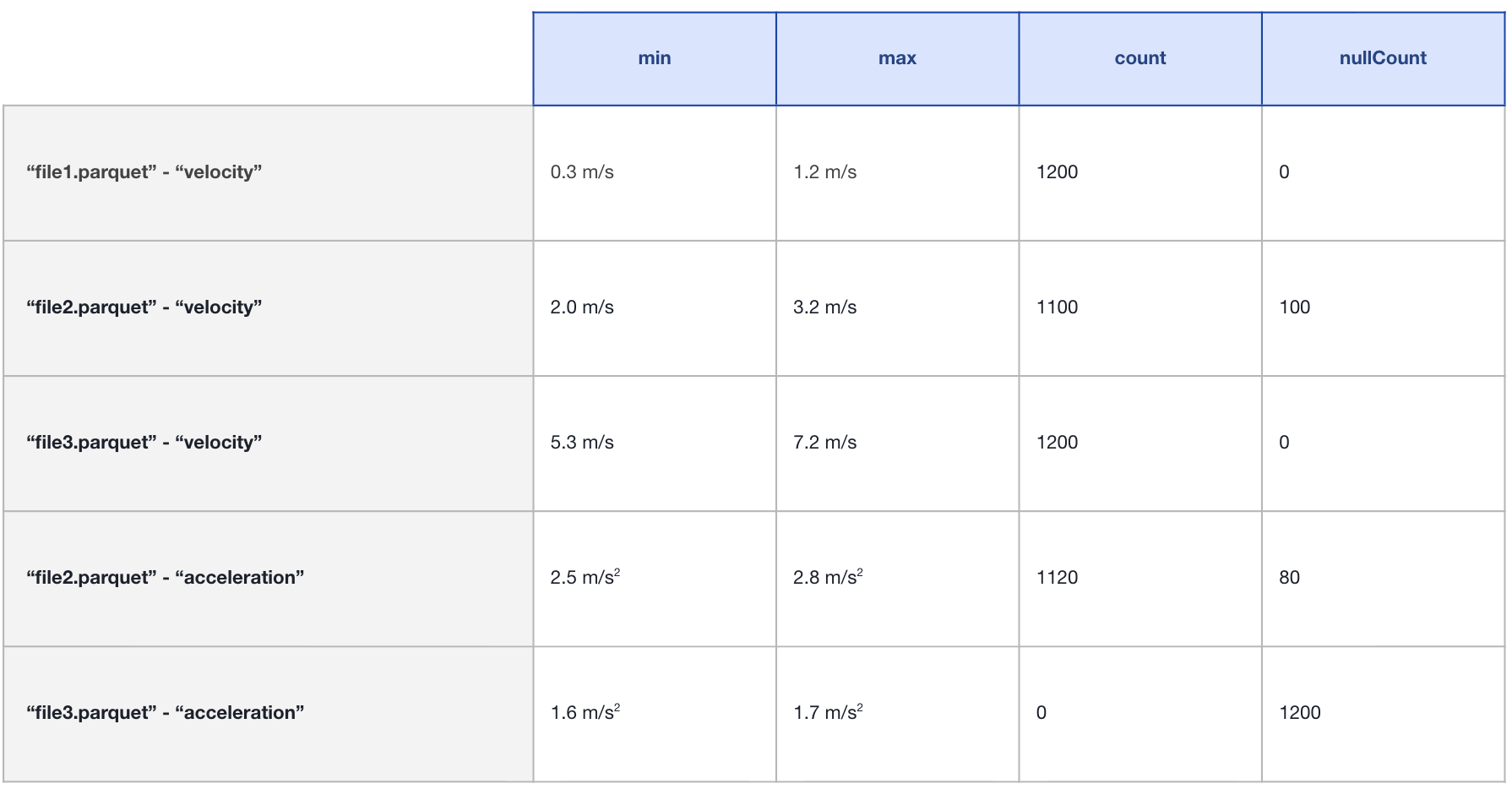
Additionally, they use column stats indices, which store min/max values for key columns. When a query runs, Hudi uses these stats to skip irrelevant files that don't match the query criteria, enabling much faster lookups.
Extending Hudi for Schema Flexibility
Given their wide customer base and evolving schema needs, Applied Intuition extended Hudi with two customizations: one to evict the cached file schema provider so mid-day schema updates are picked up during writes, and another to allow Parquet batching even when schemas differ across commits—common in simulation data where batches may have different columns.
Impact: Performance, Cost, and Scale
The improvements with Hudi have been transformative. Applied Intuition can now query 3-4 orders of magnitude more data than before. Storage costs dropped significantly thanks to file packing that achieves 20x compression compared to raw Parquet files. Query times that once took 10 minutes now complete in under 25 seconds, and dataframe initialization that used to take minutes now happens in seconds.
Despite running on tight compute resources—just 1-2 machines running DeltaStreamer—their ingestion latency sits around 15 minutes. They can easily scale this by adding more compute when needed.
Next Steps: Moving Beyond PostgreSQL
After successfully implementing Hudi on a few key tables, Applied Intuition is scaling Hudi to support their entire data lake architecture.
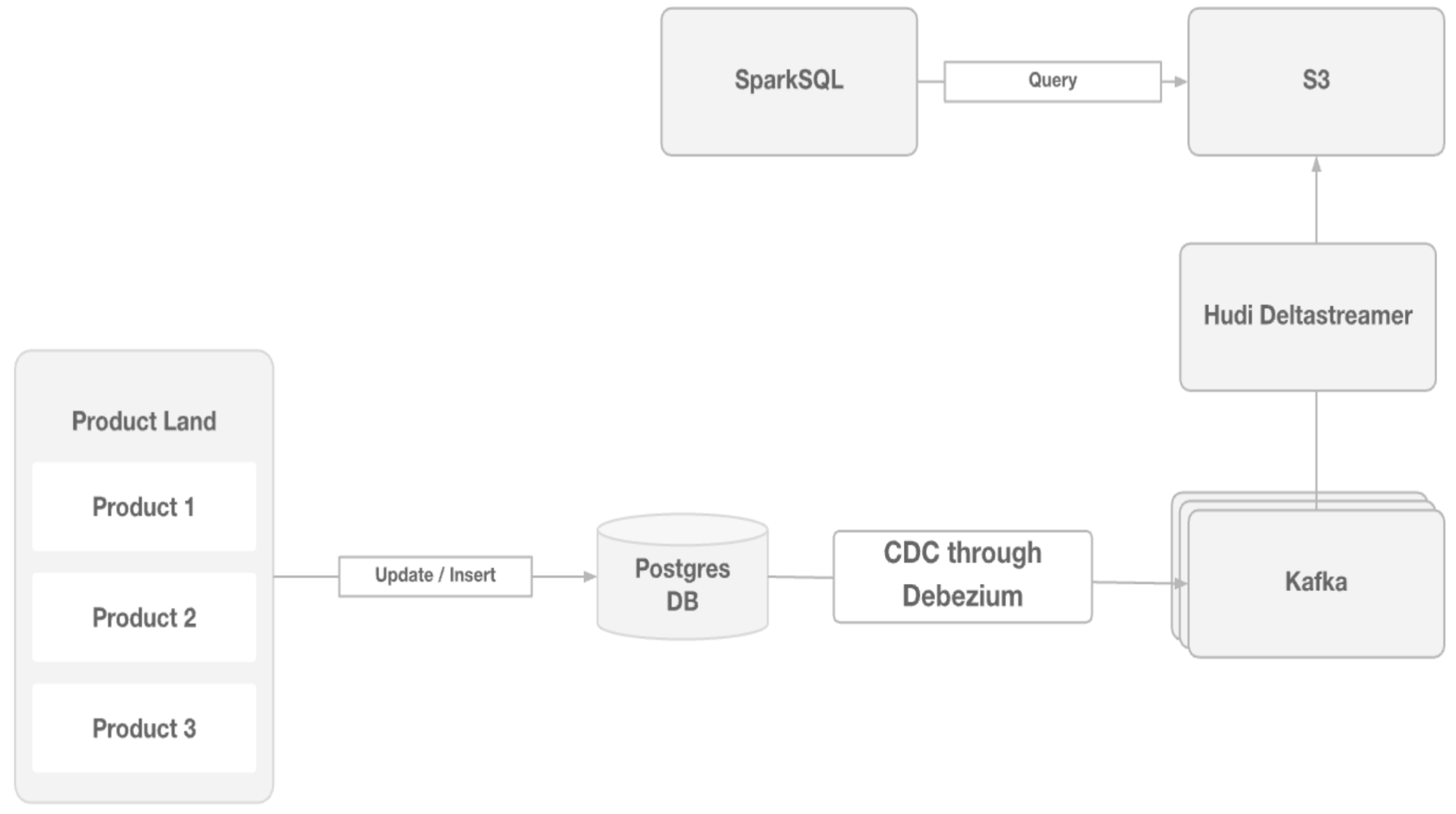
A proof of concept integrates PostgreSQL CDC via Debezium into Kafka, which feeds into Hudi DeltaStreamer, replicating transactional data into a Hudi-powered lakehouse. This setup enables non-critical queries to shift away from PostgreSQL, reducing database load and improving overall product performance. It also opens up deeper analytical insights directly from the data lake for both internal teams and customers.
The team worked through some initial setup challenges, resolving tombstone record handling through PostgreSQL and Debezium configuration updates.
Acknowledgments
Applied Intuition is grateful for the incredible support from the Apache Hudi community, which has significantly improved their data infrastructure. The Onehouse team—Sivabalan, Ethan, and Nadine—has been particularly helpful, staying up on long night calls to help debug issues and ensure the team understood the product deeply. Nadine also provided ongoing support by answering questions on Slack.
Conclusion
Applied Intuition's journey with Apache Hudi demonstrates how a modern data lakehouse platform can solve complex data infrastructure challenges while unlocking new levels of performance and insight.