Apache Hudi 2025: A Year In Review


As we close out 2025, it's clear that this has been a transformative year for Apache Hudi. The community continued to grow, delivered major advances in interoperability and performance, published "The Definitive Guide" book, and expanded our global reach through meetups, conferences, and adoption worldwide.
Community and Growth
2025 brought steady momentum in contributions and community engagement.
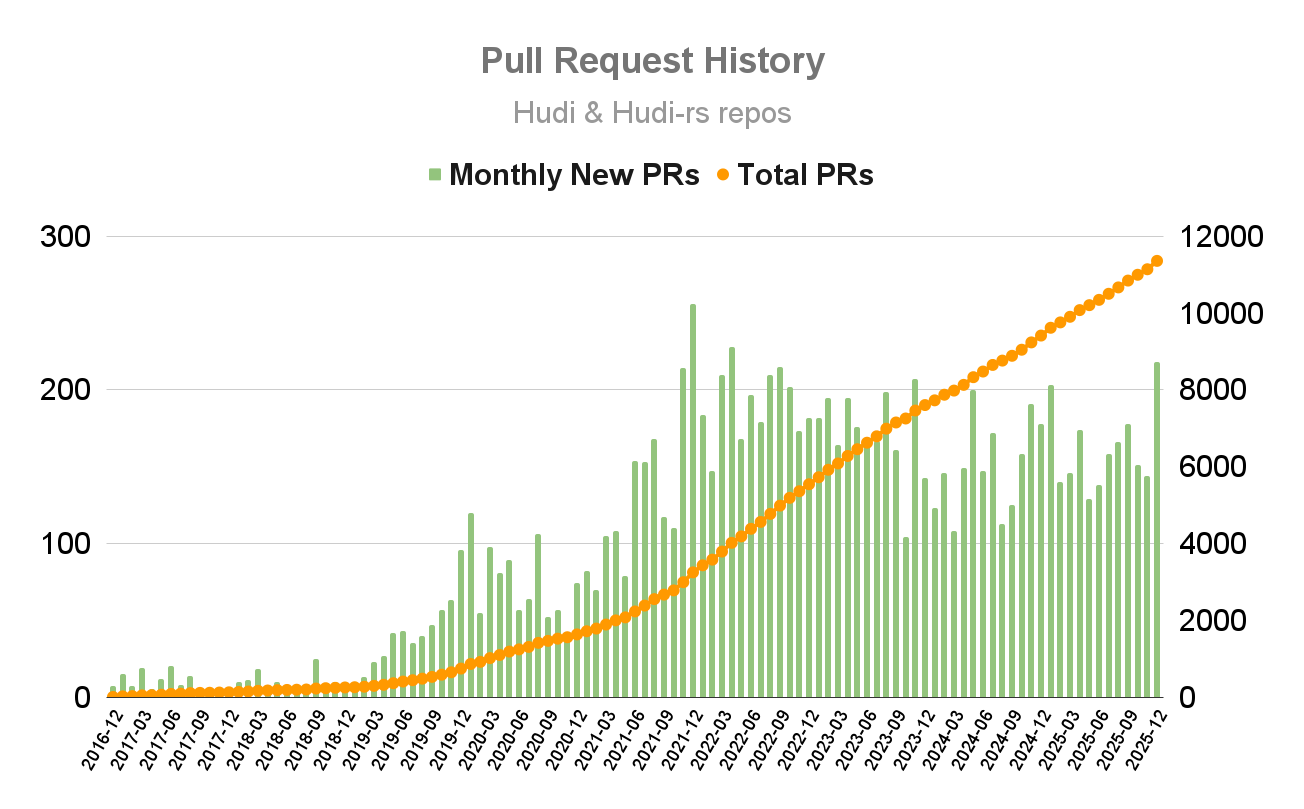
GitHub pull request activities remained steady throughout 2025, reflecting consistent development momentum. GitHub contributors reached over 500. Community engagement also grew — followers across social media platforms (LinkedIn, X, YouTube, and WeChat) increased to about 35,000, while Slack community users grew to close to 5,000.
The project celebrated new milestones in contributor recognition. Yue Zhang was elected to the Project Management Committee (PMC) for driving several major RFCs and features, evangelizing Hudi at meetups, and leading the effort to productionize hundreds of petabytes at JD.COM. Tim Brown was nominated as a committer for modernizing read/write operations behind Hudi 1.1's performance gains. Shawn Chang was nominated as a committer for strengthening Spark integration and expanding Hudi adoption on AWS EMR.
Development Highlights
Hudi 1.1 landed with over 800 commits from 50+ contributors. The headline feature is the pluggable table format framework — Hudi's storage engine is now pluggable, allowing its battle-tested transaction management, indexing, and concurrency control to work while storing data in Hudi's native format or other table formats like Apache Iceberg via Apache XTable (Incubating).
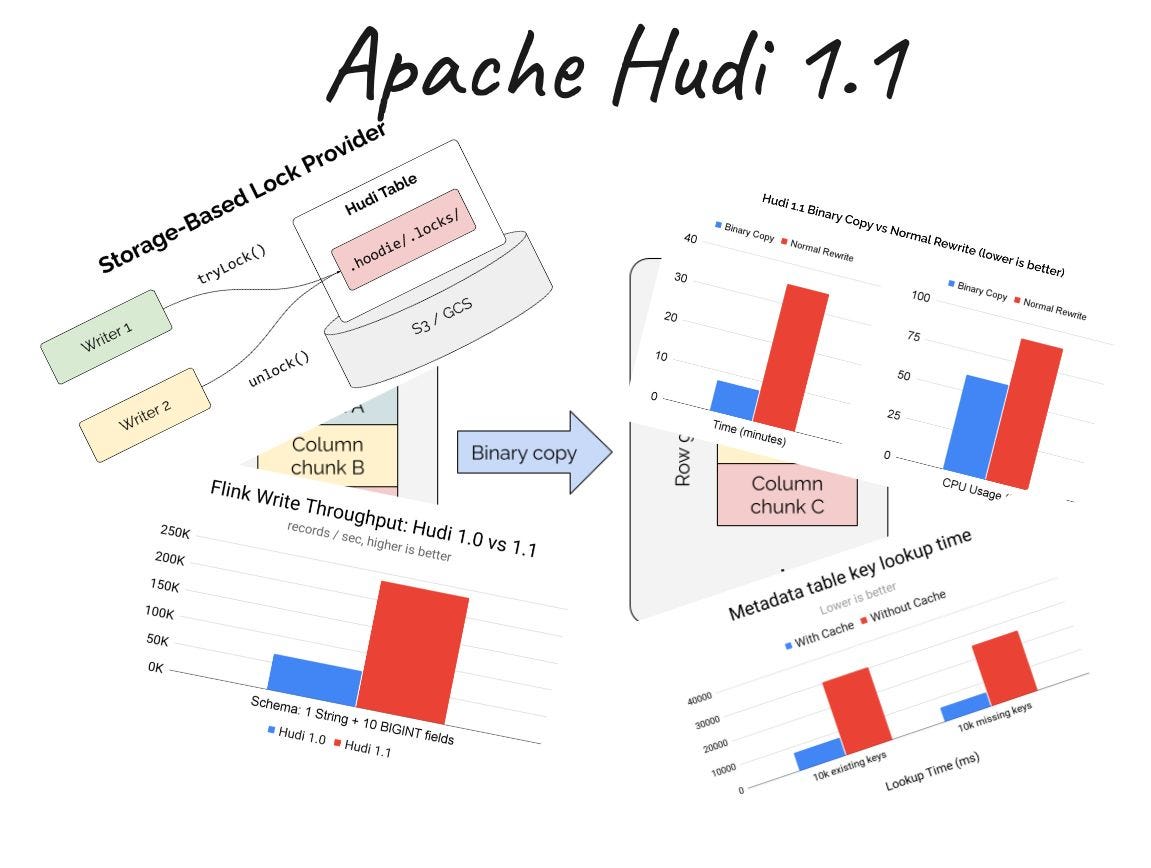
Performance saw major gains across the board. Parquet binary copy for clustering delivered 10-15x faster execution with 95% compute reduction. Apache Flink writer achieved 2-3x improved throughput with Avro conversion eliminated in the write path. Apache Spark metadata-table streaming ran ~18% faster for update-heavy workloads. Indexing enhancements — partitioned record index, partition-level bucket index, HFile caching, and Bloom filters — delivered up to 4x speedup for lookups on massive tables.
Spark 4.0 and Flink 2.0 support was added. Apache Polaris (Incubating) catalog integration enabled multi-engine queries with unified governance. Operational simplicity improved with storage-based locking that eliminated external dependencies. New merge modes replaced legacy payload classes with declarative options, and SQL procedures enhanced table management directly in Spark SQL. See more details in the release blog.
Hudi-rs expanded its feature support — release 0.3.0 introduced Merge-on-Read and incremental queries, while 0.4.0 added C++ bindings and Avro log file support. The native Rust implementation now powers Ray Data and Daft integrations for ML and multi-cloud analytics.
New Book Published
Apache Hudi: The Definitive Guide, published by O'Reilly, distills Hudi's 8+ years of innovation from 500+ contributors into a comprehensive resource for data engineers and architects.

Across 10 chapters, the guide covers writing and reading patterns, indexing strategies, table maintenance, concurrency handling, streaming pipelines with Hudi Streamer, and production deployment. With practical examples spanning batch, interactive, and streaming analytics, it takes you from getting started to building end-to-end lakehouse solutions at enterprise scale.
Meetups and Conferences
Community events brought together thousands of attendees across meetups and conferences worldwide.
Bangalore Hudi Community Meetup
A full-house gathering took place at Onehouse's India office in January, featuring deep dives into Hudi 1.0 and lakehouse architecture. The event connected developers, contributors, and enthusiasts from India's growing data engineering community.

1st Hudi Asia Meetup by Kuaishou
Our first-ever Asia meetup in March, organized by Kuaishou, drew 231 in-person attendees and 16,673 total platform views. The event featured discussions on Hudi's roadmap, lakehouse architecture patterns, and adoption stories from leading Chinese tech companies.

2nd Hudi Asia Meetup by JD.com
JD.com hosted the second Asia meetup in October, bringing together contributors and adopters for talks on real-world lakehouse implementations, streaming ingestion at scale, and roadmap discussions.

CMU Database Seminar
Vinoth Chandar, Hudi PMC Chair, presented "Apache Hudi: A Database Layer Over Cloud Storage for Fast Mutations & Queries" at Carnegie Mellon University's Future Data Systems Seminar. The talk covered how Hudi brings database-like abstractions to data lakes — enabling efficient mutations, transaction management, and fast incremental reads through storage layout, indexing, and concurrency control design decisions. A must-watch that covers both the breadth and depth of Hudi's design concepts and what problems it solves.

OpenXData
Amazon engineers presented "Powering Amazon Unit Economics at Scale Using Hudi" at OpenXData, sharing how they built Nexus — a scalable, configuration-driven platform with Hudi as the cornerstone of its data lake architecture. The talk highlighted how Hudi enables Amazon to tackle the massive challenge of understanding and improving unit-level profitability across their ever-growing businesses.

VeloxCon
Shiyan Xu, Hudi PMC member, presented on Hudi integration with Velox and Gluten for accelerating query performance, and on how Hudi-rs, the native Rust implementation with multi-language bindings such as Python and C++, can enable high-performance analytics across the open lakehouse ecosystem.

Data Streaming Summit
Two talks showcased Hudi's streaming capabilities. Zhenqiu Huang shared how Uber runs 5,000+ Flink-Hudi pipelines, ingesting 600TB daily with P90 freshness under 15 minutes. Shiyan Xu presented on Hudi's high-throughput streaming capabilities such as record-level indexing, async table services, and the non-blocking concurrency control mechanism introduced in Hudi 1.0.

Open Source Data Summit
Shiyan Xu presented on streaming-first lakehouse designs, covering Merge-on-Read table type, record-level indexing, auto-file sizing, async compaction strategies, and non-blocking concurrency control that enable streaming lakehouses with optimized mutable data handling.

Content Highlights
Throughout 2025, organizations across industries showcased their production adoption and implementation journeys through community syncs and blogs. These stories highlight Hudi's versatility as a lakehouse platform.
Featured adoption stories:
- Uber: From Batch to Streaming: Accelerating Data Freshness in Uber's Data Lake
- Amazon: Powering Amazon Unit Economics at Scale Using Apache Hudi
- Kuaishou: Hudi Lakehouse: The Evolution of Data Infrastructure for AI workloads
- Southwest Airlines: Modernizing Data Infrastructure using Apache Hudi
- Halodoc: Optimizing Apache Hudi Workflows: Automation for Clustering, Resizing & Concurrency
- Uptycs: From Transactional Bottlenecks to Lightning-Fast Analytics
The community also published noteworthy content:
- 21 Unique Reasons Why Apache Hudi Should Be Your Next Data Lakehouse
- The Future of Data Lakehouses: A Fireside Chat with Vinoth Chandar
- Deep Dive into Hudi's Indexing Subsystem: part 1 and part 2
- Hudi 1.1 Deep Dive: Optimizing Streaming Ingestion with Flink
- Maximizing Throughput with Apache Hudi NBCC: Stop Retrying, Start Scaling
- Exploring Apache Hudi’s New Log-Structured Merge (LSM) Timeline
- Introducing Secondary Index in Apache Hudi
- Lakehouse Chronicles YouTube episodes: ep. 5, ep. 6, and ep. 7
- Interactive Jupyter Notebooks for hands-on learning
Looking Ahead
The upcoming releases in 2026 will bring AI/ML-focused capabilities — including unstructured data types, column groups for embeddings, vector search, and Lance/Vortex format support. We'll also continue expanding multi-format interoperability through the pluggable table format framework and advancing streaming-first optimizations for real-time ingestion and sub-minute freshness. See the full roadmap for details.
Whether you're contributing code, sharing feedback, or spreading the word — we'd love to have you involved:
- Contribute on GitHub: Hudi & Hudi-rs
- Join our Slack community
- Follow us on LinkedIn and X (Twitter)
- Subscribe to our YouTube channel
- Follow WeChat account "ApacheHudi" for news and content in Chinese
- Participate in the developer syncs, community syncs, and office hours
- Subscribe to the dev mailing list (by sending an empty email): dev-subscribe@hudi.apache.org
A huge thank you to everyone who contributed to Hudi's growth this year. With such a strong foundation, 2026 promises to be our most exciting year yet.