Deep Dive Into Hudi’s Indexing Subsystem (Part 1 of 2)

For decades, databases have relied on indexes—specialized data structures—to dramatically improve read and write performance by quickly locating specific records. Apache Hudi extends this fundamental principle to the data lakehouse with a unique and powerful approach. Every Hudi table contains a self-managed metadata table that functions as an indexing subsystem, enabling efficient data skipping and fast record lookups across a wide range of read and write scenarios.
This two-part series dives into Hudi’s indexing subsystem. Part 1 explains the internal layout and data-skipping capabilities. Part 2 covers advanced features—record, secondary, and expression indexes—and asynchronous index maintenance. By the end, you’ll know how to leverage Hudi’s multimodal index to build more efficient lakehouse tables.
The Metadata Table
Within a Hudi table (the data table), the metadata table itself is a Hudi Merge-on-Read (MOR) table. Unlike a typical data table, it features a specialized layout. The table is physically partitioned by index type, with each partition containing the relevant index entries. For its physical storage, the metadata table uses HFile as the base file format. This choice is deliberate: HFile is exceptionally efficient at handling key lookups—the predominant query pattern for indexing. Let’s explore the partitioned layout and HFile’s internal structure.
Multimodal indexing
The metadata table is often referred to as a multimodal index because it houses a diverse range of index types, providing versatile capabilities to accelerate various query patterns. The following diagram illustrates the layout of the metadata table and its relationship with the main data table.
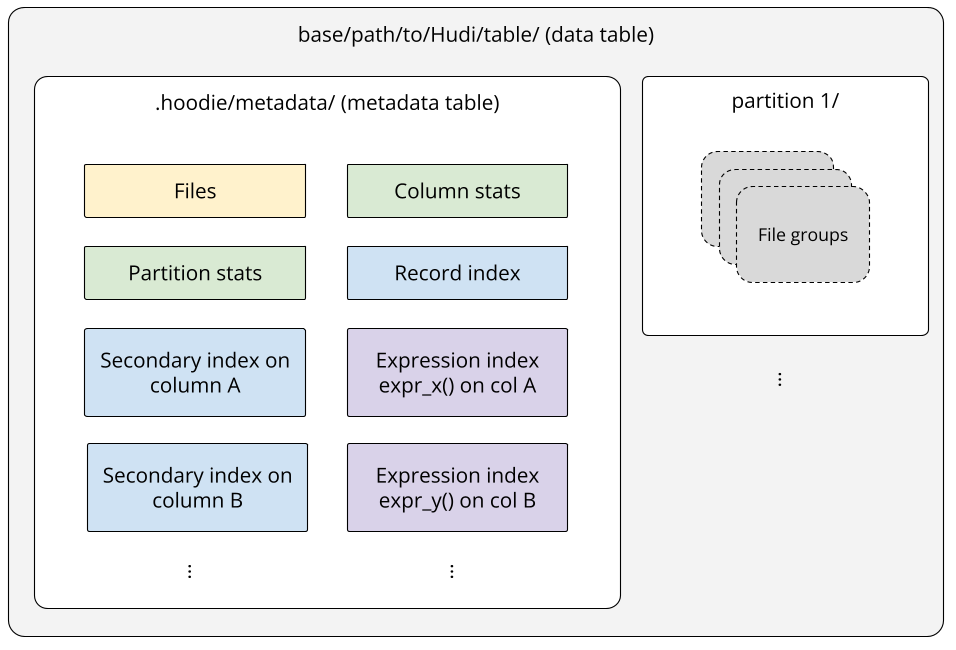
The metadata table is located in the .hoodie/metadata/ directory under the data table’s base path. It contains partitions for different indexes, such as the files index (under the files/ partition) for tracking the data table’s partitions and files, and the column stats index (under the column_stats/ partition) for tracking file-level statistics (e.g., min/max values) for specific columns. Each index partition stores mapping entries tailored to its specific purpose.
This partitioned design provides great flexibility, allowing you to enable only the indexes that suit your workload. It also ensures extensibility, making it straightforward to support new index types in the future. For example, the bitmap index and the vector search index are on the roadmap and will be maintained in their own dedicated partitions.
When committing to a data table, the metadata table is updated within the same transactional write. This crucial step ensures that index entries are always synchronized with data table records, upholding data integrity across the table. Therefore, choosing Merge-on-Read (MOR) as the table type for the metadata table is an obvious choice. MOR offers the advantage of absorbing high-frequency write operations, preventing the metadata table’s update process from becoming a bottleneck for overall table writes. To ensure efficient reading, Hudi automatically performs compaction on the metadata table based on its compaction configuration. By default, an inline compaction will be executed every 10 writes to the metadata table, merging accumulated log files with base files to produce a new set of read-optimized base files in HFile format.
HFile format
The HFile format stores key-value pairs in a sorted, immutable, and block-indexed way, modeled after Google’s SSTable introduced by the Bigtable paper. Here is the description of SSTable quoted from the paper:
An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk.
As you can tell, by implementing the SSTable, HFile is especially efficient at performing random access, which is the primary query pattern for indexing—given a specific piece of information, like a record key or a partition value, return matching results, such as the file ID that contains the record key, or the list of files that belong to the partition.
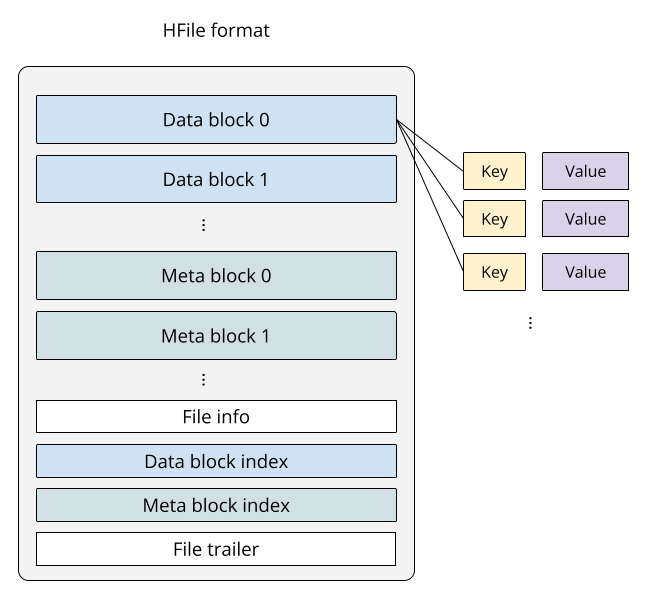
Because the keys in an HFile are stored in lexicographic order, a batched lookup with a common key prefix is also highly efficient, requiring only a sequential read of nearby keys.
Default behaviors
When a Hudi table is created, the metadata table will be enabled with three partitions by default: files, column stats, and partition stats:
- Files: stores the list of all partitions and the lists of all base files and log files of each partition, located at the
files/partition of the metadata table. - Column stats: stores file-level statistics like min, max, value count, and null count for specified columns, located at the
column_stats/partition of the metadata table. - Partition stats: stores partition-level statistics like min, max, value count, and null count for specified columns, located at the
partition_stats/partition of the metadata table.
By default, when no column is specified for column_stats and partition_stats, Hudi will index the first 32 columns (controlled by hoodie.metadata.index.column.stats.max.columns.to.index) available in the table schema.
Whenever a new write is performed on the data table, the metadata table will be updated accordingly. For any available index, new index entries will be upserted to its corresponding partition. For example, if the new write creates a new partition in the data table with some new base files, the files partition will be updated and contain the latest partition and file lists. Similarly, the column stats and partition stats partitions will receive new entries indicating the updated statistics for the new files and partitions.
Note that by design, you cannot disable the files partition, as it is a fundamental index that serves both read and write processes. You can still, although not recommended, disable the entire metadata table by setting hoodie.metadata.enable=false during a write.
We will discuss more details about how the default indexes work to improve read and write performance. We will also introduce more indexes supported by the metadata table with usage examples in the following sections.
Data Skipping with Files, Column Stats, and Partition Stats
Data skipping is a core optimization technique that avoids unnecessary data scanning. Its most basic form is physical partitioning, where data is organized into directories based on columns like order_date in a customer order table. When a query filters on a partitioned column, the engine uses partition pruning to read only the relevant directories. More advanced techniques store lightweight statistics—such as min/max values—for data within each file. The query engine consults this metadata first; if the stats indicate a file cannot contain the required data, the engine skips reading it entirely. This reduction in I/O is a key strategy for accelerating queries and lowering compute costs.
The data skipping process
Hudi’s indexing subsystem implements a multi-level skipping strategy using a combination of indexes. Query engines like Spark or Trino can leverage Hudi’s files, partition stats, and column stats indexes to improve performance dramatically. The process, illustrated in the figure below, unfolds in several stages.
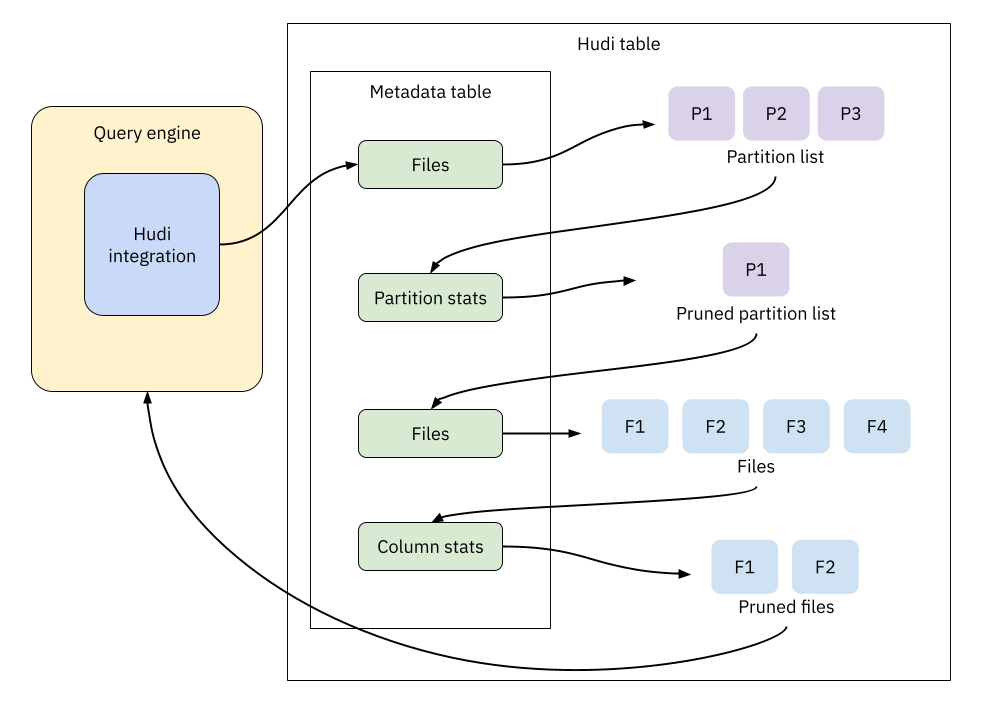
First, the query engine parses the input SQL and extracts relevant filter predicates, such as price >= 300. These predicates are pushed down to Hudi’s integration component, which manages the index lookup process.
The component then consults the files index to get an initial list of partitions. It prunes this list using the partition stats index, which holds partition-level statistics like min/max values. For example, any partition with a maximum price below 300 is skipped entirely.
After this initial pruning, the component consults the files index again to retrieve the list of data files within the remaining partitions. This file list is pruned further using the column stats index, which provides the same min/max statistics at the file level.
This multi-step process ensures that the query engine reads only the minimum set of files required to satisfy the query, significantly reducing the total amount of data processed.
SQL examples
The following examples demonstrate data skipping in action. We will create a Hudi table and execute Spark SQL queries against it, starting with both partition and column stats disabled to establish a baseline.
CREATE TABLE orders (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'update_ts',
hoodie.metadata.index.column.stats.enable = 'false',
hoodie.metadata.index.partition.stats.enable = 'false'
);
And insert some sample data:
INSERT INTO orders VALUES
('ORD001', 389.99, 'PENDING', 17495166353, DATE '2023-01-01', 'A'),
('ORD002', 199.99, 'CONFIRMED', 17495167353, DATE '2023-01-01', 'A'),
('ORD003', 59.50, 'SHIPPED', 17495168353, DATE '2023-01-11', 'B'),
('ORD004', 99.00, 'PENDING', 17495169353, DATE '2023-02-09', 'B'),
('ORD005', 19.99, 'PENDING', 17495170353, DATE '2023-06-12', 'C'),
('ORD006', 5.99, 'SHIPPED', 17495171353, DATE '2023-07-31', 'C');
Only the files index
With both column stats and partition stats disabled, only the files index is built during the insert operation. We’ll use the SQL below for our test:
SELECT order_id, price, shipping_country
FROM orders
WHERE price > 300;
This query looks for orders with price greater than 300, which only exist in partition 'A' (shipping_country = 'A'). After running the SQL, here's what we see in the Spark UI:

Spark read all 3 partitions and 3 files to find potential matches, but only 1 record from partition A actually satisfied the query condition.
Enabling column stats
Now let's enable column stats while keeping partition stats disabled. Note that we can't do it the other way around—partition stats requires column stats to be enabled first.
CREATE TABLE orders (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'update_ts',
hoodie.metadata.index.column.stats.enable = 'true',
hoodie.metadata.index.partition.stats.enable = 'false'
);
Running the same SQL gives us this in the Spark UI:

Now it shows all 3 partitions but only 1 file was scanned. Without partition stats, the query engine couldn't prune partitions, but column stats successfully filtered out the non-matching files. The compute cost of examining those 2 irrelevant partitions and their files could have been avoided with partition stats enabled.
Enabling column stats and partition stats
Now let's enable partition stats as well. Since both indexes are enabled by default in Hudi 1.x, we can simply omit those additional configs from the CREATE statement:
CREATE TABLE orders (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'update_ts'
);
Running the same SQL gives us this in the Spark UI:

Now we see the full pruning effect happened—only 1 relevant partition and 1 relevant file were scanned, thanks to both indexes working together. This blog shows a 93% reduction in query time running on a 1 TB dataset.
Configure relevant columns to be indexed
By default, Hudi indexes the first 32 columns for both partition stats and column stats. This limit prevents excessive metadata overhead—each indexed column requires computing min, max, null-count, and value-count statistics for every partition and data file. In most cases, you only need to index a small subset of columns that are frequently used in query predicates. You can specify which columns to be indexed to reduce the maintenance costs:
CREATE TABLE orders (
order_id STRING,
price DECIMAL(12,2),
order_status STRING,
update_ts BIGINT,
shipping_date DATE,
shipping_country STRING
) USING HUDI
PARTITIONED BY (shipping_country)
OPTIONS (
primaryKey = 'order_id',
preCombineField = 'update_ts',
'hoodie.metadata.index.column.stats.column.list' = 'price,shipping_date'
);
The config hoodie.metadata.index.column.stats.column.list applies to both partition stats and column stats. By indexing just the price and shipping_date columns, queries filtering on price comparisons or shipping date ranges will already see significant performance improvements.
Key Takeaways and What's Next
Hudi’s metadata table is itself a Hudi Merge‑on‑Read (MOR) table that acts as a multimodal indexing subsystem. It is physically partitioned by index type (for example, files/, column_stats/, partition_stats/) and stores base files in the HFile (SSTable‑like) format. This layout provides fast point lookups and efficient batched scans by key prefix—exactly the access patterns indexing needs at lakehouse scale.
Index maintenance happens transactionally alongside data writes, keeping index entries consistent with the data table. Periodic compaction merges log files into read‑optimized HFile base files to keep point lookups fast and predictable. On the read path, Hudi composes multiple indexes to minimize I/O: the files index enumerates candidates, partition stats prune irrelevant partitions, and column stats prune non‑matching files. In effect, the engine scans only the minimum set of files required to satisfy a query.
In practice, the defaults are a strong starting point. Keep the metadata table enabled and explicitly list only the columns you frequently filter on via hoodie.metadata.index.column.stats.column.list to control metadata overhead. In part 2, we’ll go deeper into accelerating equality‑matching and expression‑based predicates using the record, secondary, and expression indexes, and discuss how asynchronous index maintenance keeps writers unblocked while indexes build in the background.