How Zupee Cut S3 Costs by 60% with Apache HudiDecember 22, 2025 byThe Hudi Communityhudilakehousecase-studyzupee
Maximizing Throughput with Apache Hudi NBCC: Stop Retrying, Start ScalingDecember 16, 2025 byShiyan Xuhudidata lakehouseconcurrency controlstreaming
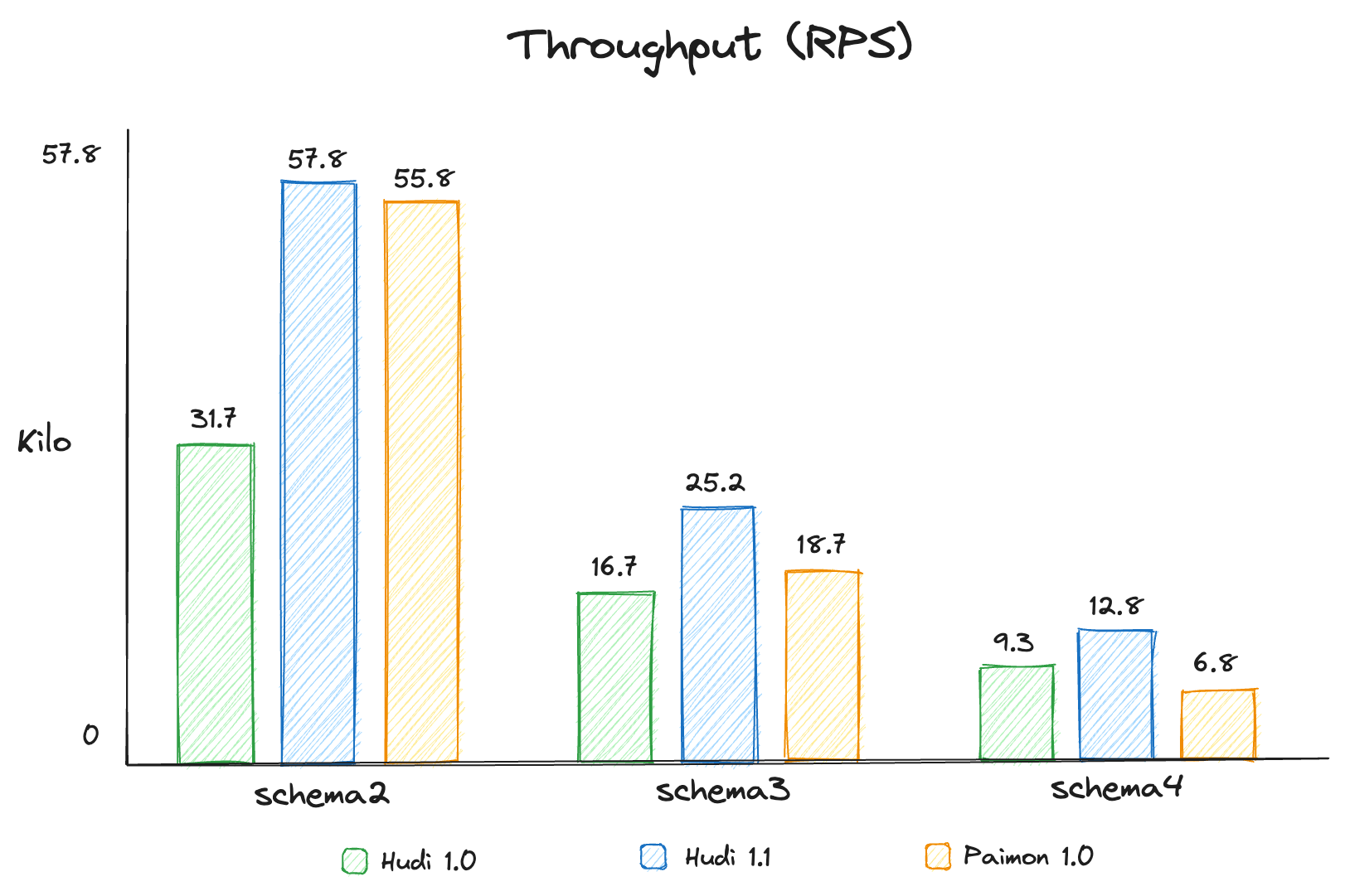
Apache Hudi 1.1 Deep Dive: Optimizing Streaming Ingestion with Apache FlinkDecember 10, 2025 byShuo Chenghudiflinkperformance
Next Generation Lakehouse: New Engine for the Intelligent Future | Apache Hudi Meetup Asia RecapDecember 1, 2025 byTeam at JD.comhudimeetuplakehousecommunity
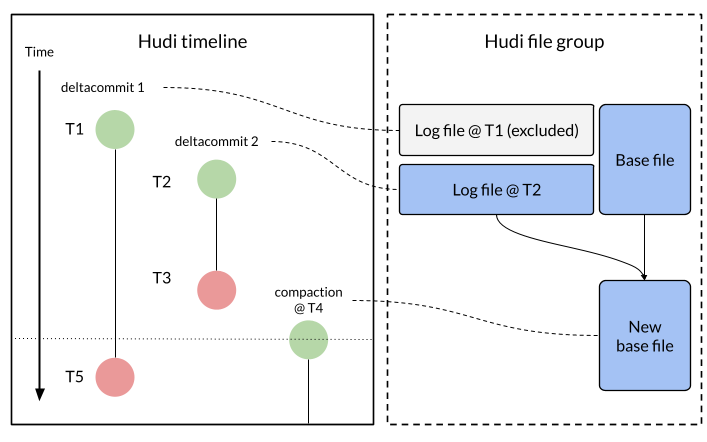
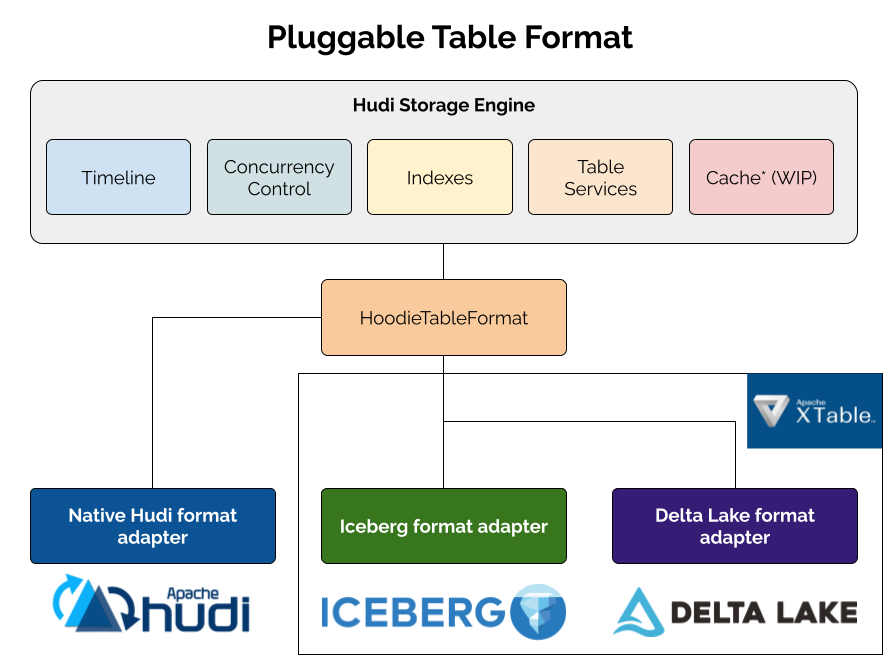
Apache Hudi 1.1 is Here—Building the Foundation for the Next Generation of LakehouseNovember 25, 2025 byShiyan Xuhudireleasefeatureperformance
Deep Dive Into Hudi's Indexing Subsystem (Part 2 of 2)November 12, 2025 byShiyan Xuhudiindexingdata lakehousedata skipping
How FreeWheel Uses Apache Hudi to Power Its Data LakehouseNovember 7, 2025 byThe Hudi Communityhudilakehousecase-studyfreewheel
Deep Dive Into Hudi’s Indexing Subsystem (Part 1 of 2)October 29, 2025 byShiyan Xuhudiindexingdata lakehousedata skipping
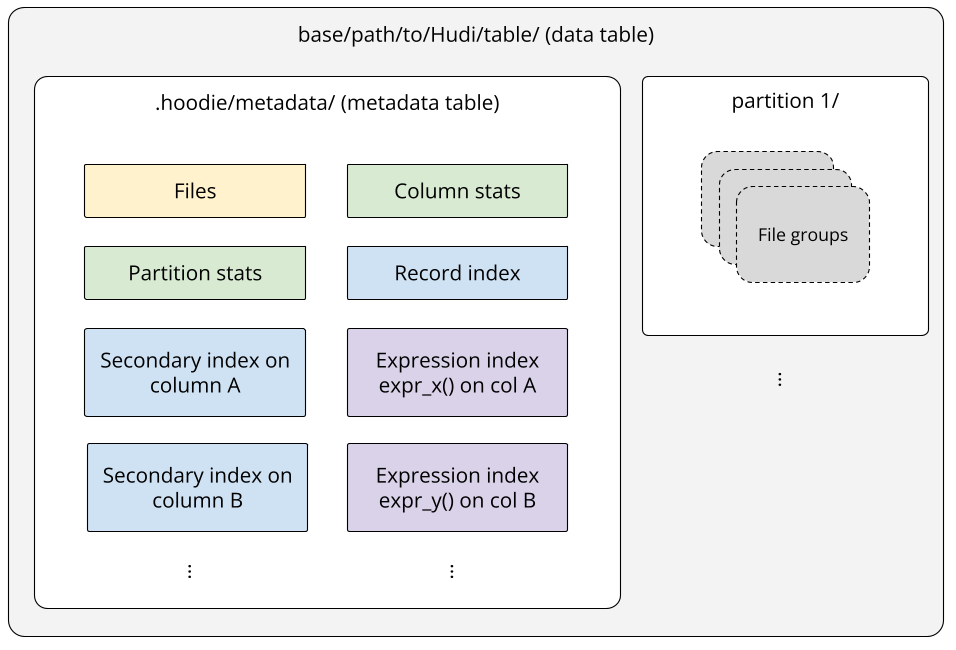
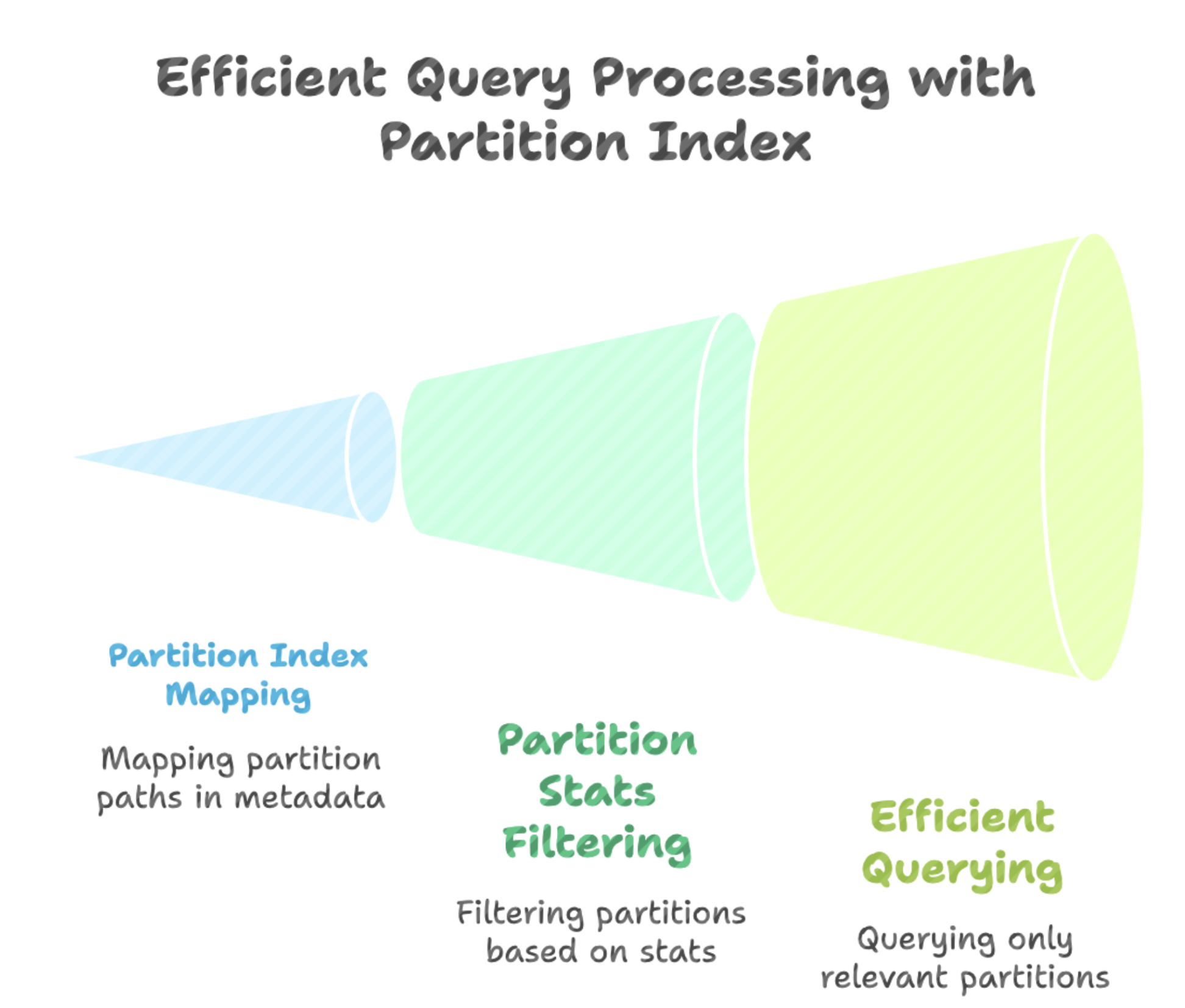
Partition Stats: Enhancing Column Stats in Hudi 1.0October 22, 2025 byAditya GoenkaandShiyan Xuhudiindexingdata lakehousedata skipping
Modernizing Upstox's Data Platform with Apache Hudi, dbt, and EMR ServerlessOctober 16, 2025 byThe Hudi Communityhudiupstoxdbtdata lakehouse
Automatic Record Key Generation in Apache HudiSeptember 17, 2025 byShiyan Xuhudirecord key generationdatabasedata lakehouse
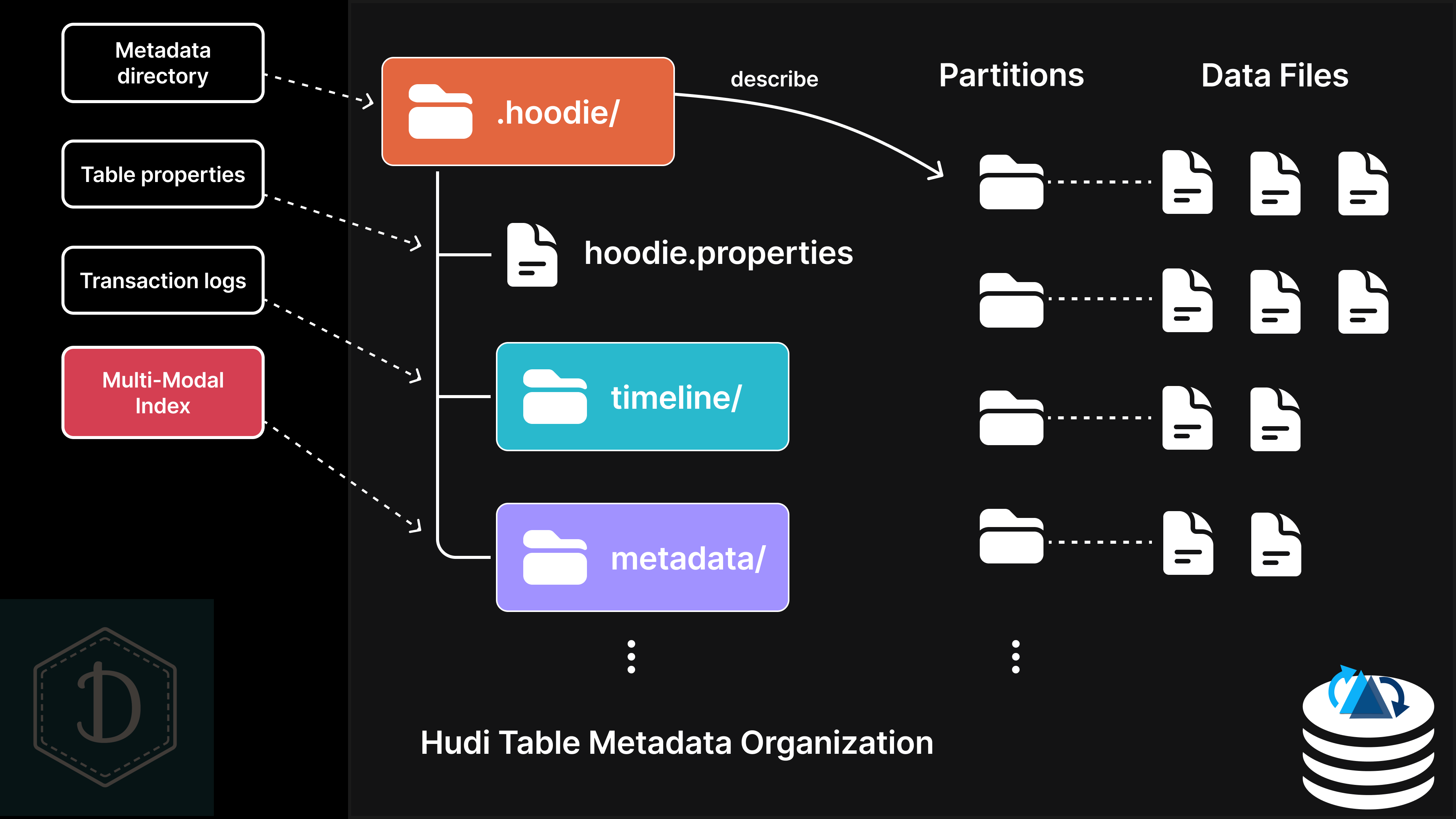
Apache Hudi does XYZ (1/10): File pruning with multi-modal indexJune 16, 2025 byShiyan Xuhudisparkblogcoursetutorialdatumagicdata lakelakehouseapache hudiapache spark