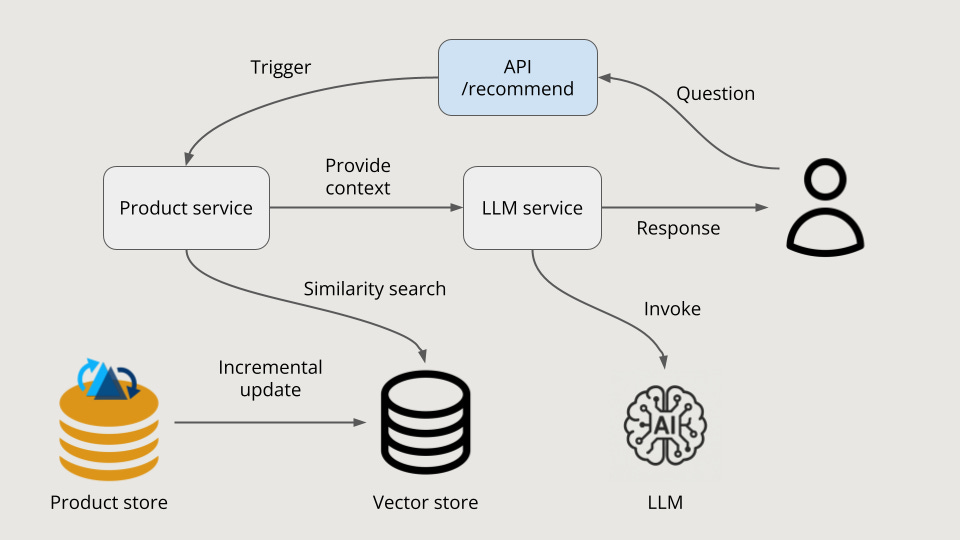
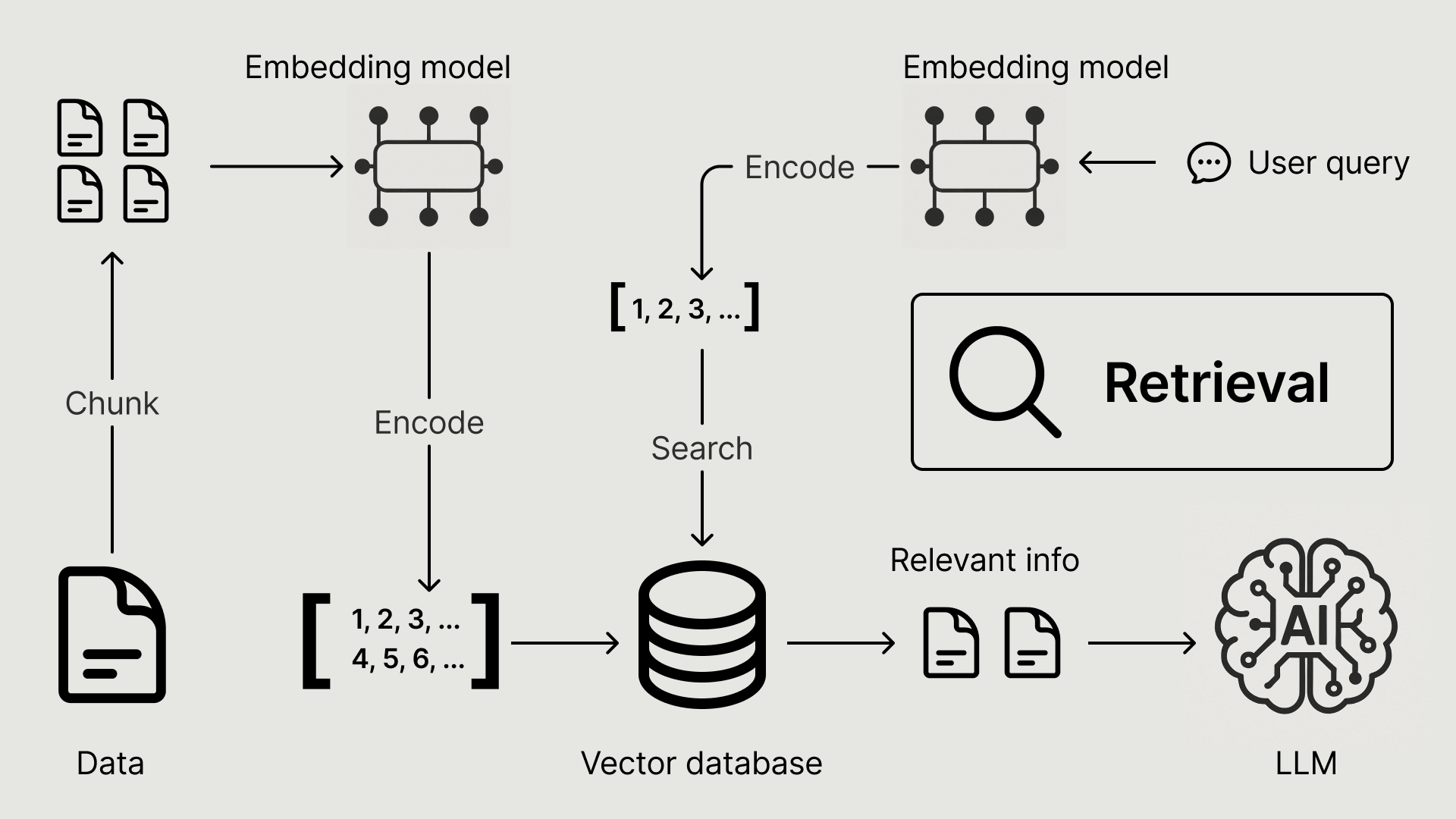
Building a RAG-based AI Recommender (2/2)August 29, 2025 byShiyan XublogApache HudiAIRAGArtificial Intelligencedata lakehouseLakehouseuse-casedatumagic
How PayU built a secure enterprise AI assistant using Amazon BedrockJuly 15, 2025 byDeepesh Dhapola, Mudit Chopra, Rahmat Khan, Rahul Ghosh, Saikat Dey, and Sandeep Kumar VeerlapatiblogApache HudiAWS
Building a RAG-based AI Recommender (Part 1/2)July 10, 2025 byShiyan XublogApache HudiAIRAGArtificial Intelligencedata lakehouseLakehouseuse-casedatumagic
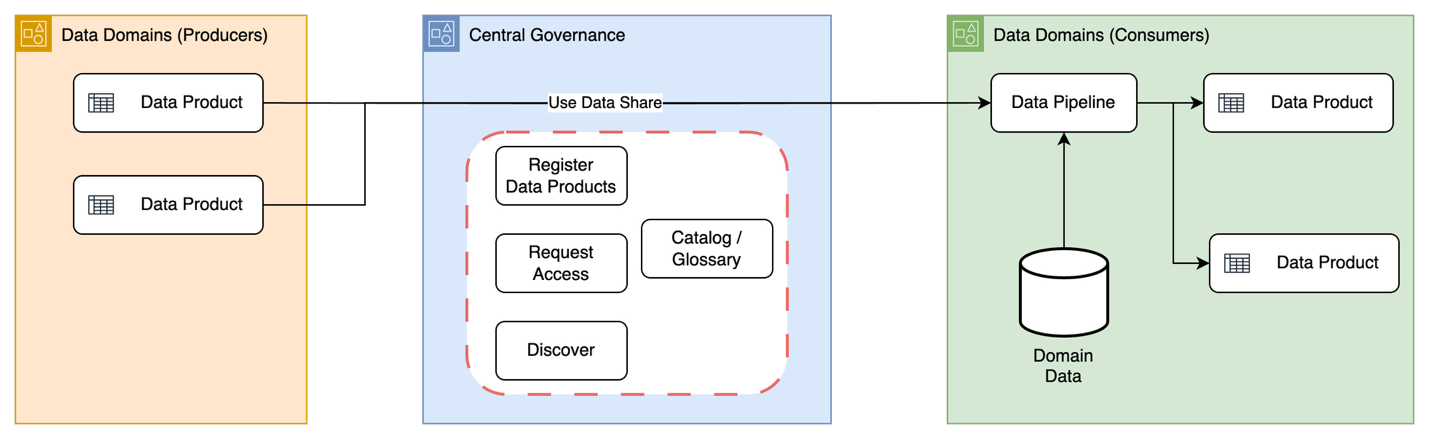
How Stifel built a modern data platform using AWS Glue and an event-driven domain architectureJuly 7, 2025 byAmit Maindola and Srinivas Kandi, Hossein Johari, Ahmad Rawashdeh, Lei MengblogApache HudiawsAWS GlueAWS BlogsAmazon EMRAWS Lake FormationData GovernanceLakehouseuse-casedet
Why Uber Built Hudi: The Strategic Decision Behind a Custom Table FormatJuly 3, 2025 byThamizhElango NatarajanblogApache HudiApache IcebergLakehouseuse-caseUberdet
Lakehouse Architecture - Apache Hudi and Apache IcebergJuly 2, 2025 bybeCloudReadyblogApache HudiApache IcebergLakehouseuse-casedet
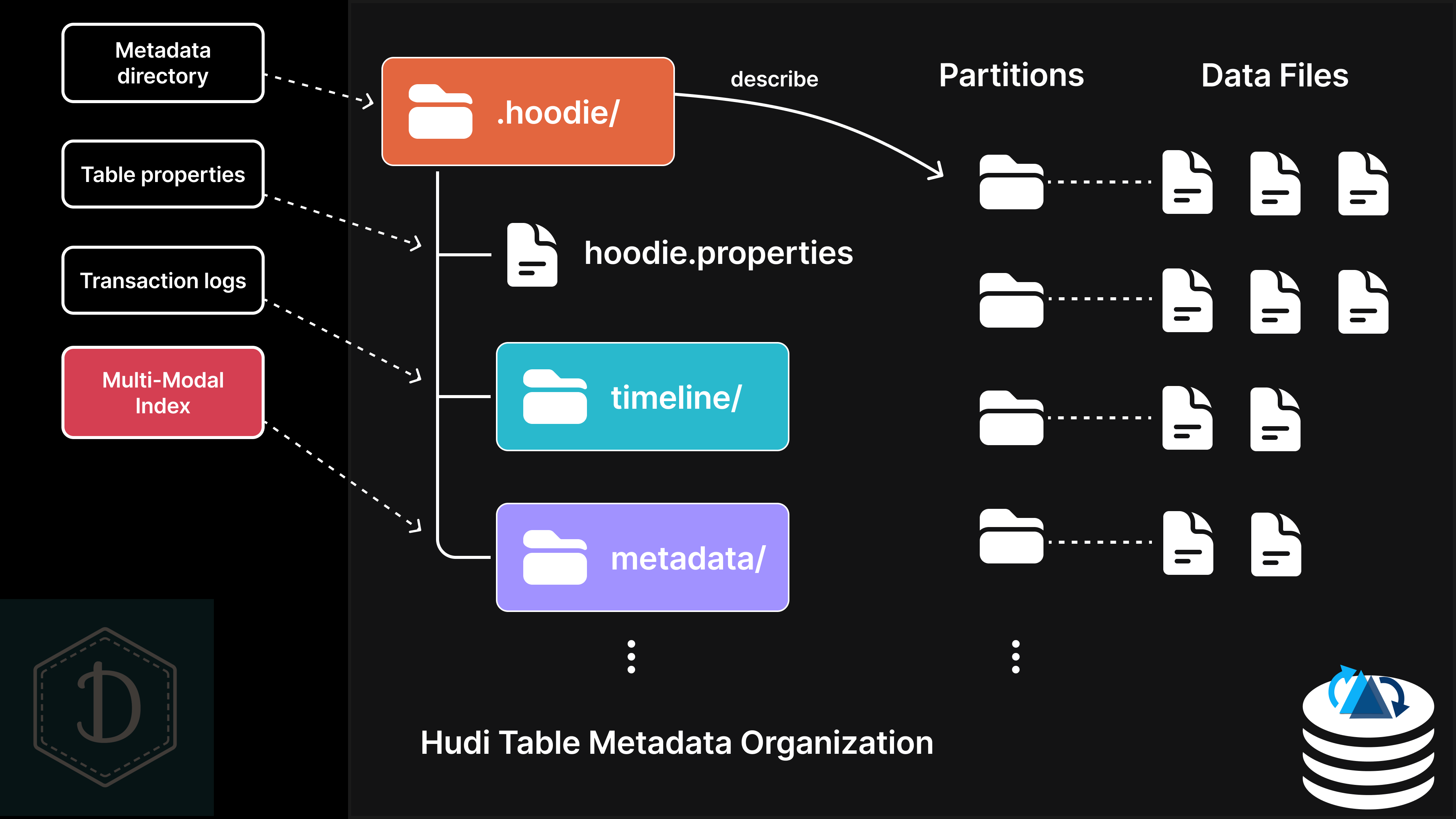
Apache Hudi does XYZ (1/10): File pruning with multi-modal indexJune 16, 2025 byShiyan Xuhudisparkblogcoursetutorialdatumagicdata lakelakehouseapache hudiapache spark
Optimizing Apache Hudi Workflows: Automation for Clustering, Resizing & ConcurrencyJune 13, 2025 byHalodoc, Apache Hudihudibloghalodocdata lakelakehouseapache hudi
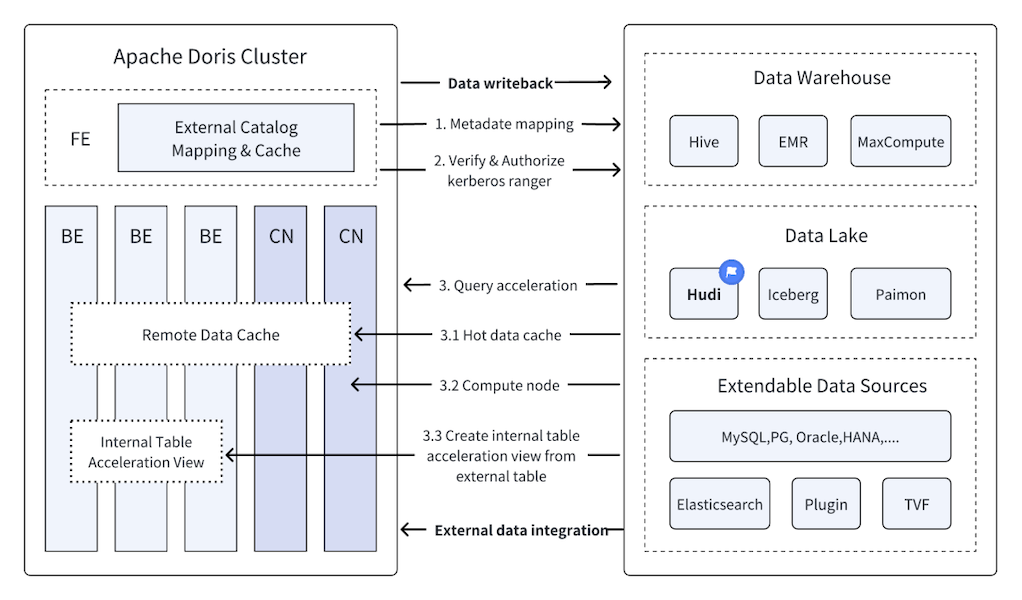
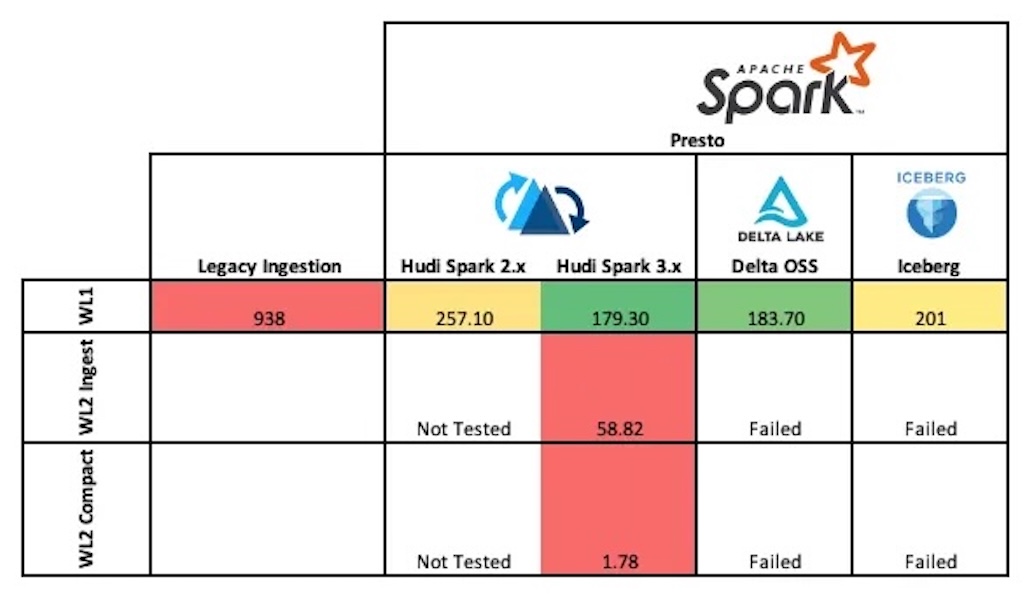
How Doris + Hudi Turned the Impossible Into the EverydayApril 14, 2025 byZen HuablogApache HudiApache Dorisuse-casefederated queryingdzone
From Swamp to Stream: How Apache Hudi Transforms the Modern Data LakeApril 6, 2025 byEverton GomedeblogApache Hudireal-time datalakeincremental processingupsertsmedium
Integrating Apache Doris and Hudi for Data Querying and MigrationApril 3, 2025 byli yyblogApache HudiApache Dorisreal-time queryhow-todzone