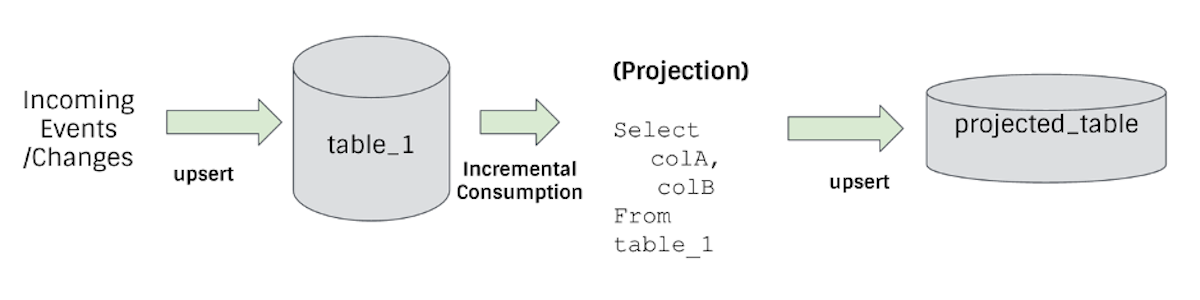
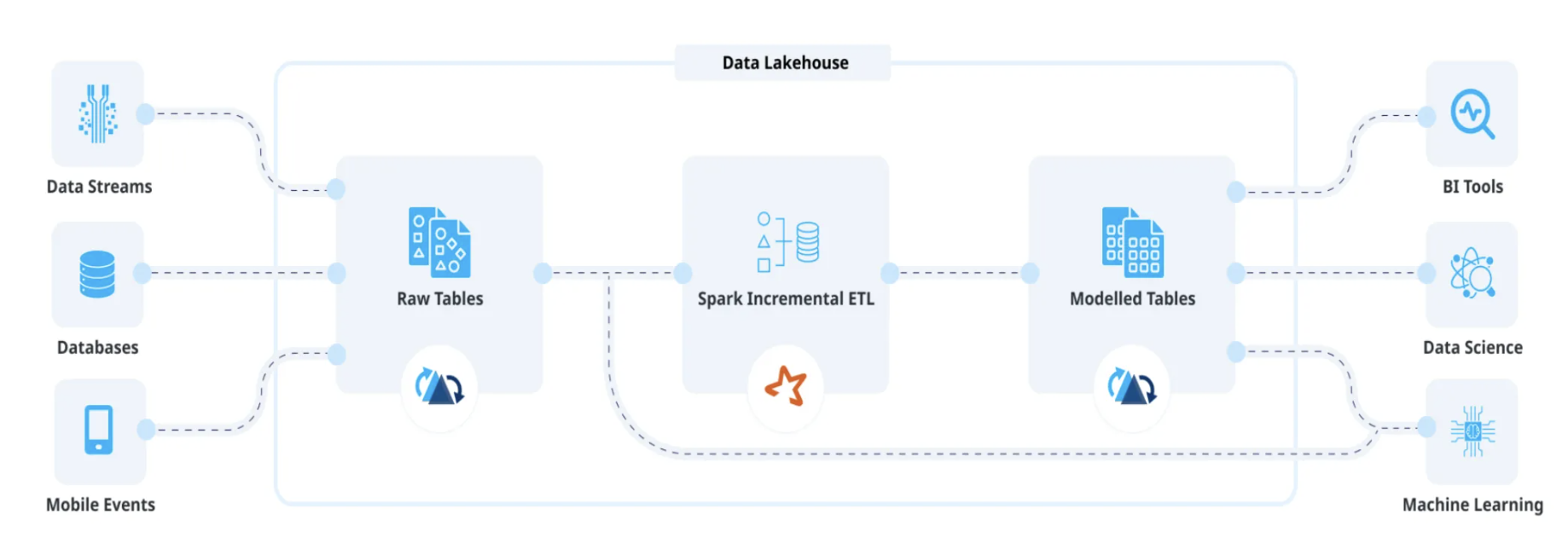
What is Incremental ETL on a Data Lake?July 16, 2026 by Vinoth Chandarincremental processingetlstreamingdata lakehousecdc
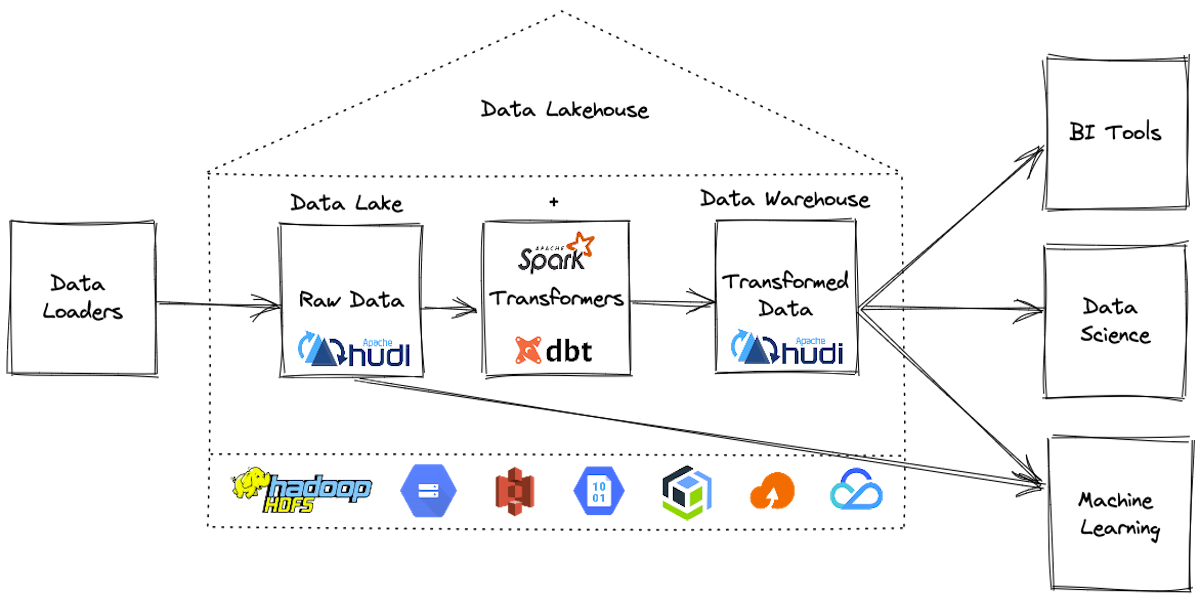
From Swamp to Stream: How Apache Hudi Transforms the Modern Data LakeApril 6, 2025 by Everton Gomededata lakehouseincremental processingdml
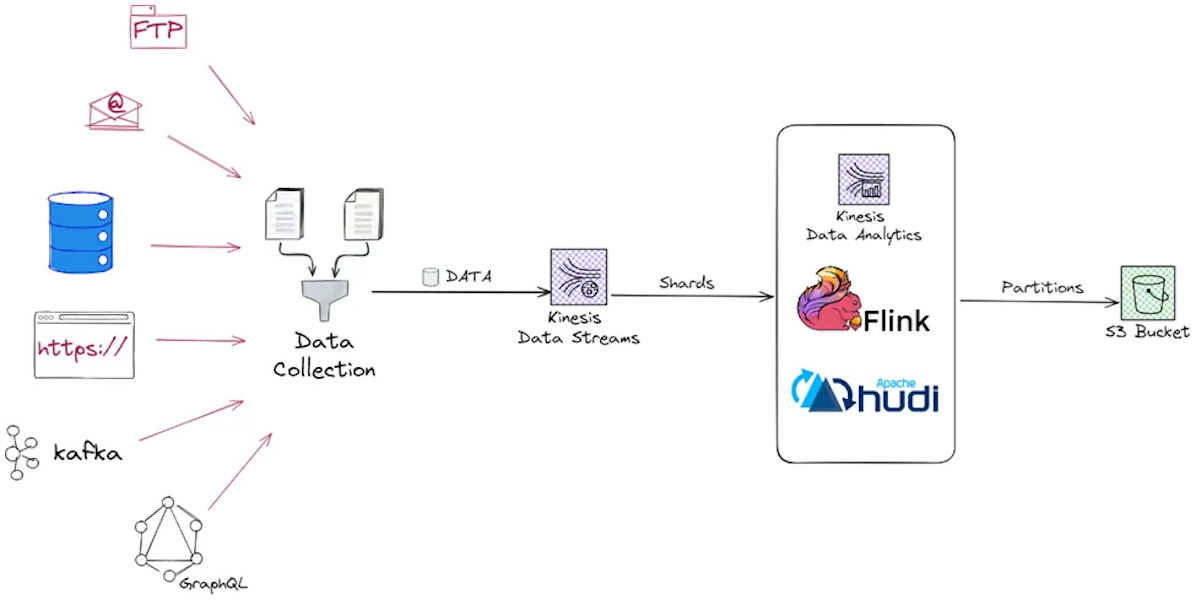
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-onApril 21, 2024 by Md Shahid Afridi Papache flinkawsstreamingdata lakehouseincremental processing
Load data incrementally from transactional data lakes to data warehousesOctober 19, 2023 by Noritaka Sekiyamaincremental processingqueryingaws
Exploring New Frontiers: How Apache Flink, Apache Hudi and Presto Power New Insights at ScaleJune 16, 2023 by Nadine Farahapache flinkprestostreamingonehouseincremental processing
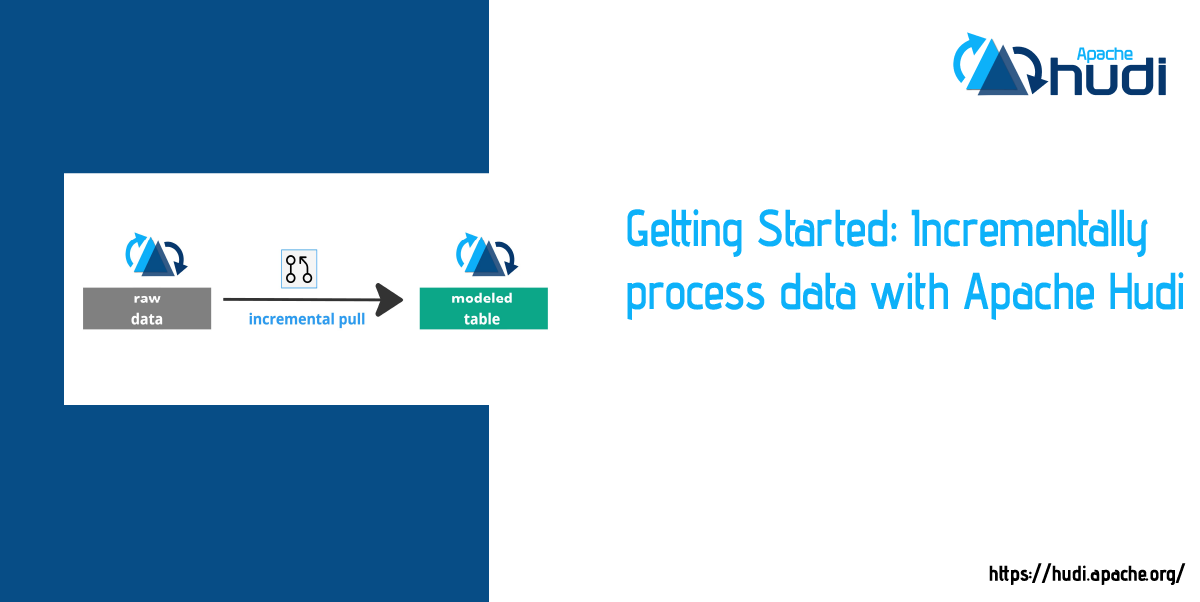
Getting Started: Incrementally process data with Apache HudiApril 18, 2023 by Shiyan Xuincremental processingonehouse
Setting Uber’s Transactional Data Lake in Motion with Incremental ETL Using Apache HudiMarch 16, 2023 by Vinoth Govindarajan, Saketh Chintapalli, Yogesh Saswade and Aayush Barejaincremental processingdata lakehouseuber
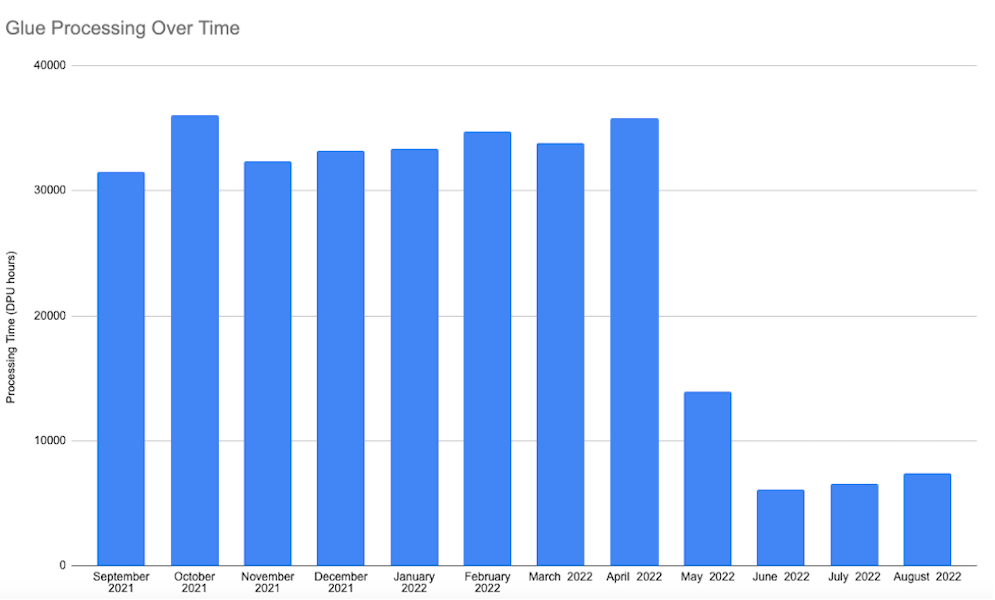
How Hudl built a cost-optimized AWS Glue pipeline with Apache Hudi datasetsNovember 10, 2022 by Indira Balakrishnan, Ramzi Yassine and Swagat Kulkarniperformanceincremental processingbiaws
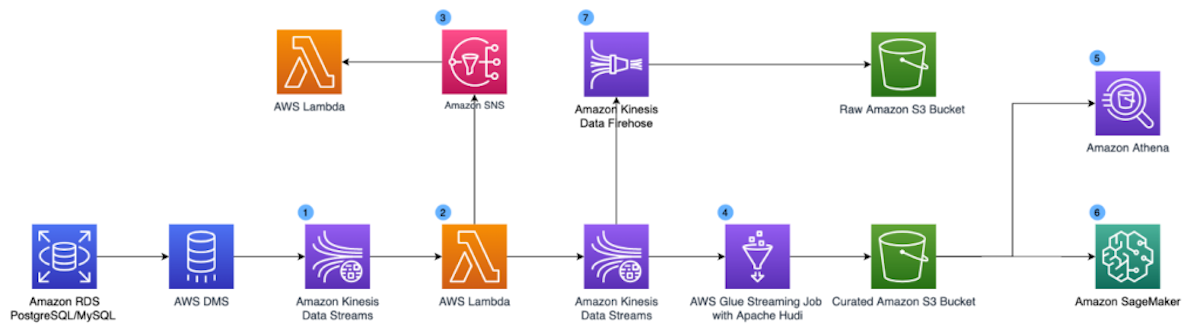
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platformAugust 9, 2022 by Kevin Chun and Dylan Qubiincremental processingaws
Build Open Lakehouse using Apache Hudi & dbtJuly 11, 2022 by Vinoth Govindarajanhudi streamerincremental processing
Key Learnings on Using Apache HUDI in building Lakehouse Architecture @ HalodocApril 4, 2022 by Jitendra Shahdata lakehouseincremental processinghalodoc