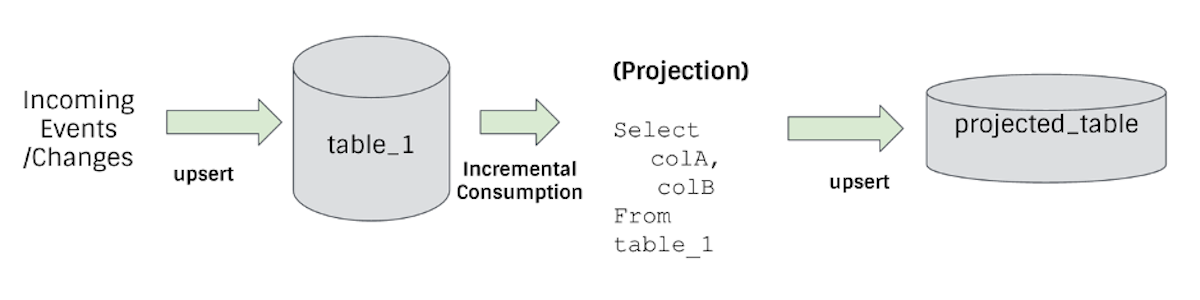
What is Incremental ETL on a Data Lake?July 16, 2026 by Vinoth Chandarincremental processingetlstreamingdata lakehousecdc
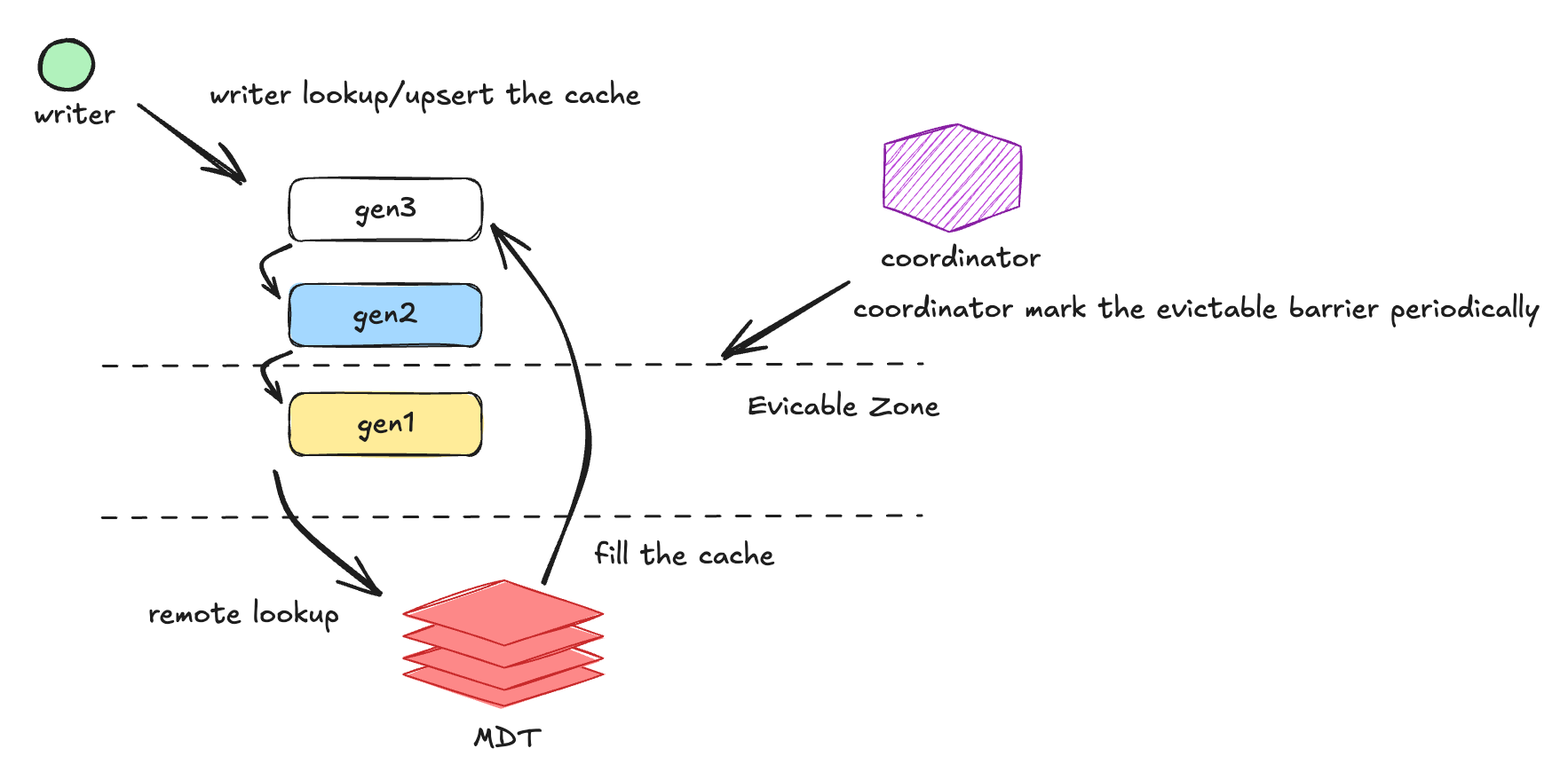
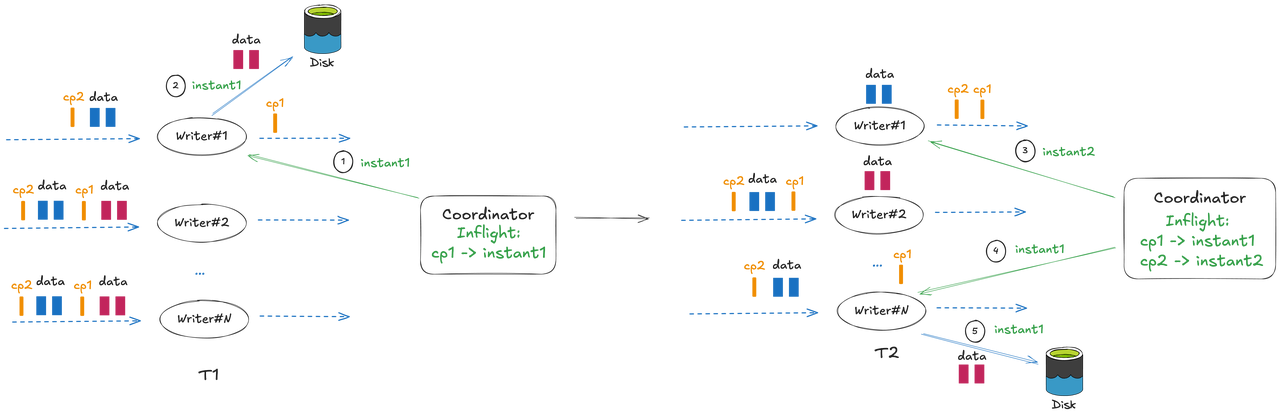
Stateless Global Upserts for Flink Streaming in Apache Hudi 1.2.0June 10, 2026 by Danny Chan and Shuo Chengapache flinkindexingrecord level indexrlistreamingmetadataperformancerelease
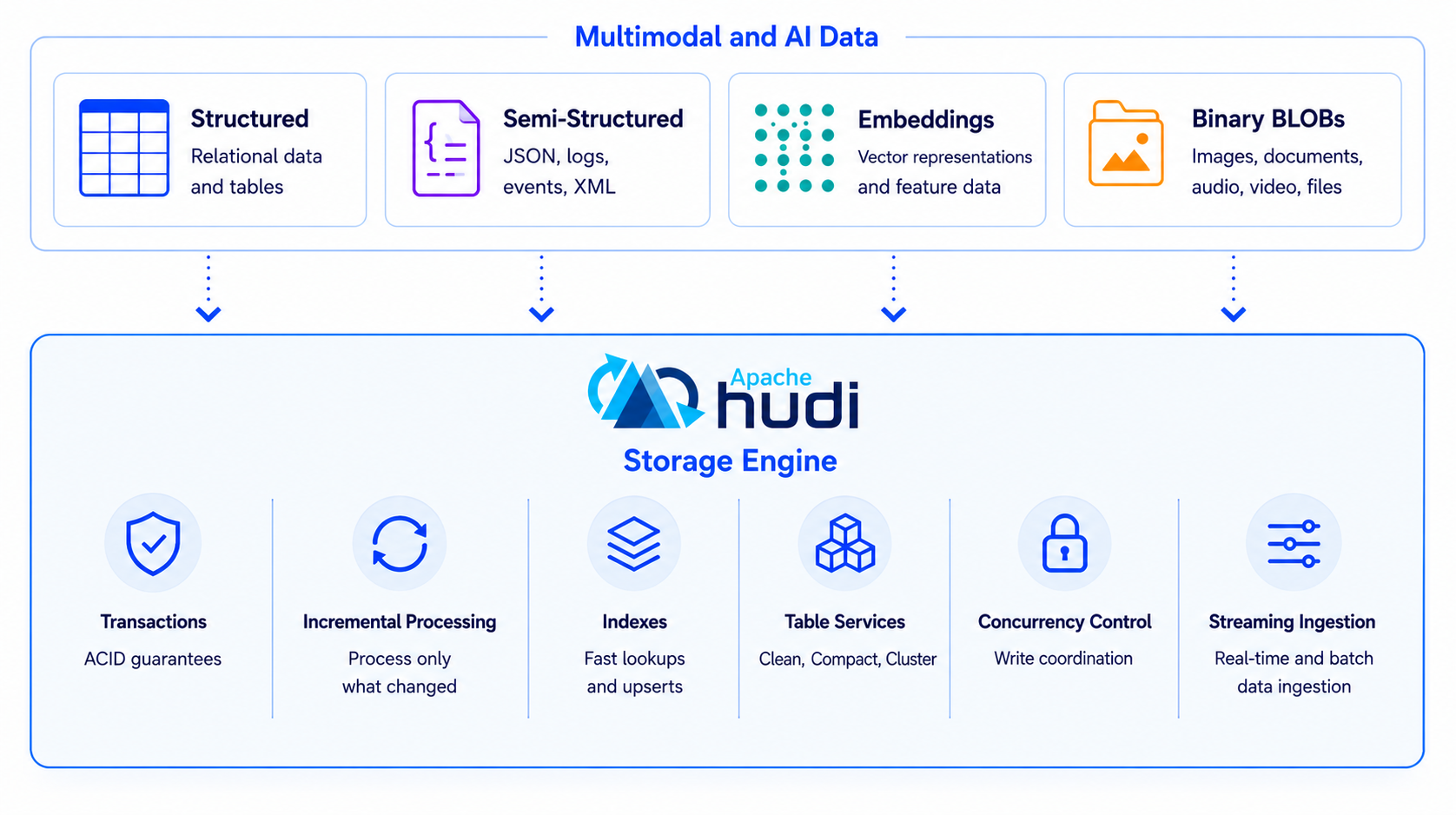
Apache Hudi 1.2: Expanding the Open Lakehouse for AI and Multimodal DataJune 7, 2026 by Rahil Chertara, Sivabalan Narayanan and Ethan Guoreleaseaimultimodalvectorvector searchblobvariantlanceragstreamingconcurrency controllakehouseapache flinkapache spark
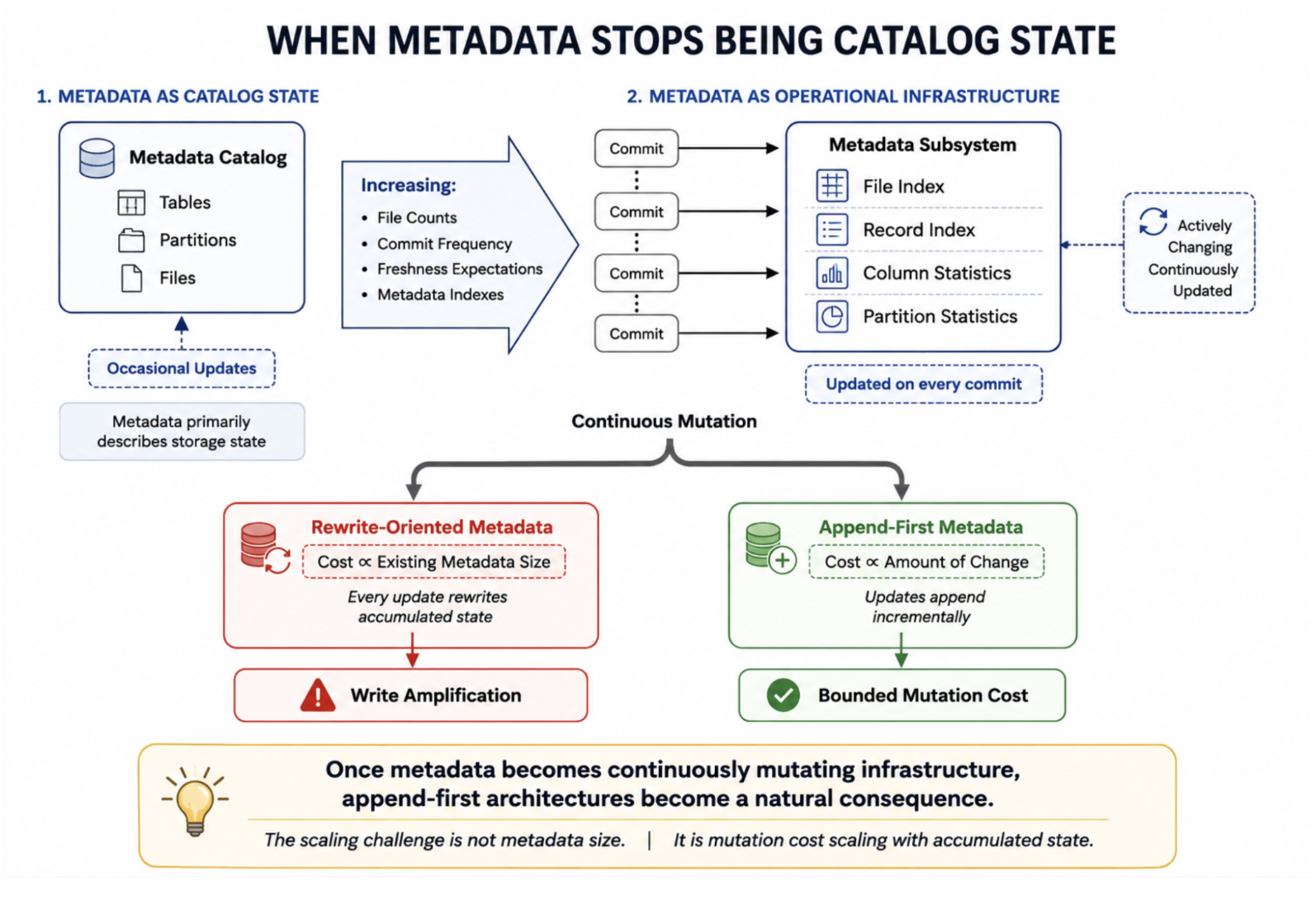
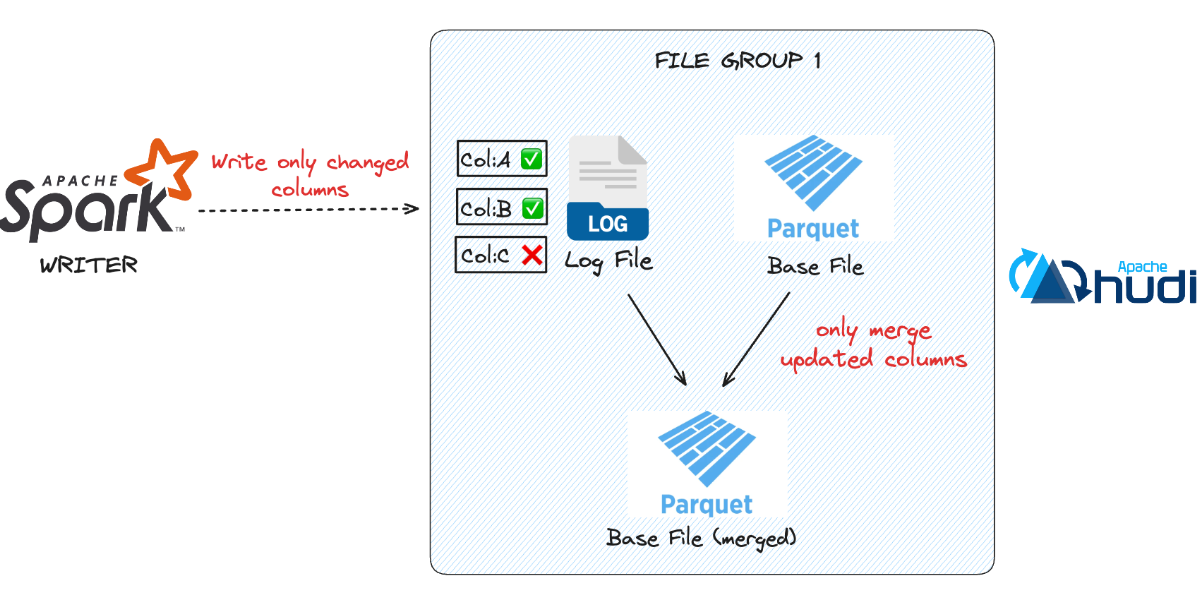
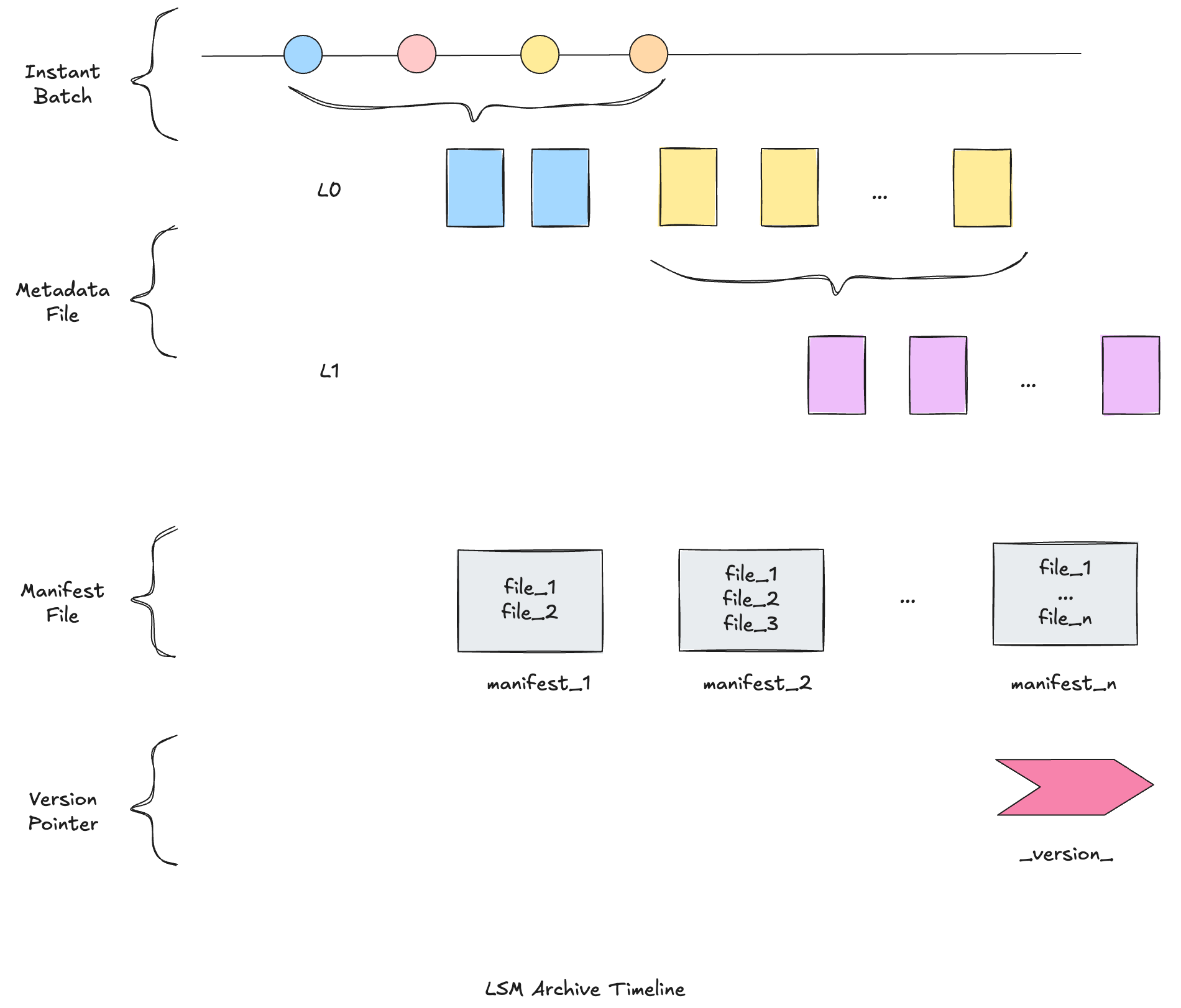
Why Metadata Has to Be Mutation-FriendlyJune 5, 2026 by Sivabalan Narayananmetadatamormerge on readindexingarchitecturedata lakehousestreaming
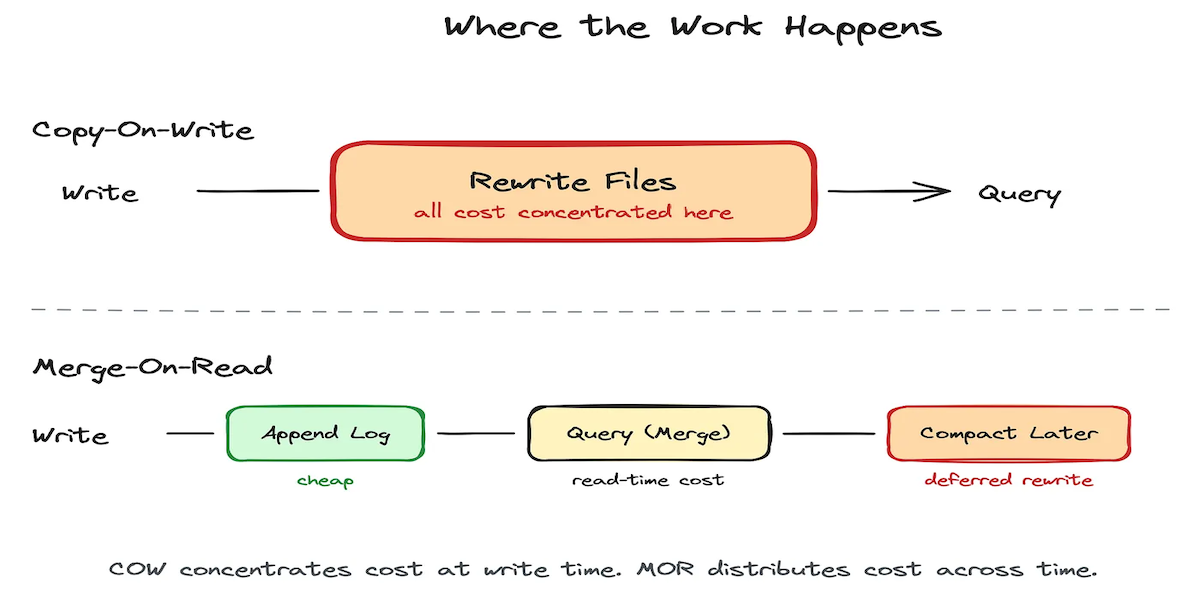
MOR Isn't a Storage Optimization. It's an Architectural ShiftMay 14, 2026 by Sivabalan Narayananmormerge on readarchitecturestreamingcdclakehouse
Apache Hudi 1.1 Deep Dive: Async Instant Time Generation for Flink WritersJanuary 9, 2026 by Shuo Chengapache flinkstreaming
Maximizing Throughput with Apache Hudi NBCC: Stop Retrying, Start ScalingDecember 16, 2025 by Shiyan Xudata lakehouseconcurrency controlstreaming
From Batch to Streaming: Accelerating Data Freshness in Uber's Data LakeDecember 12, 2025 by Uber Engineeringstreamingapache flinkdata lakehouseuber
A Deep Dive on Merge-on-Read (MoR) in Lakehouse Table FormatsJuly 21, 2025 by Dipankar Mazumdarmorstreaming
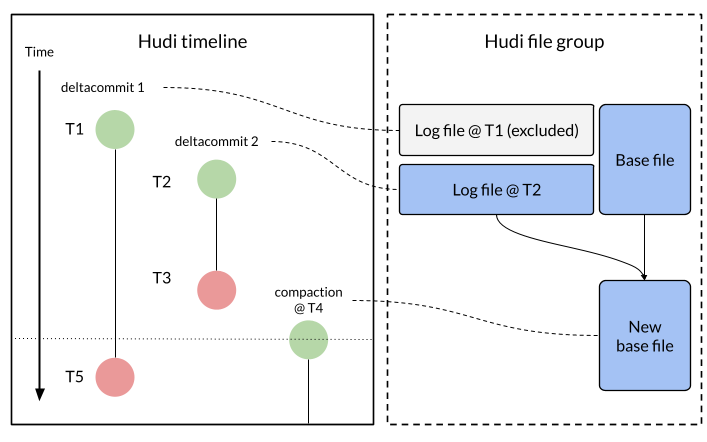
Announcing Apache Hudi 1.0 and the Next Generation of Data LakehousesDecember 16, 2024 by Vinoth Chandarhudi timelinereleasestreamingconcurrency control
Introducing Hudi's Non-blocking Concurrency Control for streaming, high-frequency writesDecember 6, 2024 by Danny Chanstreamingconcurrency control
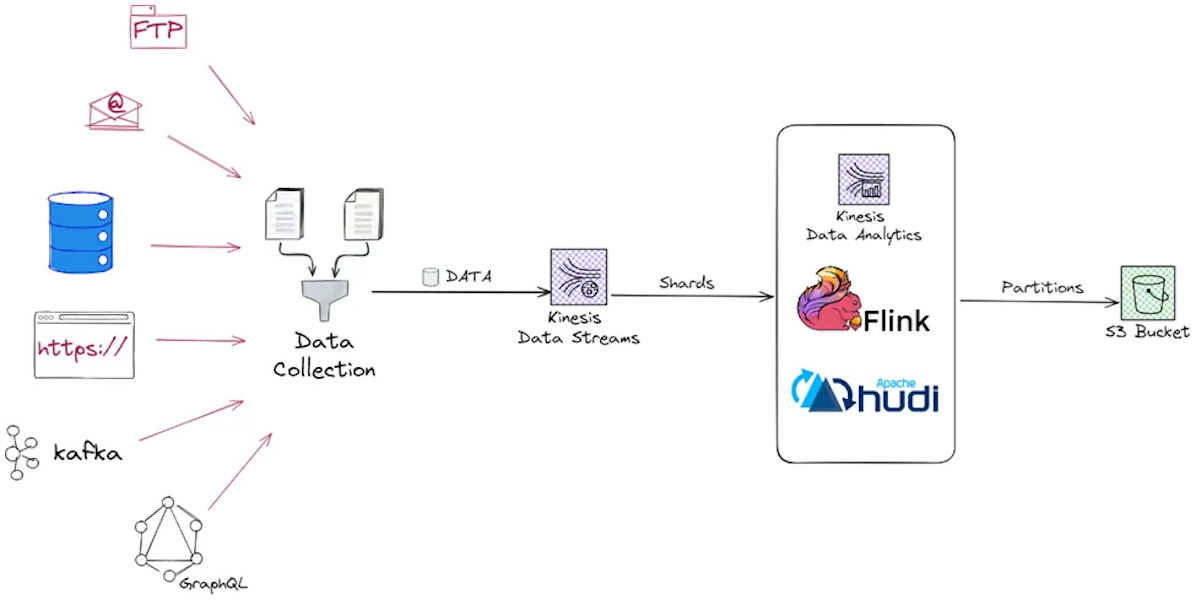
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-onApril 21, 2024 by Md Shahid Afridi Papache flinkawsstreamingdata lakehouseincremental processing