Why Metadata Has to Be Mutation-Friendly

This post is the second in a series on Merge-On-Read as an architectural shift in Apache Hudi. The first post made the broad case; this one focuses on the place where the argument becomes impossible to ignore — the metadata table.
The previous post in this series argued that Merge-On-Read (MOR) is not merely a storage optimization, but an architectural shift — a way of designing systems around the reality that mutation and analytical scans operate at fundamentally different rhythms. That argument was intentionally broad. MOR's effects are distributed across Hudi's architecture: concurrency control, indexing, streaming ingestion, asynchronous services, partial updates, and metadata management all inherit properties from that single design decision. But there is one place where the argument becomes impossible to ignore: the metadata table.
Hudi's metadata table (MDT) is itself a MOR table. That detail can easily look like an implementation choice, but it reflects something much deeper. The MDT exposes what happens when metadata itself becomes a continuously mutating system.
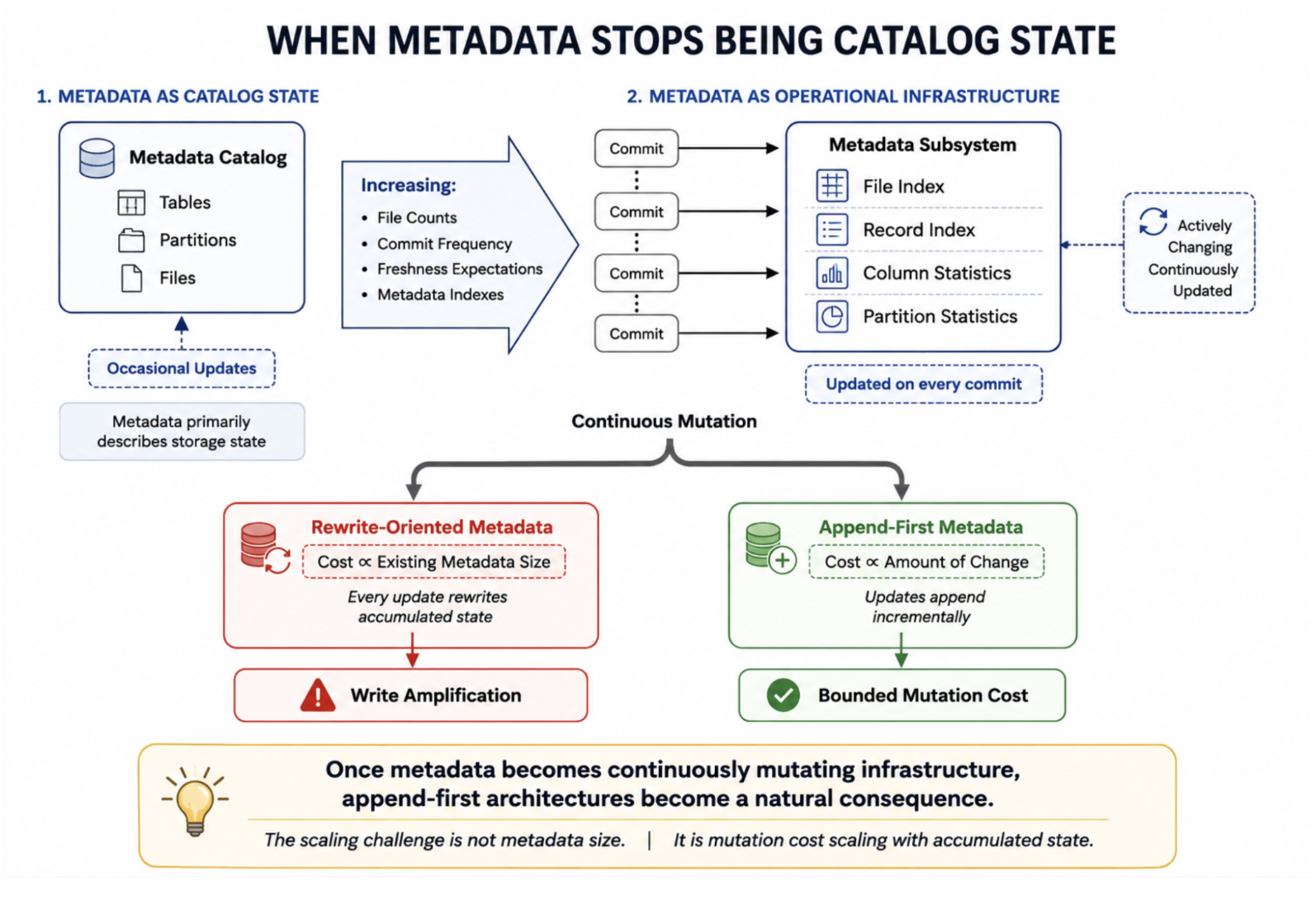
Traditional lakehouse metadata systems were largely designed around immutable replacement. Files changed infrequently, snapshots mostly referenced static objects, and metadata primarily described storage layout. Under those assumptions, metadata behaved more like inventory than coordination — its job was to help readers discover immutable files efficiently. MOR changes that model fundamentally because once updates become incremental, base files stop being complete truth. Mutations accumulate across generations, and state must be reconstructed continuously from evolving fragments. At that point, metadata stops being passive bookkeeping and starts becoming operational infrastructure.
The Hudi MDT makes this visible because it inherits the mutation profile of the data plane itself. Every commit mutates metadata. Every file rewrite, every index update, and every record relocation compounds continuously inside the metadata layer. At sufficient scale, the metadata system itself becomes one of the highest-write-frequency components in the architecture. Under these workloads, Copy-On-Write is not simply inefficient; it becomes structurally misaligned with the problem.
Metadata Before MOR
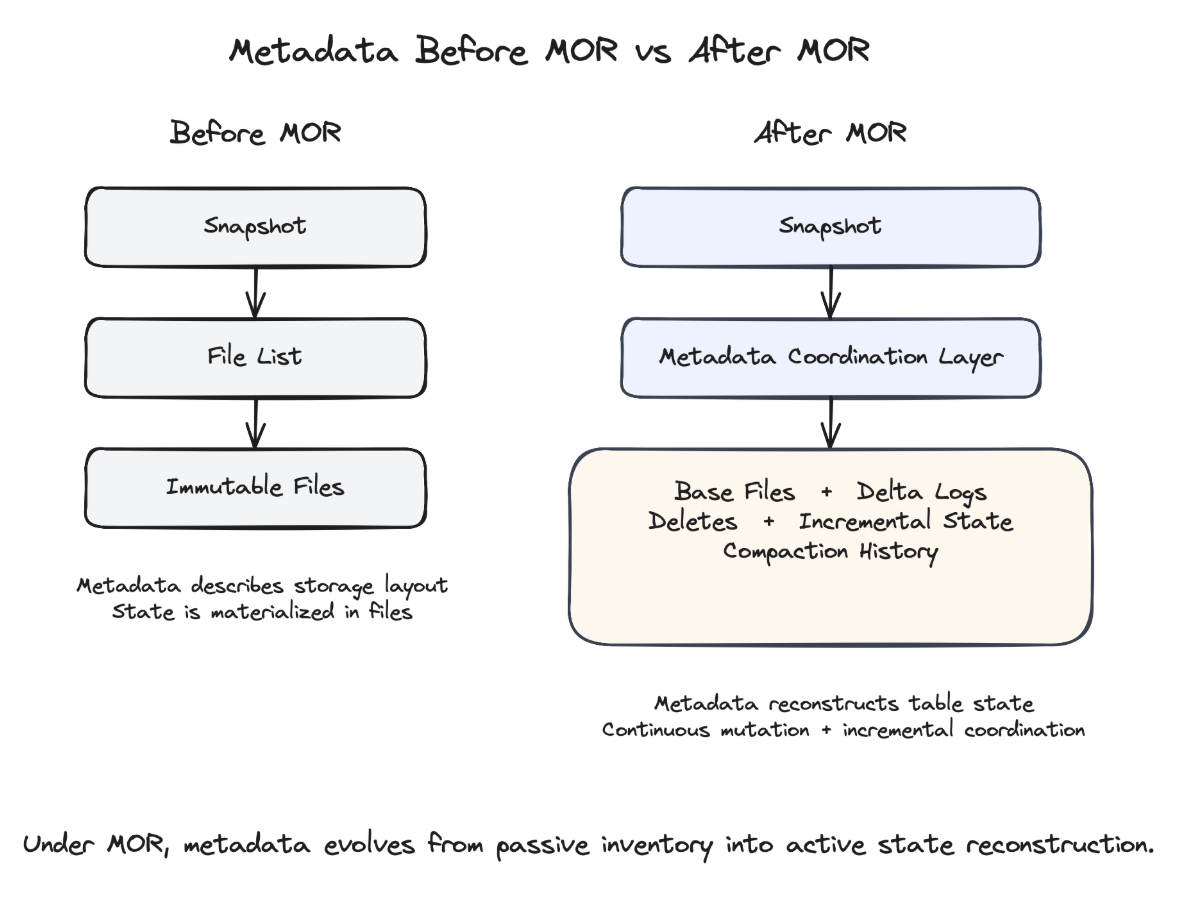
Before MOR-style mutation became common, metadata systems solved a relatively straightforward problem: mapping logical table state onto immutable storage objects.
Metadata tracked what files existed, which partitions contained them, what statistics described them, and which snapshots referenced them. That model worked extremely well when state was already materialized inside immutable files. Readers simply needed efficient mechanisms to locate the correct files and prune unnecessary scans.
In those systems, metadata primarily described storage layout.
MOR changes the nature of the problem because state no longer exists entirely inside base files. Once updates become incremental, truth becomes distributed across base files, delta logs, delete markers, and compaction history. Metadata now has to coordinate how those pieces compose into current table state.
That is the deeper architectural transition. In Copy-On-Write systems, metadata describes files. In Merge-On-Read systems, metadata increasingly describes how to reconstruct truth.
That distinction seems subtle initially, but it has enormous consequences for scalability. Under immutable snapshot-oriented systems, metadata mutation remains relatively infrequent. A new snapshot arrives, some manifests are updated, and readers transition cleanly between versions. But once workloads shift toward streaming ingestion, CDC pipelines, row-level updates, and continuous upserts, the mutation profile changes fundamentally.
Metadata no longer evolves occasionally; it evolves continuously. That transition is what ultimately forces the architectural distinction between rewrite-oriented systems and append-oriented systems.
Why the Metadata Table Changes the Cost Model
The metadata table was introduced to eliminate one of the largest bottlenecks in large-scale lakehouses: filesystem listing. Instead of repeatedly asking object storage, "What files exist in this partition?", Hudi stores that information inside an indexed internal table under .hoodie/metadata/.
But the important architectural detail is not that the MDT stores metadata. It is how the metadata evolves.
The MDT is itself a Hudi table, with its own timeline, file groups, compaction lifecycle, and indexing structures. Over time, it evolved beyond file listing into a generalized metadata substrate supporting a rich set of indexes — record indexes, bloom indexes, column statistics, expression indexes, and additional indexing structures layered into the same append-first architecture.
The files partition alone does not fully explain why MOR becomes necessary. File-listing metadata is often relatively manageable in size, even for large deployments. The deeper pressure comes from the evolution of the metadata table itself.
As the MDT expanded beyond filesystem listings into record indexes, bloom filters, column statistics, and other lookup-oriented structures, the mutation profile changed fundamentally. These metadata partitions are continuously updated, highly incremental, and optimized around lookup efficiency rather than rewrite frequency.
Record-level indexes make the difference especially visible. A high-ingest workload may continuously mutate millions of record-location mappings across existing metadata structures. Under Copy-On-Write, those updates repeatedly rewrite accumulated metadata state. Under MOR, they become incremental append-only mutations that can be compacted later.
That distinction is what changes the economics. The issue is not simply metadata size, but that continuously mutating indexing structures behave fundamentally differently from static catalog metadata. Once metadata evolves into an operational indexing substrate, append-first mutation becomes far more natural than synchronous rewrite-oriented updates.
Interestingly, early MDT design discussions largely treated append-first mutation as a given rather than a tradeoff that needed extensive justification. The focus was not on debating MOR versus COW, but on how to structure continuously evolving metadata efficiently at scale. In hindsight, that assumption reflects how strongly the workload itself constrained the architecture once metadata stopped behaving like static catalog state.
This is the key architectural property MOR introduces:
MOR decouples mutation cost from accumulated state.
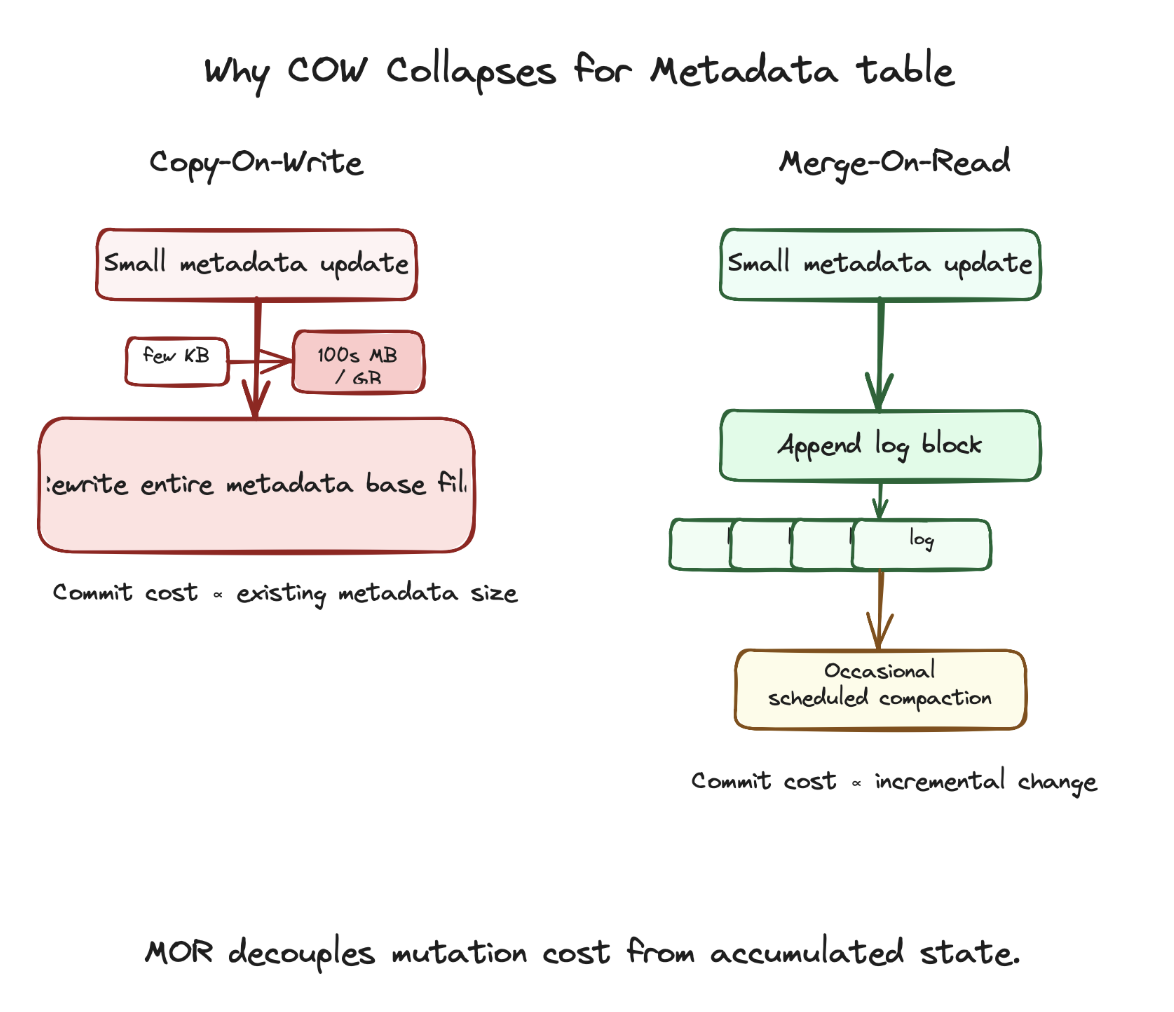
Under COW, metadata write cost scales with the size of existing metadata. Under MOR, metadata write cost scales primarily with the amount of change. That distinction is what makes continuously mutating metadata systems feasible at large scale.
Compaction and Deferred Coordination
MOR does not eliminate rewrite cost. It changes when and how the system pays it.
Eventually, incremental mutations still need to be merged back into optimized base files through compaction. But the important distinction is that compaction becomes schedulable coordination work rather than synchronous commit-path amplification.
Under Copy-On-Write, rewrite cost appears directly on every commit path. Every mutation pays the full rewrite penalty immediately, regardless of how small the incremental change actually is. Under MOR, rewrite cost becomes asynchronous, batchable, deferrable, and operationally controllable.
That separation changes the operational model entirely. Mutation handling and storage optimization become decoupled activities, allowing the system to absorb high-frequency updates incrementally while reorganizing storage on its own schedule.
The result is not simply lower write amplification; it is operational elasticity.
The platform can now decide when compaction runs, how aggressively it runs, how much work it batches together, and what resources it consumes. That flexibility becomes increasingly important as metadata itself evolves into a high-frequency operational subsystem.
Append-First Paradigm Changes the Execution Model
Once mutation becomes append-oriented, entirely different execution patterns become possible.
Streaming metadata writes are a good example. Instead of running metadata updates as a separate sequential phase after a data commit completes, metadata mutations can flow directly inside the same execution DAG as the data write itself. The metadata layer evolves alongside the ingest pipeline rather than lagging behind it.
That execution model becomes difficult to express efficiently under rewrite-oriented storage systems. The underlying base files used by the MDT are optimized for point lookups and immutable reads. They are not naturally designed for continuous streaming mutation. The only practical way to evolve those structures incrementally is to append changes first and reorganize later.
The same pattern appears repeatedly throughout Hudi's architecture. Asynchronous indexing, non-blocking concurrency control, incremental services, and partial updates all inherit properties from the same append-first foundation. Once mutation becomes cheap and incremental, background coordination and asynchronous system evolution become dramatically easier to express.
This is why MOR ends up influencing much more than storage layout — because it changes the execution model of the system itself. Once append-first mutation becomes the default assumption, the system naturally starts evolving toward asynchronous coordination rather than synchronous rewrites. That shift is deeper than storage optimization because it changes how the platform organizes work.
Metadata Scaling Is Becoming the Next Lakehouse Bottleneck
One of the clearest trends across modern lakehouse systems is the increasing focus on metadata scalability itself.
As workloads evolve toward streaming ingestion, CDC, row-level mutation, near-real-time freshness, and continuous upserts, metadata systems increasingly become high-frequency mutation systems.
The scaling pressure shows up everywhere: manifest growth, planning overhead, metadata pruning complexity, incremental reconciliation, mutation tracking costs, and metadata maintenance operations.
At sufficiently large scale, metadata itself starts becoming one of the dominant operational concerns in the system. Large lakehouse deployments operating over tens of millions of files have documented metadata footprints reaching terabyte scale, where planning queries can take unsustainable latencies or fail simply from the amount of metadata that must be processed before execution even begins.
The ecosystem's response increasingly reflects this pressure.
Manifest rewrite operations, metadata maintenance workflows, planning optimizations, deletion tracking systems, and richer metadata hierarchies are becoming necessary parts of operating large mutation-heavy lakehouse deployments. Discussions around metadata bloat, streaming ingestion instability, and metadata compaction increasingly treat metadata itself as an actively evolving operational subsystem rather than static catalog state.
That shift is important because it changes what metadata systems are responsible for. Metadata stops being lightweight bookkeeping and increasingly becomes continuous coordination infrastructure under mutation pressure.
Hudi's architecture started from those assumptions much earlier. The metadata table was designed from the beginning as incrementally mutable, append-oriented, and optimized around continuous metadata evolution.
That same architectural foundation later enabled the MDT to evolve beyond simple file listing into a generalized indexing substrate supporting record indexes, bloom indexes, column statistics, expression indexes, and more adaptive indexing strategies.
The important point is not any individual feature. It is the architectural posture underneath them.
The metadata layer was treated as an operational system from the beginning — not merely a static catalog of immutable files.
What MOR Ultimately Changed
The metadata table is one of the clearest demonstrations of MOR's architectural consequences because the workload pressure is so extreme. Every commit mutates metadata, every mutation compounds continuously, and every scaling problem becomes visible quickly.
Under those conditions, the distinction between COW and MOR becomes more than a storage-layout preference. It becomes a question of whether mutation cost scales with accumulated state or incremental change.
That distinction increasingly defines modern lakehouse architecture.
MOR did not simply optimize write amplification. It changed the role metadata plays inside the system.
Metadata stopped being a lightweight inventory of files and became the machinery responsible for coordinating continuously evolving table state. And once metadata evolves into a continuously mutating system, append-first architecture stops being an optimization. It becomes the natural model for the workload itself.