Apache Hudi 1.2: Expanding the Open Lakehouse for AI and Multimodal Data



The Apache Hudi community is excited to announce the release of Apache Hudi 1.2, a major milestone that makes the open lakehouse ready for the next generation of data and AI. By introducing first-class support for semi-structured data, vectors, and binary objects, Hudi 1.2 unifies multimodal data for Analytics and AI-native applications into a single transactional lakehouse table, eliminating the need to duplicate data across multiple storage silos.
Unified Data Foundation for Analytics and AI
Embracing Multimodal Data: AI-native applications increasingly combine structured records, semi-structured data, embeddings, and binary assets within a single workflow. These data representations are no longer peripheral artifacts. They are becoming core business assets that power search, recommendations, retrieval-augmented generation (RAG), observability, and intelligent applications.
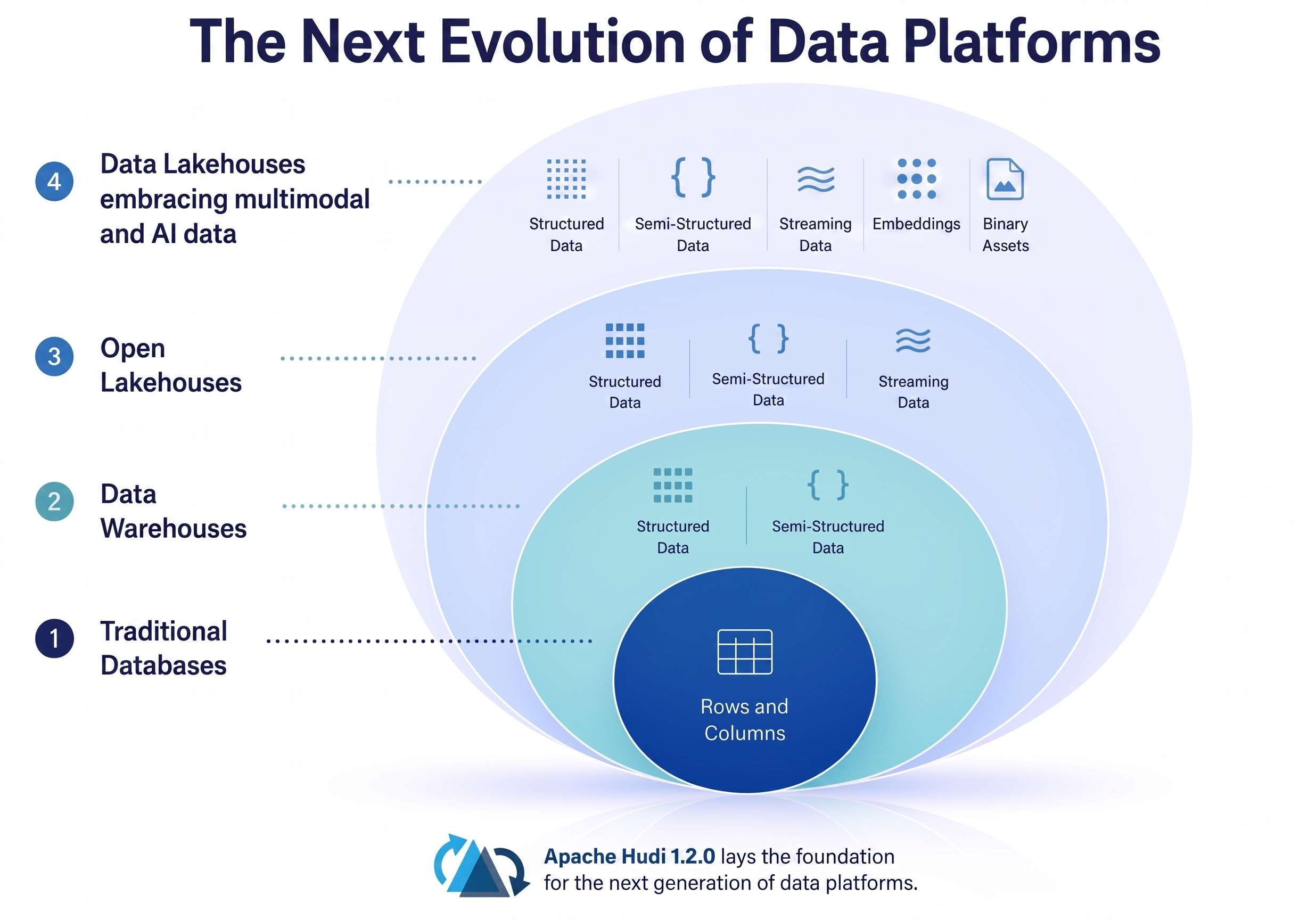
When the lakehouse architecture emerged, it promised a single, open platform capable of managing all structured, semi-structured, and unstructured data. In reality, however, the industry’s focus over the last few years has largely centered on analytical workloads. As a result, most lakehouse deployments have become highly optimized for BI, reporting, and large-scale analytics, while support for embeddings, binary objects, and other AI-centric data types has remained relatively limited.
History shows that restricting a data platform to a single data paradigm leads to storage silos. Continuously expanding support for multimodal data is a must: every major generation of data systems eventually broadens the range of data it can natively understand and manage. Relational databases like Postgres, and Oracle evolved beyond rows and columns to support semi-structured and domain-specific data. Search engines such as ElasticSearch and OpenSearch evolved from keyword retrieval to vector search. Data warehouses like Redshift and Snowflake embraced nested and semi-structured data as analytics workloads became more sophisticated.
Today, Lakehouses are positioned to natively embrace semi-structured and unstructured data within the storage engine, unlocking a unified data foundation for modern AI.
The Fragmented Modern Reality and the Sync Dilemma: For the first time, AI and large language models (LLMs) can reason directly over natural, unstructured data: text, documents, web pages, voice, images, and video.
Consider how this shifts real-world workloads:
- Content Optimization: Instead of engineering complex pipelines to strip HTML and extract structured data for Search Engine Optimization (SEO), storing raw internet content with the document structure intact is preferable for modern Answer Engine Optimization (AEO) or Generative Engine Optimization (GEO).
- Autonomous Driving: Rather than transforming a multimodal stream of sensor data, video feeds, and crash logs into structured fields, models can analyze the entire event context natively.
Driven by use cases like RAG, multimodal applications, and semantic search, modern workloads now depend entirely on such data that traditional lakehouses were never designed to serve.
This shift is creating a new operational challenge. A single core asset may now exist simultaneously as structured metadata in a lakehouse, embeddings in a vector database, documents and images in object storage, and semi-structured data in a document store. While these architectures unlock powerful new capabilities, they also create a fragmented data landscape where multiple representations of the same entity must be continuously synchronized. As data volumes grow and update frequencies increase, maintaining consistency across these systems becomes increasingly difficult. There is now a growing sync dilemma around data management for AI applications.
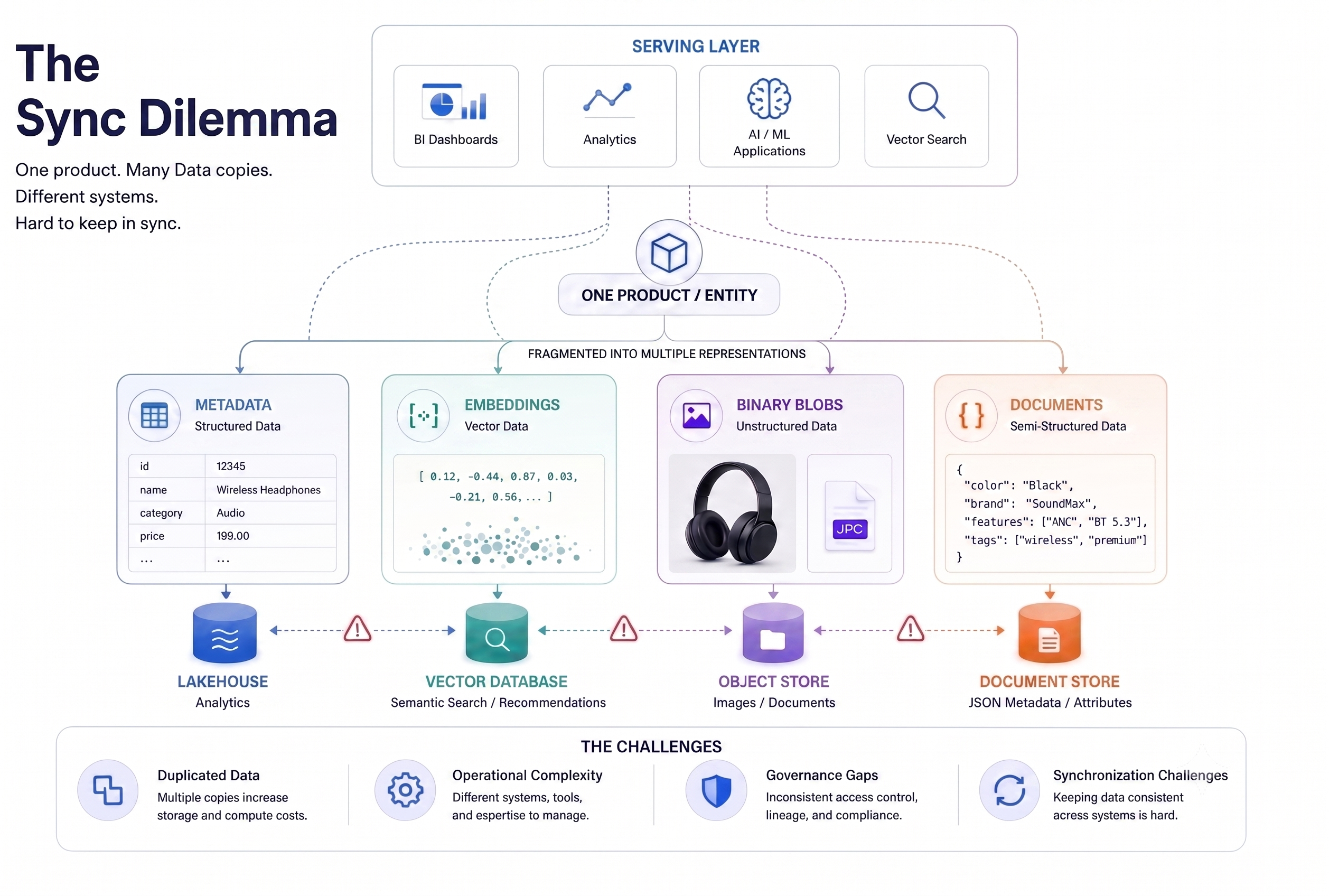
Managing Multimodal and AI Data directly on Apache Hudi: We believe organizations should not need separate databases, warehouses, or even another specialized "AI lakehouse": structured records, documents, images, and embeddings all drive the same business workflows. Isolating semi-structured and unstructured data into specialized databases, warehouses, or Lakehouses introduces data silo, complex synchronization, and operational overhead. AI as a technology impacts all aspects of the business and thus should be natively supported on the mainstream lakehouse or data lake directly, alongside existing data.
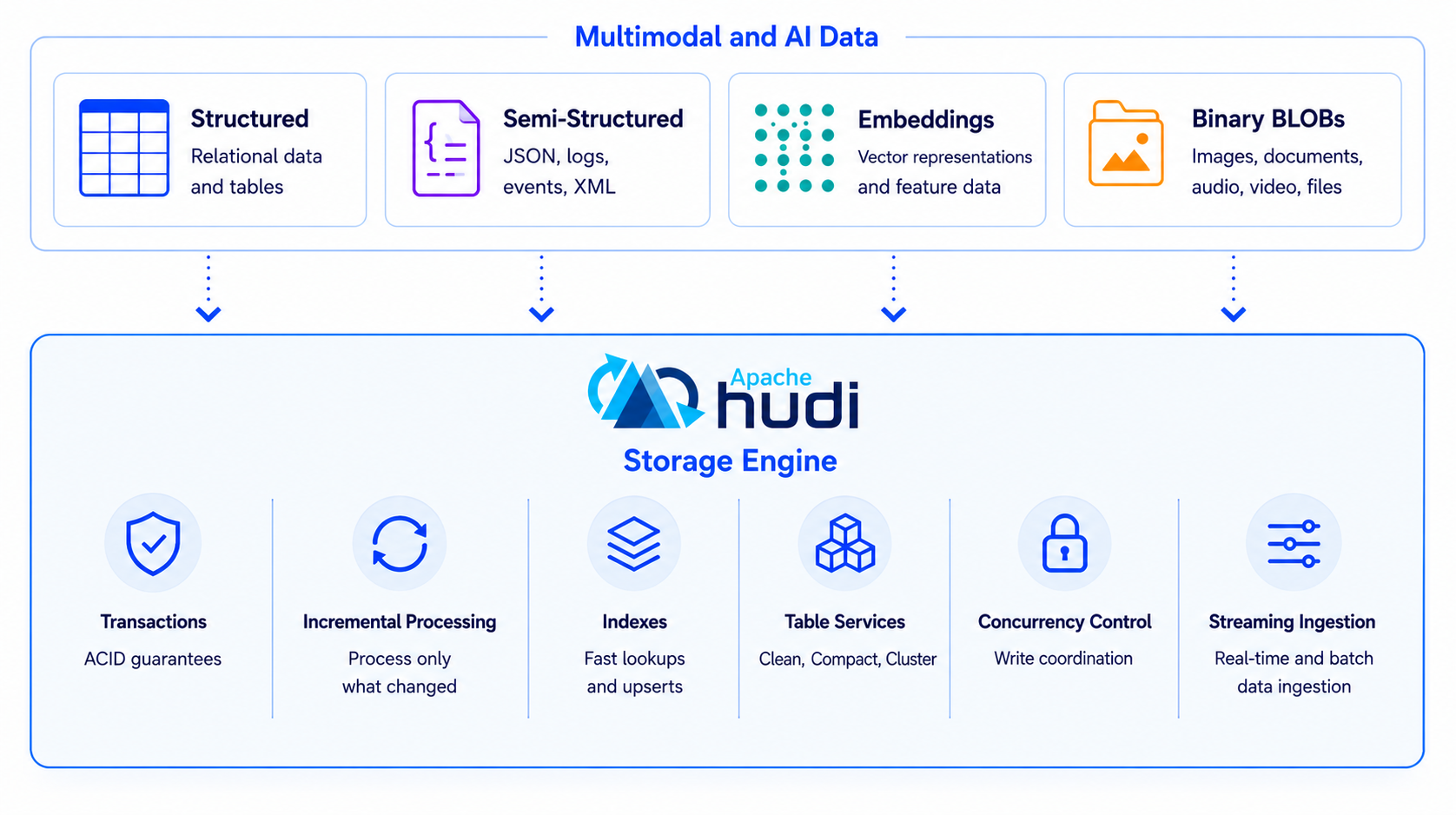
The solution is to naturally evolve the existing lakehouse to support the data types used by modern AI applications. Hudi 1.2 delivers this unified foundation for both analytics and AI workloads. By introducing native VECTOR, BLOB, and VARIANT data types directly into the engine, Hudi eliminates the need for an additional specialized storage layer. Multimodal data seamlessly inherits the same operational foundation from Hudi that already powers large-scale lakehouse deployments:
- Transactional Timeline: guarantees atomic updates and consistency across structured, semi-structured, and binary datasets simultaneously.
- Incremental Processing: efficiently tracks and captures change streams for multimodal records to minimize pipeline latency.
- Advanced Indexing: powers fast lookups and point updates, completely avoiding the brute-force table scans common when handling complex AI datasets.
- Automated Table Services: executes background cleaning, compaction, clustering, and layout optimization across text, vectors, and blobs without manual intervention.
- Multi-Writer Concurrency Control: secures transactional integrity across high-throughput streaming and concurrent AI workloads.
- Open Lakehouse Ecosystem: exposes multimodal assets natively to the existing analytical stack, spanning Spark, Flink, Trino, Athena, and cloud object storage.
Release Highlights
Apache Hudi 1.2 expands the lakehouse for multimodal and AI workloads while continuing to strengthen its streaming and operational foundations.
- Native VECTOR Type and Vector Search: First-class support for embeddings with built-in similarity search directly on Hudi tables.
- Native BLOB and VARIANT Support: Store binary objects, documents, images, and semi-structured data alongside traditional analytical records.
- Lance File Format Integration: Optimized storage for vector and multimodal data, for AI workloads within the Hudi ecosystem.
- Major Flink Performance Boosts: Record Level Index support, dynamic bucket scaling, and a new FLIP-27 based source for large-scale streaming workloads.
- Distributed Co-ordination at Scale: Expanded multi-writer concurrency control, automated table services, and operational improvements across the platform.
Technical Deep Dives
Native VECTOR Type and Built-in Vector Search
Embeddings have become a fundamental building block of modern AI systems. Whether powering retrieval-augmented generation (RAG), recommendation systems, semantic search, or clustering, embeddings provide the representation layer that allows machines to reason about similarity and meaning. Hudi 1.2 introduces VECTOR as a first-class logical type, allowing embeddings to be represented explicitly within the table schema rather than as generic arrays. This provides a consistent abstraction that storage formats and query engines can optimize around while preserving interoperability across workloads.
Alongside VECTOR, Hudi introduces built-in vector search capabilities directly on Hudi tables. Rather than exporting embeddings into a separate vector database, retrieval logic can remain within the lakehouse and participate in the same SQL workflows as the rest of the data platform. This allows organizations to manage embeddings within the same transactional and operational framework as their analytical data.
CREATE TABLE products (
id BIGINT,
title STRING,
embedding VECTOR(1024)
) USING hudi
TBLPROPERTIES (primaryKey = 'id');
SELECT *
FROM hudi_vector_search(
table => 'products',
embedding_col => 'embedding',
query_vector => ARRAY(0.12F, -0.03F, 0.81F, ...),
k => 10,
distance_metric => 'cosine'
)
ORDER BY _hudi_distance;
The initial implementation performs distributed brute-force search, while ongoing community work on native vector indexing and ANN acceleration will significantly improve similarity search performance without changing the query interface. For more information please refer to RFC 102.
Native Support for Binary and Semi-Structured Data
Modern AI applications increasingly manage more than structured records. Images, documents, audio, video, application logs, model outputs, agent traces, and telemetry have become first-class data assets. Hudi 1.2 introduces two new logical types to embrace such data types.
BLOB introduces native support for binary objects within Hudi, enabling images, documents, audio, video, and other unstructured assets to be managed directly in the lakehouse. Both inline and out-of-line variants are supported. Hudi also added support for read_blob() table-valued function to enable lazy materialization for efficient access to metadata for applications. VARIANT introduces native support for semi-structured data, preserving rich hierarchical structures without requiring rigid schemas. Together, these capabilities allow structured data, binary objects, and semi-structured data to coexist within the same transactional lakehouse table.
CREATE TABLE media_assets (
asset_id STRING,
content BLOB,
metadata VARIANT
) USING hudi
TBLPROPERTIES (primaryKey = 'asset_id');
SELECT read_blob(content) FROM media_assets WHERE asset_id = '001';
Lance File Format Support
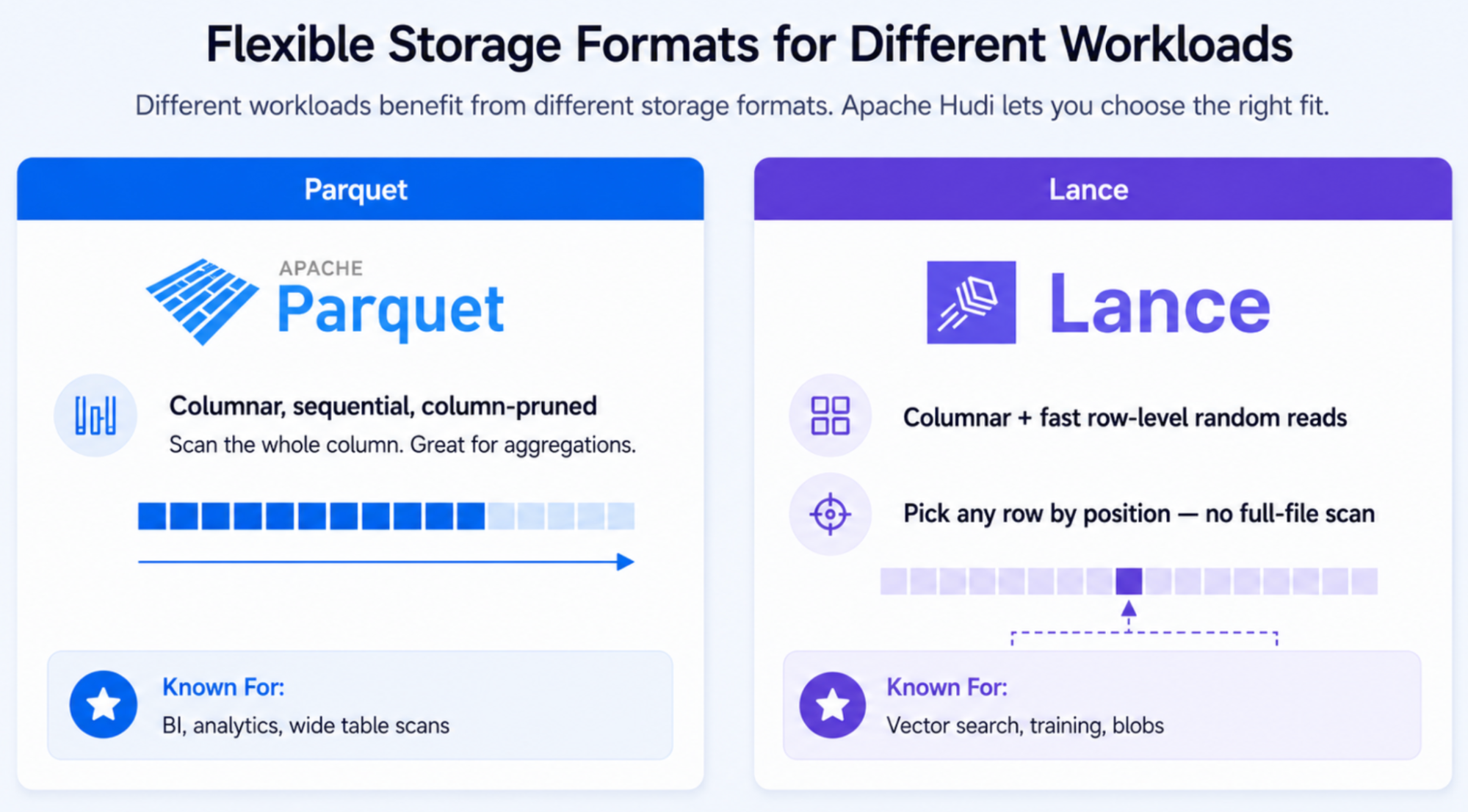
While VECTOR, BLOB, and VARIANT establish the logical foundation for multimodal data in Hudi, different workloads often require different storage layouts. Traditional analytical workloads favor columnar scans and aggregations, while vector search and multimodal applications benefit from storage formats optimized for high-dimensional vectors and random access patterns.
To address these needs, Hudi 1.2 adds support for the Lance file format alongside Parquet, ORC, and HFile. Rather than forcing users to choose between analytical and AI-optimized storage systems, Hudi allows multiple storage formats to participate in the same table abstraction. Users can choose the format that best matches their workload while preserving the same transactional guarantees, indexing infrastructure, table services, and ecosystem integrations.
Scaling Real-Time AI and Streaming Workloads
AI systems are only as useful as the freshness of the data they operate on. Recommendation engines continuously ingest user interactions. Retrieval systems require updated embeddings as source content evolves. Observability platforms process a constant stream of traces, logs, and model events. As AI workloads become increasingly real-time, the infrastructure responsible for moving and managing data must scale accordingly.
Hudi 1.2 includes significant investments across Flink ingestion, indexing, and streaming reads. Record Level Index (RLI), one of Hudi's signature indexing technologies for large-scale upsert workloads, is now available for Flink, bringing efficient record routing, global indexing, and dynamic bucket scaling to streaming deployments.
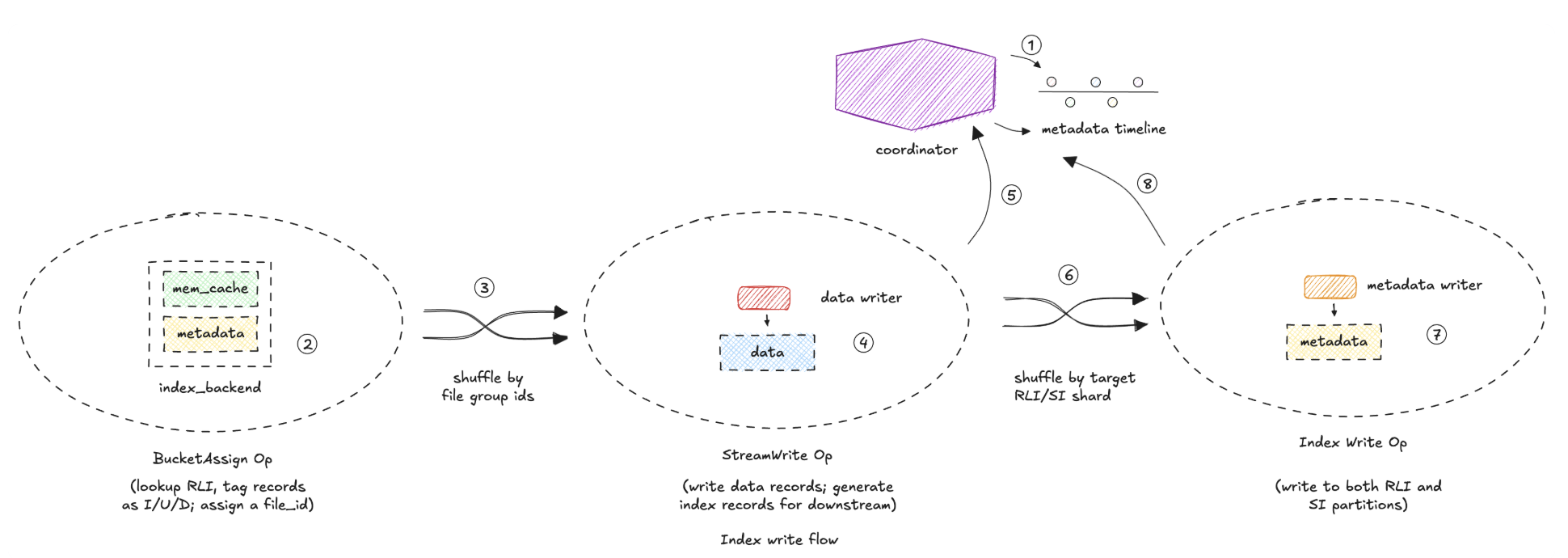
The release also introduces a new FLIP-27 based Flink Source V2 with resumable split assignment, improved fault tolerance, and stronger pushdown capabilities. Together, these improvements strengthen Hudi's ability to power large-scale real-time AI and streaming workloads.
Operational Foundations: Table Services and Multi-Writer Concurrency
Supporting multimodal and AI workloads requires more than new data types. Large-scale data platforms must also manage storage growth, optimize file layouts, coordinate concurrent writers, and maintain predictable performance over time. These operational concerns are often where specialized systems introduce additional complexity.
Hudi 1.2 continues to strengthen the lakehouse foundation through investments in table services, metadata management, and concurrency control. Cleaning and clustering gain new planning and automation capabilities, while cloud-native multi-writer support now extends across all major cloud providers through native storage-based locking for S3, GCS, Azure Blob Storage, and ADLS Gen2. Together with Hudi's ACID guarantees, incremental processing framework, and automated table services, these capabilities help organizations operate large-scale lakehouse deployments without building custom operational tooling.
What's Next
Apache Hudi 1.2 introduces new capabilities for vectors, binary objects, and semi-structured data, but more importantly, it lays the foundation for bringing multimodal data into the lakehouse. We believe the future of data platforms will be defined not by new silos for every data type, but by a unified foundation that can manage structured, semi-structured, and multimodal data within the same transactional and operational framework.
The community is already investing in the next generation of capabilities, including:
- Native vector indexing and ANN acceleration
- VARIANT shredding and nested-field pushdown
- Smarter storage layouts for multimodal workloads
- Continued investments in streaming scalability, indexing, and operational automation
Whether you are building retrieval systems, recommendation engines, AI observability platforms, multimodal datasets, or large-scale streaming applications, we invite you to try Apache Hudi 1.2 and help shape the future of the open lakehouse.
Check out the 1.2 release notes and quick start guides to learn more. Join the Apache Hudi community on Slack, GitHub, LinkedIn, X, and the dev@hudi.apache.org mailing list. We look forward to building the next generation of the open lakehouse together.