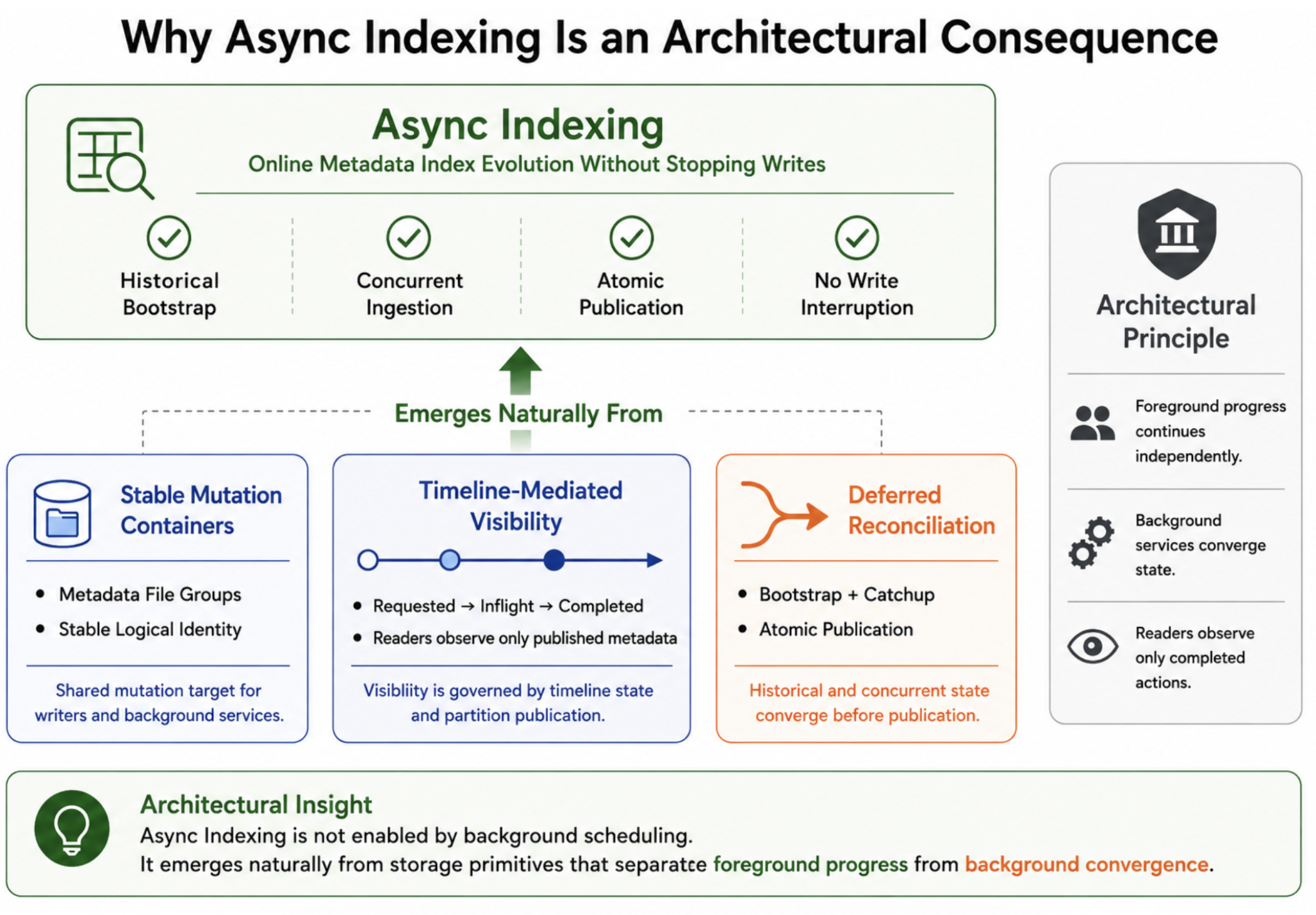
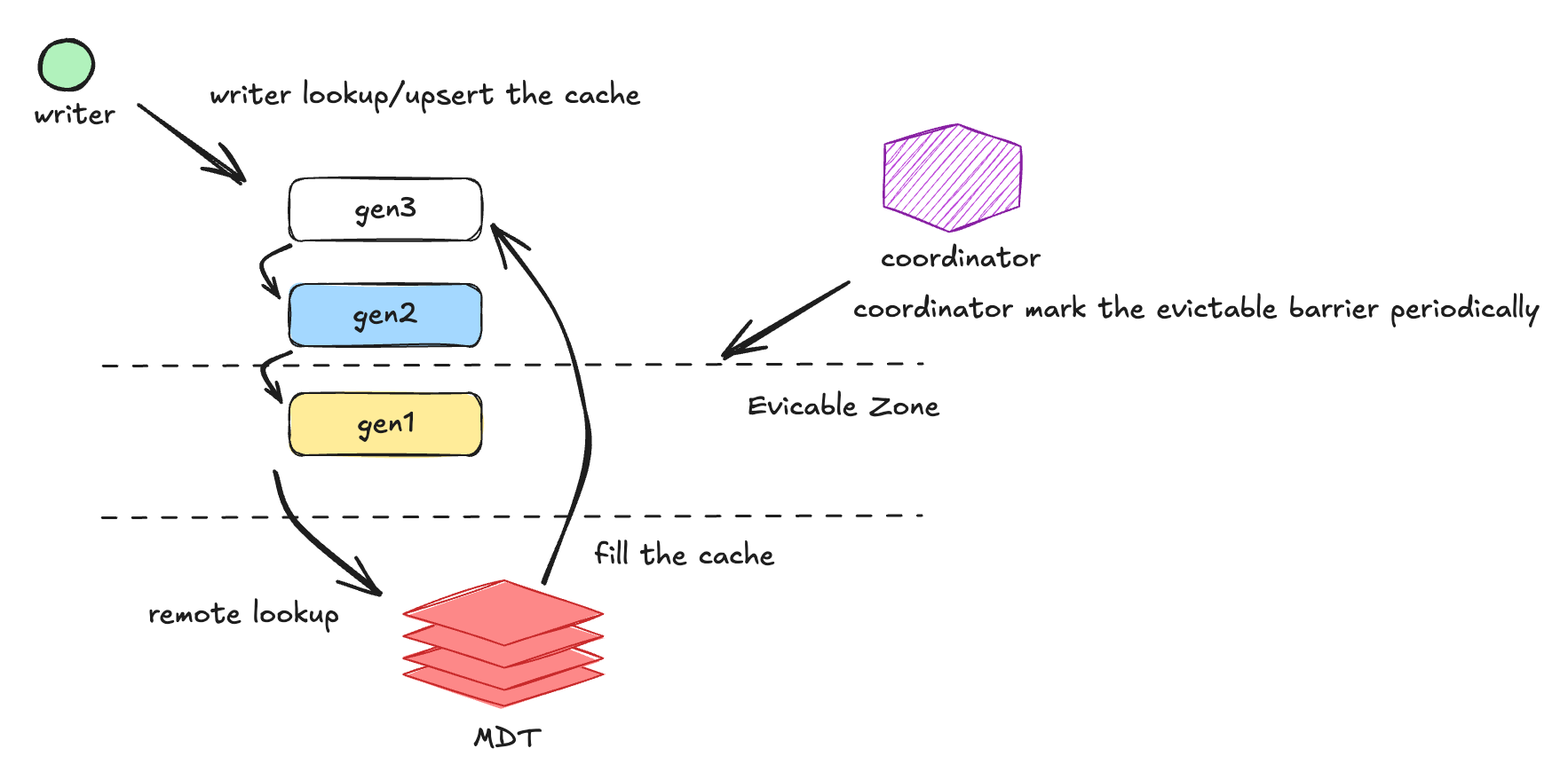
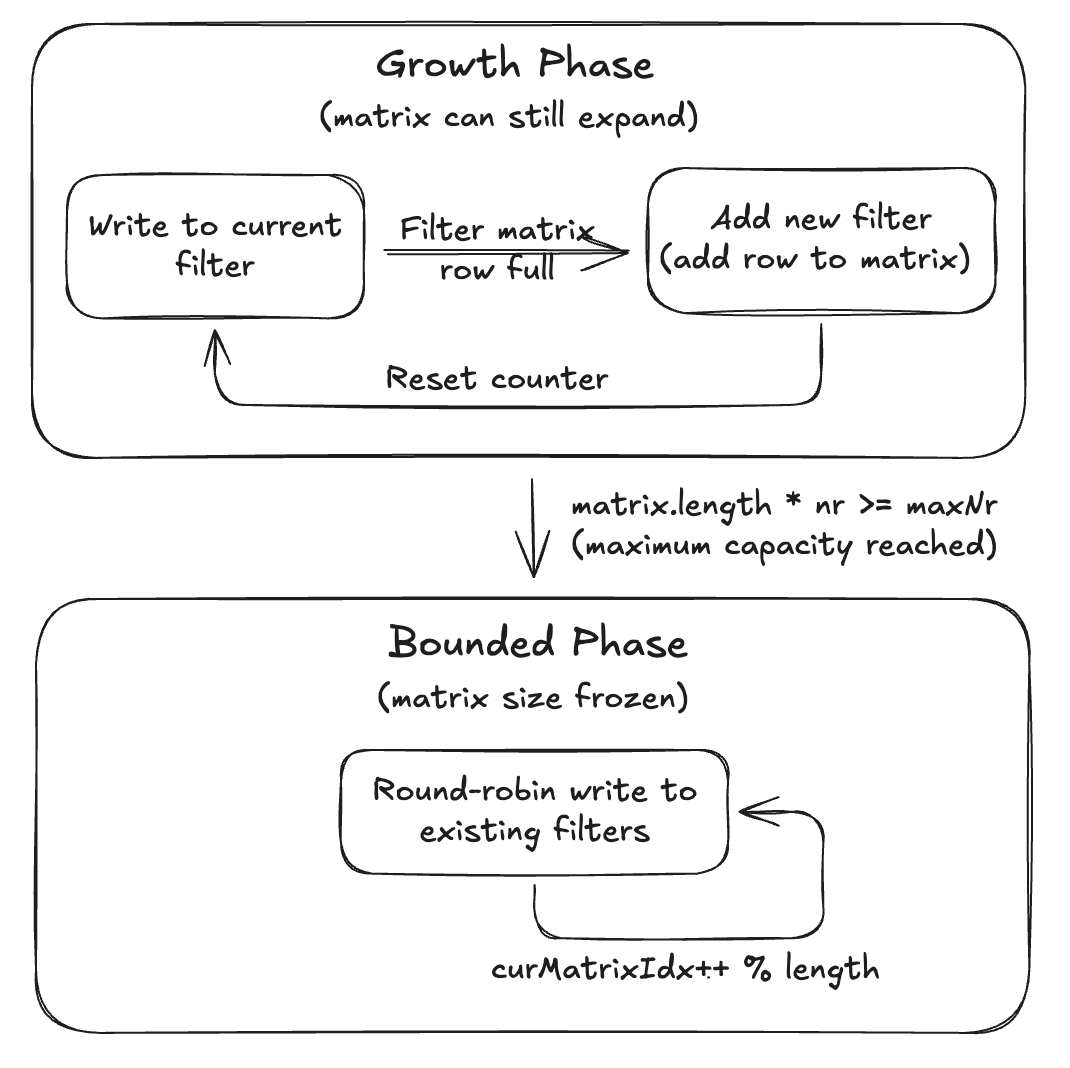
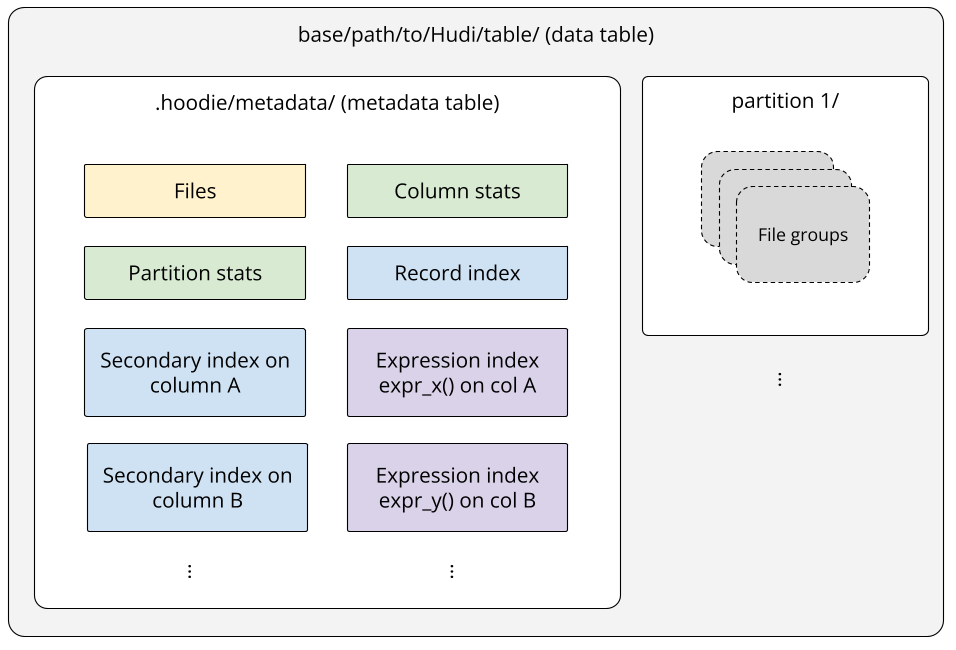
Building Indexes on a Moving TargetJune 25, 2026 by Sivabalan Narayananmormerge on readindexingasync indexingmetadataarchitecturedata lakehouse
Stateless Global Upserts for Flink Streaming in Apache Hudi 1.2.0June 10, 2026 by Danny Chan and Shuo Chengapache flinkindexingrecord level indexrlistreamingmetadataperformancerelease
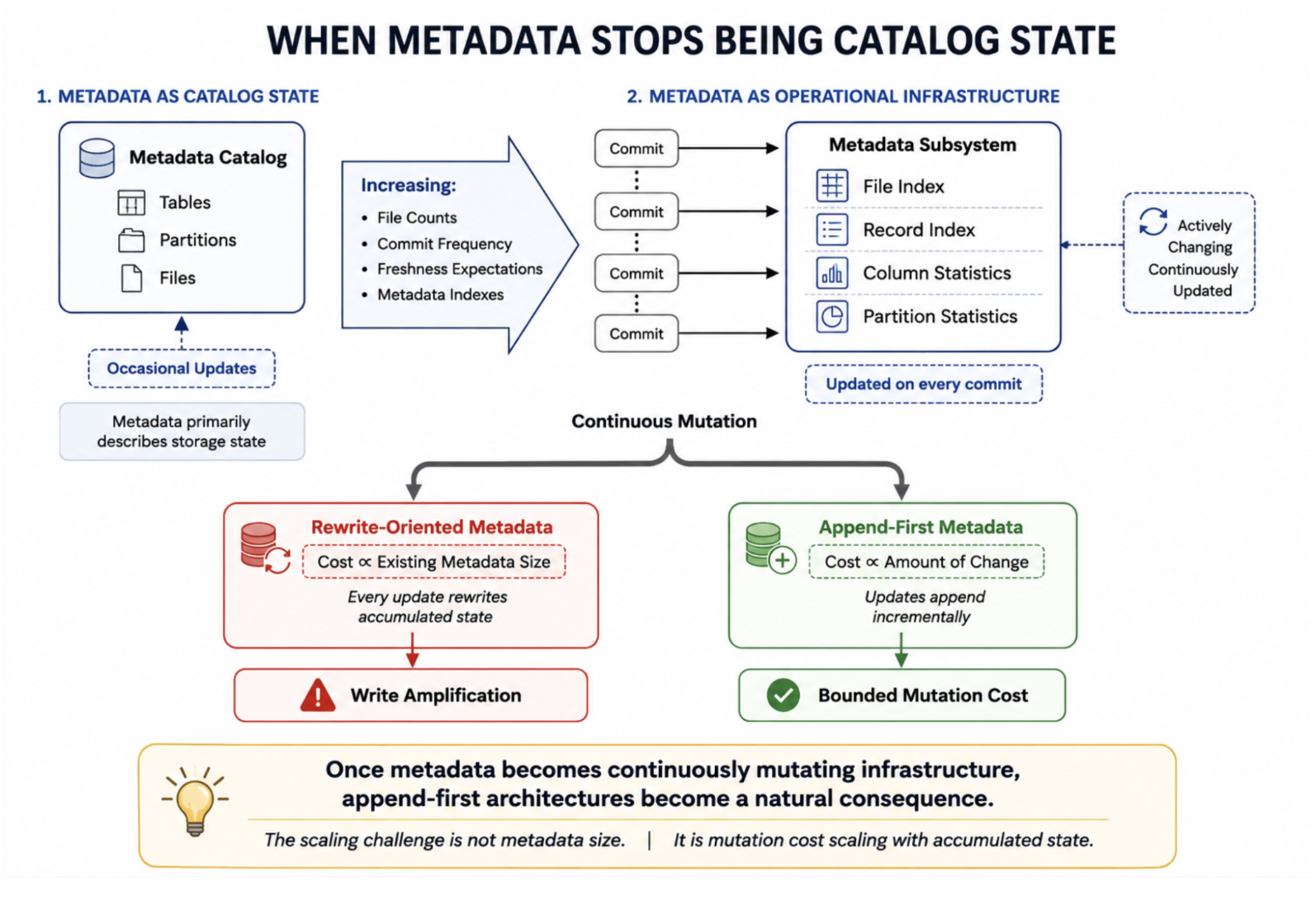
Why Metadata Has to Be Mutation-FriendlyJune 5, 2026 by Sivabalan Narayananmetadatamormerge on readindexingarchitecturedata lakehousestreaming
Deep Dive Into Hudi's Indexing Subsystem (Part 2 of 2)November 12, 2025 by Shiyan Xuindexingdata lakehousedata skipping
Deep Dive Into Hudi’s Indexing Subsystem (Part 1 of 2)October 29, 2025 by Shiyan Xuindexingdata lakehousedata skipping
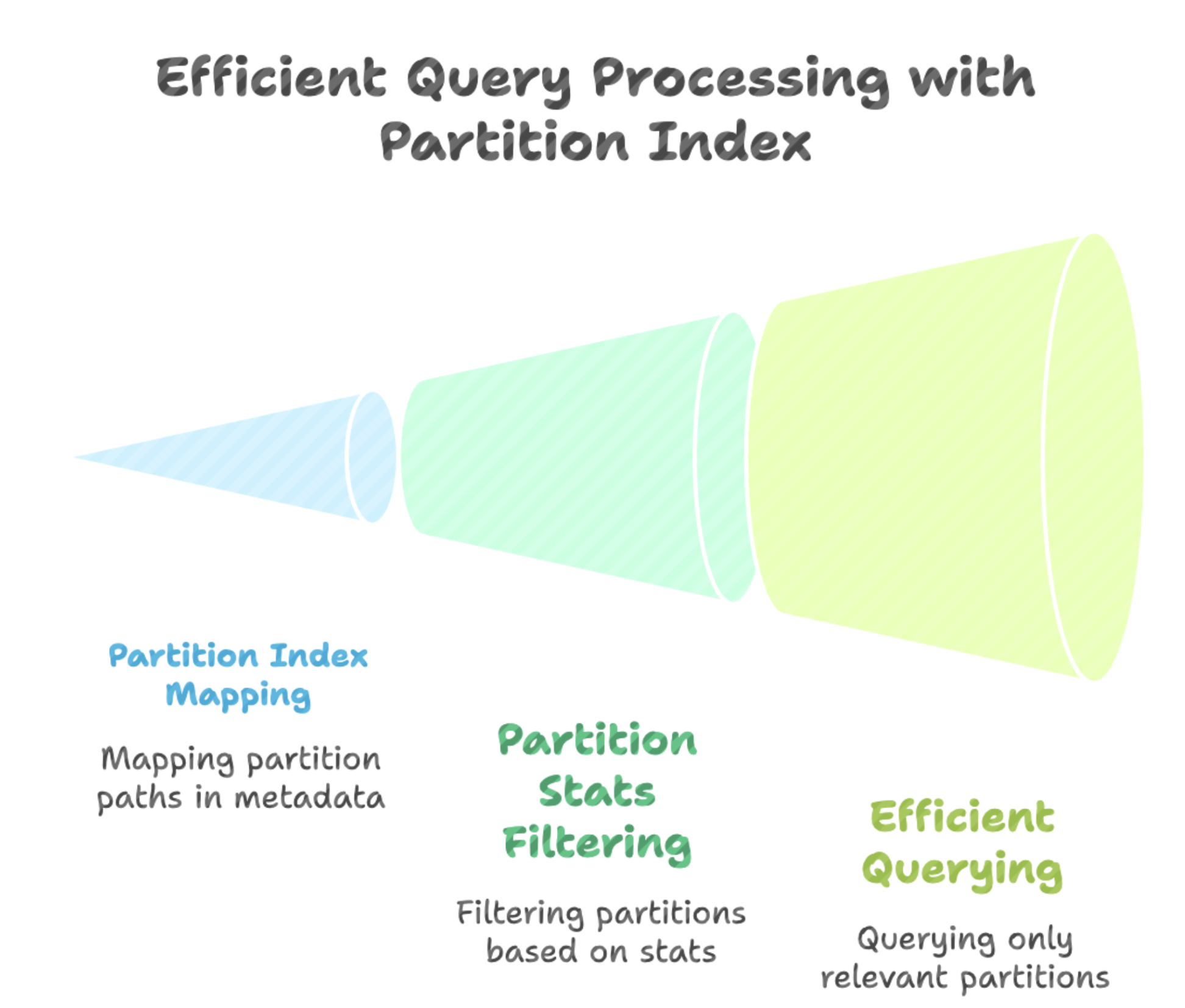
Partition Stats: Enhancing Column Stats in Hudi 1.0October 22, 2025 by Aditya Goenka and Shiyan Xuindexingdata lakehousedata skipping
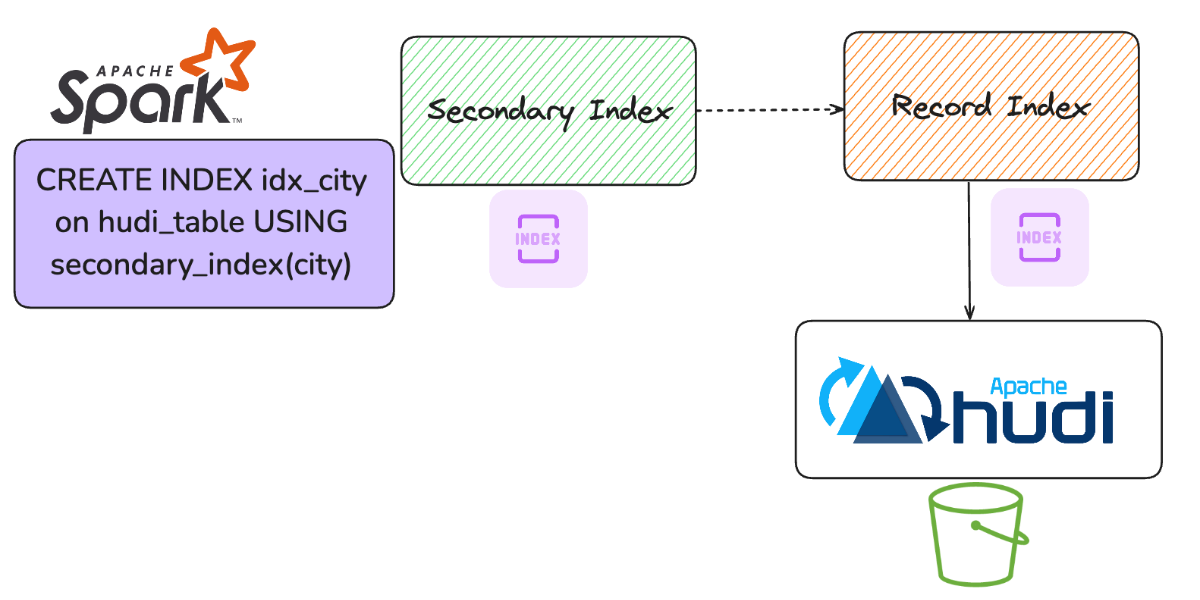
Introducing Secondary Index in Apache Hudi Lakehouse PlatformApril 2, 2025 by Dipankar Mazumdar and Aditya Goenkaindexingperformance
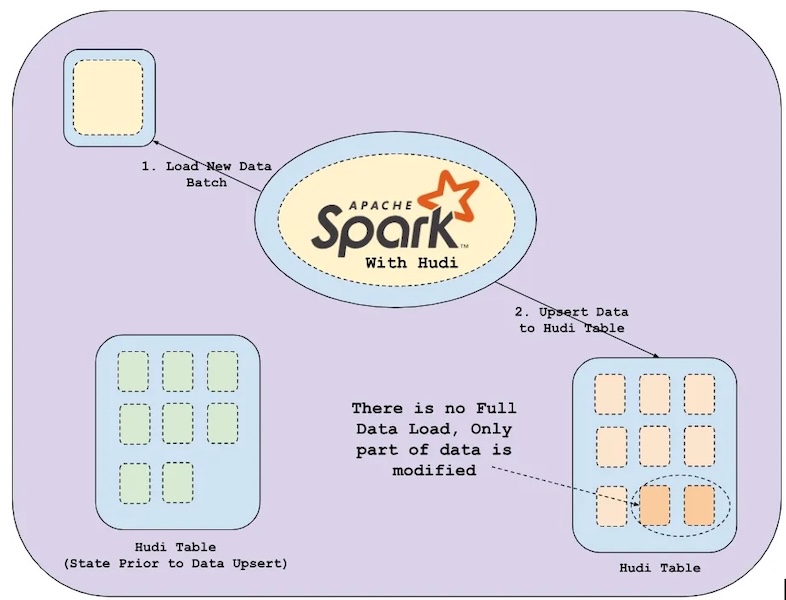
How Apache Hudi transformed Yuno’s data lakeSeptember 17, 2024 by Nahuel Leandro Mazzitellicowmorindexingclusteringcleanerfile sizingyuno