Building Indexes on a Moving Target

This is the third post in a series on Merge-On-Read as an architectural shift in Apache Hudi. The first post made the broad case; the second showed how the metadata table inherits the same append-first model; this one follows the pattern one step further — into how new indexes can be added to a live table without stopping it.
The first post in this series argued that Merge-On-Read is not a storage optimization but an architectural shift — a strategy for time-shifting work in systems where mutation and analytical scan run at different rhythms. The second grounded that argument in Hudi's metadata table, showing how metadata itself became another append-first workload. Async indexing extends the same architectural pattern one step further: enabling new capabilities to be introduced into a live table without stopping the system.
This article assumes some familiarity with Hudi's metadata table and its indexing capabilities. If you're new to the topic, the motivation for metadata indexes, their role in query planning, and the evolution of the metadata table are covered in detail in RFC-45 as well as our earlier articles on the metadata table and mutation-friendly metadata. Here, we focus on a different question: once a table is already serving production writes, how can a new metadata index be introduced without interrupting ingestion or exposing inconsistent state?
The title is literal. In Hudi, you can build a new index — record-level, secondary, expression, column stats, bloom filter — over an existing multi-petabyte table that doesn't stop while you build it. Ingest writers keep committing. No outage. No drained pipeline. No swap window. The bootstrap reads historical state into a freshly initialized metadata partition; concurrent writers route new mutations into the same partition's file groups; a reconciliation step at the end stitches the seam.
That capability does not exist in any other open lakehouse format at the spec level — not because nobody implemented it, but because the storage layer every other format is built on cannot express the pattern. Async indexing is not a feature added to Hudi; it is a consequence of decisions Hudi made in 2017. The only systems that can build indexes this way are the ones whose mutation model is already append-first.
RFC-45 is the design doc, and the Onehouse engineering blog walks through the mechanics. Those explain what async indexing does and how it's wired in. This post is about why the design works at all — what architectural primitives have to exist underneath before something like it becomes a coherent thing to build.
The Shape of the Problem
Adding a new index over an existing large table has always been an operationally expensive thing for analytical storage to do. Scan every row, project the indexed columns or compute the indexed expression, materialize the index. The trouble is that "scan every row" of a multi-petabyte table takes hours, and during those hours the table either has to stop accepting writes or has to coordinate with a table that won't sit still.
Two responses dominate the lakehouse conversation, and both inherit the limitations of their foundation.
The first is to bind the index to the write path: compute the value at ingestion time and write it alongside the data — column-level statistics, min/max metadata, file summaries. This is what Iceberg and Delta do by default. It works, but it cannot retroactively add an index. If the table was written for two years without it, the write path can't help; the data is already on disk in its final form.
The second is to lock-and-rebuild: global or per-partition lock, scan, materialize, atomic swap, release. Fine at small scale. At petabyte scale on a continuously ingesting table the lock duration is hours, the ingest pipeline has to stop or buffer indefinitely, and any failure during the rebuild discards the work.
Hudi's predicament when RFC-15 introduced the metadata table was that MDT was going to host indexes — files, column_stats, bloom_filters, record_index, partition_stats, secondary_index, expression_index. Every one of those would eventually need to be added over an existing table by someone who'd been running Hudi for a year before the index existed. If index addition required taking the table offline, the metadata table's growth story collapses to enable everything at table creation or never. That isn't a metadata layer; that's a one-shot schema decision. RFC-45 is the document that fixes this.
What COW Makes Impossible — Not Hard, Impossible
Imagine implementing async indexing on a Copy-On-Write storage layer — a generic columnar lakehouse format where the unit of mutation is the file rewrite. Bootstrap scans history, computes, materializes. Concurrent writers continue ingesting. Index has to be queryable at the end.
The bootstrap is slow under any architecture; that's not what breaks. What breaks is that there is no place for concurrent writers to put their contribution to the new index while the bootstrap is running.
Under COW, every index update is a rewrite of a finalized index file. There is no append channel. If the indexer has materialized idx_000.parquet for history up to t, and a writer commits at t+1, the writer cannot contribute to idx_000.parquet. The writer's only option is idx_001.parquet — which means the bootstrap has to coordinate with the writer about which file was produced, validate it, possibly merge it. That coordination is the synchronization we were trying to avoid. The deeper problem is the absence of a stable logical container: the index isn't something the writer can point at and append into; it's a collection of physical files whose ownership has to be negotiated.
The workaround in rewrite-oriented systems is bootstrap-and-swap: build against a frozen snapshot at t; writers ingest normally but don't touch the new index; at t + Δ, replay all writes between t and t + Δ into the index, then atomically swap. This works, but the replay window has no upper bound (if ingest exceeds replay rate, catchup never converges), and the index is unavailable for query during the entire bootstrap-plus-replay duration.
Hudi doesn't need bootstrap-and-swap because the foundation offers something neither Iceberg nor Delta has: a stable file group with an append channel, and a timeline that expresses index construction as a first-class action with its own reconciliation semantics. Both primitives are downstream of MOR.
Before examining the architectural primitives individually, it's helpful to look at the end-to-end lifecycle of an async index build. The figure below intentionally presents the high-level execution flow rather than the implementation details. For readers interested in the complete design, state-machine transitions, and failure handling, RFC-45 provides the authoritative specification. Here, we focus on the architectural primitives that make the design possible.
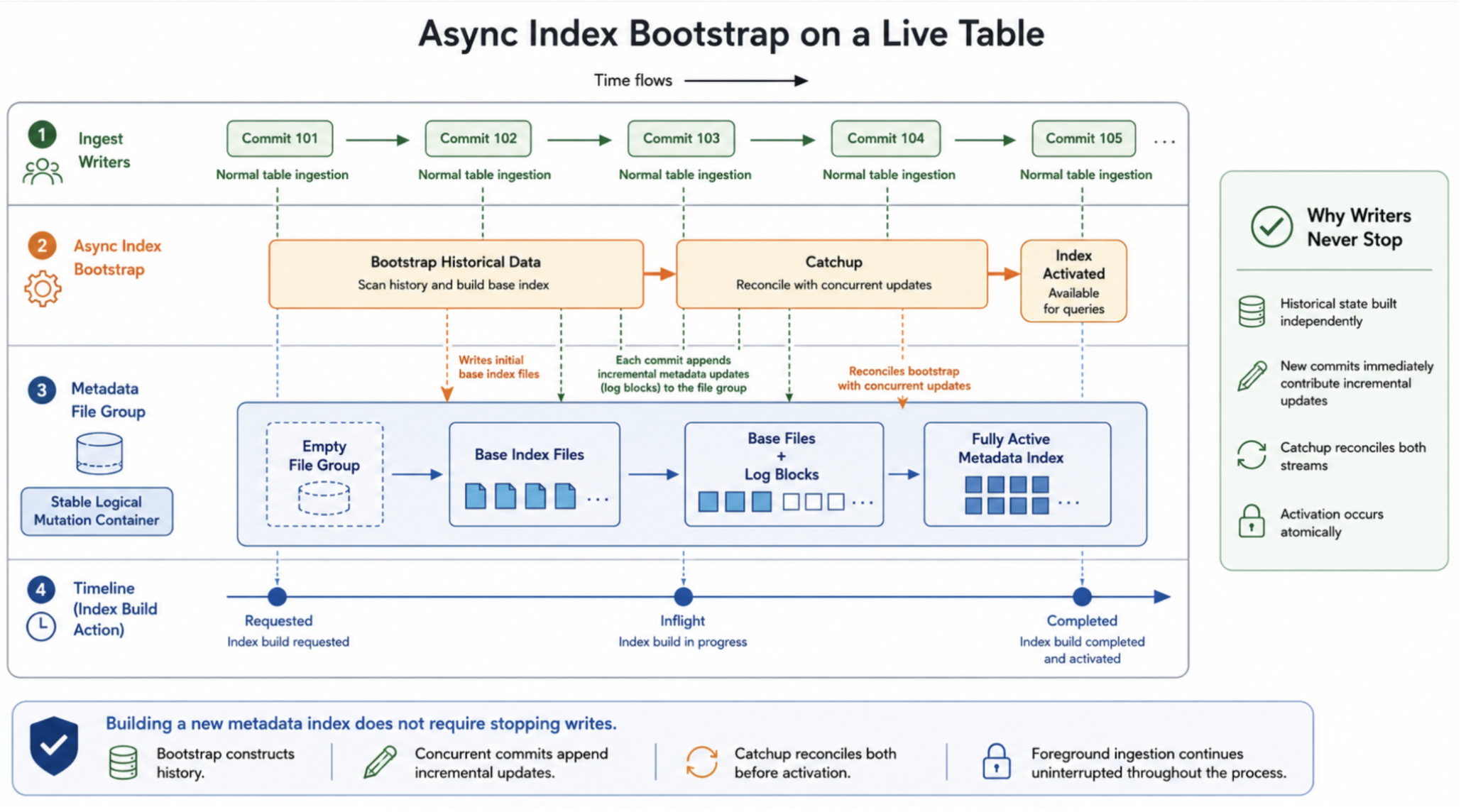
The Three Primitives, All of Them MOR Consequences
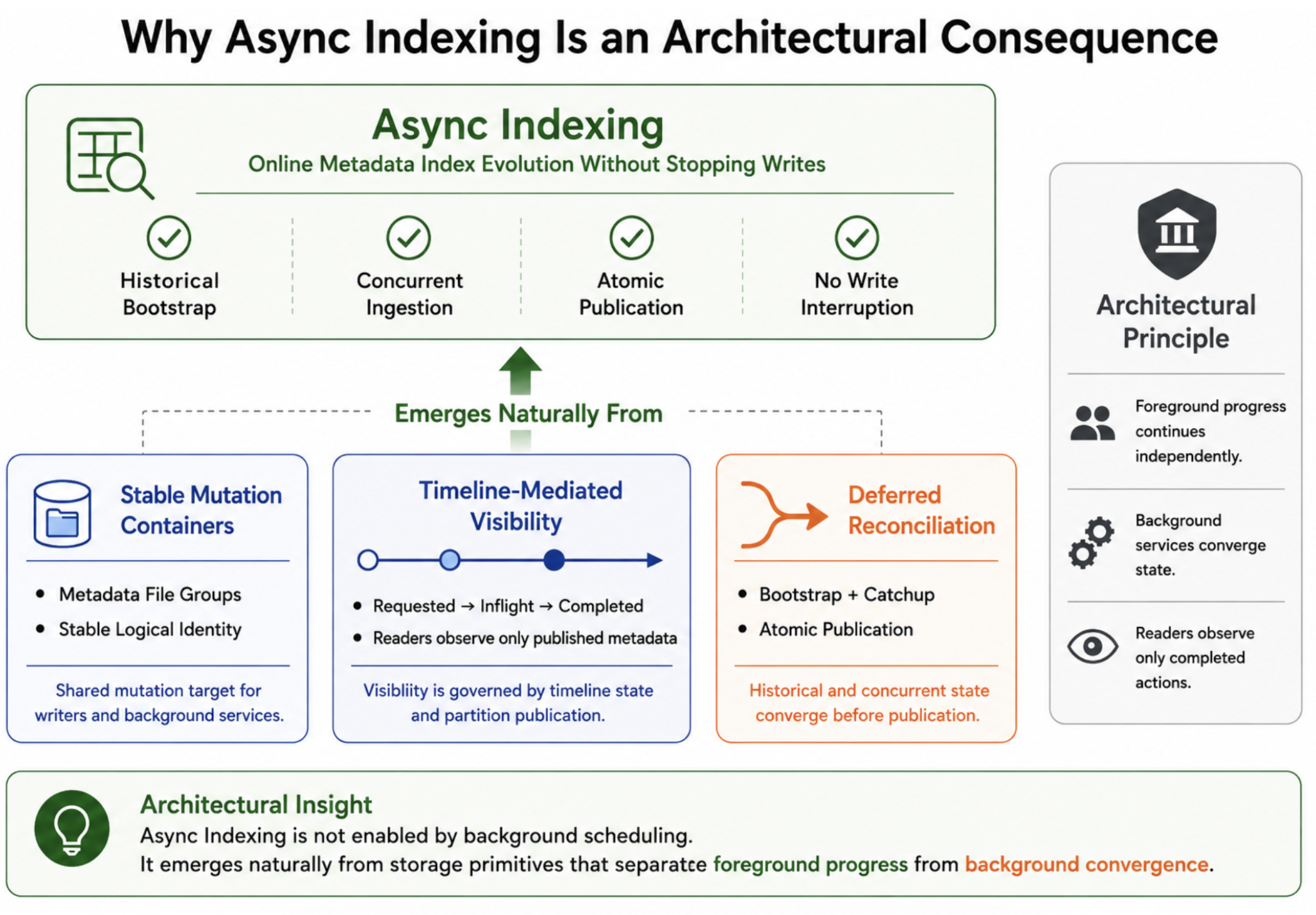
Async indexing in Hudi rests on three substrate-level primitives. Each one is something the MOR design forced into existence for other reasons, and each one is what makes RFC-45's design coherent rather than a heroic engineering effort against the storage layout.
Primitive 1: The File Group as a Stable Mutation Container
The file group is a stable logical mutation container. Once initialized, multiple independent processes — not just ingest writers, but background services such as index builders — can deterministically contribute mutations into the same logical object while deferring physical reconciliation. Async indexing is one application of this primitive. Later in the series, we'll see the same stable mutation containers reused by other Hudi capabilities, including async compaction and eventually non-blocking concurrency control.
When the indexer initializes a new metadata partition, it creates empty file groups for that partition. From that moment, they exist on disk and are addressable. A writer that sees the partition is inflight (via table config) can immediately append log blocks into those file groups, even though base files haven't been written yet. The writer doesn't need to know whether the indexer has finished the base file or coordinate physical layout at all. It needs only to know which file group to route into — a deterministic function of the record key (via bucket index or RLI's hash routing).
Under COW this primitive doesn't exist. There's no "container the indexer prepares and writers append into" — only files, produced atomically and consumed read-only. The closest analog is a shared directory both processes write new files into; but that's a namespace, not a container, and the synchronization problem returns immediately.
Primitive 2: INDEXING as a First-Class Timeline Action
Hudi's timeline is an append-only event log: commits, deltacommits, cleans, compactions, restores, rollbacks. RFC-45 adds INDEXING_ACTION. An index build is not a side process; it is represented as its own sequence of timeline instants: <t>.indexing.requested, <t>.indexing.inflight, and <t>.indexing (completed), alongside data writes and other table services.
That placement matters. Because the action lives on the timeline, concurrent writers discover it through the same timeline refresh they already perform for commits and table services; no separate coordination channel is required. Because it follows the standard requested → inflight → completed lifecycle, existing mechanisms for recovery, rollback, and lock-protected state transitions apply without introducing a parallel state machine. Async indexing is built by extending the timeline rather than bypassing it.
More importantly, the timeline and table configuration together govern visibility, not just execution. Bootstrap and Catchup may execute for minutes while the table continues accepting writes, but the new index remains invisible to readers throughout that period.
Internally, the indexing action progresses through the standard requested → inflight → completed lifecycle on the timeline, while the table configuration independently tracks whether the metadata partition is still under construction (metadata.partitions.inflight) or has become queryable (metadata.partitions). Readers observe the new index only after both transitions have completed. This separation is subtle but fundamental. Bootstrap and Catchup describe how the index is constructed. The timeline and table configuration determine when that construction becomes visible. By separating progress from publication, Hudi allows long-running background work to proceed without exposing partially constructed metadata to readers.
Although async indexing predates the completion-time semantics introduced later for non-blocking concurrency control, it already exhibits the same architectural pattern: background work progresses independently, reconciliation completes asynchronously, and publication is deferred until the system can present a consistent view. Later in the series, we'll see how Hudi generalizes this idea for concurrent writers using completion-time ordering.
Primitive 3: Two-Stage Partition Lifecycle in Table Config
The subtlest of the three, and the one most directly inherited from MOR. hoodie.properties carries two related fields: hoodie.table.metadata.partitions.inflight lists partitions initialized and receiving writes but not yet queryable; hoodie.table.metadata.partitions lists partitions fully built and safe to read.
That split is what makes async indexing safe under split-brain reader/writer views. When scheduling completes — file groups initialized, plan persisted — the partition is added to *_INFLIGHT. Writers see it and start routing log blocks. Readers see it too, and ignore the partition: table config is the source of truth for query readiness. Only after the bootstrap base is written, Catchup reconciles any missing metadata updates from concurrent commits, and the indexing action completes does the partition move from metadata.partitions.inflight to metadata.partitions.
The two-stage config is MOR's base-file-vs-log-file separation lifted to the partition level. Log files are writable before the next base file is materialized; readers reconcile both at query time. Inflight partitions are writable before the bootstrap completes; readers ignore them until done. Same idea, different scope. You can see this in code at RunIndexActionExecutor.updateTableConfigAndTimeline: the partition transitions from inflight to active as part of the indexing completion sequence, allowing the new index to become visible only after both the timeline action and table configuration reflect a completed build.
The abort path at RunIndexActionExecutor.abort removes the partition from both lists and deletes the physical partition; on any build failure, the partition reverts cleanly to "doesn't exist."
Because both scheduling and completion execute under Hudi's timeline lock provider, these metadata transitions remain serialized even though the bootstrap itself proceeds concurrently with foreground writers.
Interestingly, these primitives turn out to be useful well beyond index construction. Stable mutation containers, timeline-ordered visibility, and deferred reconciliation reappear repeatedly throughout Hudi's architecture. Async indexing is one application. Later in the series, we'll see the same foundations support background optimization and eventually reshape how concurrent writers coordinate against the same data.
Indexing Catchup as Deferred Reconciliation, Generalized
The three primitives set up the most interesting piece of the design: indexing catchup. The implementation lives in AbstractIndexingCatchupTask, orchestrated by RunIndexActionExecutor. It's where the MOR-as-foundation argument becomes concrete.
The indexing plan is scheduled against a bootstrap target — the latest completed data-table instant at scheduling time. Bootstrap builds the historical portion of the index by scanning the table up to that point. Meanwhile, the data timeline continues advancing.
A common misconception is that Bootstrap alone constructs the index. In reality, every commit that arrives while Bootstrap is running is equally part of the index build — it simply reaches the metadata partition through the incremental write path rather than the historical scan. Writers that observe the indexing action after it becomes inflight begin appending metadata updates into the new file groups. By the time Bootstrap completes, the metadata partition consists of a historical base together with an unknown amount of concurrent incremental state.
The indexer cannot simply assume that every eligible commit has been reflected in the metadata timeline. Some writers may have started before the indexing action became visible. Others may still be inflight. Catchup exists to reconcile that uncertainty before the index becomes visible.
Catchup walks the relevant portion of the data timeline and compares each eligible data-table instant against the metadata timeline using the indexing action's requested-time identifier. If the corresponding metadata update already exists, the writer has already contributed its portion of the index. Otherwise, Catchup synthesizes the missing metadata update on the writer's behalf.
Inflight writers receive special treatment. Rather than immediately treating them as missing, Catchup waits for active writers to complete while monitoring their heartbeats. Writers that complete normally are incorporated through the usual reconciliation path. Writers whose heartbeats have expired are treated as abandoned and skipped, allowing index construction to converge without waiting indefinitely. The wait itself is bounded by hoodie.metadata.index.check.timeout.seconds (900 seconds by default), after which the indexing operation aborts and the partially constructed partition is discarded.
This is deferred reconciliation in its purest form. Bootstrap constructs historical state. Concurrent writers continue making forward progress. Catchup reconciles any remaining divergence between the data timeline and metadata timeline before publication. Readers never observe intermediate state.
The pattern is exactly what Merge-On-Read readers already do for every file group: reconcile a stable base with subsequent incremental mutations to produce a consistent view. Async indexing applies the same architectural idea at the scope of an entire metadata partition.
The mechanism is different, but the underlying principle is identical: foreground progress continues independently, while background reconciliation converges the system before publication.
The Races, and How the Architecture Absorbs Them
RFC-45 enumerates four error cases. Each one is a place where synchronous coordination would have required a lock, and each one is handled instead by deferred reconciliation against timeline state. They're worth walking through because they make the architectural argument concrete.
Writer fails while the indexer is inflight. The writer crashed before logging its update. The indexer doesn't care. Catchup observes the failed instant, sees no metadata deltacommit, and either skips it (if data-table rollback already cleaned up) or fills it in. The metadata partition isn't corrupted because reader visibility hasn't flipped yet.
Indexer fails while a writer is inflight. The writer continues logging into the new file groups. The partition stays in *_INFLIGHT because no commit metadata was written. Readers continue ignoring it. When the indexer is re-triggered, it sees the partition is inflight, picks up the build (idempotent by partition name in ScheduleIndexActionExecutor), and proceeds. The writer's log files aren't lost — they're already in the file group, waiting for catchup.
Writer goes inflight just after the indexing request, before the indexer executes. A writer begins after the indexing action becomes visible and therefore participates in index construction from the outset. By bootstrap completion, log files already exist. Catchup observes them, sees the corresponding deltacommit, moves on. No coordination — writer and indexer were independently pointing at the same stable container.
Inflight writer about to commit but indexing just completed. The trickiest race. The writer started knowing the partition was inflight; during its execution the partition flipped to completed. The writer commits, producing a log file in the now-completed partition, and the indexer missed it. Because the reader engine is designed from day one to merge base + logs on the fly, the reader's merge layer inherently immunizes the system against race conditions. The storage layout itself acts as the concurrency buffer. The reader's merge logic doesn't know the difference between a log file produced during catchup and one produced just after. RFC-45 discusses an alternative design based on locking metadata-timeline appends, but explicitly rejects it in favor of the eventual-consistency path adopted by the implementation. The existing design relies on deferred reconciliation rather than stronger synchronization.
In each case, the response shape is the same: stable container, timeline record, reconciliation at the next quiet moment. None of this is async-indexing-specific. It's what every MOR table service does.
Notice that none of these cases require the bootstrap itself to synchronize with foreground writers. Synchronization is reserved for timeline state transitions, while correctness is achieved through deferred reconciliation before publication.
Why This Isn't Expressible in Rewrite-Oriented Formats
Can async indexing be added to Iceberg or Delta with sufficient engineering effort? It can be approximated, but the approximation either gives up the "no synchronization with writers" property or requires inventing the three primitives above on a foundation that doesn't naturally support them.
Iceberg has manifests, manifest lists, snapshots — no stable logical container with an append channel. Each commit produces new manifest files; there's no "manifest the indexer prepares and writers contribute to." Row lineage and v3 deletion vectors give stable row identity, but that's not the same primitive as a stable append container. Adding async indexing to Iceberg would require a new manifest layout where indexers stage skeletons that subsequent writers contribute to — a spec change, not a feature.
Delta has the transaction log, deletion vectors, and (in Databricks Runtime) row-level concurrency for non-overlapping MERGE/UPDATE/DELETE. None provide an append container stable across commits. Coordinated commits in 4.0 improve multi-engine atomic commit, but the unit of commit is still a set of new files; there's no notion of writers appending into a file the indexer staged. Delta's data skipping and statistics are written during the data commit; they cannot be retroactively built without bootstrap-and-swap.
Async indexing isn't a missing feature in those formats; it's missing because the foundation cannot express the pattern. Adding it would require lifting append-first mutation into the storage model itself. That is most of what MOR is.
The "async-indexing-ish" capabilities those formats have shipped are either write-path additions (compute during writes, can't retroactively add) or batch-and-swap (block readers during a window, schedule a maintenance window). Neither is what Hudi async indexing actually does.
What This Unlocks Operationally
The architectural argument lands on a small set of capabilities that change how teams operate Hudi tables.
The most immediate: adding indexes to existing tables without a maintenance window. RLI on a 1 PB table for primary-key lookup. Secondary index on customer_email for a query pattern that wasn't important when the table was created. Expression index on LOWER(country_code) because the workload changed. Issue CREATE INDEX (or run HoodieIndexer) against the running table. Bootstrap fills history. Writers continue. Catchup closes the seam.
Second: index re-initialization as a routine operation. If an index gets into a bad state — schema evolution mismatch, corrupted base file, missed catchup window — recovery is "delete the partition, re-run the indexer." Not a migration event. The same ScheduleIndexActionExecutor.abort path handles cleanup before re-initialization.
Third: staged index rollouts. You don't have to enable every metadata partition at table creation. Enable files and column_stats initially, add record_index later when point-lookup load justifies it, secondary_index later still when a new query pattern emerges. The metadata table's footprint grows with the workload's actual needs. A table running for years can adopt a new index without dropping a write.
None of these are theoretical. Take any one primitive away — make the file group non-append, take INDEXING off the timeline, collapse the two-stage partition config — and the operational story collapses with it.
What MOR Ultimately Made Possible
A single architectural decision — append-first mutation with deferred reconciliation — produces a family of capabilities that look like independent features but are the same idea applied to different scopes. The metadata table is MOR because the commit cadence demands it. Async indexing is possible because the same stable mutation containers can be initialized empty and evolved by concurrent contributors.
Looked at in isolation, each capability has its own moving parts: RFC-15 for MDT, RFC-45 for async indexing, and later in the series we'll examine how Hudi extends the same architectural principles — stable mutation containers, deferred reconciliation, and timeline-mediated publication — to support non-blocking concurrency control. The descriptions are all correct. They miss the bigger point, which is that the moving parts exist because MOR established the underlying mutation model — and the same model gets reused every time a new operational requirement shows up.