A Deep Dive on Merge-on-Read (MoR) in Lakehouse Table Formats

TL;DR
- Merge-on-Read tables help manage updates on immutable files without constant rewrites.
- Apache Hudi's MoR tables, with delta logs, file groups, asynchronous compaction, and event-time merging, are well-suited for update-heavy, low-latency streaming and CDC workloads.
- Iceberg and Delta Lake also support MoR, but with design differences around delete files and deletion vectors.
As open table formats like Apache Hudi, Apache Iceberg, and Delta Lake become foundational to modern data lakes, understanding how data is written and read becomes critical for designing high-performance pipelines. One such key dimension is the table's write mechanism, specifically, what happens when updates or deletes are made to these lakehouse tables.
This is where Copy-on-Write (CoW) and Merge-on-Read (MoR) table types come into play. These terms were popularized by Apache Hudi, in the original blog from Uber Engineering, when the project was open-sourced in 2017. These strategies exist to overcome a fundamental limitation: data file formats like Parquet and ORC are immutable in nature. Therefore, any update or delete operation that is executed on these files (managed by a lakehouse table format) requires a specific way to deal with it - either by merging changes right away during writes, rewriting entire files (CoW) or maintaining a differential log or delete index that can be merged at read time (MoR).
Viewed through the lens of the RUM Conjecture - which states that optimizing for two of Read, Update, and Memory inevitably requires trading off the third. CoW and MoR emerge as two natural design responses to the trade-offs in lakehouse table formats:
-
Copy-on-Write tables optimize for read performance. They rewrite Parquet files entirely when a change is made, ensuring clean, columnar files with no extra merge logic at query time. This suits batch-style, read-optimized analytics workloads where write frequency is low.
-
Merge-on-Read, in contrast, introduces flexibility for write-intensive and latency-sensitive workloads by avoiding expensive writes. Instead of rewriting files for every change, MoR tables store updates in delta logs (Hudi), delete files (Iceberg V2), or deletion vectors (Delta Lake). Reads then stitch together the base data files with these changes to present an up-to-date view. This tradeoff favors streaming or near real-time workloads where low write latency is critical.
Here is a generic comparison table between CoW and MoR tables.
| Trade-Off | CoW | MoR |
|---|---|---|
| Write latency | Higher | Lower |
| Query latency | Lower | Higher |
| Update cost | High | Low |
| File Size Guidance | Base files should be smaller to keep rewrites manageable | Base files can be larger, as updates don’t rewrite them directly |
| Read Amplification | Minimal - all changes are already materialized into base files | Higher - readers must combine base files with change logs or metadata (e.g., delete files or vectors) |
| Write Amplification | Higher - changes often rewrite full files, even for small updates | Lower - only incremental data (e.g., updates/deletes) is written as separate files or metadata |
In this blog, we will understand how various lakehouse table formats implement MoR strategy and how the design influences performance and other related factors.
How Merge-on-Read Works Across Table Formats
Although Merge-on-Read is a shared concept across open table formats, each system implements it using different techniques, influenced by their internal design philosophy and read-write optimization goals. Here’s a breakdown of how Apache Hudi, Apache Iceberg, and Delta Lake enable Merge-on-Read behavior.
Apache Hudi
Hudi implements Merge-on-Read as one of its two core table types (along with Copy-on-Write), offering a trade-off between read and write costs by maintaining base files alongside delta log files. Instead of rewriting columnar files for every update or delete, MoR tables maintain a combination of base files and log files that encode delta updates/deletes to the base file, enabling fast ingestion and deferred file merging via asynchronous compaction. This design is particularly suited for streaming ingestion and update-heavy workloads, where minimizing write amplification and achieving high throughput are critical, without any downtime whatsoever for the writers.
Storage Layout
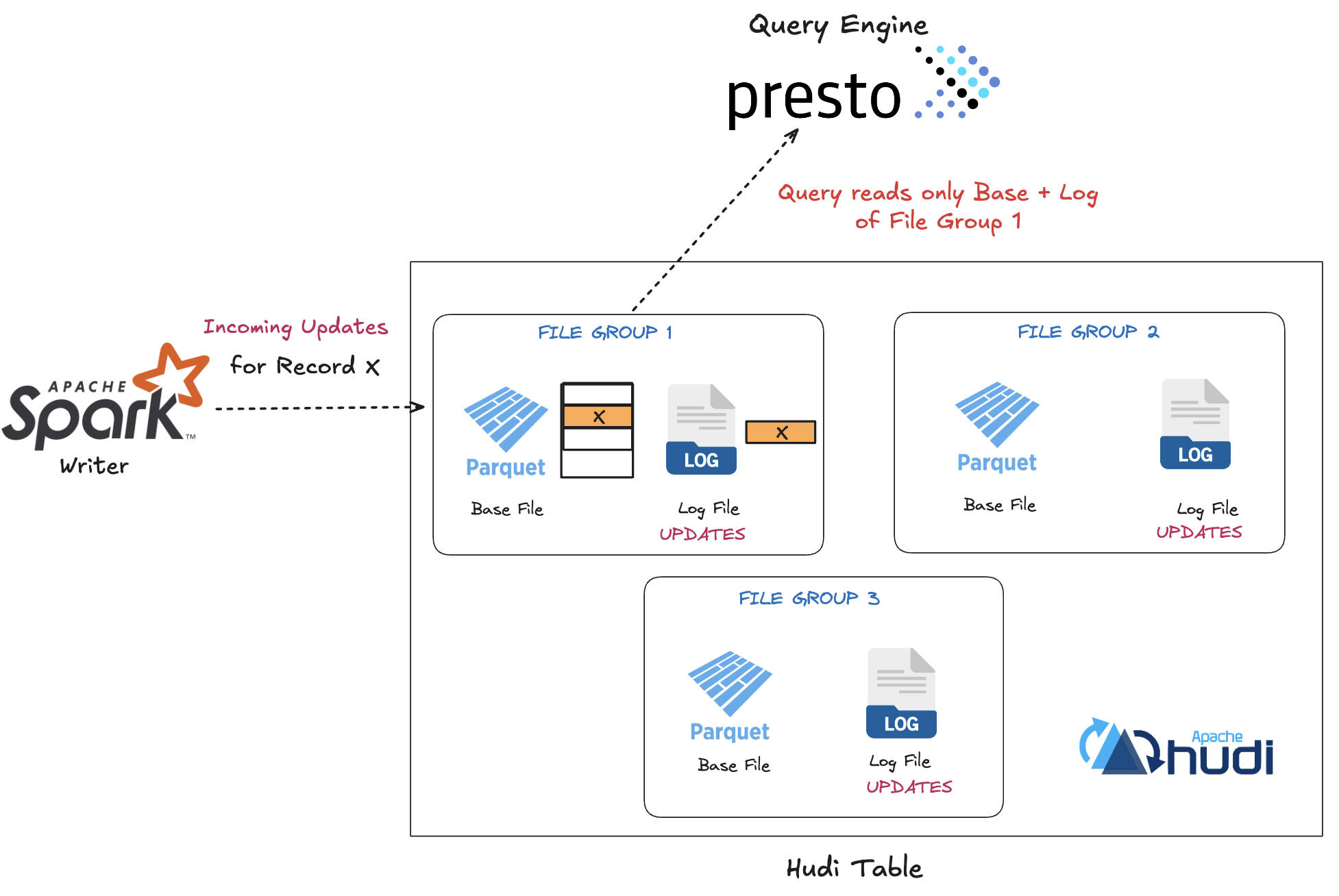
At the physical level, a Hudi MoR table stores data in File Groups, each uniquely identified by a fileId. A file group consists of:
- Base File (
.parquet, .orc): Stores the base snapshot of records in columnar format. - Delta Log Files (
.log): Append-only files that capture incremental updates, inserts, and deletes since the last compaction, in either row-oriented data formats like Apache Avro, Hudi’s native SSTable format or columnar-formats like Apache Parquet
This hybrid design enables fast writes and defers expensive columnar file writing to asynchronous compaction.
Write Path
In a Merge-on-Read table, insert and update operations are handled differently to strike a balance between write efficiency and read performance.
-
Insert operations behave similarly to those in Copy-on-Write tables. New records are written to freshly created base files, aligned to a configured block size. In some cases, these inserts may be merged into the smallest existing base file in the partition to control file counts and sizes.
-
Update operations, however, are written to log files associated with the corresponding file group. These updates in the log files are written using Hudi’s
HoodieAppendHandleclass. At runtime, a new instance ofHoodieAppendHandleis created with the target partition and file ID. The update records are passed to itswrite()method, which processes and appends them to the active log file associated with that file group. This mechanism avoids rewriting large Parquet base files and instead accumulates changes in a rolling log structure associated with each base file.
HoodieAppendHandle appendHandle = new HoodieAppendHandle(config, instantTime, this,
partitionPath, fileId, recordMap.values().iterator(), taskContextSupplier, header);
appendHandle.write(recordMap);
List<WriteStatus> writeStatuses = appendHandle.close();
return Collections.singletonList(writeStatuses).iterator();
- Delete operations are also appended to log files as either delete keys or deleted vector positions, to refer to the base file records that were deleted. These delete entries are not applied to the base files immediately. Instead, they are taken into account during snapshot reads, which merge the base and log files to produce the latest view, and during compaction, which merges the accumulated log files (including deletes) into new base files.
This design ensures that write operations remain lightweight and fast, regardless of the size of the base files. Writers are not blocked by background compaction or cleanup operations, making the system well-suited for streaming and CDC workloads.
Read Path
Hudi MoR tables offer flexible read semantics by supporting both snapshot queries and read-optimized queries, depending on the user's performance and freshness requirements.
-
Snapshot queries provide the most current view of the dataset by dynamically merging base files with their corresponding log files at read time. The system selects between different reader types based on the nature of the query and the presence of log files:
- A full-schema reader reads the complete row data to ensure correct application of updates and deletes.
- A required-schema reader projects only the needed columns to reduce I/O, while still applying log file merges.
- A skip-merging reader is used when log files are absent for a file group, allowing the query engine to read directly from base files without incurring merge costs.
-
Read-optimized queries, in contrast, skip reading the delta log files altogether. These queries only scan the base Parquet files, providing faster response times at the cost of not reflecting the latest un-compacted changes. This mode is suitable for applications where slightly stale data is acceptable or where performance is critical.
Together, these two read strategies allow Hudi MoR tables to serve both real-time and interactive queries from the same dataset, adjusting behavior depending on the workload and latency constraints.
Compaction
As log files accumulate new updates and deletes, Hudi triggers a compaction operation to merge these log files back into columnar base files. This process is configurable and asynchronous, and plays a key role in balancing write and read performance.
Compaction in Hudi is triggered based on thresholds that can be configured by the user, such as the number of commits (NUM_COMMITS). During compaction, all log files associated with a file group are read and merged with the existing base file to produce a new compacted base file.
Apache Iceberg
Apache Iceberg supports Merge-on-Read (MoR) semantics by maintaining immutable base data files and tracking updates and deletions through separate delete files. This design avoids rewriting data files for every update or delete operation. Instead, these changes are applied at query time by merging delete files with the base files to produce an up-to-date view.
Storage Layout
An Iceberg table consists of:
- Base Data Files: Immutable Parquet, ORC, or Avro files that contain the primary data.
- Delete Files: Auxiliary files that record row-level deletions.
Write Path
In Iceberg’s MoR tables, write operations implement row-level updates by encoding them as a delete of the old record and an insert of the new one. Rather than modifying existing Parquet base files directly, Iceberg maintains a clear separation between new data and logical deletes by introducing delete files alongside new data files.
- Inserts behave in the same way as CoW tables. The new data is appended to the table as part of a new snapshot.
- For delete operations, Iceberg writes a delete file containing rows to be logically removed across multiple base files. Delete files are of two types:
- Position Deletes: Reference row positions in a specific data file.
- Equality Deletes: Encode a predicate that matches rows based on one or more column values.
Equality deletes are typically not favored in performance sensitive data platforms, since it forces predicate evaluation against every single base file during snapshot reads.
The DeleteFile interface captures these semantics:
public interface DeleteFile extends ContentFile<StructLike> {
enum DeleteType {
EQUALITY, POSITION
}
}
Note: Iceberg v3 introduces Deletion Vectors as a more efficient alternative to positional deletes. Deletion vectors attach a bitmap to a data file to indicate deleted rows, allowing query engines to skip over deleted rows at read time. Deletion Vectors are already supported by Delta Lake and Hudi and this is now borrowed into the Iceberg spec as well.
- For update operations, Iceberg uses a two-step process. An update is implemented as a delete + insert pattern. First, a delete file is created to logically remove the old record, using either a position or equality delete. Then, a new data file is written that contains the full image of the updated record. Both the delete file and the new data file are added in a single atomic commit, creating a new snapshot of the table. This behavior is implemented via the
RowDeltainterface:
RowDelta rowDelta = table.newRowDelta()
.addDeletes(deleteFile)
.addRows(dataFile);
rowDelta.commit();
All write operations, whether adding new data files or new delete files, produce a new snapshot in Iceberg’s timeline. This guarantees consistent isolation across readers and writers while avoiding any rewriting of immutable data files.
Read Path
During query execution, Iceberg performs a Merge-on-Read query by combining the immutable base data files with any relevant delete files to present a consistent and up-to-date view. Before reading, the scan planning logic identifies which delete files apply to each data file, ensuring that deletes are correctly associated with their targets.
This planning step guarantees that any row marked for deletion through either position deletes or equality deletes is filtered out of the final results, while the original base files remain unchanged. The merging of base data with delete files is applied dynamically by the query engine, allowing Iceberg to preserve the immutable file structure and still deliver row-level updates.
Delta Lake
Delta Lake supports Merge-on-Read semantics using Deletion Vectors (DVs), a feature that allows rows to be logically removed from a dataset without rewriting the base Parquet files. This enables efficient row-level delete while preserving immutability of data files. For updates, Delta Lake encodes changes as a combination of DELETE and INSERT operations, i.e. the old row is marked as deleted, and a new row with updated values is appended.
Storage Layout
In Delta Lake, the storage layout consists of:
- Base Data Files: Immutable Parquet files that hold the core data
- Deletion Vectors: Structures that track rows that should be considered deleted during reads, instead of physically removing them from Parquet
A deletion vector is described by a descriptor which captures its storage type (inline, on-disk, or UUID-based), its physical location or inline data, an offset if stored on disk, its size in bytes, and the cardinality (number of rows it marks as deleted).
Small deletion vectors can be embedded directly into the Delta transaction log (inline), while larger ones are stored as separate files, with the UUIDs referencing them by a unique identifier.
Write Path
When a DELETE, UPDATE, or MERGE operation is performed on a Delta table, Delta Lake does not rewrite the affected base Parquet files. Instead, it generates a deletion vector that identifies which rows are logically removed. These deletion vectors are built as compressed bitmap structures (using Roaring Bitmaps), which efficiently encode the positions of the deleted rows.
Smaller deletion vectors are kept inline in the transaction log for quick lookup, while larger ones are persisted as separate deletion vector files. All write operations that affect rows in this way update the metadata to track the associated deletion vectors, maintaining a consistent and atomic snapshot view for downstream reads.
Read Path
During query execution, Delta Lake consults any deletion vectors attached to the current snapshot. The query execution loads these deletion vectors and applies them dynamically, filtering out rows marked as deleted before returning results to the user. This happens without rewriting or modifying the base Parquet files, preserving their immutability while still providing correct row-level semantics.
This Merge-on-Read approach allows Delta Lake to combine efficient write operations with the ability to serve up-to-date views, ensuring that queries see a consistent, deletion-aware representation of the dataset.
Comparative Design Analysis
Merge-on-Read semantics are implemented differently across open table formats, with each approach reflecting distinct trade-offs that influence workload performance, complexity, and operational flexibility. MoR is generally well-suited for high-throughput, low-latency streaming ingestion scenarios in a lakehouse, where frequent updates and late-arriving data are expected. In contrast, Copy-on-Write (CoW) tables often work best for simpler, batch-oriented workloads where updates are infrequent and read-optimized behavior is a priority.
In this section, we focus on Apache Hudi and Apache Iceberg table formats and explore how their MoR designs influence real-world workloads.
Streaming Data Support & Event-Time Ordering
Hudi’s Merge-on-Read design supports event-time ordering and late-arriving data for streaming workloads by providing RecordPayload and RecordMerger APIs. These allow updates to be merged based on database sequence numbers or event timestamps, so that if data arrives out of order or has late arriving data, the final state is still correct from a temporal perspective.
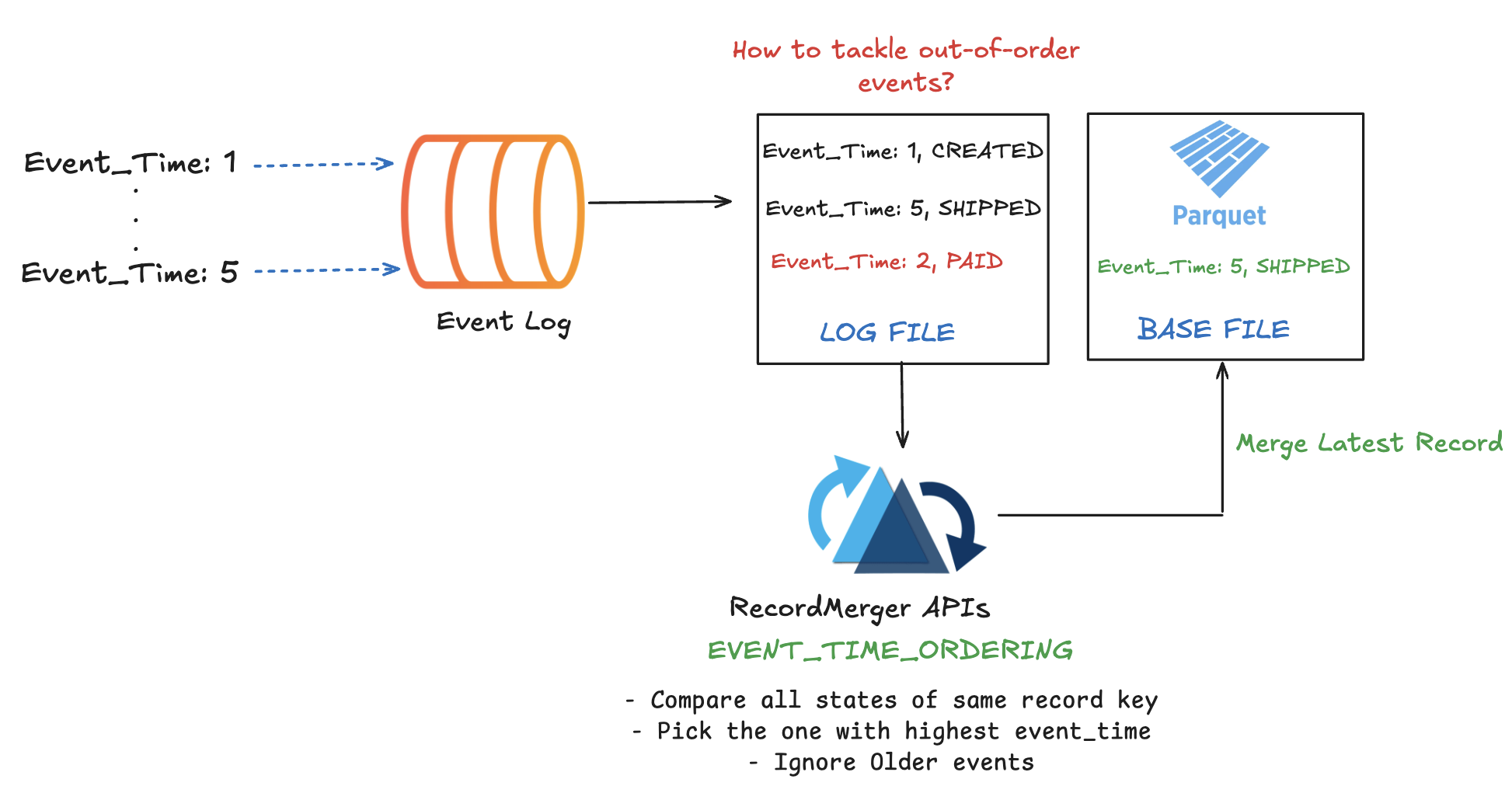
Iceberg uses a last-writer-wins approach, where the most recent commit determines record values regardless of event time. This design may be tricky to deal with late-arriving data in streaming workloads or CDC ingestion. For e.g. if the source stream is ever repositioned to an earlier time, it will cause the table to move backwards in time where older record values from the replayed stream overwrite newer record images in the table.
Scalable Incremental Write Costs
One of the main goals of MoR is to reduce write costs and latencies by avoiding full file rewrites. Hudi achieves this by appending changes to delta logs and using indexing to quickly identify which file group an incoming update belongs to. Hudi supports different index types to accelerate this lookup process, so it does not need to scan the entire table on every update. This ensures that even if you are updating a relatively small amount of data - for example, 1GB of changes into a 1TB table every five to ten minutes, the system can efficiently target only the affected files.
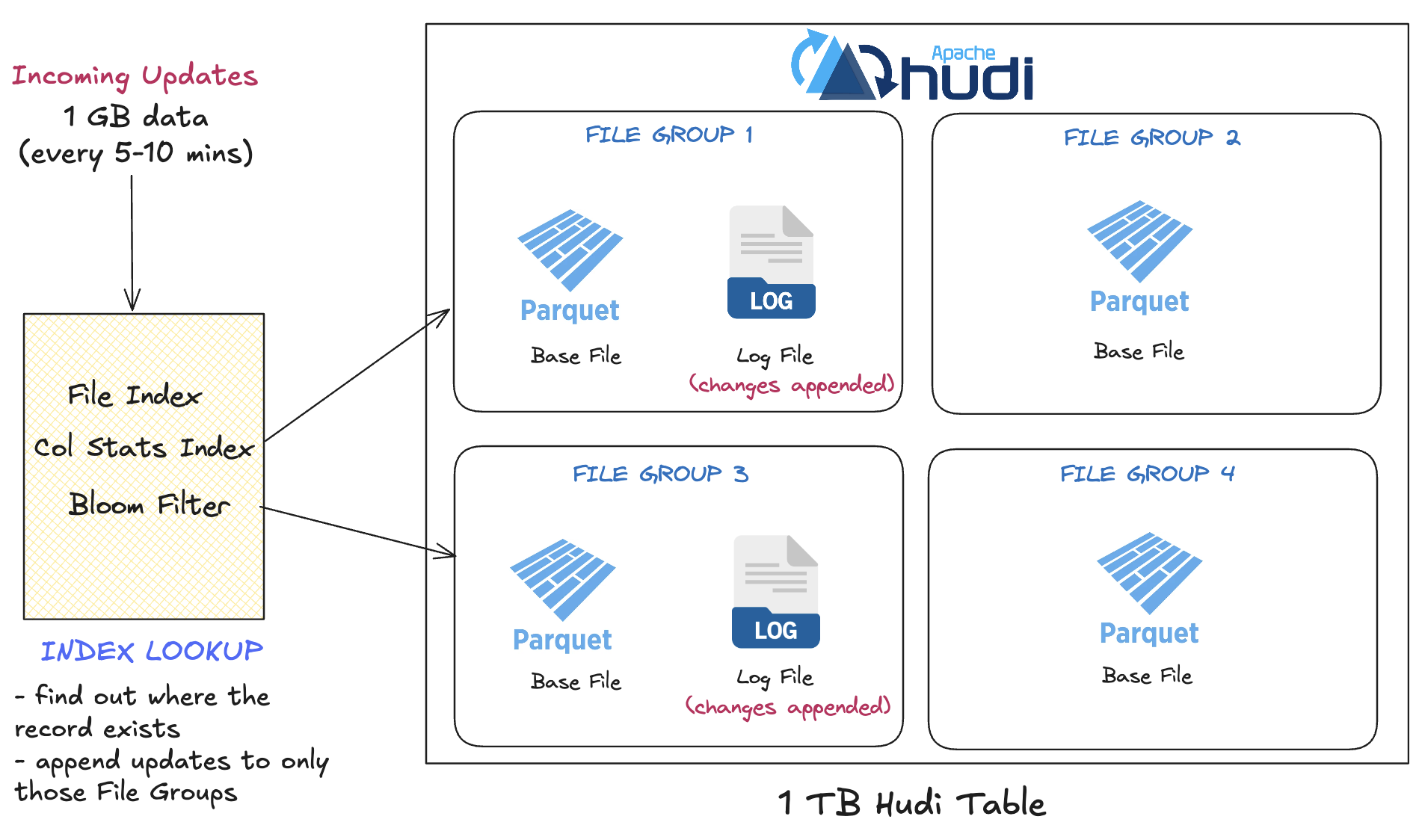
Iceberg handles row-level updates and deletes by recording them as delete files. To identify which records to update or delete, Iceberg relies on scanning table metadata, and in some cases file-level data, to locate affected rows. This design uses a simple metadata approach but if partitioning is not highly selective, this lookup step can become a bottleneck for write performance on large tables with frequent small updates.
Asynchronous Compaction during ‘Merge’
Hudi employs optimistic concurrency control (OCC) between writers and maintains blocking-free multi-version concurrency control (MVCC) between writers and its asynchronous compaction process. This means writers can continue appending updates to the same records while earlier versions are being compacted in the background. Compaction operates asynchronously, creating new base files from accumulated log files, without interfering with active writers. This ensures great data freshness as well as better compression ratio and thus excellent query performance for columnar files longer term.
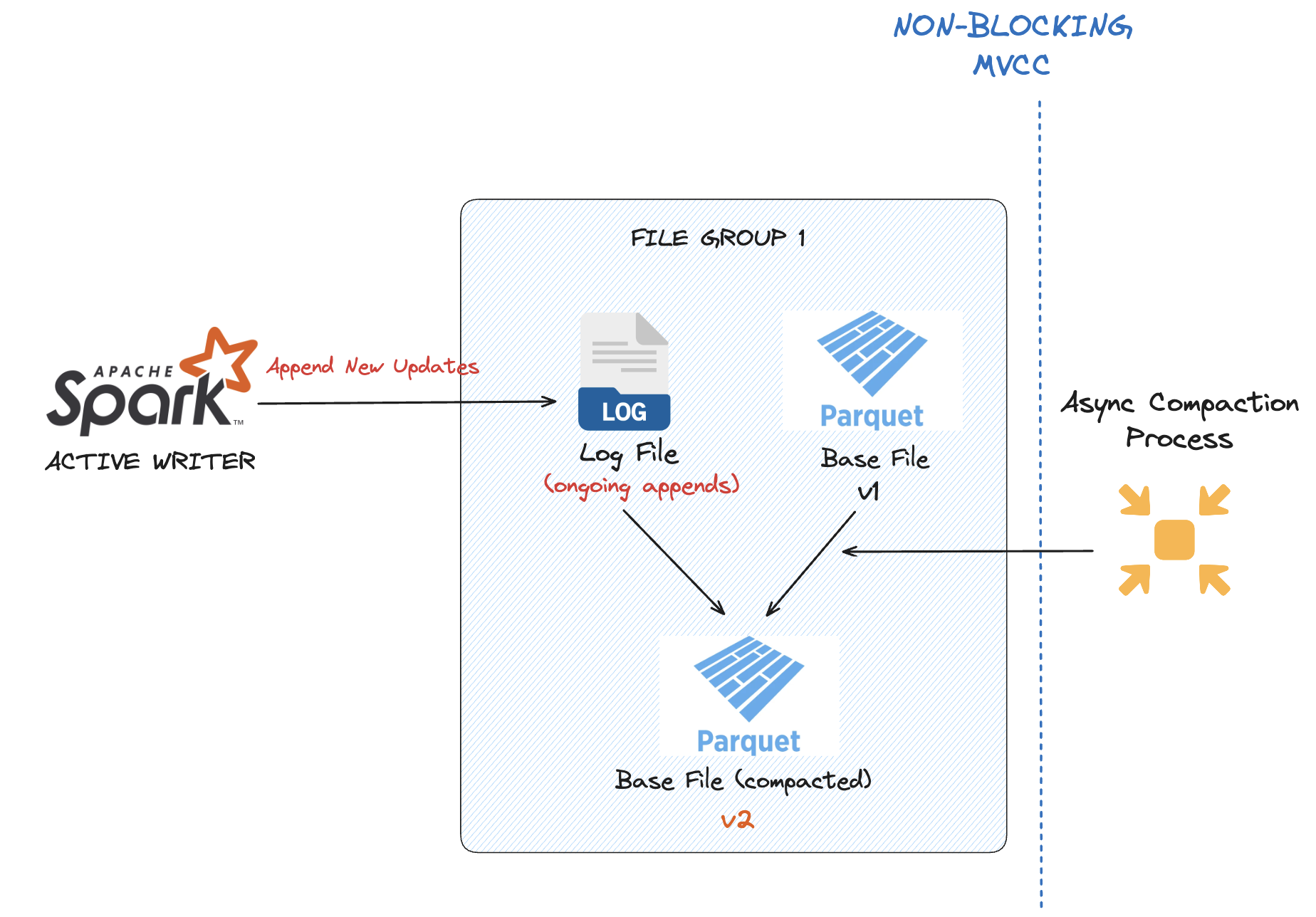
Iceberg maintains consistent snapshots across all operations, but it does not separate a dedicated compaction action from other write operations. As a result, if both a writer and a maintenance process try to modify overlapping data, standard snapshot conflict resolution ensures only one succeeds and might require retries in some concurrent write scenarios, but there is no asynchronous way to run compaction services. This could lead to livelocking between the writer and table maintenance, where one of them continuously causes the other to fail.
Non-Blocking Concurrency Control (NBCC) for Real-time applications
Hudi 1.0 further extends its concurrency model to allow multiple writers to safely update the same record at the same time with non-blocking conflict resolution. It supports serializability guarantees based on write completion timestamps (arrival-time processing), while also allowing record merging according to event-time order if required. This flexible concurrency strategy enables concurrent writes to proceed, without the need to wait, making it ideal for real-time applications that demand faster ingestion.
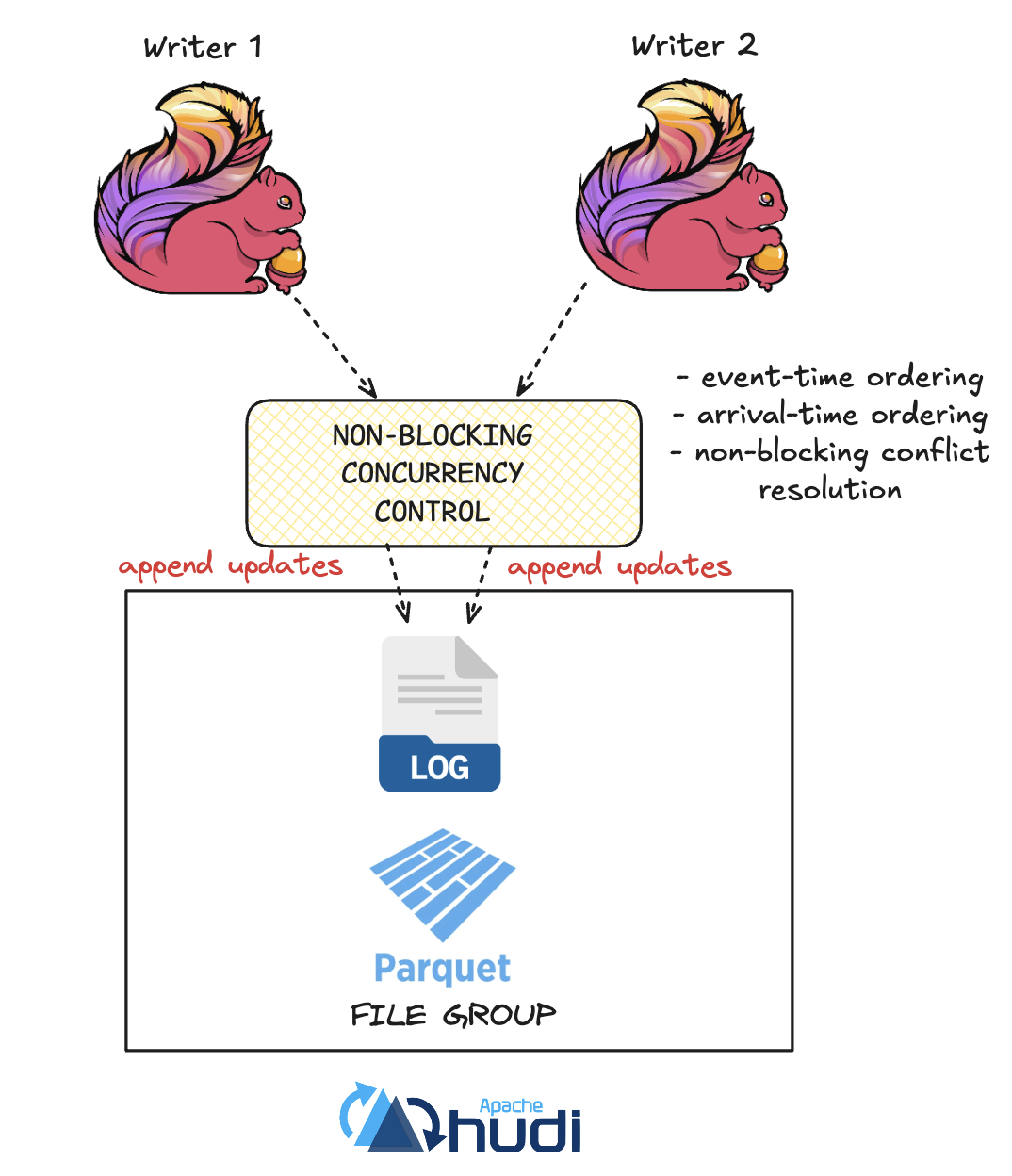
Iceberg applies OCC through its snapshot approach, where writers commit updates against the latest known snapshot, and if conflicts are detected, retries are required. There is no explicit distinction between arrival-time and event-time semantics for concurrent record updates.
Minimizing Read Costs
Hudi organizes records into file groups, ensuring that updates are consistently routed back to the same group where the original records were stored. This approach means that when a query is executed, it only needs to scan the base file and any delta log files within that specific file group, reducing the data that must be read and merged at query time. By tying updates and inserts to a consistent file group, Hudi preserves locality and limits merge complexity.
Iceberg applies updates and deletes using delete files, and these can reference any row in any base file. As a result, readers must examine all relevant delete files along with all associated base data files during scan planning and execution, which can increase I/O and metadata processing requirements for large tables.
Performant Read-Side Merge
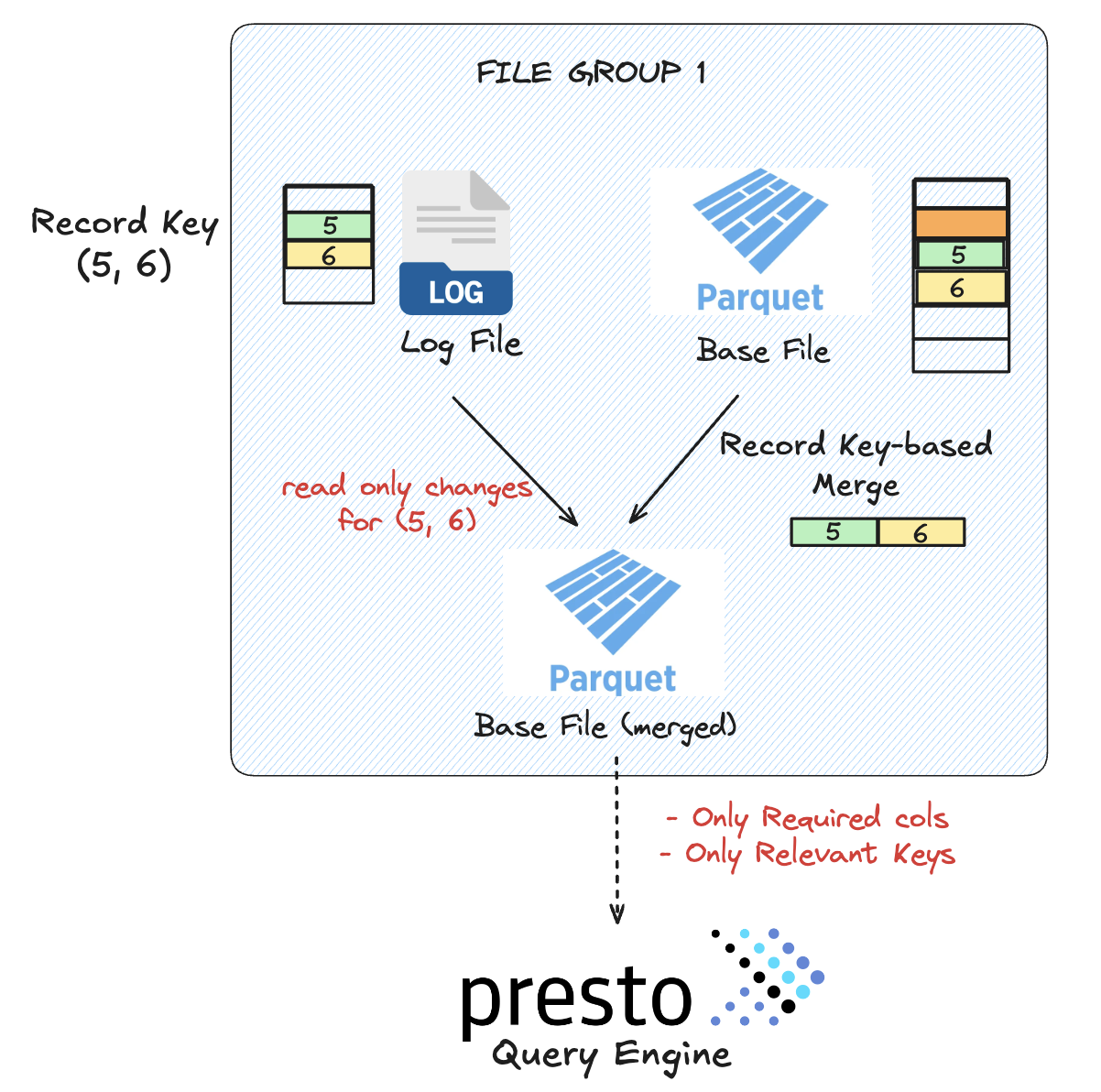
Hudi’s MoR implementation uses key-based merging to reconcile delta log records with base files, which allows query engines to push down filters and still correctly merge updates based on record keys. This selective merging reduces unnecessary I/O and improves performance for queries that only need a subset of columns or rows.
Iceberg historically required readers (particularly Spark readers) to load entire base files when applying positional deletes. This was because pushing down filters could change the order or number of rows returned by the Parquet reader, making positional delete applications incorrect. As a result, filter pushdowns could not be safely applied, forcing a full file scan to maintain correctness. There has been ongoing work in the Iceberg community to address this limitation by improving how positional information is tracked through filtered reads.
Efficient Compaction Planning
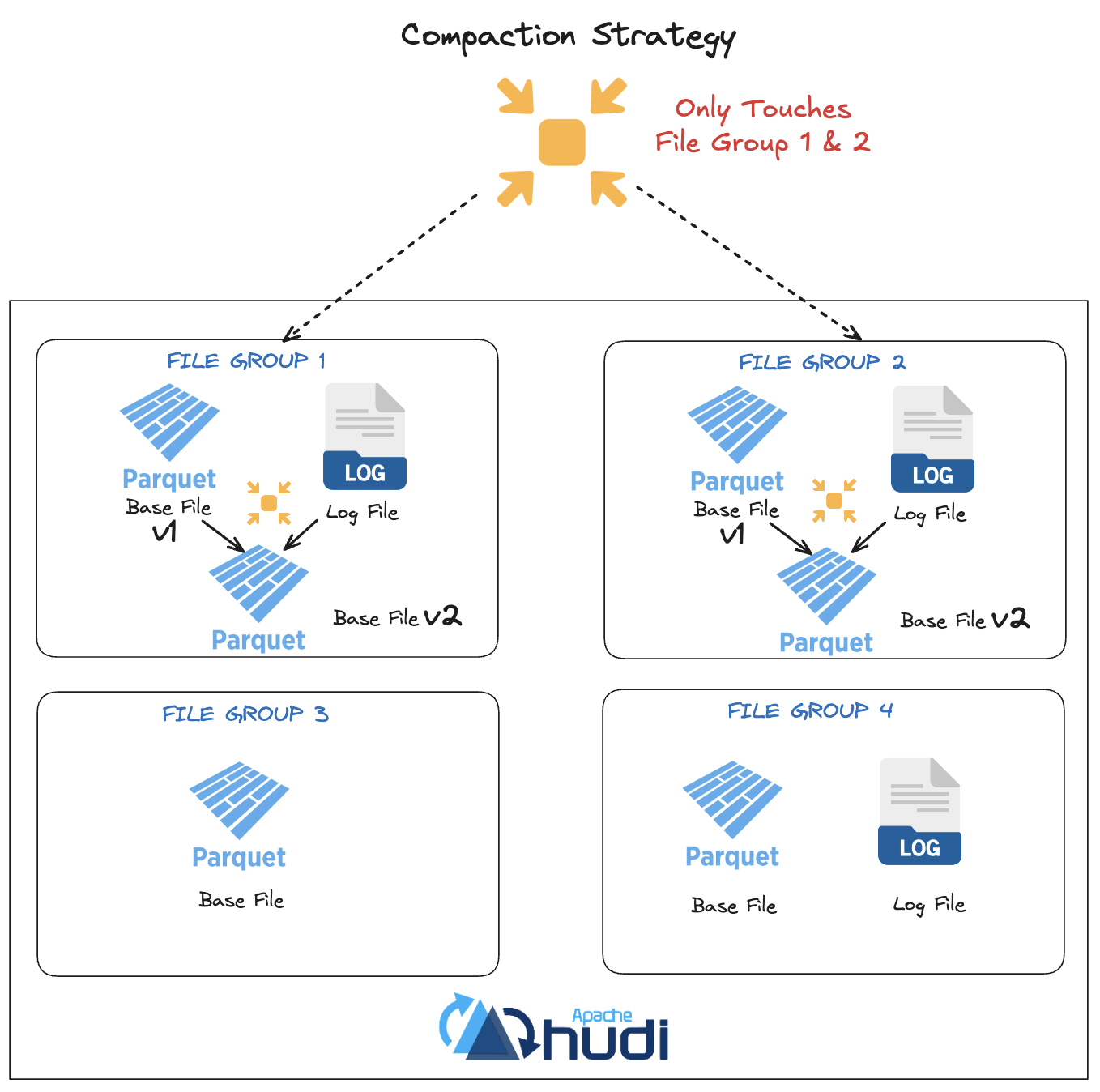
Hudi’s compaction strategy operates at the level of individual file groups, which means it can plan and execute small, predictable units of compaction work. This fine-grained approach allows compaction to proceed incrementally and avoids large, unpredictable workloads.
In Iceberg, compaction must consider all base files and their related delete files together, because delete files reference rows in the base data files. This creates a dependency graph where all related files must be handled in a coordinated way. As delete files accumulate over time, these compaction operations can become increasingly large and complex to plan, making it harder to schedule resources efficiently. If compaction falls behind, the amount of data that must be compacted in future operations continues to grow, potentially making the problem worse.
Temporal and Spatial Locality for Event-Time Filters
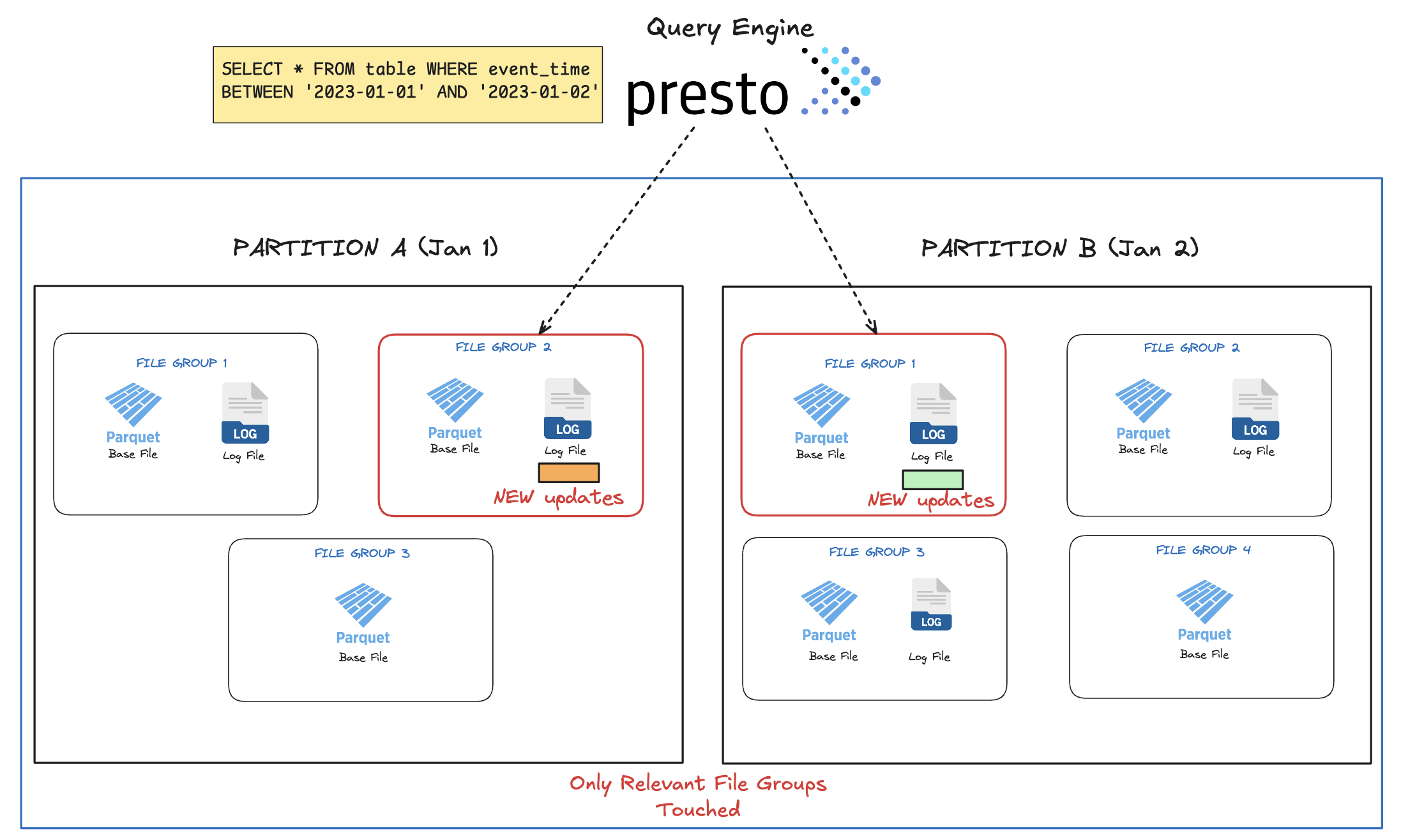
Hudi maintains temporal and spatial locality by ensuring that updates and deletes are routed back to the same file group where the original record was first stored. This preserves the time-based clustering or ordering of records, which is especially beneficial for queries filtering by event time or operating within specific time windows. By keeping related records together, Hudi enables efficient pruning of file groups along with partition pruning, during time-based queries.
Iceberg handles updates by deleting the existing record and inserting a new one, which may place the updated record in a different data file. Over time, this can scatter records that belong to the same logical or temporal group across multiple files, reducing the effectiveness of partition pruning and requiring periodic clustering or optimization to restore temporal locality.
Partial Updates for Performant Merge
Hudi supports partial updates by encoding only the columns that have changed into its delta log files. This means the cost of merging updates is proportional to the number of columns actually modified, rather than the total width of the record. For columnar datasets with wide schemas, this can significantly reduce write amplification and improve merge performance.
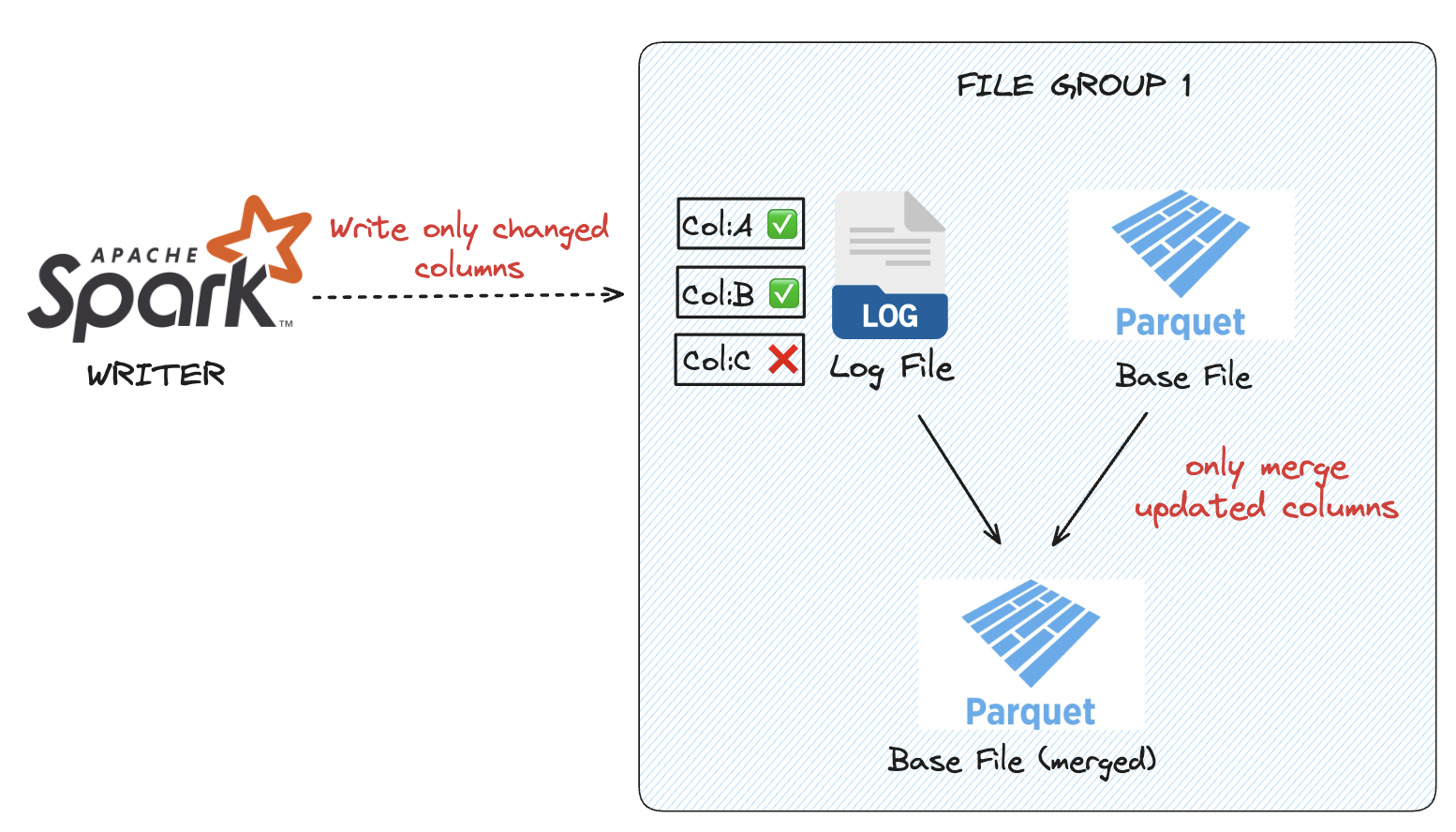
In Iceberg, updates are implemented as a delete plus a full-row insert, which requires rewriting the entire record even if only a single column has changed. As a result, update costs in Iceberg scale with the total number of columns in the record, increasing I/O and storage requirements for wide tables with frequent column-level updates.
Conclusion
Merge-on-Read (MoR) table type provides an alternative approach to managing updates and deletes on immutable columnar files in a lakehouse. While multiple open table formats support MoR semantics, their design choices significantly affect suitability for real-time and change-data driven workloads.
Apache Hudi’s MoR implementation specifically addresses the needs of high-ingestion, update-heavy pipelines. By appending changes to delta logs, preserving file-group-based data locality, supporting event-time ordering, and enabling asynchronous, non-blocking compaction, Hudi minimizes write amplification and supports low-latency data availability. These design primitives directly align with streaming and CDC patterns, where data arrives frequently and potentially out of order. Iceberg and Delta Lake also implement MoR semantics in their own ways to address transactional consistency and immutable storage goals.