Modernizing Data Infrastructure at Peloton Using Apache Hudi
Peloton re-architected its data platform using Apache Hudi to overcome snapshot delays, rigid service coupling, and high operational costs. By adopting CDC-based ingestion from PostgreSQL and DynamoDB, moving from CoW to MoR tables, and leveraging asynchronous services with fine-grained schema control, Peloton achieved 10-minute ingestion cycles, reduced compute/storage overhead, and enabled time travel and GDPR compliance.
Peloton is a global interactive fitness platform that delivers connected, instructor-led fitness experiences to millions of members worldwide. Known for its immersive classes and cutting-edge equipment, Peloton combines software, hardware, and data to create personalized workout journeys. With a growing member base and increasing product diversity, data has become central to how Peloton delivers value. The Data Platform team at Peloton is responsible for building and maintaining the core infrastructure that powers analytics, reporting, and real-time data applications. Their work ensures that data flows seamlessly from transactional systems to the data lake, enabling teams across the organization to make timely, data-driven decisions.
The Challenge: Data Growth, Latency, and Operational Bottlenecks
As Peloton evolved into a global interactive fitness platform, its data infrastructure was challenged by the growing need for timely insights, agile service migrations, and cost-effective analytics. Daily operations, recommendation systems, and compliance requirements demanded an architecture that could support near real-time access, high-frequency updates, and scalable service boundaries.
However, the team faced persistent bottlenecks with the existing setup:
- Reporting pipelines were gated by the completion of full snapshot jobs.
- Recommender systems could only function on daily refreshed datasets.
- The analytics platform was tightly coupled with operational systems.
- Microservice migrations were constrained to all-at-once shifts.
- Database read replicas incurred high infrastructure costs.
These limitations made it difficult to meet SLA expectations, scale workloads efficiently, and adapt the platform to new user and product needs.
The Legacy Architecture
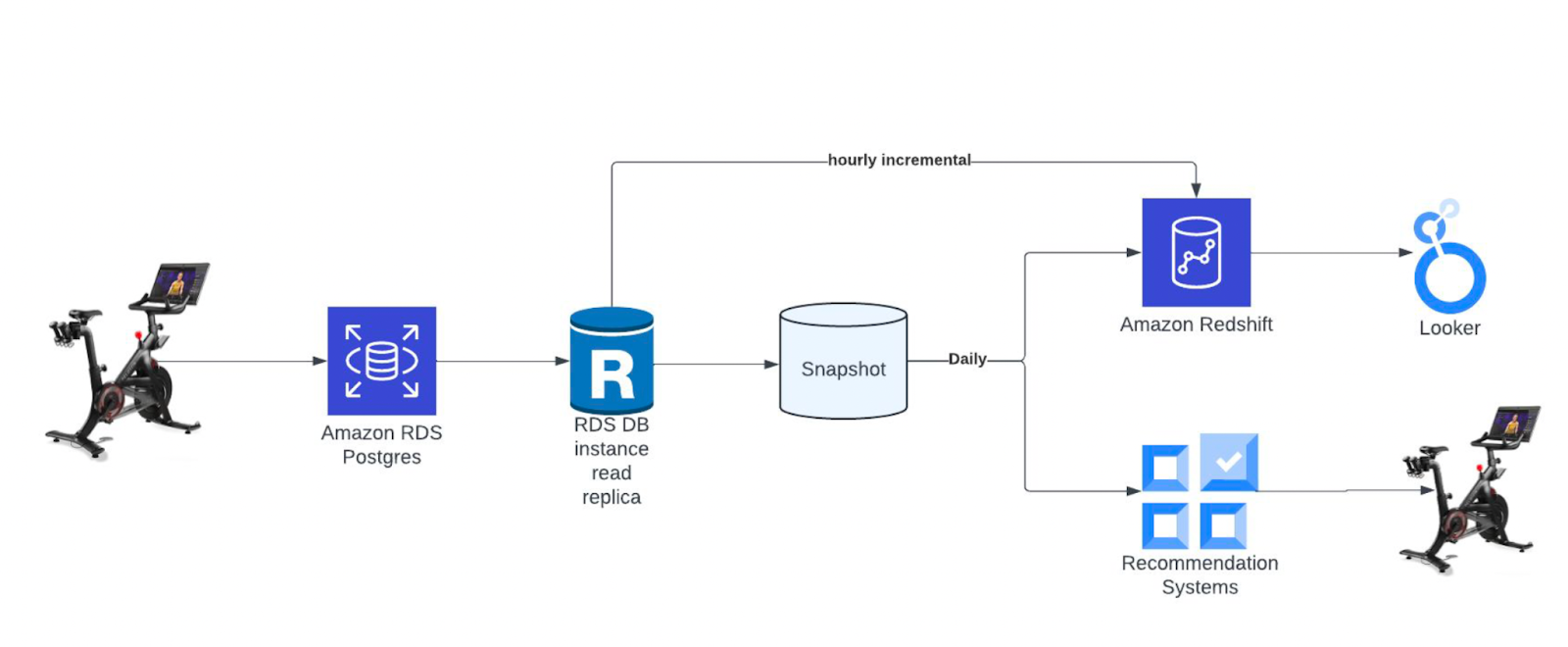
Peloton's earlier architecture relied on daily snapshots from a monolithic PostgreSQL database. The analytics systems would consume these snapshots, often waiting hours for completion. This not only delayed reporting but also introduced downstream rigidity.
Because the same data platform supported both online and analytical workloads, any schema or service migration required significant planning and coordination. Database read replicas, used to scale reads, increased cost overhead. Moreover, recommendation systems that depended on data freshness were constrained by the snapshot interval, limiting personalization capabilities. This architecture struggled to support a fast-moving product roadmap, near real-time analytics, and the data agility needed to experiment and iterate.
Reimagining the Data Platform with Apache Hudi
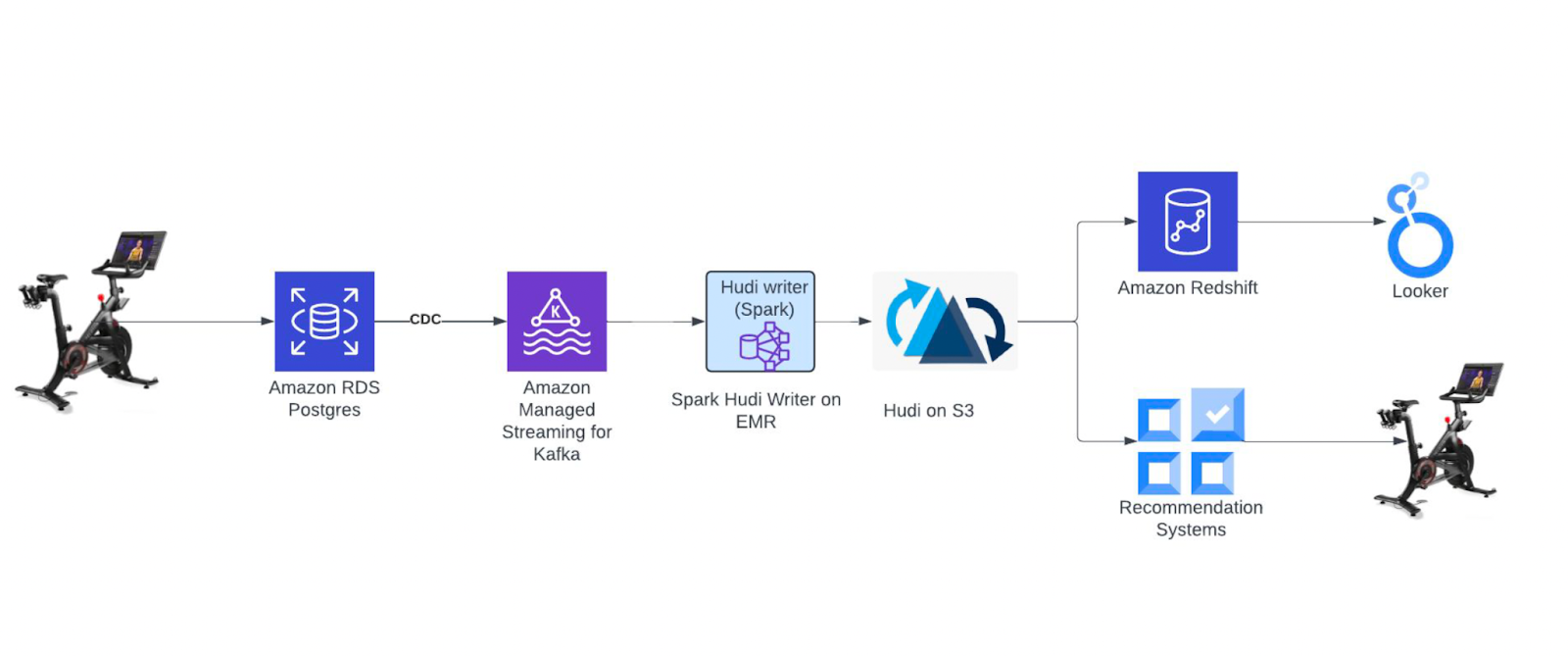
To address these challenges, the data platform team introduced Apache Hudi as the foundation of its modern data lake. The architecture was rebuilt to support Change Data Capture (CDC) ingestion from both PostgreSQL and DynamoDB using Debezium, with Kafka acting as the transport layer. A custom-built Hudi writer was developed to ingest CDC records into S3 using Apache Spark on EMR (version 6.12.0 with Hudi 0.13.1).
Peloton initially chose Copy-on-Write (CoW) table formats to support querying via Redshift Spectrum and simplify adoption. However, performance and cost bottlenecks prompted a transition to Merge-on-Read (MoR) tables with asynchronous table services for cleaning and compaction.
Key architectural enhancements included:
- Support for GDPR compliance through structured delete propagation.
- Time travel queries for recommender model training and data recovery.
- Phased migration support for microservices via decoupled ingestion.
Peloton's broader data platform tech stack supports this architecture with a range of tools for orchestration, analytics, and governance. This includes EMR for compute, Redshift for querying, DBT for data transformations, Looker for BI and visualization, Airflow for orchestration, and DataHub for metadata management. These components complement Apache Hudi in forming a modular and production-ready lakehouse stack.
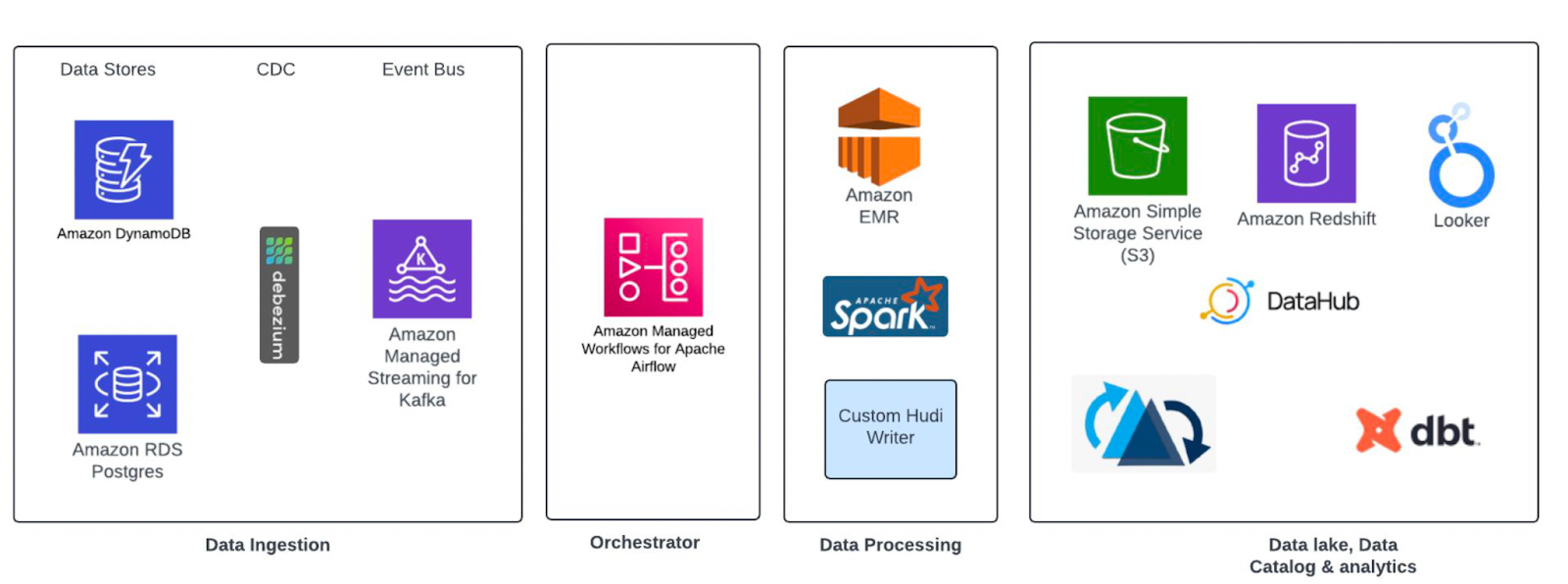
Learnings from Running Hudi at Scale
With Hudi now integrated into Peloton's data lake, the team began to observe and address new operational and architectural challenges that emerged at scale. This section outlines the major lessons learned while maintaining high-ingestion throughput, ensuring data reliability, and keeping infrastructure costs under control.
CoW vs MoR: Performance Trade-offs
Initially, Copy-on-Write (CoW) tables were chosen to simplify deployment and ensure compatibility with Redshift Spectrum. However, as ingestion frequency increased and update volumes spanned hundreds of partitions, performance became a bottleneck. Some high-frequency tables with updates across 256 partitions took nearly an hour to process per run. Additionally, retaining 30 days of commits for training recommender models significantly inflated storage requirements, reaching into the hundreds of gigabytes.
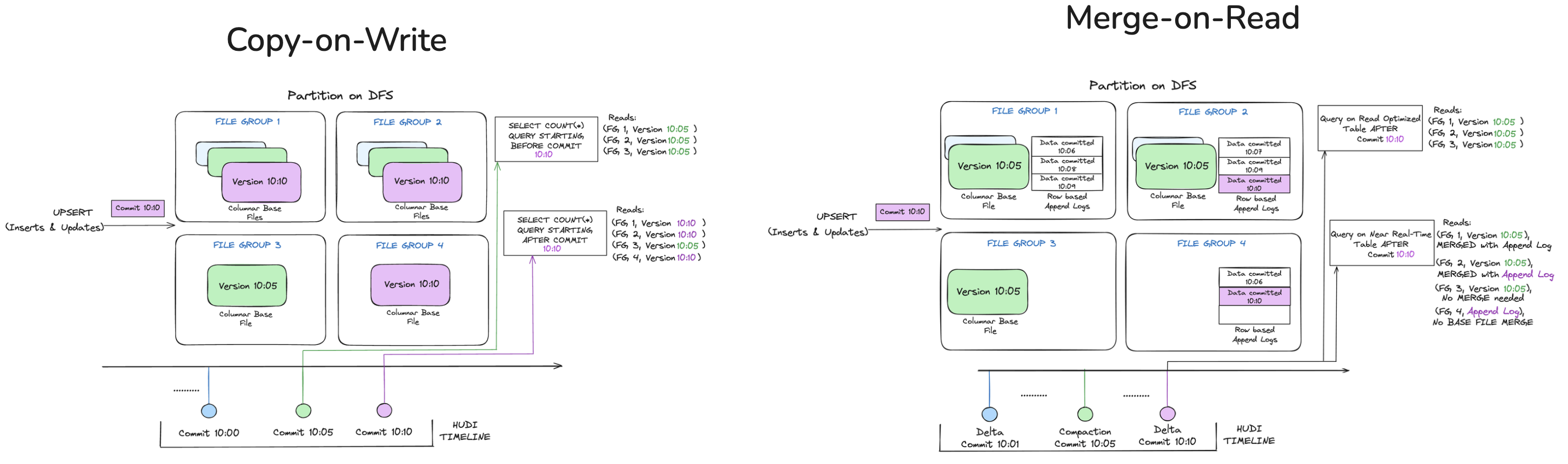
To resolve this, the team migrated to Hudi’s Merge-on-Read (MoR) tables and reduced commit retention to 7 days. With ingestion jobs now running every 10 minutes, latency dropped significantly, and storage and compute usage became more efficient.
Async vs Inline Table Services
To improve write throughput and meet low-latency ingestion goals, the Peloton team initially configured Apache Hudi with asynchronous cleaner and compactor services. This approach worked well across most tables, allowing ingestion pipelines to run every 10 minutes with minimal blocking but introduced some operational edge cases. Some of the challenges encountered included:
- Concurrent execution of writer and cleaner jobs, leading to conflicts. These were mitigated by introducing DynamoDB-based locks to serialize access.
- Reader-cleaner race conditions, where time travel queries intermittently failed with
"File Not Found"errors - traced back to cleaners deleting files mid-read. - Compaction disruptions caused by EMR node terminations, which led to orphaned files when jobs failed mid-way.
These edge cases were largely due to the operational complexity of managing concurrent workloads at Peloton’s scale. After weighing reliability against latency, the team opted to switch to inline table services for compaction and cleaning, augmented with custom logic to control when these actions would run. This change improved system stability while maintaining acceptable latency trade-offs.
Glue Schema Version Limits
As schema evolution continued, the team used Hudi's META_SYNC_ENABLED to sync schema updates with AWS Glue. Over time, high-frequency schema updates pushed the number of TABLE_VERSION resources in Glue beyond the 1 million limit. This caused jobs to fail in ways that were initially difficult to trace.
One such failure manifested as the following error:
ERROR Client: Application diagnostics message: User class threw exception:
java.lang.NoSuchMethodError: 'org.apache.hudi.exception.HoodieException
org.apache.hudi.sync.common.util.SyncUtilHelpers.getExceptionFromList(java.util.Collection)'
After significant debugging, the issue was traced to AWS Glue limits. The team implemented a multi-step fix:
- Worked with AWS to temporarily raise resource limits.
- Developed a Python service to identify and delete outdated table versions, removing over 1 million entries.
- Added an Airflow job to schedule weekly cleanup tasks.
- Improved schema sync logic to trigger only when the schema changed.
Debezium & TOAST Handling
PostgreSQL CDC ingestion posed unique challenges due to the database’s handling of large fields using TOAST (The Oversized-Attribute Storage Technique). When fields over 8KB were unchanged, Debezium emitted a placeholder value __debezium_unavailable_value, making it impossible to determine whether the value had changed.
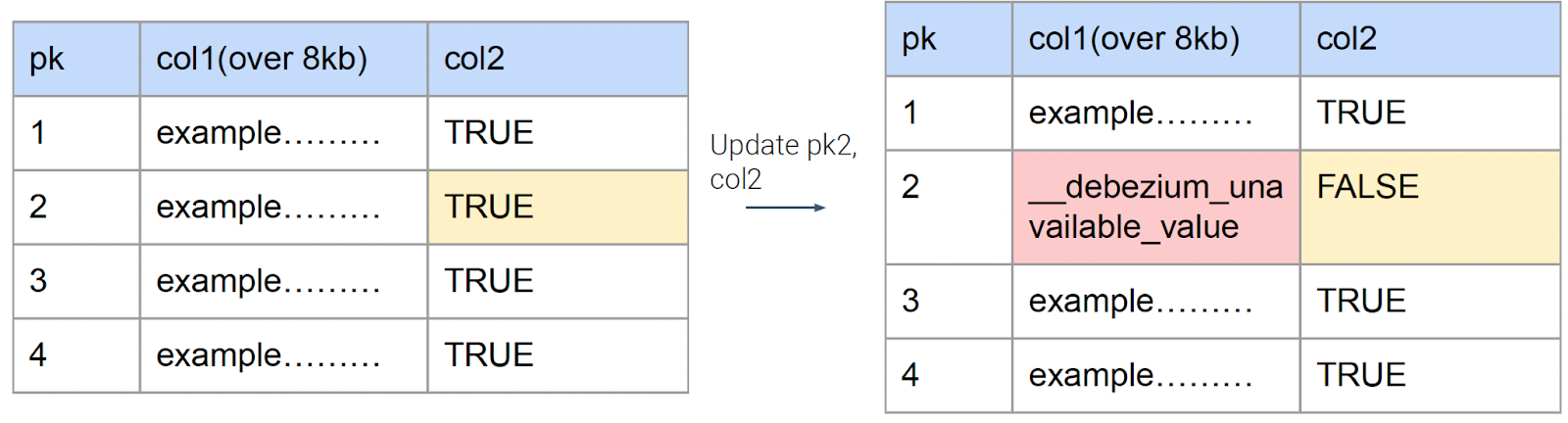
To address this, Peloton:
- Populated initial data using PostgreSQL snapshots.
- Implemented self-joins between incoming CDC records and existing Hudi records to fill in missing values.
- Separated inserts, updates, and deletes within Spark batch processing.
- Used the
tsfield as the precombine key to ensure only the latest record state was retained.
A reconciliation pipeline was also developed to heal data inconsistencies caused by multiple operations on the same key within a batch (e.g., create-delete-create).
Data Validation and Quality Enforcement
Data quality was critical to ensure trust in the newly established data lake. The team developed several internal libraries and checks:
- A Crypto Shredding Library to encrypt
user_idand other PII fields before storage. - A Data Validation Framework that compared records in the lake against snapshot data.
- A Data Quality Library that enforced column-level thresholds. These checks integrated with DataHub and were tied to Airflow sensors to halt downstream jobs on failures.
DynamoDB Ingestion and Schema Challenges
Some Peloton services relied on DynamoDB for operational workloads (NoSQL). To ingest these datasets into the lake, the team used DynamoDB Streams and a Kafka Connector, allowing reuse of the existing Kafka-based Hudi ingestion path.
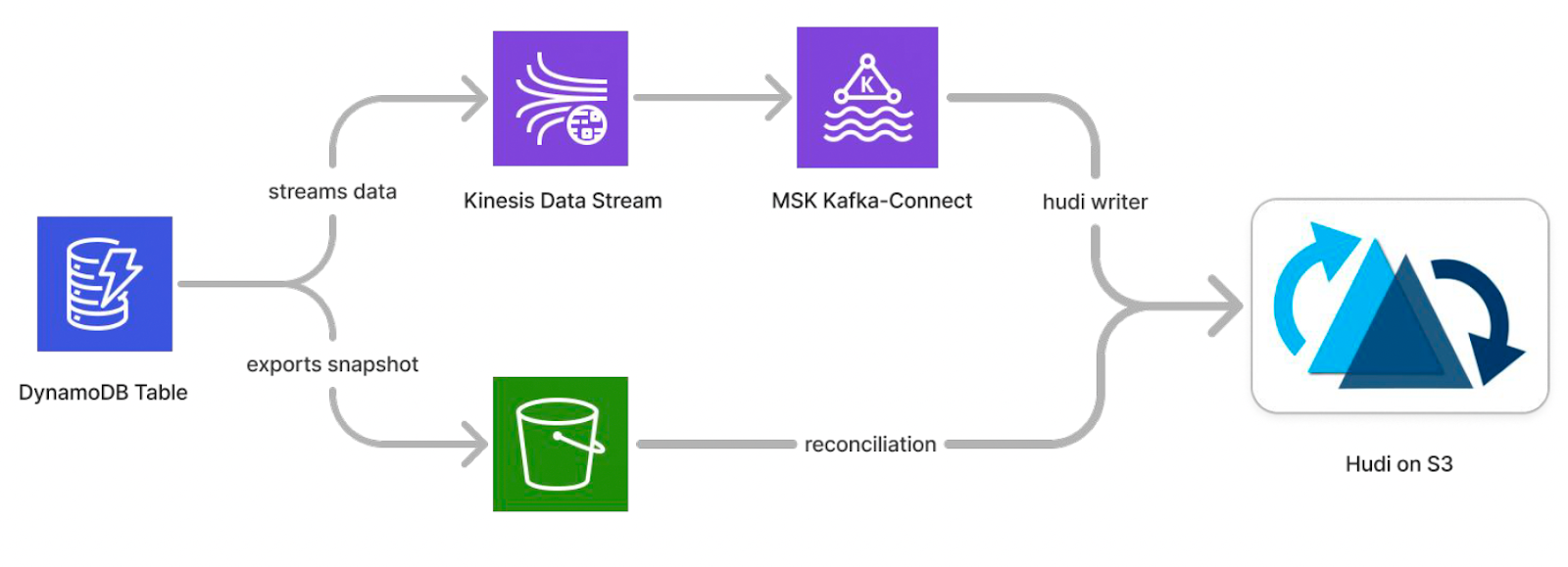
However, the NoSQL nature of DynamoDB introduced schema management challenges. Two strategies were evaluated:
- Stakeholder-defined schemas, using SUPER-type fields.
- Dynamic schema inference, where incoming JSON records were parsed, and the evolving schema was inferred and reconciled.
The team opted for dynamic inference despite increased processing time, as it enabled better support for exploratory workloads. Daily snapshots and reconciliation steps helped clean up inconsistent schema states.
Reducing Operational Costs
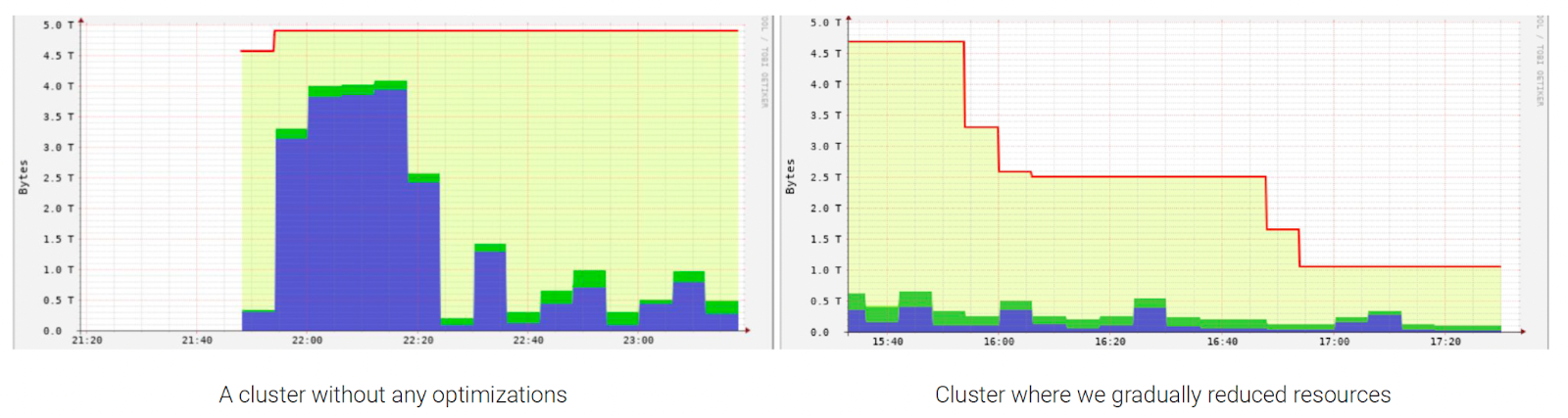
As the system matured, cost optimization became a priority. The team used Ganglia to analyze job profiles and identify areas for improvement:
- EMR resources were gradually right-sized based on CPU and memory usage.
- Conditional Hive syncing was introduced to avoid unnecessary sync operations during each run.
- A Spark-side inefficiency was discovered where archived timelines were unnecessarily loaded, causing jobs to take 4x longer. Fixing this reduced overall latency and compute resource usage.
These operational refinements significantly reduced idle times and improved the cost-efficiency of the platform.
Gains from Hudi Adoption
Peloton's transition to Apache Hudi led to measurable performance, operational, and cost-related improvements across its modern data platform.
Peloton's transition to Apache Hudi yielded several measurable improvements:
- Ingestion frequency increased from once daily to every 10 minutes.
- Reduced snapshot job durations from an hour to under 15 minutes.
- Cost savings by eliminating read replicas and optimizing EMR cluster usage.
- Time travel support enabled retrospective analysis and model re-training.
- Improved compliance posture through structured deletes and encrypted PII.
The modernization laid the groundwork for future evolution, including real-time streaming ingestion using Apache Flink and continued improvements in data freshness, latency, and governance.
This blog is based on Peloton’s presentation at the Apache Hudi Community Sync. If you are interested in watching the recorded version of the video, you can find it here.