

What is Hudi
Apache Hudi is an open data lakehouse platform, built on a high-performance open table format to bring database functionality to your data lakes. Hudi reimagines slow old-school batch data processing with a powerful new incremental processing framework for low latency minute-level analytics.
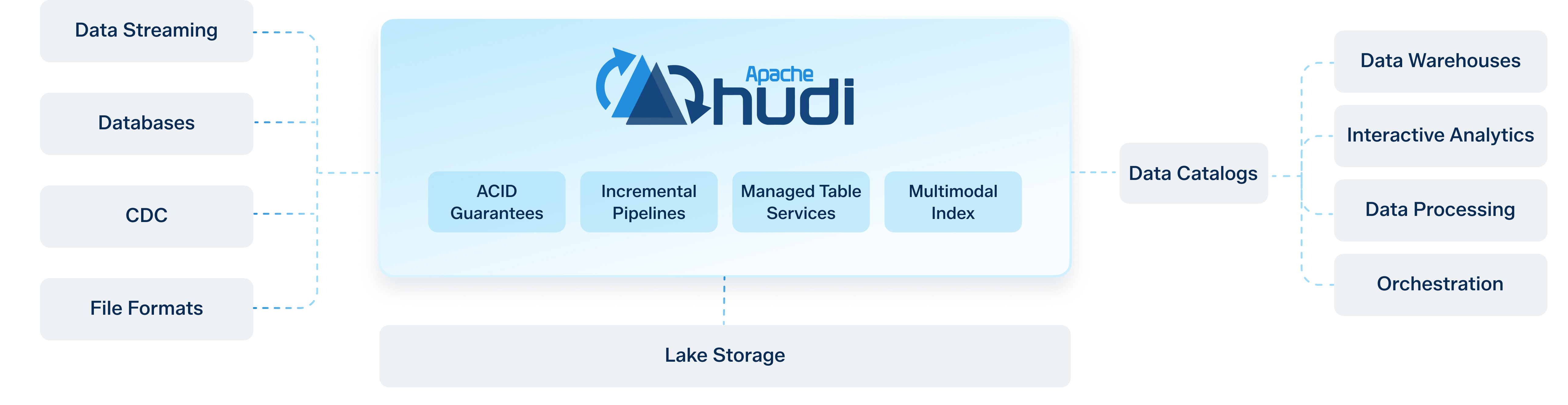
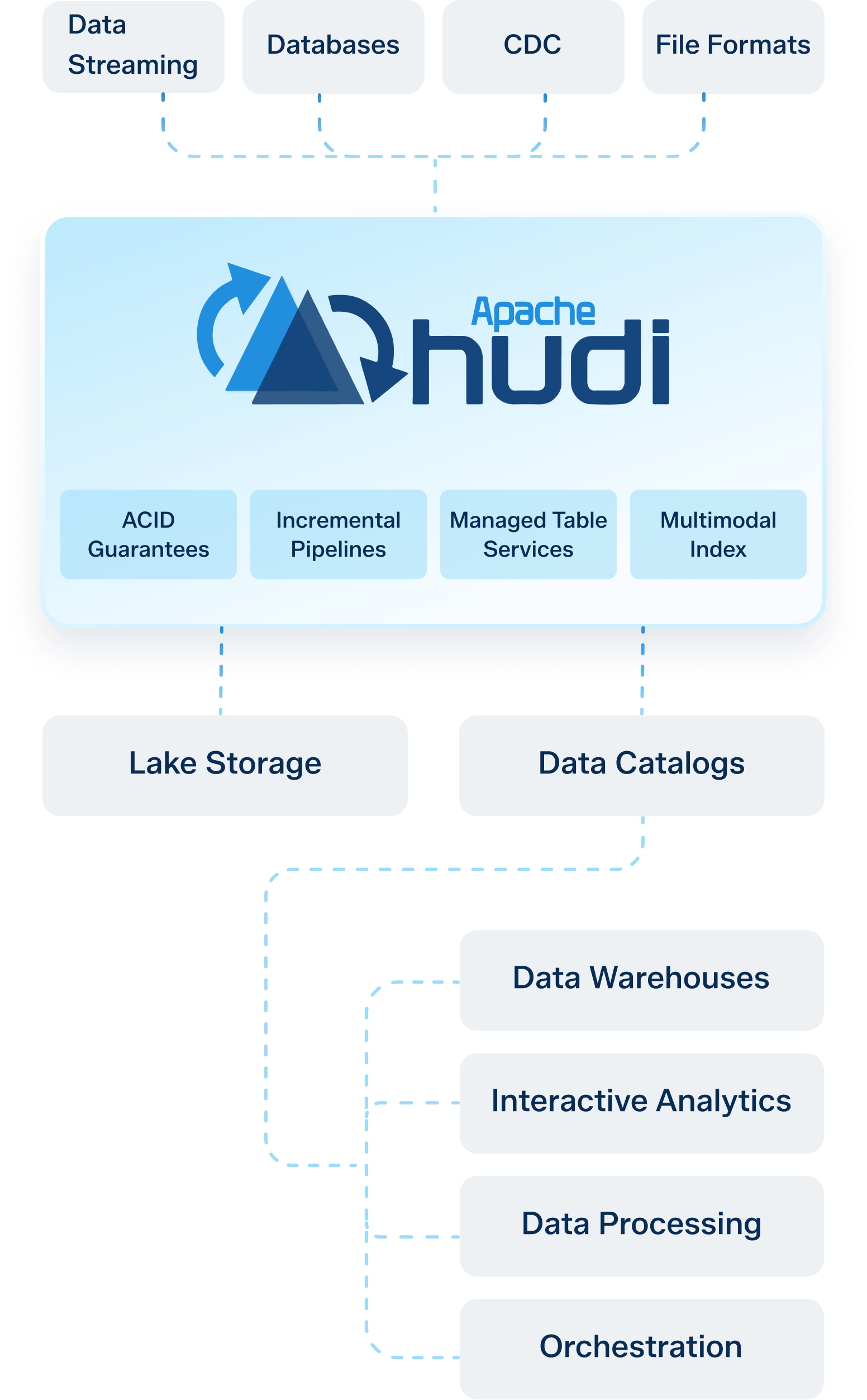
Integrations
Data Streaming

Apache Kafka

Apache Pulsar
Databases

PostgreSQL

MySQL
CDC

Debezium

Apache Flink CDC
File Formats

Apache Parquet

Apache ORC

Apache Avro

CSV

JSON
Lake Storage

Apache Hadoop

Amazon S3

Google Cloud Storage

Azure Blob Storage

Alibaba Cloud

IBM Cloud

Oracle Cloud

Tencent Cloud

MinIO
Data Catalogs

AWS Glue Data Catalog

Google BigQuery

Apache Hive Metastore

DataHub

Apache XTable (Incubating) (For sync)
Data Warehouses

Amazon Redshift

ClickHouse
Interactive Analytics

Presto

Trino
Apache Hive

AWS Athena
Google BigQuery

Apache Doris

StarRocks

Apache Impala
Data Processing

Apache Spark
Apache Flink

Databricks

AWS EMR

Azure HDInsight

Onehouse

Ray

Daft
Orchestration

dbt

Apache Airflow
Hudi Features
Why Hudi
The most innovative and completely open data lakehouse platform in the industry!
Trusted Platform
Battle tested and proven in production in some of the largest data lakes on the planet.
Open Source
Hudi is a thriving & growing community that is built with contributions from people around the globe.
High Performance
Hudi's storage format is purpose-built to continuously deliver performance as data scales.
Data streams
Take advantage of built-in CDC sources and tools for streaming ingestion.
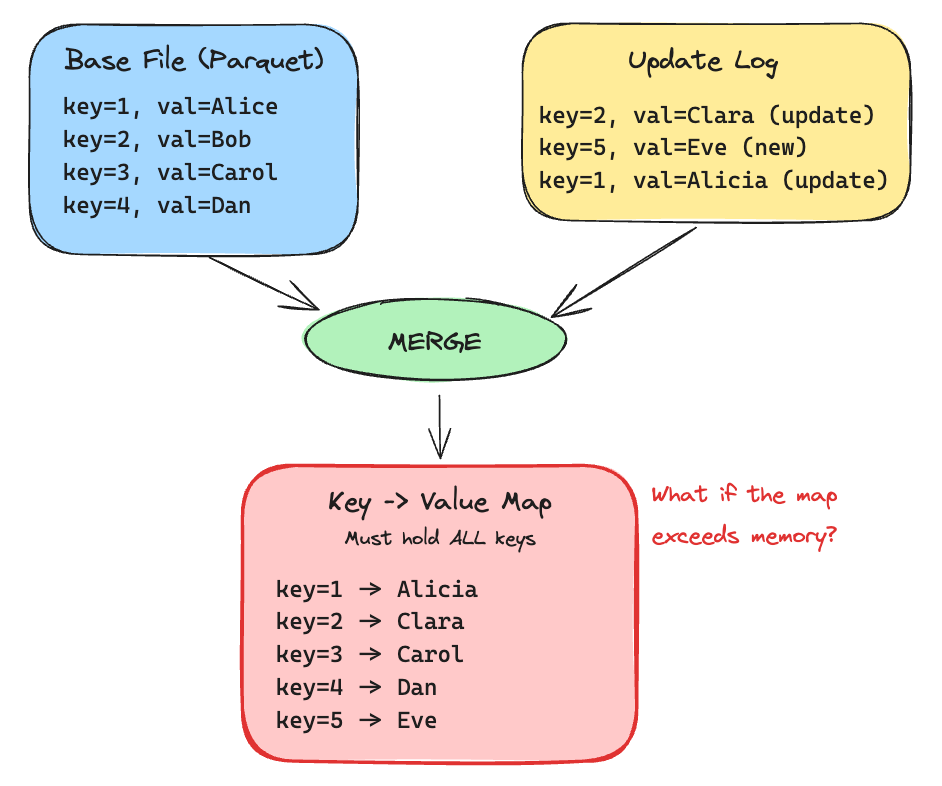
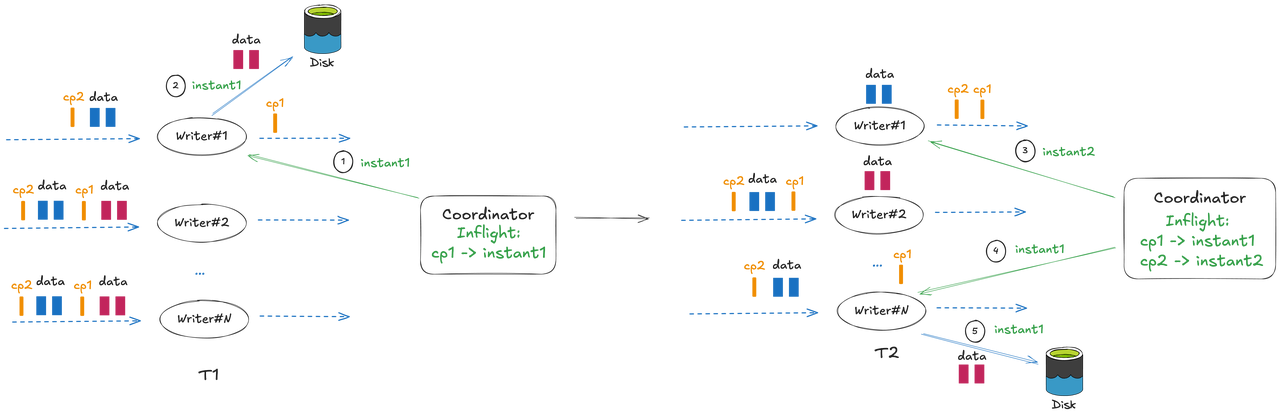
Hudi Blogs



Join our Community
Get technical help, influence the product roadmap & see what’s new with Hudi!
Youtube
GitHub
Slack
Mailing
X