How Zupee Cut S3 Costs by 60% with Apache Hudi
This post summarizes Zupee's talk from the Apache Hudi community sync. Watch the recording on YouTube.
Zupee is India's largest skill-based Ludo platform (Ludo is a classic Indian board game), founded in 2018 with a vision of bringing moments of joy to users through meaningful entertainment. The company was the first to introduce a skill element to culturally relevant games like Ludo, reviving the joy of traditional Indian gaming.
At Zupee, data plays a crucial role in everything they do—from understanding user behavior to optimizing services. It sits at the core of their decision-making process. In this community sync, Amarjeet Singh, Senior Data Engineer at Zupee, shared how his team built a scalable data platform using Apache Hudi and the significant performance gains they achieved.
Data Platform Architecture
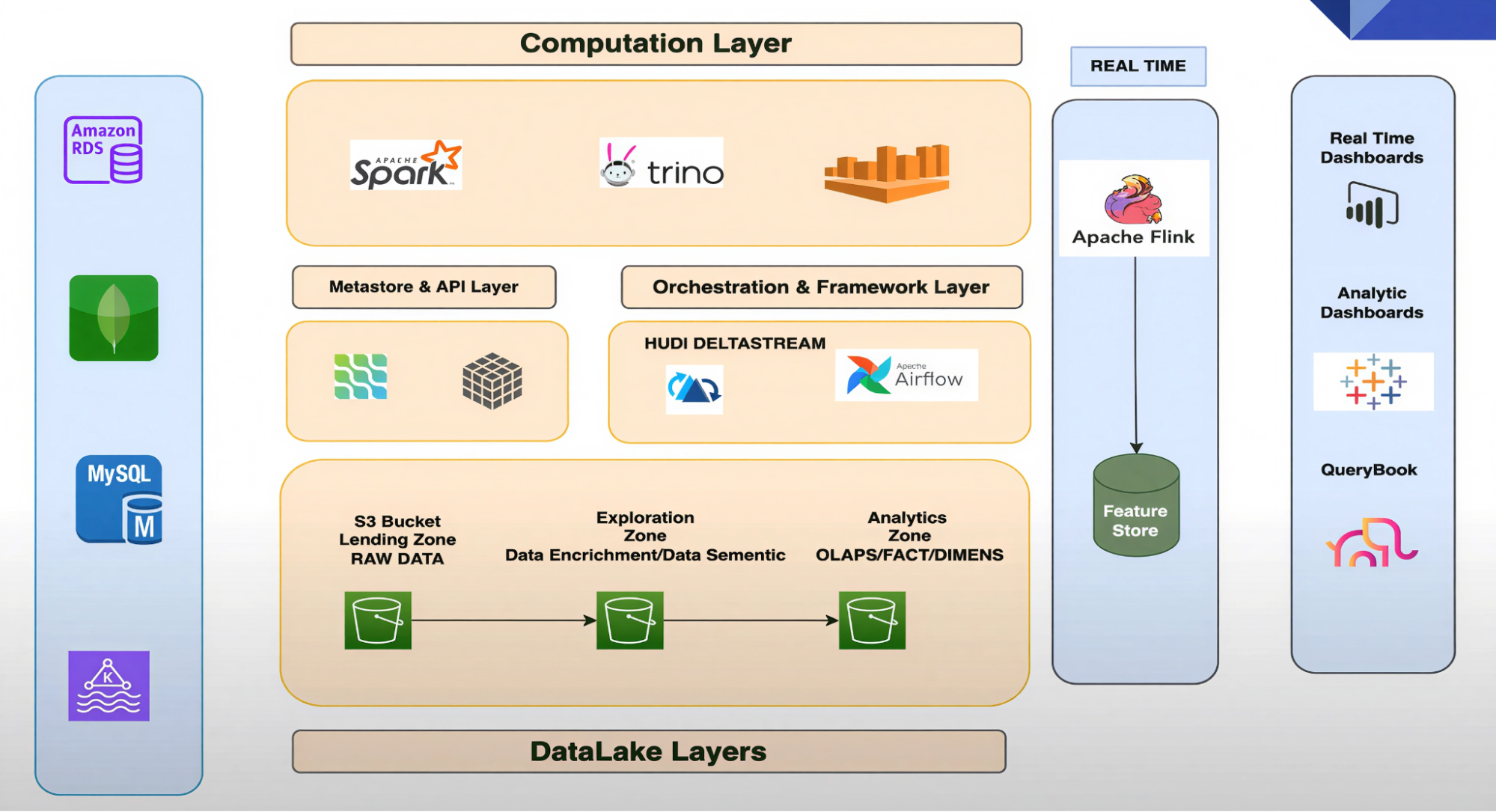
Zupee's data platform architecture is designed to handle complex data needs efficiently. It consists of several layers working together:
Three-Tiered Data Lake
The data lake is structured into three zones:
- Landing Zone: Where raw data first arrives—like a receiving dock where all incoming data is stored in its original format.
- Exploration Zone: Data is cleaned and prepared for analysts and data scientists to explore and derive insights.
- Analytical Zone: Processed data optimized for analytical queries. This layer stores OLAP tables, facts and dimensions, or denormalized wide tables.
Metastore and API Layer
This layer acts as the brain of the data platform, managing metadata and providing APIs for data access and integration.
Orchestration and Framework Layer
The orchestration layer includes tools like Apache Airflow for scheduling and managing workflows, along with in-house tools and frameworks for ML operations, data ingestion, and data computation—including Hudi Streamer for data ingestion.
Compute Layer
The compute layer includes Apache Spark for large-scale data processing, and Amazon Athena and Trino for querying.
Real-Time Serving Layer
For real-time data needs, Zupee uses Apache Flink as a powerful streaming framework to power their feature store and enable real-time model predictions.
The serving layer includes real-time dashboards powered by Flink, analytical dashboards powered by Athena and Trino, and Jupyter notebooks for ad-hoc analysis by data scientists and machine learning teams.
Workflow-Based Data Ingestion
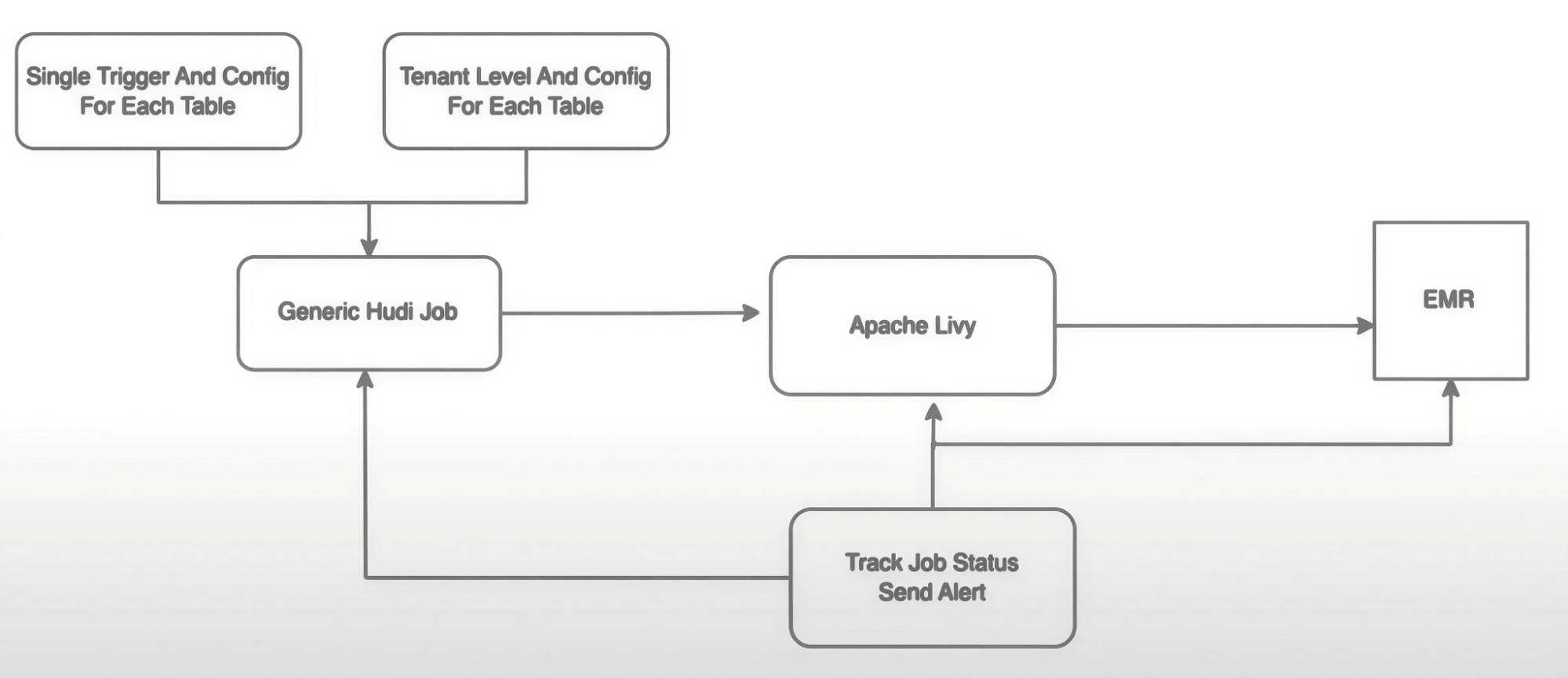
Zupee designed a data ingestion pipeline that provides smooth integration and scalability. At the heart of their approach is a centralized configuration system that gives them granular control over every aspect of their jobs.
Centralized Configuration
The team uses YAML files to centrally manage job details and tenant-level settings. This promotes consistency and makes updates easy. The centralized system is hosted on Amazon EMR, ensuring uniformity across all ingestion jobs.
Multi-Tenant Pipeline
Zupee runs a multi-tenant setup of generic pipelines. They can switch between different versions of Spark, Hudi Streamer, and Scala—all controlled at the tenant level.
Automated Spark Command Generation
The system automatically generates Spark commands based on YAML configurations. This significantly reduces manual intervention, minimizes errors, and accelerates the development process.
The Ingestion Flow
Here's how the workflow operates:
- A generic job reads a YAML file containing specific job information and tenant-level configurations.
- A single trigger starts each pipeline.
- The generic job creates Spark configurations and generates a
spark-submitcommand with Hudi Streamer settings. - The command is submitted using Livy or EMR steps.
- Throughout the process, the team tracks data lineage for monitoring and debugging.
This workflow-based approach streamlines data ingestion, making it both scalable and reliable for handling large volumes of data.
Real-Time Ingestion with Hudi Streamer
Zupee uses Hudi Streamer, a utility built on checkpoint-based ingestion. It supports various sources including distributed file systems (S3, GCS), Kafka, and JDBC sources like MySQL and MongoDB.
Key Benefits
- Checkpoint-based consistency: Ensures the ability to resume from the last checkpoint in case of interruption.
- Easy backfills: Reprocess historical data efficiently based on checkpoints, without re-ingesting the entire dataset—saving both time and resources.
- Data catalog syncing: Automatically syncs metadata to catalogs such as AWS Glue and Hive Metastore.
- Built-in transformations: Supports SQL transformations and flat transformations, allowing complex logic to be applied on the fly.
- Custom transformations: Developers can build custom transformation classes for specific requirements.
Deep Dive: How Hudi Streamer Works
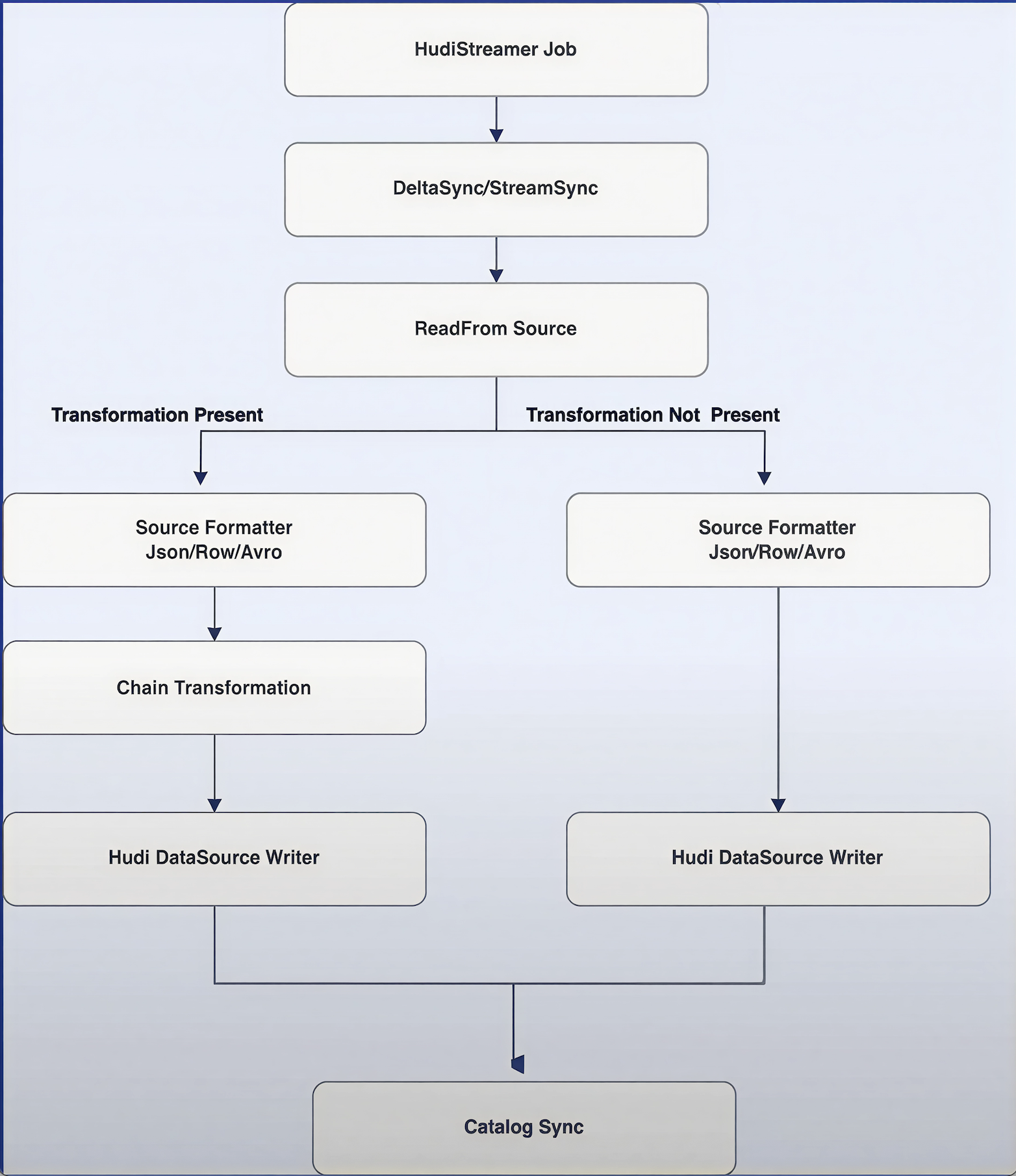
Here's how Hudi Streamer processes data internally:
-
Job Submission: A Spark job is submitted with Hudi properties specifying primary keys, checkpointing details, and other configurations.
-
StreamSync Wrapper: The job creates a StreamSync wrapper (formerly DeltaSync) based on the provided properties.
-
Continuous or Single Run: StreamSync initiates a synchronized process that can run continuously or as a single batch, depending on the parameters.
-
Checkpoint Retrieval: Hudi Streamer checks if a checkpoint exists and retrieves the last position from the Hudi commit metadata. For S3-based ingestion, it checks the last modified date; for Kafka sources, it retrieves the last committed offset.
-
Transformation: If transformations are configured (single or chained), they are applied to the source data based on the format (JSON, Avro, etc.).
-
Write and Compaction: Data is written to the Hudi table. For Merge-On-Read tables, compaction runs inline or asynchronously to merge log files with base files.
-
Metadata Sync: Finally, if enabled, metadata is synced to ensure catalog consistency.
Custom Solutions
The Zupee team developed several custom solutions to enhance their Hudi Streamer pipeline:
- Dynamic Schema Generator: A custom class that dynamically generates schemas for JSON sources, enabling automatic schema creation based on incoming data.
- Post-Process Transformations: Custom transformations to handle schema evolution at the source level.
- Centralized Configurations: Hudi configurations managed centrally via YAML files or
hoodie-config.xml, simplifying maintenance and updates. - Raw Data Handling: For raw data ingestion, they discovered that Hudi Streamer can infer schemas automatically without requiring a schema provider.
Results: Cost Savings and Performance Gains
The migration to a Hudi-powered platform delivered significant outcomes:
60% Reduction in S3 Network Costs
After migrating from Hudi 0.10.x to 0.12.3 and enabling the Metadata Table, Zupee reduced S3 network costs by over 60%. The metadata table eliminates expensive S3 file listing operations by maintaining an internal index of all files. The key settings are hoodie.metadata.enable=true for Spark and hudi.metadata.listing-enabled=true for Athena.
15-Minute Ingestion SLA
The team achieved a 15-minute SLA for ingesting 2-5 million records using Merge-On-Read (MOR) tables with Hudi's indexing for efficient record lookups during upserts.
30% Storage Reduction
Switching from Snappy to ZSTD compression resulted in a 30% decrease in data size. While write times increased slightly, query performance improved significantly, and both storage and Athena costs decreased.
Small File Management
Async compaction handles the small file problem by consolidating smaller files into larger ones, configured via hoodie.parquet.small.file.limit and hoodie.parquet.max.file.size. The team also explored Parquet page-level indexing to reduce query costs by allowing engines to read only relevant pages from files.
Why Hudi Over Other Table Formats?
During the Q&A, Amarjeet explained why Zupee chose Hudi over other table formats. The team ran POCs with Delta Lake but found that for near-real-time ingestion, Hudi performs much better. Since Zupee primarily works with real-time data rather than batch workloads, this was the deciding factor.
The native Hudi Streamer utility also adds significant value with its built-in checkpoint management, compaction, and catalog syncing—features that would require additional work with other ingestion approaches.
Best Practices for EMR Upgrades
When asked about upgrading Hudi on EMR, Amarjeet shared their approach: instead of using the EMR-provided JARs, they use open-source JARs. This way, they can upgrade JARs using their multi-tenant framework, which controls which JAR goes to which job. They can also use different Spark versions for different jobs. For example, if they are currently running Hudi 0.12.3 and want to test version 0.14.1, they simply specify the JAR in their YAML file for that particular job.
Conclusion
Zupee's journey with Apache Hudi demonstrates how a modern data platform can solve real-world engineering challenges at scale. By moving from legacy architecture to a Hudi-powered lakehouse, they built a platform that is robust, scalable, and cost-effective.
The keys to their success were:
- Enabling Hudi's Metadata Table to eliminate file listing overhead
- Using Merge-On-Read tables with indexing for efficient upserts
- Building custom transformations for flexible schema evolution
- Centralizing configuration management for operational simplicity
Watch the full presentation on YouTube. Ready to optimize your own data platform? Get started with Hudi and explore Hudi Streamer for your ingestion needs.