Apache Hudi 1.1 Deep Dive: Optimizing Streaming Ingestion with Apache Flink

Apache Hudi 1.1 optimizes streaming ingestion with Apache Flink through three writer-side changes - a Flink-native record representation that avoids Kryo serialization during operator shuffles, a new write path that operates directly on Flink's RowData instead of converting records to Avro, and the elimination of record-level bytes copy when writing MOR log files - delivering about 3.5x the ingestion throughput of Hudi 1.0 in benchmarks. This post walks through each optimization and the benchmark results. If you are new to writing Hudi tables from Flink, start with the Flink quick start guide.
This blog was translated from the original blog in Chinese.
Background
With the rise of real-time data processing, streaming ingestion has become a critical use case for Apache Hudi. Apache Flink, a robust stream processing framework, has been seamlessly integrated with Hudi to support near-real-time data ingestion. While the Flink integration has already provided powerful and comprehensive capabilities—such as robust exactly-once guarantees backed by Flink's checkpointing mechanism, flexible write modes, and rich index management—as data volumes scale into petabytes, achieving optimal performance for streaming ingestion becomes a challenge, leading to backpressure and high resource costs for streaming jobs.
There are multiple factors that impact streaming ingestion performance, such as the network shuffle overhead between Flink operators, SerDe costs within Hudi writers, and GC issues caused by memory management of in-memory buffers. With Hudi 1.1, meticulous refactoring and optimization work has been conducted to solve these problems, significantly enhancing the performance and stability of streaming ingestion with Flink.
In the subsequent sections, several key performance optimizations are introduced, including:
- Optimized SerDe between Flink operators
- New performant Flink-native writers
- Eliminated bytes copy for MOR log file writing
Following that, performance benchmarks for streaming ingestion in Hudi 1.1 are presented to demonstrate the concrete improvements achieved.
Optimized SerDe Between Flink Operators
Before Hudi 1.1, Avro was the default internal record format in the Flink writing/reading path, which means the first step in the write pipeline was converting Flink RowData into Avro record payload, and then it was used to create Hudi internal HoodieRecord for the following processing.

Almost every Flink job has to exchange data between its operators, and when the operators are not chained together (located in the same JVM process), records need to be serialized to bytes first before being sent to the downstream operator through the network. The shuffle serialization alone can be quite costly if not executed efficiently, and thus, when you examine the profiler output of the job, you will likely see serialization among the top consumers of CPU cycles. Flink actually has an out-of-the-box serialization framework, and there are performant internal serializers for basic types, like primitive types and row type. However, for generic types, e.g., HoodieRecord, Flink will fall back to the default serializer based on Kryo, which exhibits poor serialization performance.
RFC-84 proposed an improvement on SerDe between operators in the Hudi write pipeline based on the extensible type system of Flink:
HoodieFlinkInternalRow: an object to replaceHoodieRecordduring data shuffle, which containsRowDataas the data field and some necessary metadata fields, e.g., record key, partition path, etc.HoodieFlinkInternalRowTypeInfo: a customized Flink type information forHoodieFlinkInternalRow.HoodieFlinkInternalRowSerializer: a customized and efficient FlinkTypeSerializerfor the SerDe ofHoodieFlinkInternalRow.

With the customized Flink-native data structure and the companion serializer, the average streaming ingestion throughput can be boosted by about 25%.
New Performant Flink-Native Writers
Historically, Hudi Flink writer used HoodieRecord<AvroPayload> with data serialized using Avro to represent incoming records. While this unified format worked across engines, it came at a performance cost:
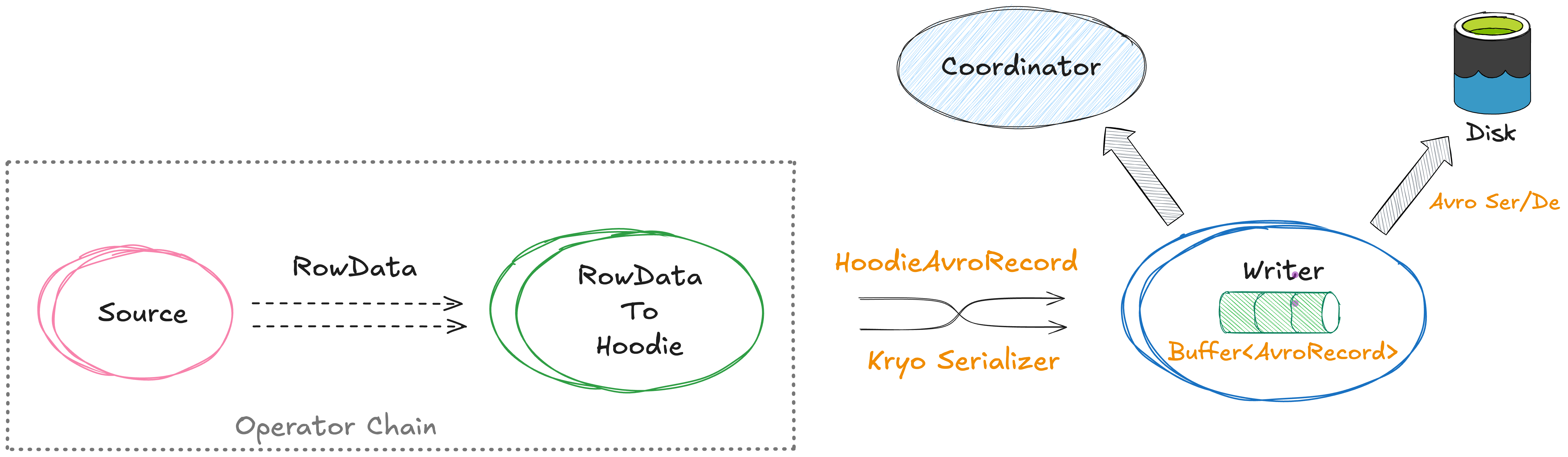
- Redundant SerDe: Take MOR table ingestion as an example. Flink reads records as
RowData, which are converted to AvroGenericRecordand then serialized to Avro bytes for internalHoodieAvroRecord. During the later log writing, the Avro bytes inHoodieAvroRecordare deserialized back into AvroIndexedRecordfor further processing before being appended to log files. Apparently, with Avro as the intermediate record representation, significant SerDe overhead is introduced. - Excess memory usage: The buffer in the writers is a Java List with intermediate Avro objects which will be released after being flushed to disk. These objects can increase heap usage and GC pressure, particularly under high-throughput streaming workloads.
RFC-87: A Flink-Native Write Path
RFC-87 proposes and implements a shift in data representation: instead of transforming RowData to GenericRecord, the Flink writer now directly wraps RowData inside a specialized HoodieRecord. The entire write path now operates around the RowData structure, eliminating all redundant conversion overhead. This change is Flink engine-specific and transparent to the overall Hudi writer lifecycle.
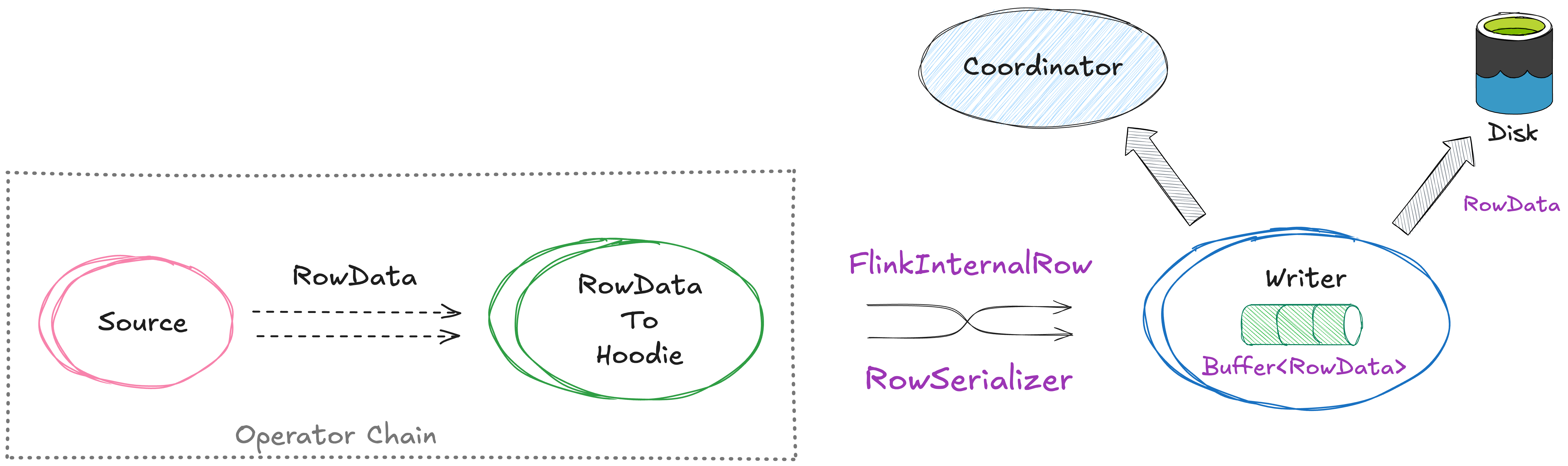
Key Changes:
- Customized HoodieRecord: Introduced
HoodieFlinkRecordto encapsulate Flink'sRowDatadirectly—no extra conversion to Avro record in the writing path anymore. - Self-managed binary buffer: Flink's internal
BinaryRowDatais in binary format. We've implemented a binary buffer to cache the bytes of theRowData. The memory is managed by the writer and can be reused after the previously cachedRowDatabytes are flushed to disk. With this self-managed binary buffer, GC pressure can be effectively reduced even under high-throughput workloads. - Flexible log formats: For MOR tables, records are written as data blocks in log files. We currently support two kinds of block types:
- Avro data block: Optimized for row-level writes, making it ideal for streaming ingestion or workloads with frequent updates and inserts. It's the default block type for log files.
- Parquet data block: Columnar and better suited for data with a high compression ratio, e.g., records with primitive type fields.
By leveraging the Flink-native data model, the redundant Avro conversions along with SerDe overhead are eliminated in the streaming ingestion pipeline, which brings significant improvements in both write latency and resource consumption.
Eliminate Bytes Copy for MOR Log File Writing
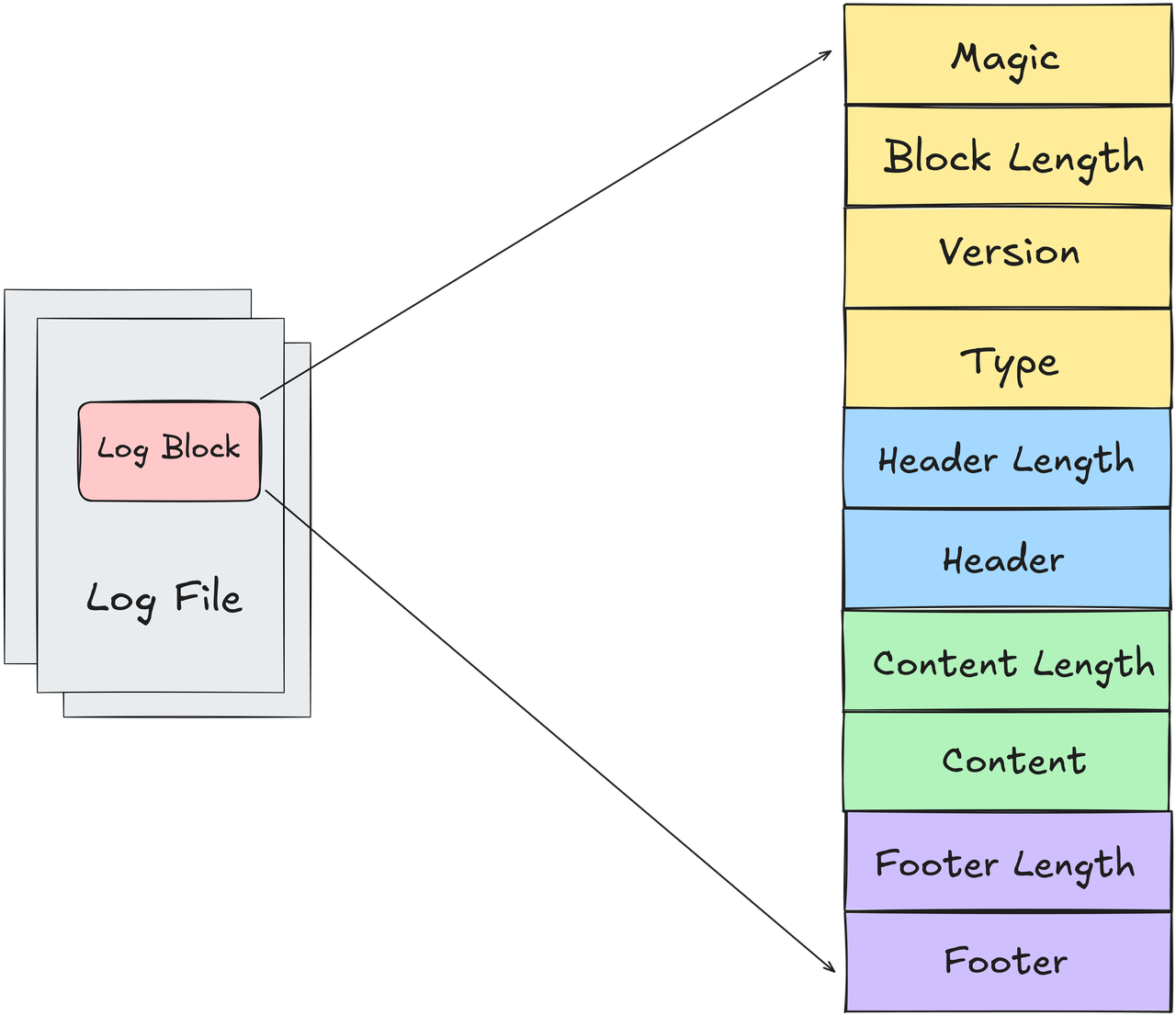
The log file of a MOR table is composed of data blocks. When writing a log file, the basic unit is the data block. The main contents of each block are shown in the figure below, where the Content is binary bytes generated by serializing the records in the buffer into the specified block format.
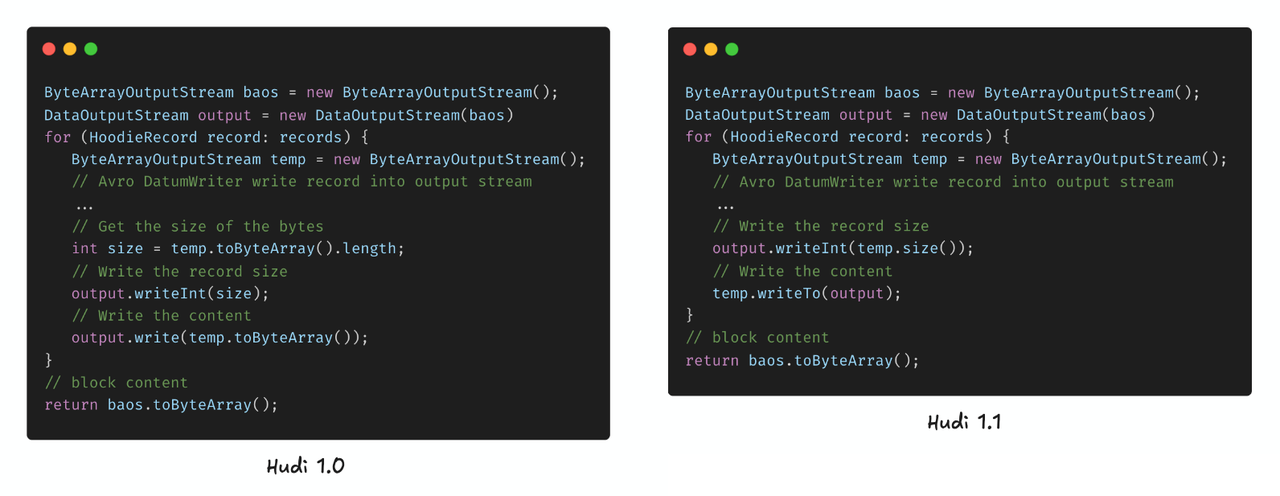
As mentioned in the previous section, the default data block format is Avro. In Hudi 1.1, the serialization of this block type has been carefully optimized by eliminating record-level bytes copy. Specifically, before Hudi 1.1, each record was serialized by the Avro Writer into a ByteArrayOutputStream, then the toByteArray method was invoked to obtain the data bytes for writing into the outer output stream for the data block. However, under the hood, toByteArray involves the creation of a new byte array and bytes copy. Since the bytes copy happens at the record level, it generates a large number of temporary objects in high-throughput scenarios, which further increases GC pressure.
Improvement in Hudi 1.1
In Hudi 1.1, the writeTo method of ByteArrayOutputStream is utilized to directly write the underlying data bytes to the outer output stream for the block, thereby avoiding additional record-level bytes copy and effectively reducing GC pressure.
Benchmark
To demonstrate performance improvements in streaming ingestion with Flink, we performed comprehensive benchmark testing of Apache Hudi 1.1 vs. Apache Hudi 1.0 vs. Apache Paimon 1.0.1. Currently there is no standard test dataset for streaming read/write. Since it's important to run transparent and reproducible benchmarking, we decided to use the existing Cluster benchmark program of Apache Paimon inspired by Nexmark, as Paimon has previously claimed multi-fold better ingestion performance than Hudi in this benchmark, which is one of their key selling points.
Cluster Environment
The benchmarks were run on an Alibaba Cloud EMR cluster, with the following settings:
- EMR on ECS: version 5.18.1
- Master (x1): 8 vCPU, 32 GiB, 5 Gbps
- Worker (x4): 24 vCPU, 96 GiB, 12 Gbps
- Apache Hudi version: 1.1 and 1.0.1
- Apache Paimon version: 1.0.1
- Apache Flink version: 1.17.2
- HDFS version: 3.2.1
Streaming Ingestion Scenario
The testing scenario is the most common streaming ingestion case in production: MOR table with UPSERT operation and Bucket index. We used the Paimon Benchmark program to simulate the workloads, where the data source was generated by the Flink DataGen connector, which produces records with primary keys ranging from 0 to 100,000,000, and the total record number is 500 million. For more detailed settings, refer to this repository.
Note that we disabled compaction in the test ingestion jobs, since it can significantly impact the performance of the ingestion job for both Hudi and Paimon and interfere with a fair comparison of ingestion performance. In fact, this is also common practice in production.
Additionally, the schema of a table also has a significant impact on write performance. There is a noticeable difference in the processing overhead between numeric primitive type fields and string type fields. Therefore, besides the default table schema (Schema1) used in the Paimon Benchmark program, we also added 3 different schemas containing mostly STRING-type fields, which are much more common in production scenarios.
| Schema1 | Schema2 | Schema3 | Schema4 |
|---|---|---|---|
| 1 String + 10 BIGINT fields | 20 String fields | 50 String fields | 100 String fields |
Benchmark Results
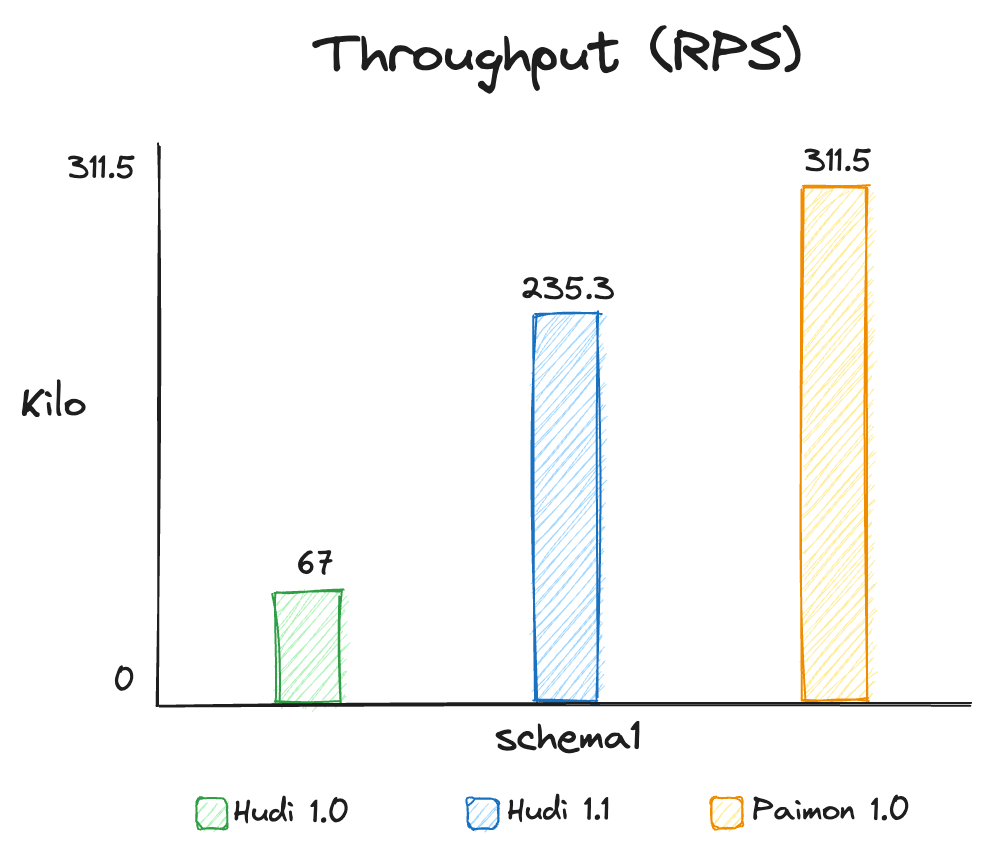
- For Schema1 with almost all fields being numeric type, the streaming ingestion performance of Hudi 1.1 is about 3.5 times that of Hudi 1.0. The performance gain mainly comes from the optimizations introduced in RFC-84 and RFC-87, which reduce the shuffle SerDe overhead in the ingestion pipeline and internal Avro SerDe costs in the writer.
- Streaming ingestion throughput of Paimon is slightly higher than that of Hudi 1.1. Through detailed profiling and analysis, we found that this performance gap mainly stems from the fact that each
HoodieRecordcontains 5 extra String-type metadata fields by default, and in simple schema scenarios like Schema1, these record-level additional fields have a significant performance impact.
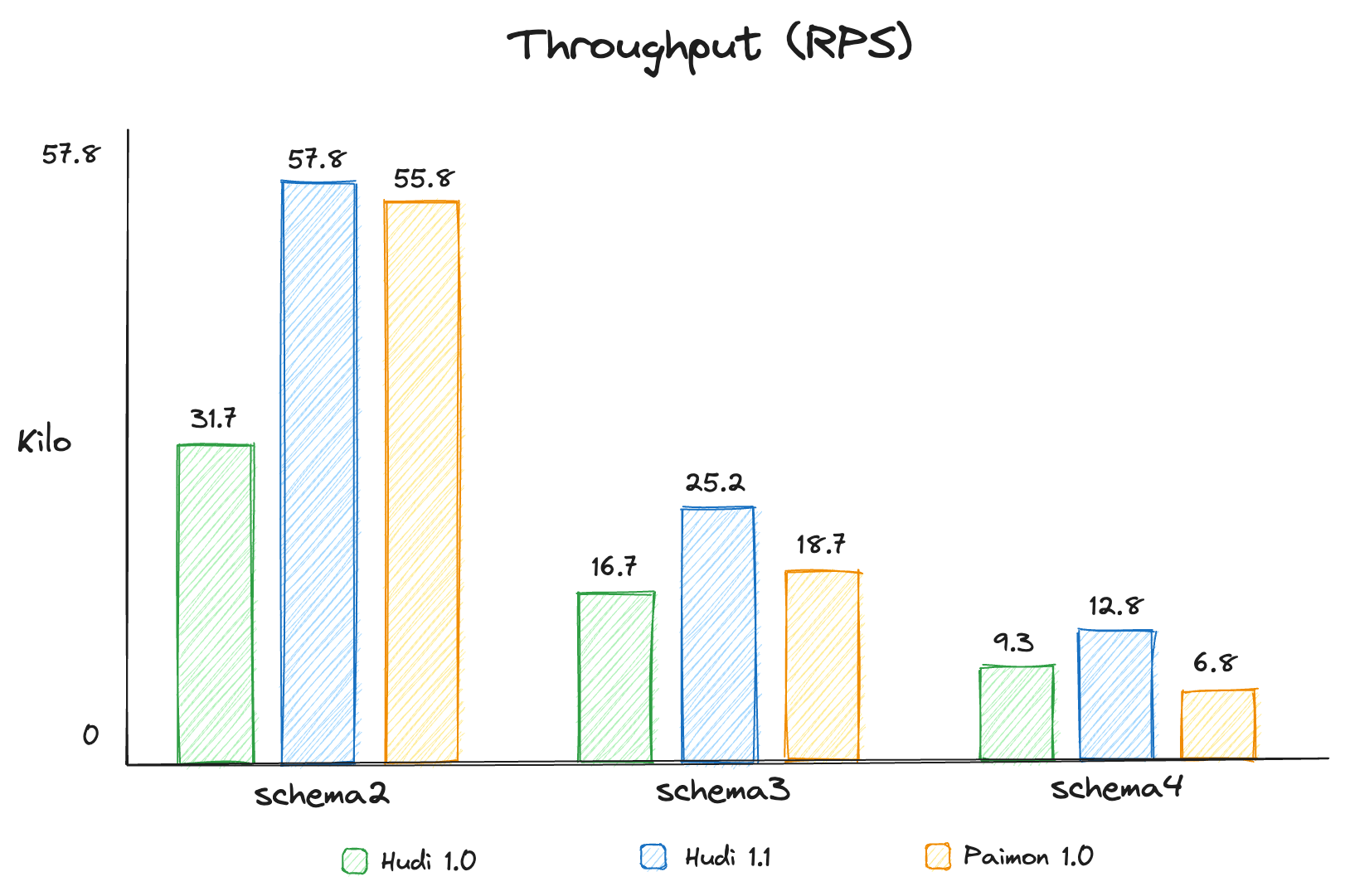
- For schemas where most fields are of STRING type, Hudi 1.1 achieves the best streaming ingestion performance. Based on the profiling analysis, we found that when the data fields are all strings, Paimon's approach of directly writing to Parquet files incurs noticeable compression overhead, which negatively impacts throughput—even though the benchmark tests used SNAPPY, the fastest available compression codec. Hudi, on the other hand, writes incremental data in row-based Avro format to log files. While its compression ratio is lower, this approach is more favorable for ingestion throughput across a variety of workloads.
Summary
The optimizations in Hudi 1.1 around writer performance for Flink have brought significant, multi-fold improvements to streaming ingestion throughput. These enhancements are transparent and backward-compatible, allowing users to seamlessly upgrade their jobs from earlier Hudi versions to the latest version and enjoy the substantial performance gains without any additional operational overhead.
FAQ
How much faster is Flink streaming ingestion in Hudi 1.1 compared to Hudi 1.0?
In benchmarks on a merge-on-read table with UPSERT operation and bucket index, Hudi 1.1 achieved about 3.5 times the streaming ingestion throughput of Hudi 1.0 on a numeric-heavy schema. The optimized shuffle SerDe alone (RFC-84) boosts average throughput by about 25%.
Why was Avro a bottleneck in the older Flink write path?
Before Hudi 1.1, Flink RowData was converted to Avro records and serialized to Avro bytes, then deserialized again during log writing - redundant SerDe overhead at every step. The in-memory buffer of intermediate Avro objects also increased heap usage and GC pressure, and shuffles of the generic HoodieRecord type fell back to Flink's Kryo serializer, which is slow.
What is the Flink-native write path introduced in Hudi 1.1?
RFC-87 makes the Flink writer wrap RowData directly inside a specialized HoodieFlinkRecord instead of converting it to an Avro record, so the entire write path operates on RowData. It adds a self-managed, reusable binary buffer that reduces GC pressure under high-throughput workloads, and supports both Avro (default, row-oriented) and Parquet (columnar) data blocks for MOR log files.
How does Hudi 1.1 compare with Apache Paimon for streaming ingestion?
On the numeric-heavy Schema1 from the Paimon cluster benchmark, Paimon's throughput was slightly higher than Hudi 1.1, mainly because each HoodieRecord carries 5 extra String-type metadata fields by default. On string-heavy schemas, which are more common in production, Hudi 1.1 achieved the best throughput, since writing row-based Avro log files avoids the Parquet compression overhead Paimon incurs at write time.
Do I need to change my Flink jobs to get these improvements?
No. The optimizations are transparent and backward-compatible, so existing jobs can upgrade from earlier Hudi versions and get the performance gains without additional operational overhead.