Apache Hudi 1.1 is Here—Building the Foundation for the Next Generation of Lakehouse

The Hudi community is excited to announce the release of Hudi 1.1, a major milestone that sets the stage for the next generation of data lakehouse capabilities. This release represents months of focused engineering on foundational improvements, engine-specific optimizations, and key architectural enhancements, laying the foundation for ambitious features coming in future releases.
Hudi continues to evolve rapidly, with contributions from a vibrant community of developers and users. The 1.1 release brings over 800 commits addressing performance bottlenecks, expanding engine support, and introducing new capabilities that make Hudi tables more reliable, faster, and easier to operate. Let’s dive into the highlights.
Pluggable Table Format—The Foundation for Multi-Format Support
Hudi 1.1 introduces a pluggable table format framework that opens up the powerful storage engine capabilities beyond Hudi’s native storage format to other table formats like Apache Iceberg and Delta Lake. This framework represents a fundamental shift in how Hudi approaches table format support, enabling native integration of multiple formats and giving you a unified system with total read-write compatibility across formats.
Vision and Design
The table format landscape in the modern lakehouse ecosystem is diverse and evolving. Like a game of rock-paper-scissors, different formats—Hudi, Iceberg, Delta Lake—each have unique strengths for specific use cases. Rather than forcing a one-size-fits-all approach, Hudi 1.1 introduces a pluggable table format framework that embraces the open lakehouse ecosystem and prevents vendor lock-in.
The framework is built on a clean abstraction layer that decouples Hudi’s core capabilities—transaction management, indexing, concurrency control, and table services—from the specific storage format used for data files. At the heart of this design is the HoodieTableFormat interface, which different format implementations can extend.
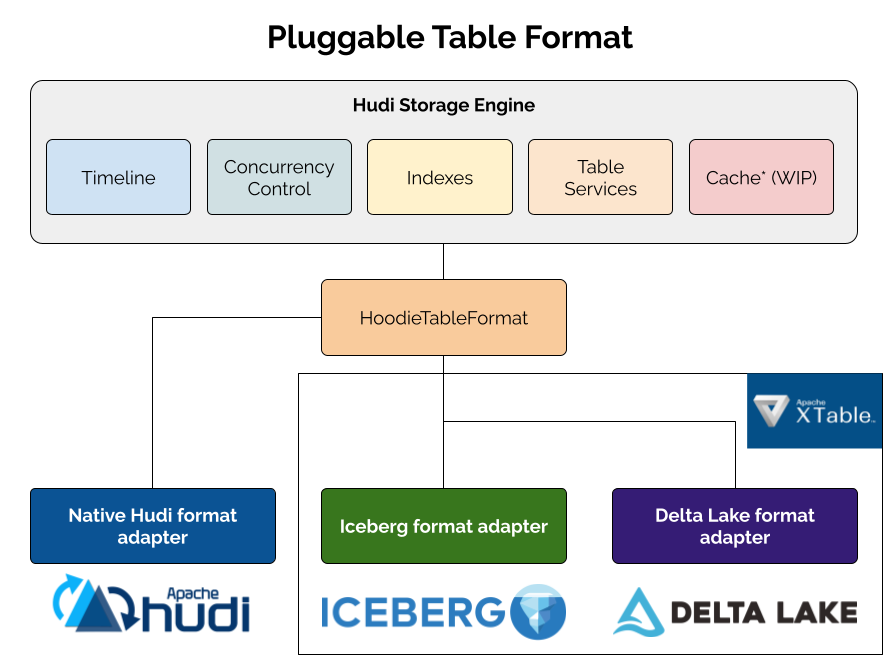
Key Architectural Components
- Storage engine: Hudi’s storage engine capabilities, such as timeline management, concurrency control mechanisms, indexes, and table services, can work across multiple table formats
- Pluggable adapters: Format-specific implementations handle the generation of conforming metadata upon writes
Hudi’s artifact provides support for the native Hudi format, while Apache XTable (incubating) supplies pluggable format adapters. For example, this XTable PR implements the Iceberg adapter to allow you to add dependencies to your running pipelines as needed. This architecture enables organizations to choose the right format for each use case while maintaining a unified operational experience and leveraging Hudi’s sophisticated storage engine across all of them.
In the 1.1 release, the framework comes with native Hudi format support (configured via hoodie.table.format=native by default). Existing users don't need to change anything—tables continue to work exactly as before. The real excitement lies ahead: the framework paves the way for supporting additional formats like Iceberg and Delta Lake. Imagine writing high-frequency updates to a Hudi table efficiently with Hudi's record-level indexing capability while maintaining Iceberg metadata through the Iceberg adapter, which supports a wide range of catalogs for reads. The pluggable table format framework in 1.1 makes such usage patterns possible—a game-changer for organizations that need flexibility and openness in their data architecture.
Indexing Improvements—Faster and Smarter Lookups
Hudi’s indexing subsystem is one of its most powerful features, enabling fast record lookups during writes and efficient data skipping during reads.
Partitioned Record Index
Since version 0.14.0, Hudi has supported a global record index in the indexing subsystem—a breakthrough that enables blazing-fast lookups on large datasets. While this is ideal for globally unique identifiers like order IDs or SSNs, many scenarios only require uniqueness within a partition—for example, user events partitioned by date. Hudi 1.1 introduces the partitioned record index, a non-global variant of the record index that works with the combination of partition path and record key, leveraging partition information to prune irrelevant partitions during lookups and dramatically reducing the search space, and thus achieving efficient lookups even on very large datasets.
-- Spark SQL: Create table with partitioned record index
CREATE TABLE user_activity (
user_id STRING,
activity_type STRING,
timestamp BIGINT,
event_date DATE
) USING hudi
TBLPROPERTIES (
'primaryKey' = 'user_id',
'preCombineField' = 'timestamp',
-- Enable partitioned record index
'hoodie.metadata.record.level.index.enable' = 'true',
'hoodie.index.type' = 'RECORD_LEVEL_INDEX'
)
PARTITIONED BY (event_date);
The partitioned record index enables index lookups that scale proportionally with partition size—file group accesses correlate directly to the data partition size, optimizing performance across heterogeneous data distributions. The design also supports future clustering operations that can dynamically expand file groups within partitions as they grow.
Partition-level Bucket Index
The bucket index is a popular choice for high-throughput write workloads because it eliminates expensive record lookups by deterministically mapping keys to file groups. However, the existing bucket index has a key limitation: once you set the number of buckets, changing it requires rewriting the entire table.
The 1.1 release introduces partition-level bucket index, which enables different bucket counts for different partitions using regex-based rules. This design allows tables to adapt as data volumes change over time—for example, older, smaller partitions can use fewer buckets while newer, larger partitions can have more.
-- Spark SQL: Create table with partition-level bucket index
CREATE TABLE sales_transactions (
transaction_id BIGINT,
user_id BIGINT,
amount DOUBLE,
transaction_date DATE
) USING hudi
TBLPROPERTIES (
'primaryKey' = 'transaction_id',
-- Partition-level bucket index
'hoodie.index.type' = 'BUCKET',
'hoodie.bucket.index.hash.field' = 'transaction_id',
'hoodie.bucket.index.partition.rule.type' = 'regex',
'hoodie.bucket.index.partition.expressions' = '2023-.*,16;2024-.*,32;2025-.*,64',
'hoodie.bucket.index.num.buckets' = '8'
)
PARTITIONED BY (transaction_date);
The partition-level bucket index is ideal for time-series data where partition sizes vary significantly over time. The adaptive bucket sizing helps you maintain optimal write performance as your data volume changes. See the docs and RFC 89 for more information.
Indexing Performance Optimizations
Beyond new indexes, Hudi 1.1 delivers substantial performance improvements for metadata table operations:
- HFile block cache and prefetching: The new block cache stores recently accessed data blocks in memory, avoiding repeated reads from storage. For smaller HFiles, Hudi prefetches the entire file upfront rather than making multiple read requests. Benchmarks show approximately 4x speedup for repeated lookups, enabled by default.
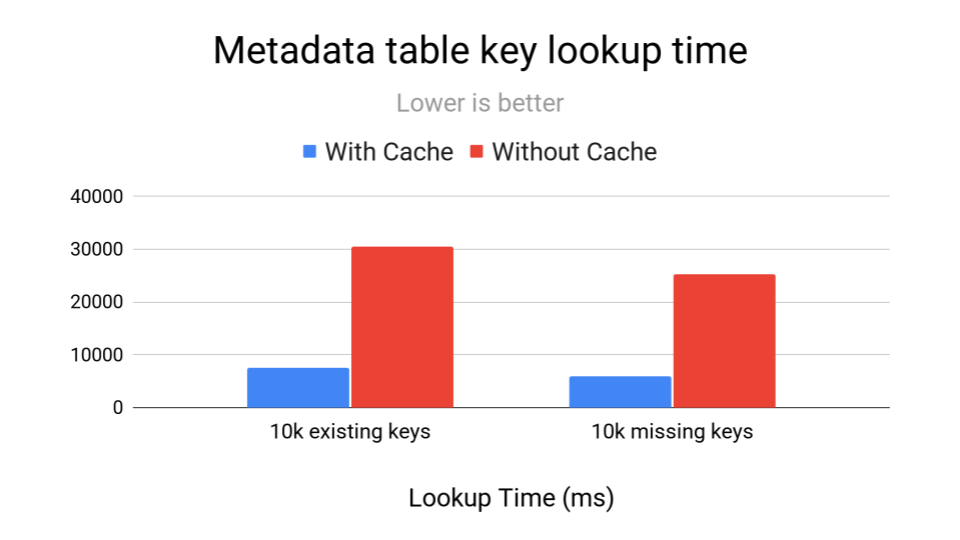
- HFile Bloom filter: Adding Bloom filters to HFiles enables Hudi to quickly determine whether a key might exist in a file before fetching data blocks, avoiding unnecessary I/O and dramatically speeding up point lookups. You can enable it with
hoodie.metadata.bloom.filter.enable=true.
These optimizations compound to make the metadata table significantly faster, directly improving both write and read performance across your Hudi tables. Additionally, Hudi 1.1 adds its own native HFile writer implementation, eliminating the dependency on HBase libraries. This refactoring significantly reduces the Hudi bundle size and provides the foundation for future HFile performance optimizations.
Faster Clustering with Parquet File Binary Copy
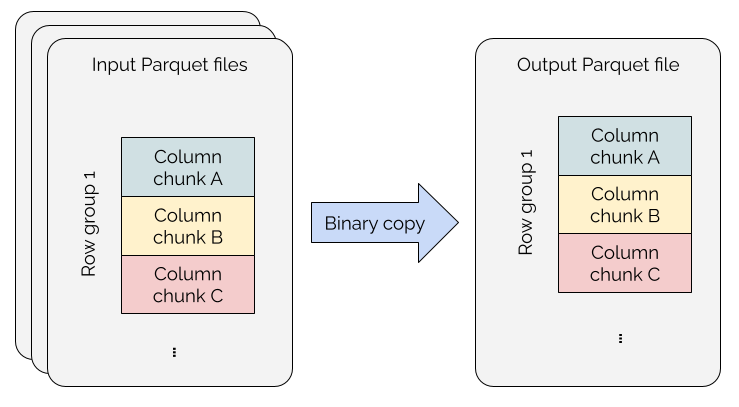
Clustering reorganizes data to improve query performance, but traditional approaches are expensive—decompressing, decoding, transforming, re-encoding, and re-compressing data even when no transformation is needed.
Hudi 1.1 implements Parquet file binary copy for clustering operations. Instead of processing records, this optimization directly copies Parquet RowGroups from source to destination files when schema-compatible, eliminating redundant transformations entirely.
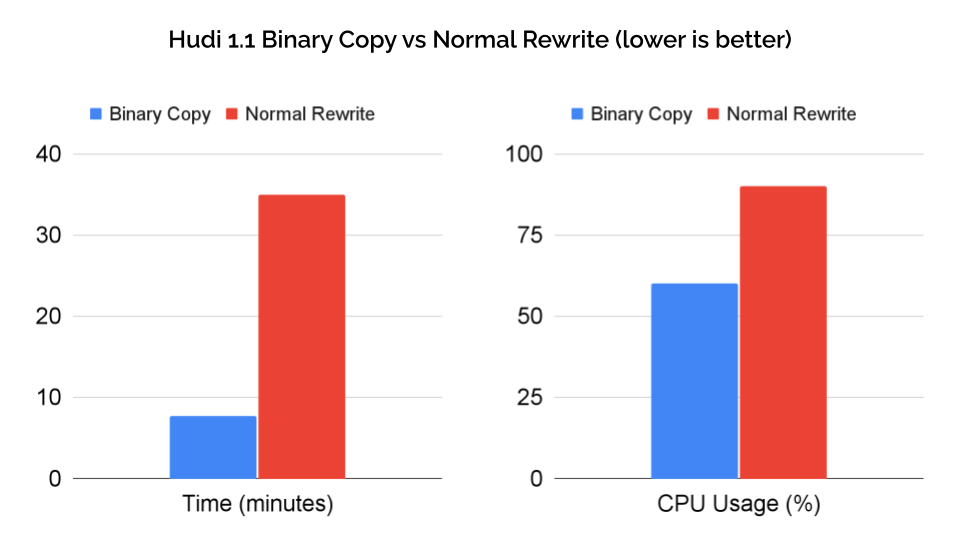
On 100GB test data, using Parquet file binary copy achieved 15x faster execution (18 minutes → 1.2 minutes) and 95% reduction in compute (28.7 task-hours → 1.3 task-hours) compared to the normal rewriting of Parquet files. Real-world validation with 1.7TB datasets (300 columns) showed approximately 5x performance improvement (35 min → 7.7 min) with CPU usage dropping from 90% to 60%.
The optimization is currently supported for Copy-on-Write tables and enabled automatically when safe, with Hudi intelligently falling back to traditional clustering when schema reconciliation is required. You may refer to this PR for more detail.
Storage-Based Lock Provider—Eliminating External Dependencies for Concurrent Writers
Multi-writer concurrency is critical for production data lakehouses, where multiple jobs need to write to the same table simultaneously. Historically, enabling multi-writer support in Hudi required setting up external lock providers like AWS DynamoDB, Apache Zookeeper, or Hive Metastore. While these work well, they add operational complexity—you need to provision, maintain, and monitor additional infrastructure.
Hudi 1.1 introduces a storage-based lock provider that eliminates this dependency entirely by managing concurrency directly using the .hoodie/ directory in your table's storage layer.
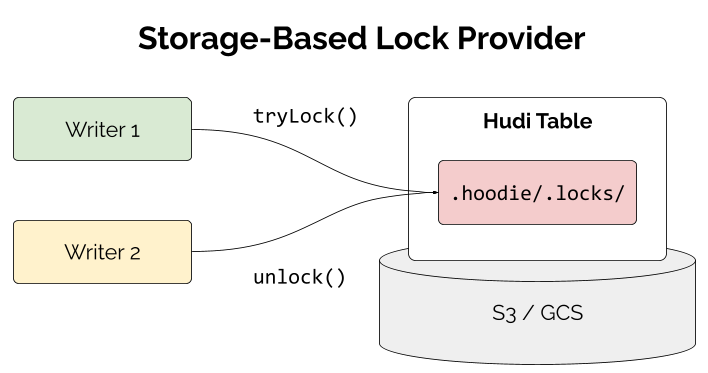
The implementation uses conditional writes on a single lock file under .hoodie/.locks/ to ensure only one writer holds the lock at a time, with heartbeat-based renewal and automatic expiration for fault tolerance. To use the storage-based lock provider, you need to add the corresponding Hudi cloud bundle (hudi-aws-bundle for S3 and hudi-gcp-bundle for GCS) and set the following configuration:
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.StorageBasedLockProvider
This approach eliminates the need for DynamoDB, ZooKeeper, or Hive Metastore dependencies, reducing operational costs and infrastructure complexity. The cloud-native design works directly with S3 or GCS storage features, with support for additional storage systems planned, making Hudi easier to operate at scale in cloud-native environments. Check out the docs and RFC 91 for more detail.
Use Merge Modes and Custom Mergers—Say Goodbye to Payload Classes
A core design principle of Hudi is enabling the storage layer to understand how to merge updates to the same record key, even when changes arrive out of order—a common scenario with mobile apps, IoT devices, and distributed systems. Prior to Hudi 1.1, record merging logic was primarily implemented through payload classes, which were fragmented and lacked standardized semantics.
Hudi 1.1 deprecates payload classes and encourages users to adopt the new APIs introduced since 1.0 for record merging: merge modes and the HoodieRecordMerger interface.
Merge Modes—Declarative Record Merging
For common use cases, the COMMIT_TIME_ORDERING and EVENT_TIME_ORDERING merge modes provide a declarative way to specify merge behavior:
| Merge mode | What does it do? |
|---|---|
COMMIT_TIME_ORDERING | Picks the record with the highest completion time/instant as the final merge result (standard relational semantics or arrival time processing) |
EVENT_TIME_ORDERING | Picks the record with the highest value on a user-specified ordering field as the final merge result. Enables event time processing semantics for handling late-arriving data without corrupting record state. |
The default behavior is adaptive: if no ordering field (hoodie.table.ordering.fields) is configured, Hudi defaults to COMMIT_TIME_ORDERING; if one or more ordering fields are set, it uses EVENT_TIME_ORDERING. This makes Hudi work out-of-the-box for simple use cases while still supporting event-time ordering when needed.
Custom Mergers—The Flexible Approach
For complex merging logic—such as field-level reconciliation, aggregating counters, or preserving audit fields—the HoodieRecordMerger interface provides a modern, engine-native alternative to payload classes. You need to set the merge mode to CUSTOM and provide your own implementation of HoodieRecordMerger. By using the new API, you can achieve consistent merging across all code paths: precombine, updating writes, compaction, and snapshot reads—you are strongly encouraged to migrate to the new APIs. See the docs for more details. For migration guidance, see the release notes and RFC-97.
Apache Spark Integration Improvements
Spark remains one of the most popular engines for working with Hudi tables, and the 1.1 release brings several important enhancements.
Spark 4.0 Support
Spark 4.0 brought significant performance gains for ML/AI workloads, smarter query optimization with automatic join strategy switching, dynamic partition skew mitigation, and enhanced streaming capabilities. Hudi 1.1 adds Spark 4.0 support to unlock these improvements for working with Hudi tables. To get started, use the new hudi-spark4.0-bundle_2.13:1.1.1 artifact in your dependency list.
Metadata Table Streaming Writes
Hudi 1.1 introduces streaming writes to the metadata table, unifying data and metadata writes into a single RDD execution chain. The key design generates metadata records directly during data writes in parallel across executors, eliminating redundant file lookups that previously created bottlenecks and enhancing reliability when performing stage retries in Spark.
A benchmark with update-intensive workloads showed that this 1.1 feature delivered about 18% faster write times for tables with record index, compared to Hudi 1.0. The feature is enabled by default for Spark writers.
New and Enhanced SQL Procedures
Hudi 1.1 expands the SQL procedure library with useful additions and enhanced capabilities for table management and observability, bringing operational capabilities directly into Spark SQL.
The new procedures, show_cleans, show_clean_plans, and show_cleans_metadata, provide visibility into cleaning operations:
CALL show_cleans(table => 'hudi_table', limit => 10);
CALL show_clean_plans(table => 'hudi_table', limit => 10);
CALL show_cleans_metadata(table => 'hudi_table', limit => 10);
The enhanced run_clustering procedure supports partition filtering with regex patterns:
-- Cluster all 2025 partitions matching a pattern
CALL run_clustering(
table => 'hudi_table',
partition_regex_pattern => '2025-.*',
);
All show procedures, where applicable, were enhanced with path and filter parameters. path helps when table_name is not able to identify a table properly. filter can support advanced predicate expressions. For example:
-- Find large files in recent partitions
CALL show_file_status(
path => '/data/warehouse/transactions',
filter => "partition LIKE '2025-11%' AND file_size > 524288000"
);
The new and enhanced SQL procedures bring table management directly into Spark SQL, streamlining operations for SQL-focused workflows.
Apache Flink Integration Improvements
Flink is a popular choice for real-time data pipelines, and Hudi 1.1 brings substantial improvements to the Flink integration.
Flink 2.0 Support
Hudi 1.1 brings support for Flink 2.0, the first major Flink release in nine years. Flink 2.0 introduced disaggregated state storage (ForSt) that decouples state from compute for unlimited scalability, asynchronous state execution for improved resource utilization, adaptive broadcast join for efficient query processing, and materialized tables for simplified stream-batch unification. Use the new hudi-flink2.0-bundle:1.1.1 artifact to get started.
Engine-Native Record Support
Hudi 1.1 eliminates expensive Avro conversions by processing Flink's native RowData format directly, enabling zero-copy operations throughout the pipeline. This automatic change (no configuration required) delivers 2-3x improvement in write and read performance on average compared to Hudi 1.0.
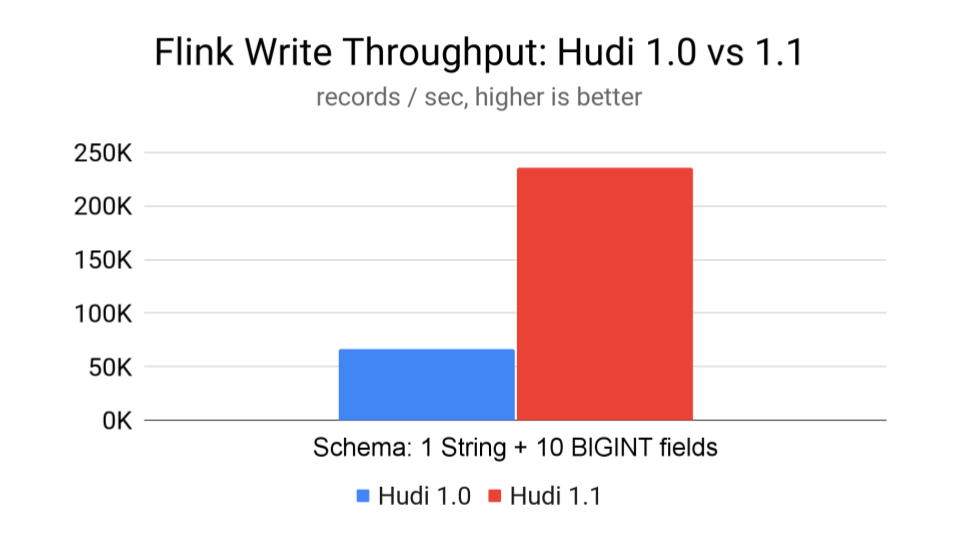
The above shows a benchmark that inserted 500 million records with a schema of 1 STRING and 10 BIGINT fields: Hudi 1.1 achieved 235.3k records per second and Hudi 1.0 67k records per second—over 3 times higher throughput.
Buffer Sort
For append-only tables, Hudi 1.1 introduces in-memory buffer sorting that pre-sorts records before flushing to Parquet. This delivers 15-30% better compression and faster queries through better min/max filtering. You can enable this feature with write.buffer.sort.enabled=true and specify sort keys via write.buffer.sort.keys (e.g., "timestamp,event_type"). You may also adjust the buffer size for sorting via write.buffer.size (default 1000 records).
New Integration: Apache Polaris (Incubating)
Polaris (incubating) is an open-source catalog for lakehouse platforms that provides multi-engine interoperability and unified governance across diverse table formats and query engines. Its key feature is enabling data teams to use multiple engines—Spark, Trino, Dremio, Flink, Presto—on a single copy of data with consistent metadata, governed openly by a diverse committee including Snowflake, AWS, Google Cloud, Azure, and others to prevent vendor lock-in.
Hudi 1.1 introduces native integration with Polaris (pending a Polaris release that includes this PR), allowing users to register Hudi tables in the Polaris catalog and query them from any Polaris-compatible engine, simplifying multi-engine workflows and providing centralized role-based access control that works uniformly across S3, Azure Blob Storage, and Google Cloud Storage.
What’s Next—Join Us in Building the Future
The future of Hudi is incredibly exciting, and we're building it together with a vibrant, global community of contributors. Building on the strong foundation of 1.1, we're actively developing transformative AI/ML-focused capabilities for Hudi 1.2 and beyond—unstructured data types and column groups for efficient storage of embeddings and documents, Lance, Vortex, blob-optimized Parquet support, and vector search capabilities for lakehouse tables. This is just the beginning—we're reimagining what's possible in the lakehouse, from multi-format interoperability to next-generation AI/ML workloads, and we need your ideas, code, and creativity to make it happen.
Join us in building the future. Check out the 1.1 release notes to get started, join our Slack space, follow us on LinkedIn and X (twitter), and subscribe (send an empty email) to the mailing list—let's build the next generation of Hudi together.