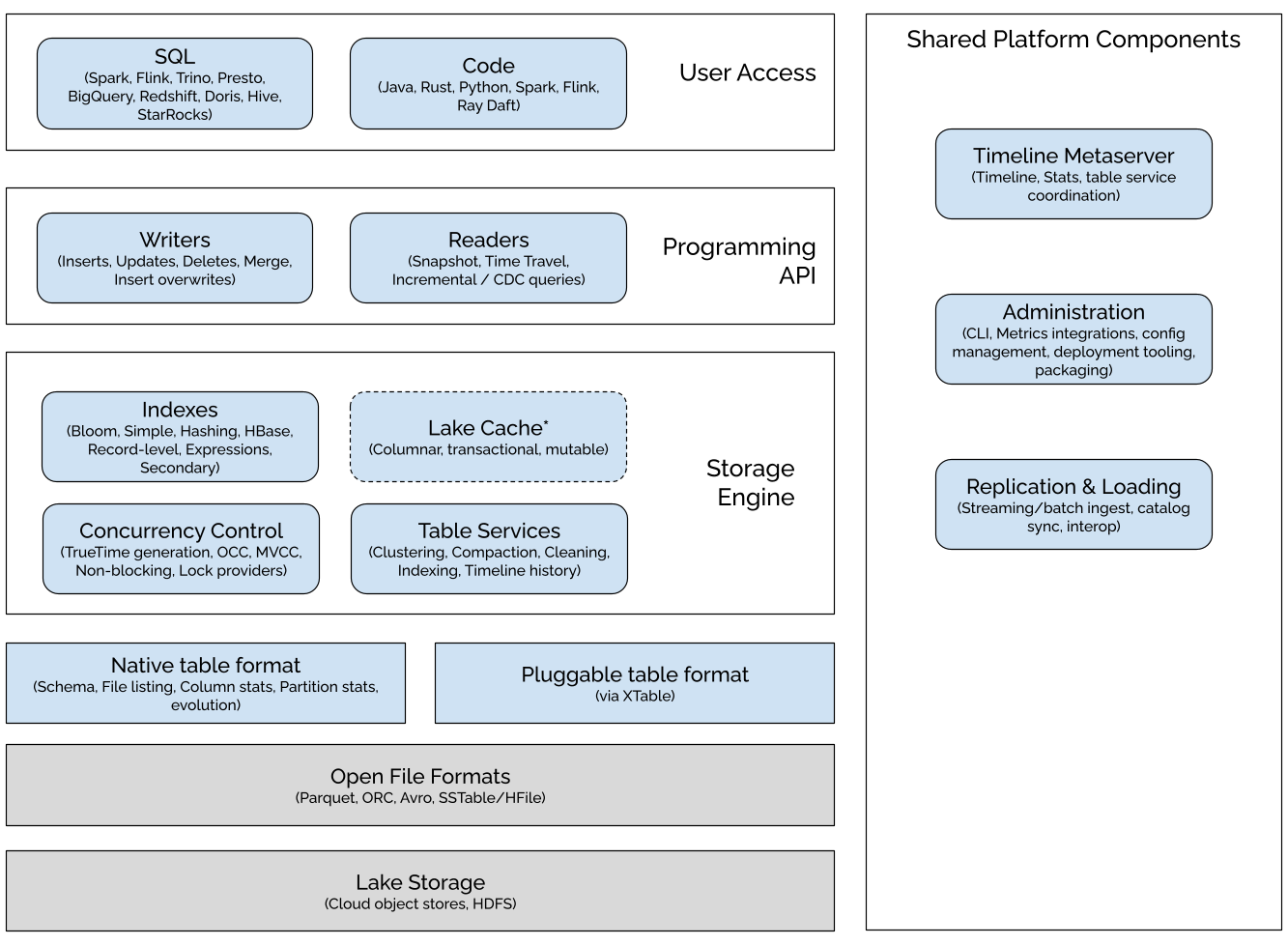
The Hudi Stack
Hudi adds core warehouse and database functionality directly to a data lake (more recently known as the data lakehouse architecture) elevating it from a collection of objects/files to well-managed tables. Hudi adds table abstraction over open file formats like Apache Parquet/ORC using a table format layer, that is optimized for frequent writes, large-scale queries on a table snapshot as well efficient incremental scans. To understand the Hudi stack, we can simply translate the components to the seminal paper on "Architecture of a Database System", with modernized names.
On top of this foundation, Hudi adds storage engine functionality found in many databases ("transactional storage manager" in the paper), enabling transactional capabilities such as concurrency control, indexing, change capture and updates/deletes. The storage engine also consists of essential table services to manage/maintain the tables, that are tightly integrated with the underlying storage layer and executed automatically by upper-layer writers or platform components like an independent table management service.
Hudi then defined clear read/write APIs that help interact with the tables, from a variety of SQL engines and code written in many programming languages using their popular data processing frameworks. Hudi also comes with several platform services that help tune performance, operate tables, monitor tables, ingest data, import/export data, and more.
The Hudi stack
Thus, when all things considered, the Hudi stack expands out of being just a 'table format' to a comprehensive and robust data lakehouse platform. In this section, we will explore the Hudi stack and deconstruct the layers of software components that constitute Hudi. The features marked with an asterisk (*) represent work in progress, and the dotted boxes indicate planned future work. These components collectively aim to fulfill the vision for the project.
Lake Storage
The storage layer is where the data files/objects (such as Parquet) as well as all table format metadata are stored. Hudi interacts with the storage layer through Cloud native and Hadoop FileSystem API, enabling compatibility with various systems including HDFS for fast appends, and various cloud stores such as Amazon S3, Google Cloud Storage (GCS), and Azure Blob Storage. Additionally, Hudi offers its own storage APIs that can rely on Hadoop-independent file system implementation to simplify the integration of various file systems. Hudi adds a custom wrapper filesystem that lays out the foundation for improved storage optimizations.
File Formats
File format structure in Hudi
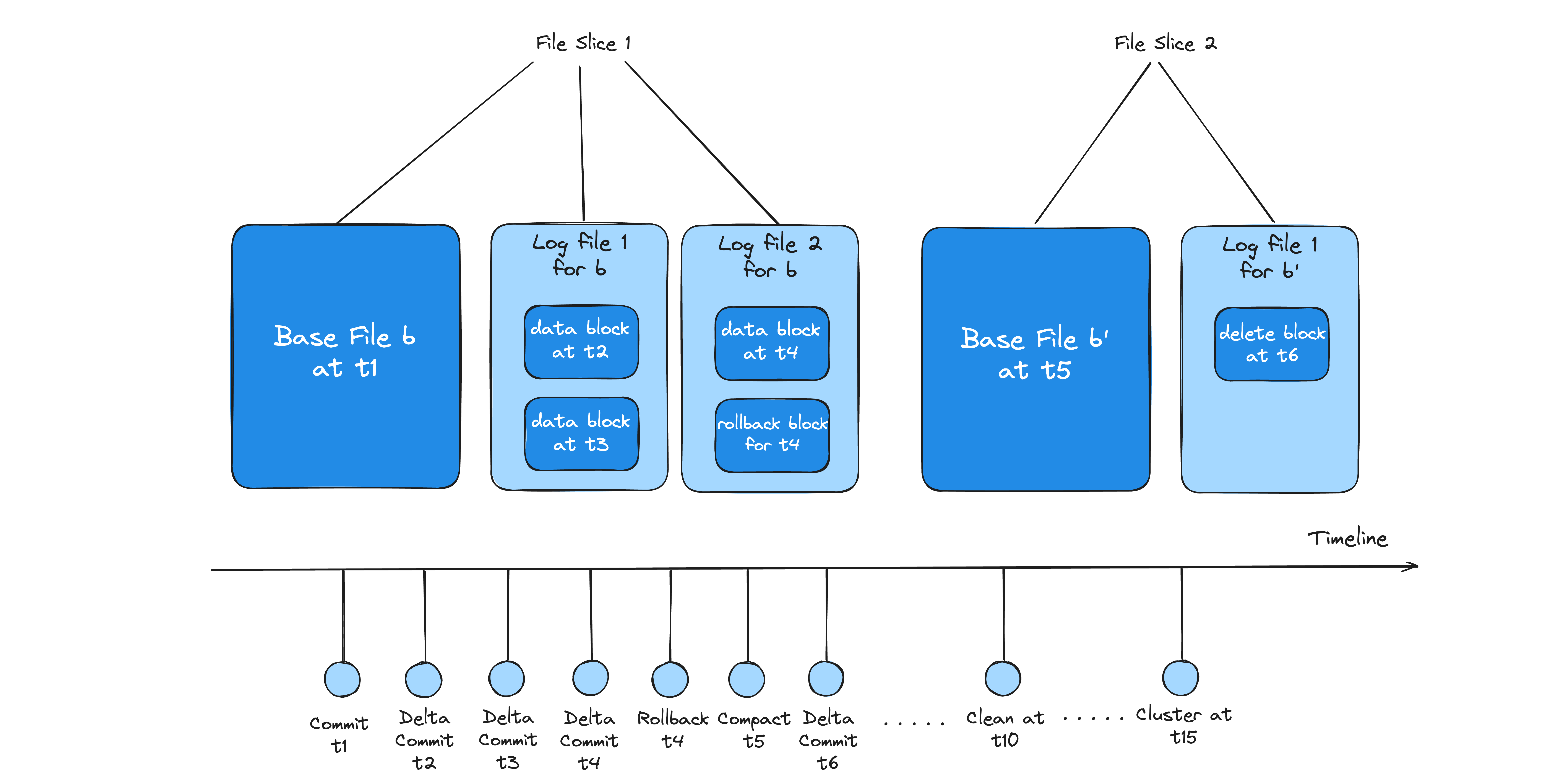
File formats hold the actual data and are physically stored on the lake storage. Hudi operates on logical structures of File Groups and File Slices, which consist of Base File and Log Files. Log files store updates/deletes/inserts on top of records stored in base files, and periodically log files are compacted into small set of log files (log compaction) or base files (compaction). Future updates aim to integrate diverse formats like unstructured data (e.g., JSON, images), and compatibility with different storage layers in event-streaming, OLAP engines, and warehouses. Hudi's layout scheme encodes all changes to a Log File as a sequence of blocks (data, delete, rollback). By making data available in open file formats (such as Parquet/Avro), Hudi enables users to bring any compute engine for specific workloads.
Native Table Format
Hudi's Native Table format
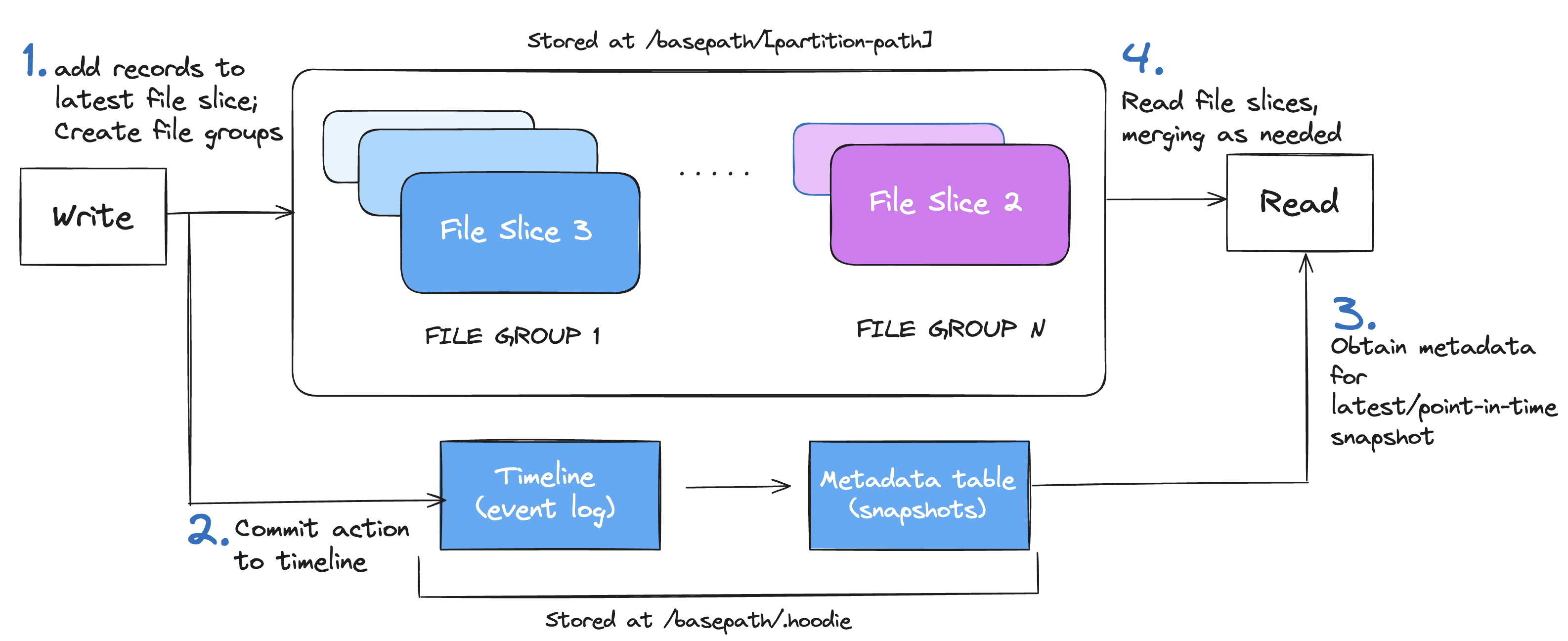
Drawing an analogy to file formats, a table format simply concerns with how files are distributed with the table, partitioning schemes, schema and metadata tracking changes. Hudi organizes files within a table or partition into File Groups. Updates are captured in log files tied to these File Groups, ensuring efficient merges. There are three major components related to Hudi’s table format.
-
Timeline : Hudi's timeline, stored in the
/.hoodie/timelinefolder, is a crucial event log recording all table actions in an ordered manner, with events kept for a specified period. Hudi uniquely designs each File Group as a self-contained log, enabling record state reconstruction through delta logs, even after archival of historical actions. This approach effectively limits metadata size based on table activity frequency, essential for managing tables with frequent updates. -
File Group and File Slice : Within each partition the data is physically stored as base and Log Files and organized into logical concepts as File groups and File Slices. File groups contain multiple versions of File Slices and are split into multiple File Slices. A File Slice comprises the Base and Log File. Each File Slice within the file-group is uniquely identified by the write that created its base file or the first log file, which helps order the File Slices.
-
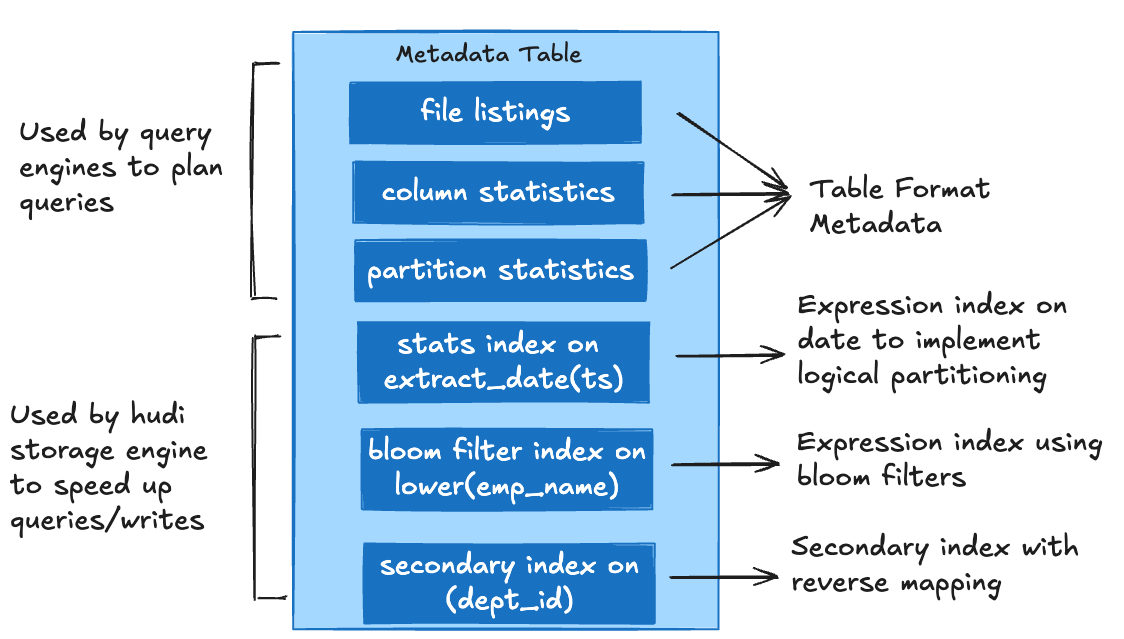
Metadata Table : Implemented as another merge-on-read Hudi table, the metadata table efficiently handles quick updates with low write amplification. It leverages a SSTable based file format for quick, indexed key lookups, storing vital information like file paths, column statistics and schema. This approach streamlines operations by reducing the necessity for expensive cloud file listings.
Hudi's approach of recording updates into Log Files is more efficient and involves low merge overhead than systems like Hive ACID, where merging all delta records against all Base Files is required. Read more about the various table types in Hudi table types documentation.
Pluggable Table format
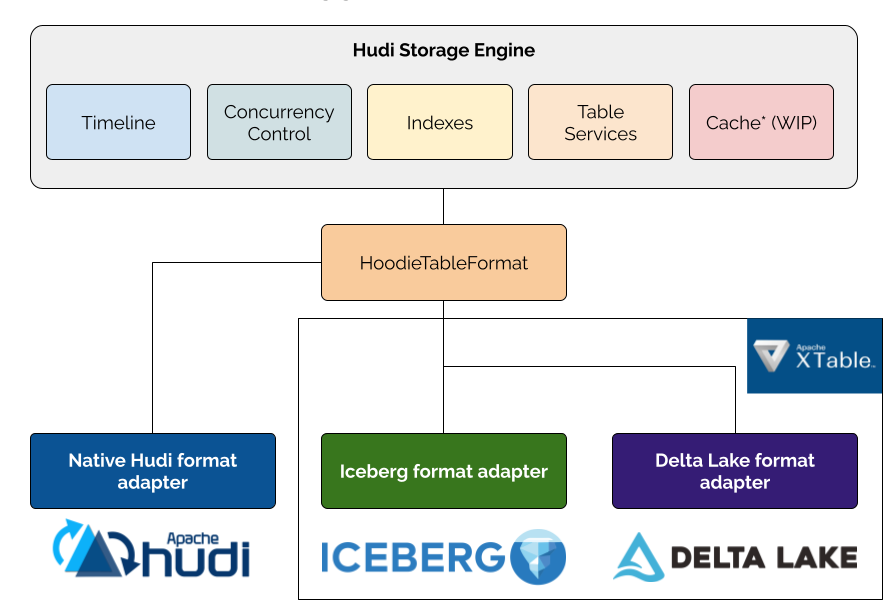
Starting with Hudi 1.1, Hudi introduces a pluggable table format framework that extends Hudi's powerful storage engine capabilities beyond its native format to other table formats like Apache Iceberg and Delta Lake. This framework decouples Hudi's core capabilities—transaction management, indexing, concurrency control, and table services—from the specific storage format used for data files.
Pluggable Table Format
Hudi provides native format support (configured via hoodie.table.format=native by default), while Apache XTable (incubating) supplies pluggable format adapters for formats like Iceberg and Delta Lake. The framework enables organizations to choose the right format for each use case while maintaining a unified operational experience and leveraging Hudi's sophisticated storage engine across all formats. For example, you can write high-frequency updates to a Hudi table efficiently with Hudi's record-level indexing capability while maintaining Iceberg metadata through the Iceberg adapter, which supports a wide range of catalogs for reads. This architecture prevents vendor lock-in and embraces the open lakehouse ecosystem.
Storage Engine
The storage layer of Hudi comprises the core components that are responsible for the fundamental operations and services that enable Hudi to store, retrieve, and manage data efficiently on data lakehouse storages. This functionality is comparable to that of roles play by storage engines in popular databases like PostgreSQL, MySQL, MongoDB, Cassandra and Clickhouse.
Indexes
Indexes in Hudi
Indexes in Hudi enhance query planning, minimizing I/O, speeding up response times and providing faster writes with low merge costs. The metadata table acts as an additional indexing system and brings the benefits of indexes generally to both the readers and writers. Compute engines can leverage various indexes in the metadata table, like file listings, column statistics, bloom filters, record-level indexes, and expression indexes to quickly generate optimized query plans and improve read performance. In addition to the metadata table indexes, Hudi supports simple join based indexing, bloom filters stored in base file footers, external key-value stores like HBase, and optimized storage techniques like bucketing , to efficiently locate File Groups containing specific record keys. Hudi also provides reader indexes such as expression and secondary indexes to boost reads. The table partitioning scheme in Hudi is consciously exploited for implementing global and non-global indexing strategies, that limit scope of a record's uniqueness to a given partition or globally across all partitions.
Table Services
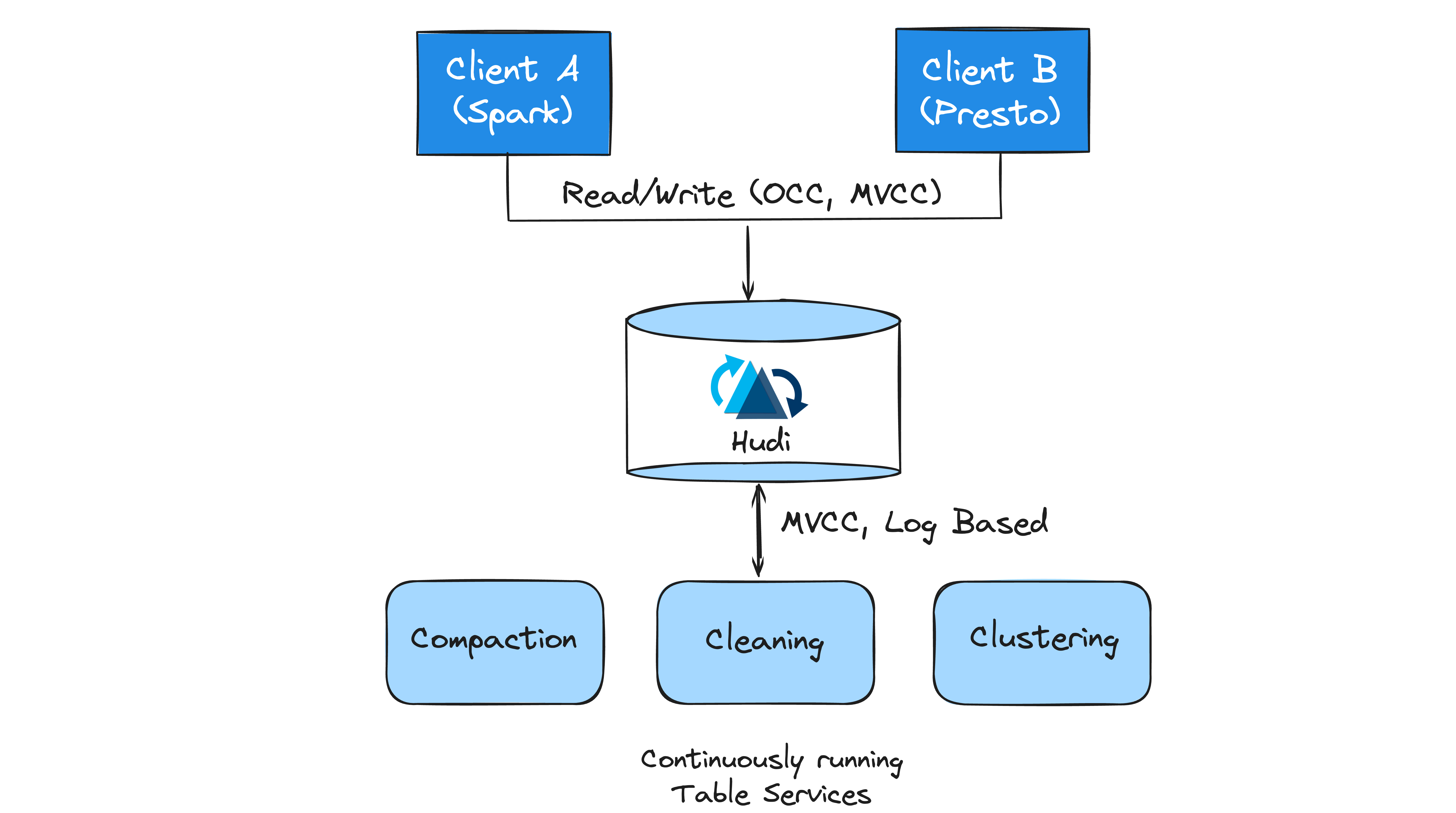
Table services in Hudi
Hudi offers various table services to help keep the table storage layout and metadata management performant. Hudi was designed with built-in table services that enables running them in inline, semi-asynchronous or full-asynchronous modes. Furthermore, Spark and Flink streaming writers can run in continuous mode, and invoke table services asynchronously sharing the underlying executors intelligently with writers. Let’s take a look at these services.
Clustering
The clustering service, akin to features in cloud data warehouses, allows users to group frequently queried records using sort keys or merge smaller Base Files into larger ones for optimal file size management. It's fully integrated with other timeline actions like cleaning and compaction, enabling smart optimizations such as avoiding compaction for File Groups undergoing clustering, thereby saving on I/O.
Compaction
Hudi's compaction service, featuring strategies like date partitioning and I/O bounding, merges Base Files with delta logs to create updated Base Files. It allows concurrent writes to the same File Froup, enabled by Hudi's file grouping and flexible log merging. This facilitates non-blocking execution of deletes even during concurrent record updates.
Cleaning
Cleaner service works off the timeline incrementally, removing File Slices that are past the configured retention period for incremental queries, while also allowing sufficient time for long running batch jobs (e.g Hive ETLs) to finish running. This allows users to reclaim storage space, thereby saving on costs.
Indexing
Hudi's scalable metadata table contains auxiliary data about the table. This subsystem encompasses various indices, including files, column_stats, and bloom_filters, facilitating efficient record location and data skipping. Balancing write throughput with index updates presents a fundamental challenge, as traditional indexing methods, like locking out writes during indexing, are impractical for large tables due to lengthy processing times. Hudi addresses this with its innovative asynchronous metadata indexing, enabling the creation of various indices without impeding writes. This approach not only improves write latency but also minimizes resource waste by reducing contention between writing and indexing activities.
Concurrency Control
Concurrency control defines how different writers/readers/table services coordinate access to the table. Hudi uses monotonically increasing time to sequence and order various changes to table state. Much like databases, Hudi take an approach of clearly differentiating between writers (responsible for upserts/deletes), table services (focusing on storage optimization and bookkeeping), and readers (for query execution). Hudi provides snapshot isolation, offering a consistent view of the table across these different operations. It employs lock-free, non-blocking MVCC for concurrency between writers and table-services, as well as between different table services, and optimistic concurrency control (OCC) for multi-writers with early conflict detection. With Hudi 1.0, non-blocking concurrency control (NBCC) is introduced, allowing multiple writers to concurrently operate on the table with non-blocking conflict resolution.
Lake Cache*
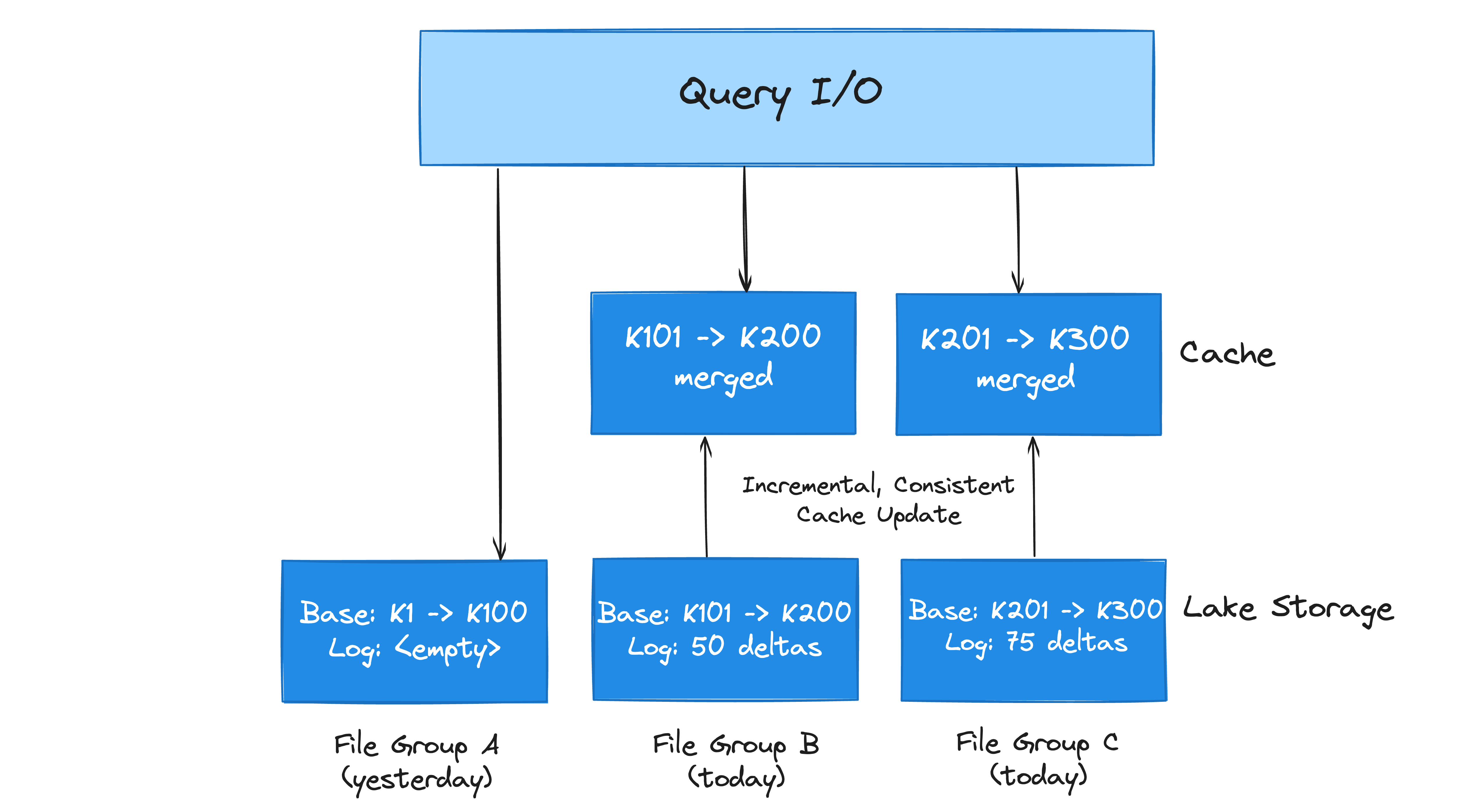
Proposed Lake Cache in Hudi
Data lakes today face a tradeoff between fast data writing and optimal query performance. Writing smaller files or logging deltas enhances writing speed, but superior query performance typically requires opening fewer files and pre-materializing merges. Most databases use a buffer pool to reduce storage access costs. Hudi’s design supports creating a multi-tenant caching tier that can store pre-merged File Slices. Hudi’s timeline can then be used to simply communicate caching policies. Traditionally, caching is near query engines or in-memory file systems. Integrating a caching layer with Hudi's transactional storage enables shared caching across query engines, supporting updates and deletions, and reducing costs. The goal is to build a buffer pool for lakes, compatible with all major engines, with the contributions from the rest of the community.
Programming APIs
Writers
Hudi tables can be used as sinks for Spark/Flink pipelines and the Hudi writing path provides several enhanced capabilities over file writing done by vanilla parquet/avro sinks. It categorizes write operations into incremental (insert, upsert, delete) and batch/bulk (insert_overwrite, delete_partition, bulk_insert) with specific functionalities. upsert and delete efficiently merge records with identical keys and integrate with the file sizing mechanism, while insert operations smartly bypass certain steps like pre-combining, maintaining pipeline benefits. Similarly, bulk_insert operation offers control over file sizes for data imports. Batch operations integrate MVCC for seamless transitions between incremental and batch processing. Additionally, the write pipeline includes optimizations like handling large merges via rocksDB and concurrent I/O, enhancing write performance.
Readers
Hudi provides snapshot isolation for writers and readers, enabling consistent table snapshot queries across major query engines (Spark, Hive, Flink, Presto, Trino, Impala) and cloud warehouses. It optimizes query performance by utilizing lightweight processes, especially for base columnar file reads, and integrates engine-specific vectorized readers like in Presto and Trino. This scalable model surpasses the need for separate readers and taps into each engine's unique optimizations, such as Presto and Trino's data/metadata caches. For queries merging Base and Log Files, Hudi employs mechanisms such as spillable maps and lazy reading to boost merge performance. Additionally, Hudi offers a read-optimized query option, trading off data freshness for improved query speed. There are also recently added features such as positional merge, encoding partial Log File to only changed columns and support for Parquet as the Log File format to improve MoR snapshot query performance.
User Access
SQL Engines
Hudi is compatible with a wide array of SQL query engines, catering to various analytical needs. For distributed ETL batch processing, Apache Spark is frequently utilized, leveraging its efficient handling of large-scale data. In the realm of streaming use cases, compute engines such as Apache Flink and Apache Spark's Structured Streaming provide robust support when paired with Hudi. Moreover, Hudi supports modern data lake query engines such as Trino and Presto, as well as modern analytical databases such as ClickHouse and StarRocks. This diverse support of compute engines positions Hudi as a flexible and adaptable platform for a broad spectrum of use cases.
Code Frameworks
While SQL still rules the roost when it comes to data engineering, an equally important and widespread data engineering/data science practice is to write code in different languages like Java, Scala, Python and R, to analyze data using sophisticated algorithms with full expressiveness of the language. To this end, Hudi supports several popular data processing frameworks like Apache Spark and Apache Flink, as well as python based distributed frameworks like Daft, Ray and native bindings in Rust for easy integration with engines written in C/C++.
...
Platform Services
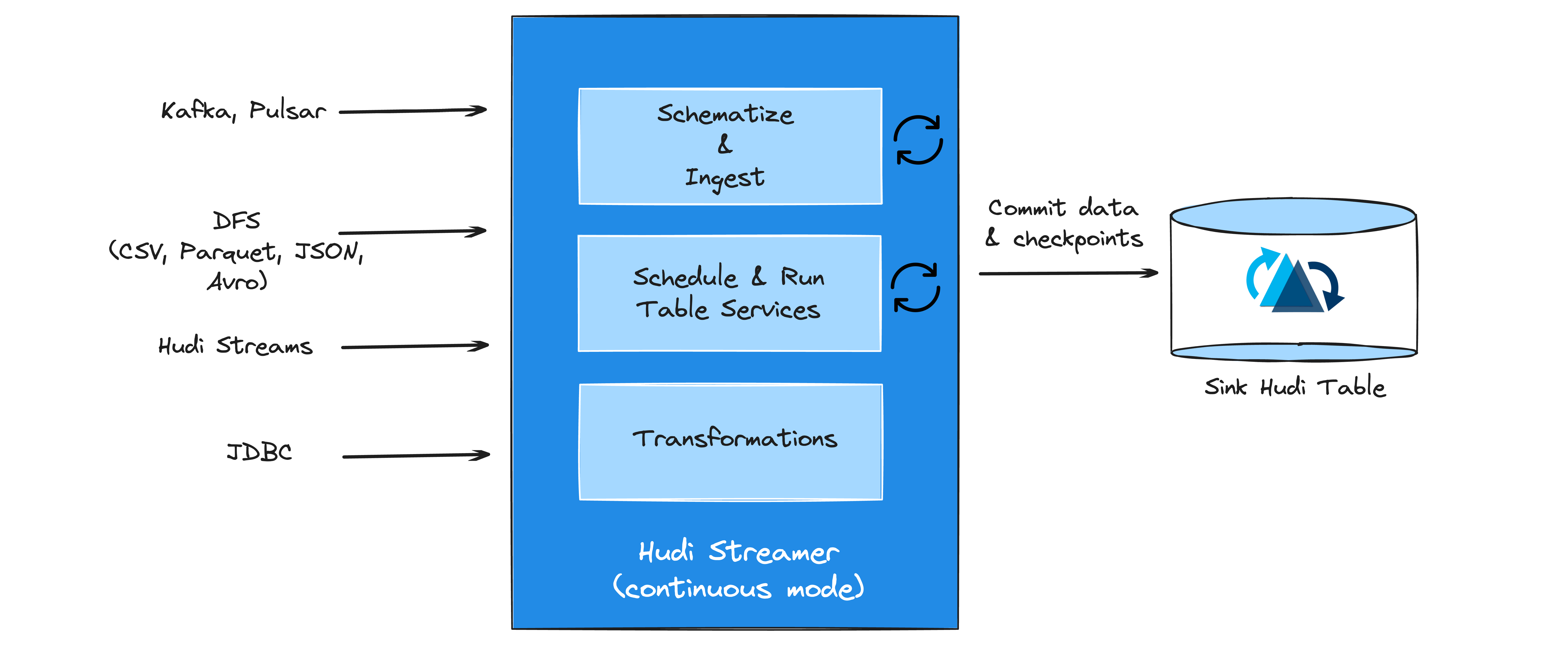
Various platform services in Hudi
Platform services offer functionality that is specific to data and workloads, and they sit directly on top of the table services, interfacing with writers and readers. Services, like Hudi Streamer (or its Flink counterpart), are specialized in handling data and workloads, seamlessly integrating with Kafka streams and various formats to build data lakes. They support functionalities like automatic checkpoint management, integration with major schema registries (including Confluent), and deduplication of data. Hudi Streamer also offers features for backfills, one-off runs, and continuous mode operation with Spark/Flink streaming writers. Additionally, Hudi provides tools for snapshotting and incrementally exporting Hudi tables, importing new tables, and post-commit callback for analytics or workflow management, enhancing the deployment of production-grade incremental pipelines. Apart from these services, Hudi also provides broad support for different catalogs such as Hive Metastore, AWS Glue, Google BigQuery, DataHub, etc. that allows syncing of Hudi tables to be queried by interactive engines such as Trino and Presto.
Metaserver*
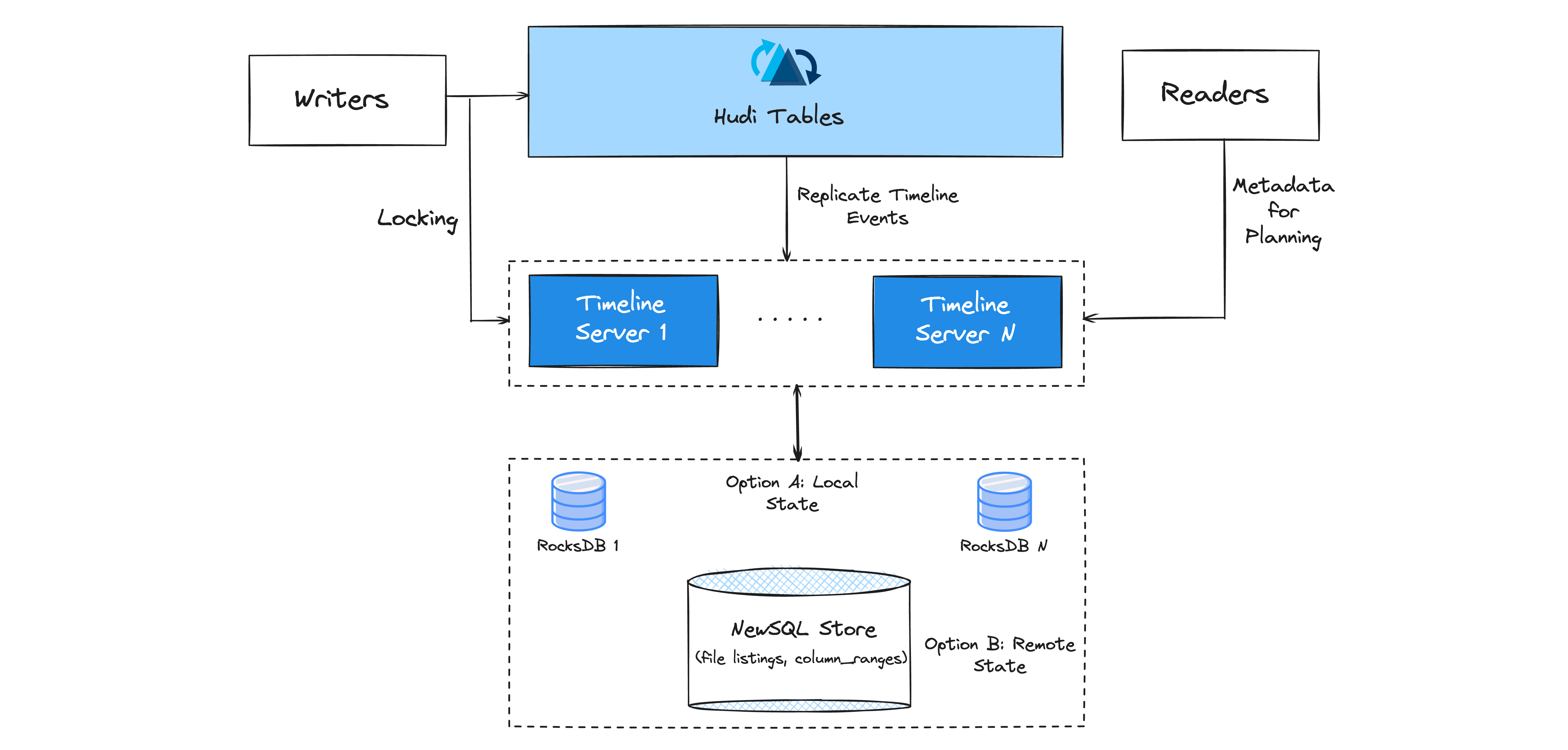
Proposed Metaserver in Hudi
Storing table metadata on lake storage, while scalable, is less efficient than RPCs to a scalable meta server. Hudi addresses this with its metadata server, called "metaserver," an efficient alternative for managing table metadata for a large number of tables. Currently, the timeline server, embedded in Hudi's writer processes, uses a local rocksDB store and Javalin REST API to serve file listings, reducing cloud storage listings. Since version 0.6.0, there's a trend towards standalone timeline servers, aimed at horizontal scaling and improved security. These developments are set to create a more efficient lake metastore for future needs.