Hudi’s Automatic File Sizing Delivers Unmatched Performance

Introduction
In today’s data-driven world, managing large volumes of data efficiently is crucial. One of the standout features of Apache Hudi is its ability to handle small files during data writes, which significantly optimizes both performance and cost. In this post, we’ll explore how Hudi’s auto file sizing, powered by a unique bin packing algorithm, can transform your data processing workflows.
Understanding Small File Challenges
In big data environments, small files can pose a major challenge. Some major use-cases which can create lot of small files -
- Streaming Workloads : When data is ingested in micro-batches, as is common in streaming workloads, the resulting files tend to be small. This can lead to a significant number of small files, especially for high-throughput streaming applications.
- High-Cardinality Partitioning : Excessive partitioning, particularly on columns with high cardinality, can create a large number of small files. This can be especially problematic when dealing with large datasets and complex data schemas.
These small files can lead to several inefficiencies that can include increased metadata overhead, degraded read performance, and higher storage costs, particularly when using cloud storage solutions like Amazon S3.
- Increased Metadata Overhead : Metadata is data about data, including information such as file names, sizes, creation dates, and other attributes that help systems manage and locate files. Each file, no matter how small, requires metadata to be tracked and managed. In environments where numerous small files are created, the amount of metadata generated can skyrocket. For instance, if a dataset consists of thousands of tiny files, the system must maintain metadata for each of these files. This can overwhelm metadata management systems, leading to longer lookup times and increased latency when accessing files.
- Degraded Read Performance : Reading data from storage typically involves input/output (I/O) operations, which can be costly in terms of time and resources. When files are small, the number of I/O operations increases, as each small file needs to be accessed individually. This scenario can create bottlenecks, particularly in analytical workloads where speed is critical. Querying a large number of small files may result in significant delays, as the system spends more time opening and reading each file than processing the data itself.
- Higher Cloud Costs : Many cloud storage solutions, like Amazon S3, charge based on the total amount of data stored as well as the number of requests made. With numerous small files, not only does the total storage requirement increase, but the number of requests to access these files also grows. Each small file incurs additional costs due to the overhead associated with managing and accessing them. This can add up quickly, leading to unexpectedly high storage bills.
- High Query Load : Multiple teams are querying these tables for various dashboards, ad-hoc analyses, and machine learning tasks. This leads to a high number of concurrent queries, including Spark jobs, which can significantly impact performance. All those queries/jobs will take a hit on both performance and cost.
Impact of Small File
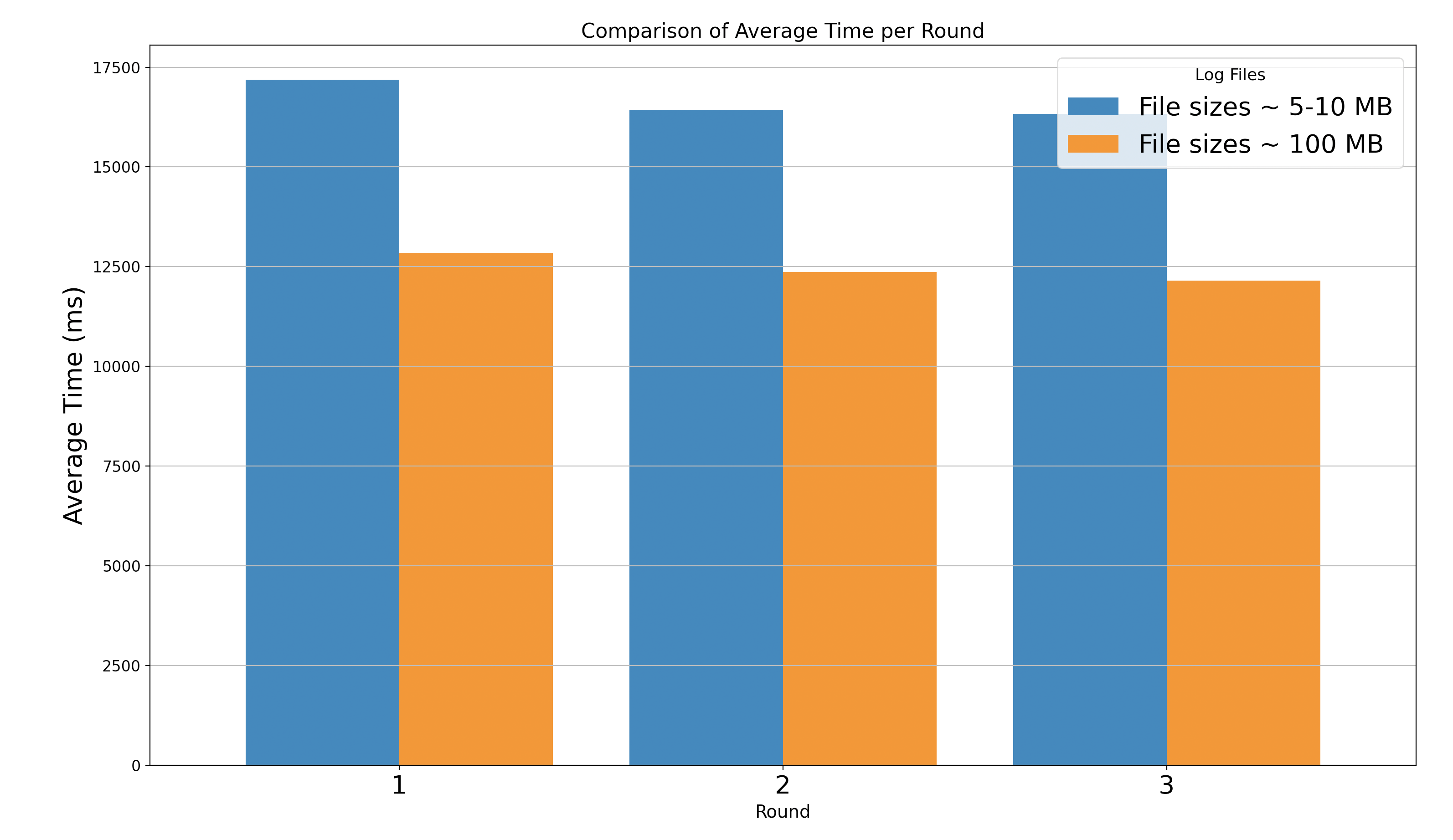
To demonstrate the impact of small files, we conducted a benchmarking using AWS EMR. Dataset Used - TPC-DS 1 TB dataset ( https://www.tpc.org/tpcds/ ) Cluster Configurations - 10 nodes (m5.4xlarge) Spark Configurations - Executors: 10 (16 cores 32 GB memory) Dataset Generation - We generated two types of datasets in parquet format
- Optimized File Sizes which had ~100 MB sized files
- Small File Sizes which had ~5-10 MB sized files Execution and Results
- We executed 3 rounds of 99 standard TPC-DS queries on both datasets and measured the time taken by the queries.
- The results indicated that queries executed on small files were, on average, 30% slower compared to those executed on optimized file sizes.
The following chart illustrates the average runtimes for the 99 queries across each round.
How table formats solve this problem
When it comes to managing small files in table formats, there are two primary strategies:
Ingesting Data As-Is and Optimizing Post-Ingestion :
In this approach, data, including small files, is initially ingested without immediate processing. After ingestion, various technologies provide functionalities to merge these small files into larger, more efficient partitions:
- Hudi uses clustering to manage small files.
- Delta Lake utilizes the OPTIMIZE command.
- Iceberg offers the rewrite_data_files function.
Pros:
- Writing small files directly accelerates the ingestion process, enabling quick data availability—especially beneficial for real-time or near-real-time applications.
- The initial write phase involves less data manipulation, as small files are simply appended. This streamlines workflows and eases the management of incoming data streams.
Cons:
- Until clustering or optimization is performed, small files may be exposed to readers, which can significantly slow down queries and potentially violate read SLAs.
- Just like with read performance, exposing small files to readers can lead to a high number of cloud storage API calls, which can increase cloud costs significantly.
- Managing table service jobs can become cumbersome. These jobs often can't run in parallel with ingestion tasks, leading to potential delays and resource contention.
Managing Small Files During Ingestion Only :
Hudi offers a unique functionality that can handle small files during the ingestion only, ensuring that only larger files are stored in the table. This not only optimizes read performance but also significantly reduces storage costs. By eliminating small files from the lake, Hudi addresses key challenges associated with data management, providing a streamlined solution that enhances both performance and cost efficiency.
How Hudi helps in small file handling during ingestion
Hudi automatically manages file sizing during insert and upsert operations. It employs a bin packing algorithm to handle small files effectively. A bin packing algorithm is a technique used to optimize file storage by grouping files of varying sizes into fixed-size containers, often referred to as "bins." This strategy aims to minimize the number of bins required to store all files efficiently. When writing data, Hudi identifies file groups of small files and merges new data into the same group, resulting in optimized file sizes.
The diagram above illustrates how Hudi employs a bin packing algorithm to manage small files while using default parameters: a small file limit of 100 MB and a maximum file size of 120 MB.
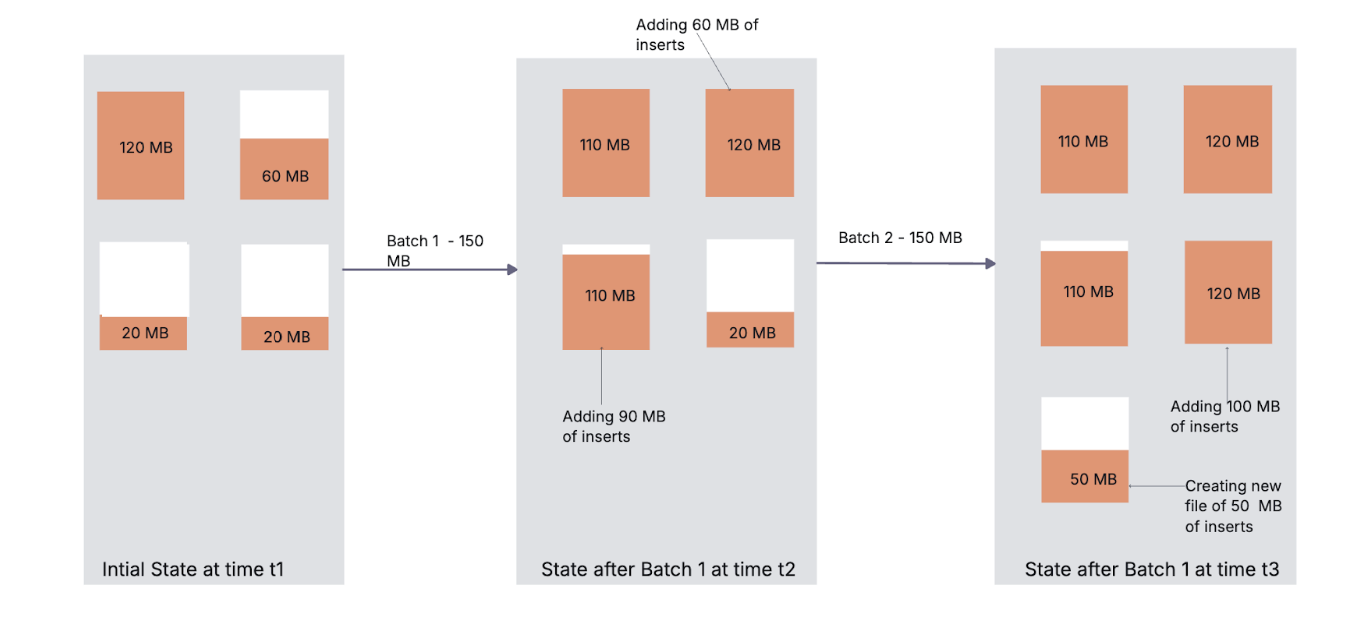
Initially, the table contains the following files: F1 (110 MB), F2 (60 MB), F3 (20 MB), and F4 (20 MB). After processing a batch-1 of 150 MB, F2, F3, and F4 will all be classified as small files since they each fall below the 100 MB threshold. The first 60 MB will be allocated to F2, increasing its size to 120 MB. The remaining 90 MB will be assigned to F3, bringing its total to 110 MB. After processing batch-2 of 150 MB, only F4 will be classified as a small file. F3, now at 110 MB, will not be considered a small file since it exceeds the 100 MB limit. Therefore, an additional 100 MB will be allocated to F4, increasing its size to 120 MB, while the remaining 50 MB will create a new file of 50 MB. We can refer this blog for in-depth details of the functionality - https://hudi.apache.org/blog/2021/03/01/hudi-file-sizing/
We use following configs to configure this -
-
hoodie.parquet.max.file.size (Default 128 MB) This setting specifies the target size, in bytes, for Parquet files generated during Hudi write phases. The writer will attempt to create files that approach this target size. For example, if an existing file is 80 MB, the writer will allocate only 40 MB to that particular file group.
-
hoodie.parquet.small.file.limit (Default 100 MB) This setting defines the maximum file size for a data file to be classified as a small file. Files below this threshold are considered small files, prompting the system to allocate additional records to their respective file groups in subsequent write phases.
-
hoodie.copyonwrite.record.size.estimate (Default 1024) This setting represents the estimated average size of a record. If not explicitly specified, Hudi will dynamically compute this estimate based on commit metadata. Accurate record size estimation is essential for determining insert parallelism and efficiently bin-packing inserts into smaller files.
-
hoodie.copyonwrite.insert.split.size (Default 500000) This setting determines the number of records inserted into each partition or bucket during a write operation. The default value is based on the assumption of 100MB files with at least 1KB records, resulting in approximately 100,000 records per file. To accommodate potential variations, we overprovision to 500,000 records. As long as auto-tuning of splits is turned on, this only affects the first write, where there is no history to learn record sizes from.
-
hoodie.merge.small.file.group.candidates.limit (Default1) This setting specifies the maximum number of file groups whose base files meet the small-file limit that can be considered for appending records during an upsert operation. This parameter is applicable only to Merge-On-Read (MOR) tables.
We can refer this blog to understand internal functionality how it works - https://hudi.apache.org/blog/2021/03/01/hudi-file-sizing/#during-write-vs-after-write
Conclusion
Hudi's innovative approach to managing small files during ingestion positions it as a compelling choice in the lakehouse landscape. By automatically merging small files at the time of ingestion, it optimizes storage costs and enhances read performance, and alleviates users from the operational burden of maintaining their tables in an optimized state.
Unleash the power of Apache Hudi for your big data challenges! Head over to https://hudi.apache.org/ and dive into the quickstarts to get started. Want to learn more? Join our vibrant Hudi community! Attend the monthly Community Call or hop into the Apache Hudi Slack to ask questions and gain deeper insights.