Exploring Apache Hudi’s New Log-Structured Merge (LSM) Timeline

Apache Hudi 1.0 introduces a new LSM Timeline to scale metadata management for long-lived tables. By restructuring timeline storage into a compacted, versioned tree layout, Hudi enables faster metadata access, snapshot isolation, and support for Non-Blocking Concurrency Control.
Apache Hudi’s Timeline
At the heart of Apache Hudi’s architecture is the Timeline - a log-structured system that acts as the single source of truth for the table’s state at any point in time. The timeline records every change and operation performed on a Hudi table, encompassing writes, schema evolutions, compactions, cleanings, and clustering operations. This meticulous record-keeping empowers Hudi to deliver ACID guarantees, robust concurrency control, and advanced capabilities such as incremental processing, rollback/recovery, and time travel.
In essence, the timeline functions like a Write-Ahead Log (WAL), maintaining a sequence of immutable actions. Each action is recorded as a unique instant - a unit of work identified by its action type (e.g., commit, clean, compaction), a timestamp that marks when the action was initiated, and its lifecycle state. In Hudi, an instant refers to this combination of action, timestamp, and state (REQUESTED, INFLIGHT, or COMPLETED), and serves as the atomic unit of change on the timeline. These timeline entries are the backbone of Hudi’s transactional integrity, ensuring that every table change is atomically recorded and timeline-consistent. Every operation progresses through a lifecycle of states:
- REQUESTED: The action is planned and registered but not yet started.
- INFLIGHT: The action is actively being performed, modifying table state.
- COMPLETED: The action has successfully executed, and all data/metadata updates are finalized.
These instants serve as both log entries and transaction markers, defining exactly what data is valid and visible at any given time. Whether you're issuing a snapshot query for the latest view, running an incremental query to fetch changes since the last checkpoint, or rolling back to a prior state, the timeline ensures that each action’s impact is precisely tracked. Every action, such as commit, clean, compaction, or rollback is explicitly recorded, allowing compute engines and tools to reason precisely about the table’s state transitions and history. This strict sequencing and lifecycle management also underpin Hudi’s ability to provide serializable isolation (the “I” in ACID) guarantees, ensuring that readers only observe committed data and consistent snapshots.
To optimize both performance and long-term storage scalability, Apache Hudi splits the timeline into two distinct components that work together to provide fast access to recent actions while ensuring historical records are retained efficiently. Let’s understand these in detail.
Active Timeline
The Active timeline is the front line of Hudi’s transaction log. It contains the most recent and in-progress actions that are critical for building a consistent and up-to-date view of the table. Every time a new operation, such as a data write, compaction, clean, or rollback is initiated, it is immediately recorded here as a new instant file under the .hoodie/ directory. Each of these files holds metadata about the action’s lifecycle, moving through the standard states of REQUESTED → INFLIGHT → COMPLETED.
The active timeline is consulted constantly - whether you are issuing a query, running compaction, or planning a new write operation. Compute engines read from the active timeline to determine what data files are valid and visible, making it the source of truth for the table’s latest state. To maintain performance, Hudi enforces a retention policy on the active timeline, i.e. it deliberately keeps only a window of the most recent actions, ensuring the timeline remains lightweight and quick to scan.
Archived Timeline
Tables naturally accumulate many more actions over time, especially in high-ingestion or update environments. As the number of instants grows, the active timeline can become bloated if left unchecked, introducing latency and performance penalties during reads and writes.
To solve this, Hudi implements an archival process. Once the number of active instants crosses a configured threshold, older actions are offloaded from the active timeline into the Archived Timeline stored in the .hoodie/archive/ directory. This design ensures that while the active timeline remains lean and fast for day-to-day operations, the complete transactional history of the table is still preserved for auditing, recovery, and time travel purposes.
Although the archived timeline is optimized for long-term retention, accessing deep history can incur higher latency and overhead, especially in workloads with a large number of archived instants. This limitation is precisely what set the stage for the LSM Timeline innovation introduced in Hudi 1.0.
Problem Statement - Why move to an LSM Timeline?
Apache Hudi’s original timeline design served well for many workloads. By maintaining a lightweight active timeline for fast operations and offloading historical instants to the archive, Hudi struck a balance between performance and durability. However, there were some aspects to think about with the previous timeline design.
-
Linear Growth: The timeline grows linearly with each table action, whether it’s a commit, compaction, clustering, or rollback. Although Hudi’s archival process offloads older instants to keep the active timeline lean, the total number of instants (active + archived) continues to grow unbounded in long-lived tables. Over time, the accumulation of these instants can inflate metadata size, leading to slower scans and degraded query planning performance, especially for use cases like time travel and incremental queries.
-
Latency & Cost: Accessing the archived timeline, which is often required for time-travel, or recovery operations introduces high read latencies. This is because the archival format was optimized for durability and storage efficiency (many small Avro files), not for fast access. As the number of archived instants balloons, reading deep history involves scanning and deserializing large volumes of metadata, increasing both latency and compute cost. This can noticeably slow down operations like incremental syncs and historical audits.
-
Cloud Storage Limitations: In cloud object stores like S3 or GCS, appending to existing files is not supported (or is highly inefficient). As a result, every new archival batch creates new small files, leading to a small-file problem. Over time, these fragmented archives accumulate, creating operational challenges in storage management and performance bottlenecks during metadata access, especially when files must be scanned individually across large object stores.
-
Emerging Use Cases: Apache Hudi has evolved to support next-generation features such as non-blocking concurrency control (NBCC), infinite time travel, and fine-grained transaction metadata. These capabilities place heavier demands on the timeline architecture, requiring high-throughput writes and faster lookups across both recent and historical data.
Introducing the LSM Timeline
To overcome the scaling challenges of the original timeline architecture, Apache Hudi 1.0 introduced the LSM (Log-Structured Merge) Timeline - a fundamentally new way to store and manage timeline metadata. This redesign brings together principles of log-structured storage, tiered compaction, and snapshot versioning to deliver a highly scalable, cloud-native solution for tracking table history.
Hudi introduces a critical change in how time is represented on the timeline. Previously, Hudi treated time as instantaneous, i.e. each action appeared to take effect at a single instant. While effective for basic operations, this model proved limiting when implementing certain advanced features like Non-Blocking Concurrency Control (NBCC), which require reasoning about actions as intervals of time to detect overlaps and resolve conflicts.
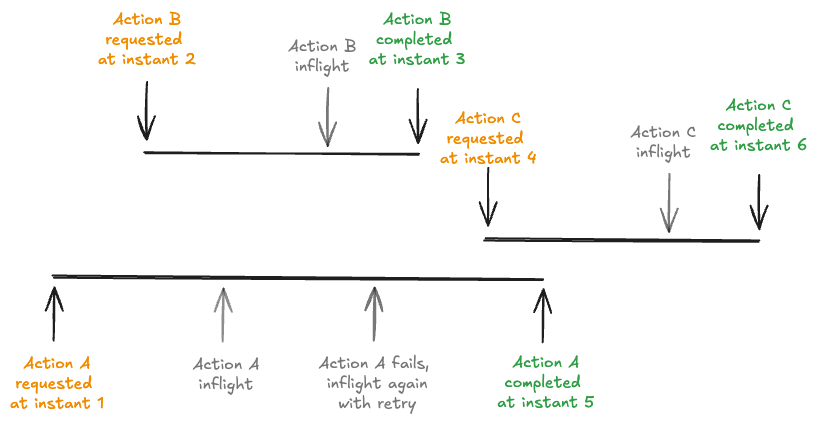
To address this, every action on the Hudi timeline now records both a requested time (when the action is initiated) and a completion time (when it finishes). This allows Hudi to track not just when an action was scheduled, but also how it interacts with other concurrent actions over time. To ensure global consistency across distributed processes, Hudi formalized the use of TrueTime semantics, guaranteeing that all instant times are monotonically increasing and globally ordered. This is a foundational requirement for precise conflict detection and robust transaction isolation.
How It Works / Design
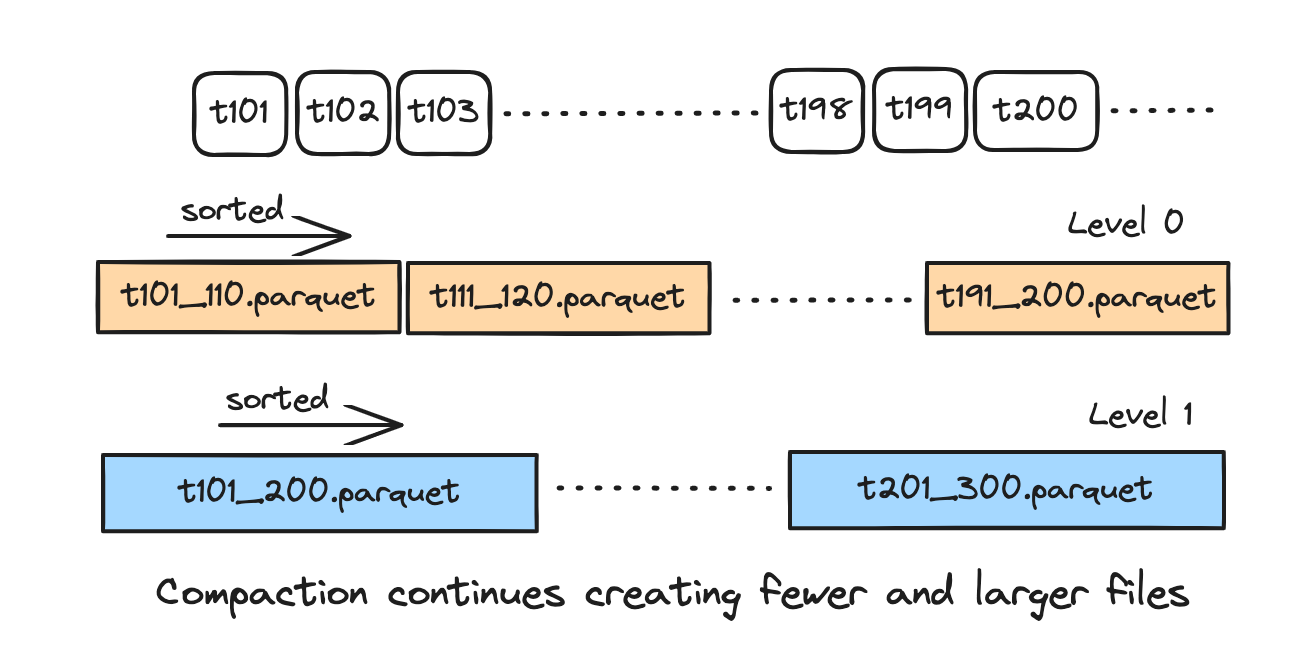
At its core, the LSM timeline replaces the flat archival model with a layered tree structure, allowing Hudi to manage metadata for millions of historical instants efficiently, without compromising on read performance or consistency. Here’s how it’s designed:
File Organization
- Metadata files are organized into layers (L0, L1, L2, …) following a Log-Structured Merge (LSM) tree layout.
- Each file is a Parquet file that stores a batch of timeline instants. Their metadata entries are sorted chronologically by timestamp.
- The files follow a precise naming convention:
${min_instant}_${max_instant}_${level}.parquetwheremin_instantandmax_instantrepresent the range of instants in the file andleveldenotes the layer (e.g., L0, L1, L2). - Files in the same layer may have overlapping time ranges, but the system tracks them via manifest files (more on that below).
Compaction Strategy
- The LSM timeline uses a universal compaction strategy, similar to designs seen in modern databases.
- Whenever N files (default: 10) accumulate in a given layer (e.g., L0), they are merged and flushed into the next layer (e.g., L1).
- Compaction is governed by a size-based policy (default max file size ~1 GB), ensuring that write amplification is controlled and files stay within optimal size limits.
- There’s no hard limit on the number of layers. The LSM tree naturally scales to handle massive tables with deep histories.
Version & Manifest Management: Snapshot Isolation
- The LSM timeline introduces manifest files that record the current valid set of Parquet files representing the latest snapshot of the timeline.
- Version files are generated alongside manifest files to maintain snapshot isolation, ensuring that readers and writers do not conflict.
- This system supports multiple valid snapshot versions simultaneously (default: 3), enabling:
- Consistent reads even during compaction.
- Seamless evolution of the timeline without impacting query correctness.
Reader Workflow
- When a query is made on the timeline:
- The engine first fetches the latest version file.
- It reads the corresponding manifest file to get the list of valid data files.
- It scans only the relevant Parquet files, often using timestamp-based filtering to skip irrelevant data early.
Cleaning Strategy
- The LSM timeline performs cleaning only after successful compaction, ensuring that no active snapshot is disrupted.
- By default, Hudi retains 3 valid snapshot versions to support concurrent readers/writers.
- Files are retained for at least 3 archival trigger intervals, providing a grace period before old data is purged.
What It Brings to the Table (Benefits)
The LSM timeline unlocks significant advancements in how Apache Hudi handles metadata, providing both performance improvements and new capabilities.
-
Scalability: The LSM timeline architecture allows Hudi to manage virtually infinite timeline history while keeping both read and write performance predictable. Whether it's thousands or millions of instants, the layered compaction model ensures stable metadata performance over time, supporting efficient query and metadata access even as tables grow in size and history length.
-
Efficient Reads: Readers benefit from manifest-guided lookups, allowing them to scan only the specific set of files relevant to their query. By using Parquet’s columnar format and timestamp-based filtering, Hudi dramatically reduces the overhead of accessing deep historical metadata.
-
Non-Blocking Concurrency Control (NBCC): One of the most powerful capabilities enabled by the LSM timeline is Non-Blocking Concurrency Control, allowing multiple writers to operate concurrently on the same table (and even the same file group) without the need for explicit locks - except during final commit metadata updates.
-
Cloud-Native Optimization: By compacting small files into large Parquet files, the LSM timeline avoids the small-file problem common in cloud storage systems like Amazon S3 or Google Cloud Storage. This improves both query performance and storage cost efficiency.
-
Snapshot Isolation & Consistency: The manifest + version file mechanism ensures that concurrent operations remain isolated and consistent, even as background compaction and cleaning occur. This provides strong transactional guarantees without sacrificing performance.
-
Maintenance-Free Scalability: The universal compaction and smart cleaning strategies keep the timeline healthy over time, requiring minimal manual tuning, while ensuring that old data is cleaned up safely only after valid snapshots are no longer in use.
Performance
Micro-benchmarks show that the LSM Timeline scales efficiently even as the number of timeline actions grows by orders of magnitude. Reading just the instant times for 10,000 actions takes around 32ms, while fetching full metadata takes 150ms. At larger scales, such as 10 million actions, metadata reads completes in about 162 seconds.
These results demonstrate that Hudi's LSM timeline can handle decades of high-frequency commits (e.g., one every 30 seconds for 10+ years) while keeping metadata access performant.
The LSM timeline represents a natural progression in Apache Hudi’s timeline architecture, designed to address the growing demands of large-scale and long-lived tables. Hudi’s timeline has been foundational for transactional integrity, time travel, and incremental processing capabilities. The new LSM-based design enhances scalability and operational efficiency by introducing a layered, compacted structure with manifest-driven snapshot isolation. This improvement allows Hudi to manage extensive metadata histories more efficiently, maintain predictable performance, and better support advanced use cases such as non-blocking concurrency control.