Building Analytical Apps on the Lakehouse using Apache Hudi, Daft & StreamlitMay 10, 2024 by Dipankar Mazumdarpythondaftstreamlitdata lakehouse
Learn how to read Hudi data with AWS Glue Ray using Daft (No Spark)May 7, 2024 by Soumil Shahawsraydaft
How to Query Apache Hudi Tables with Python Using Daft: A Spark-Free ApproachMay 2, 2024 by Soumil Shahpythondaft
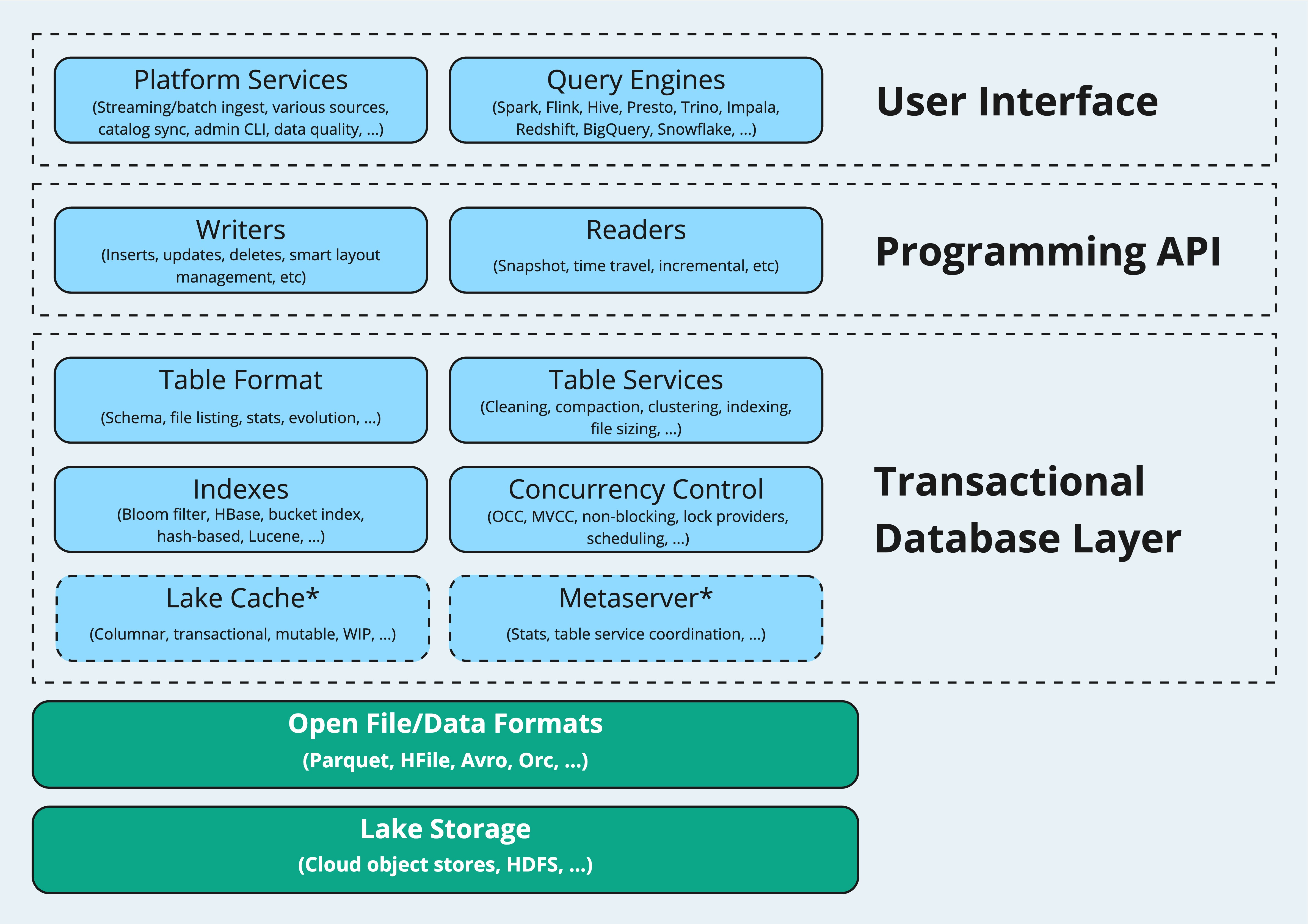
Apache Hudi vs Apache Iceberg: A Comprehensive ComparisonApril 25, 2024 by RisingWave marketing teamapache icebergcomparisonrisingwave
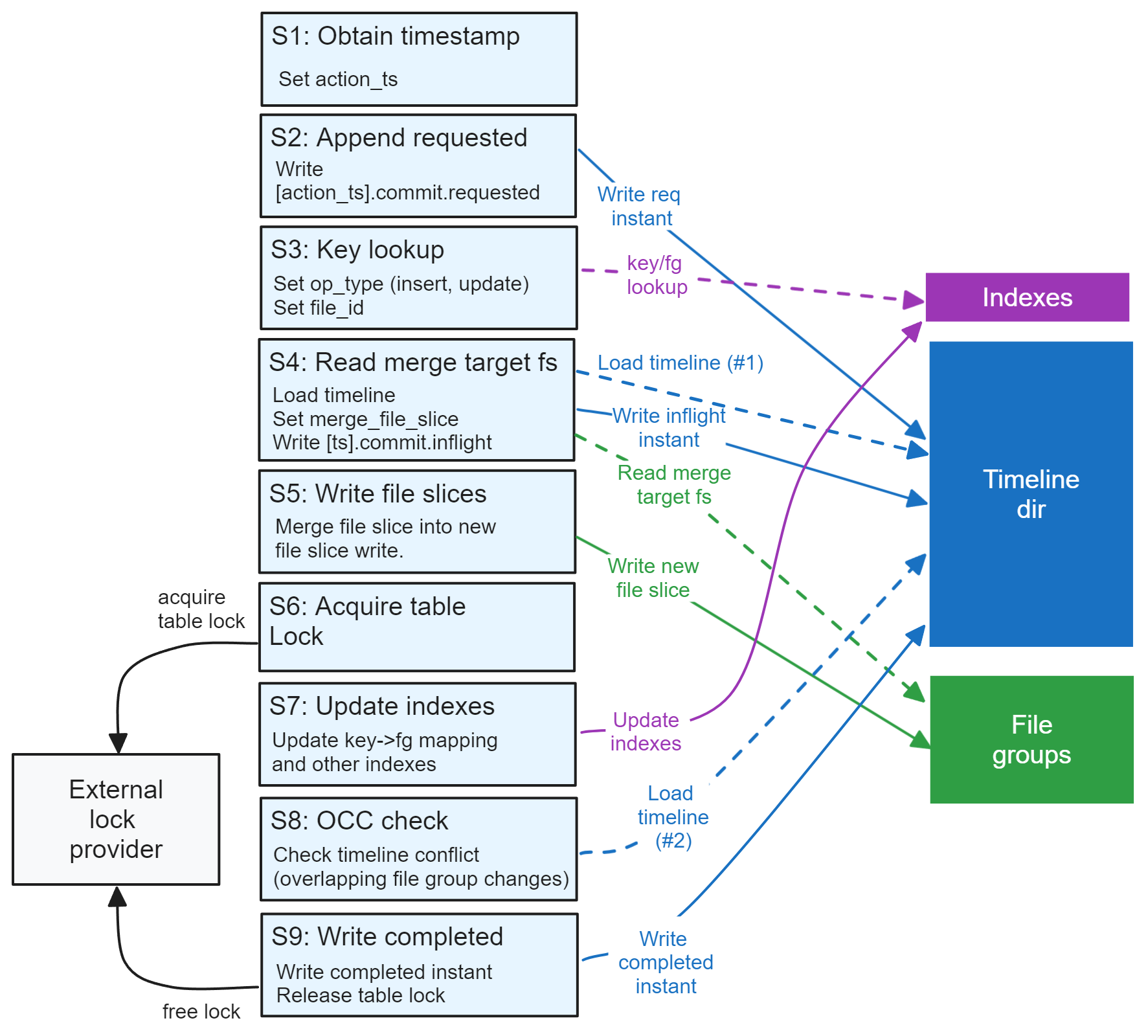
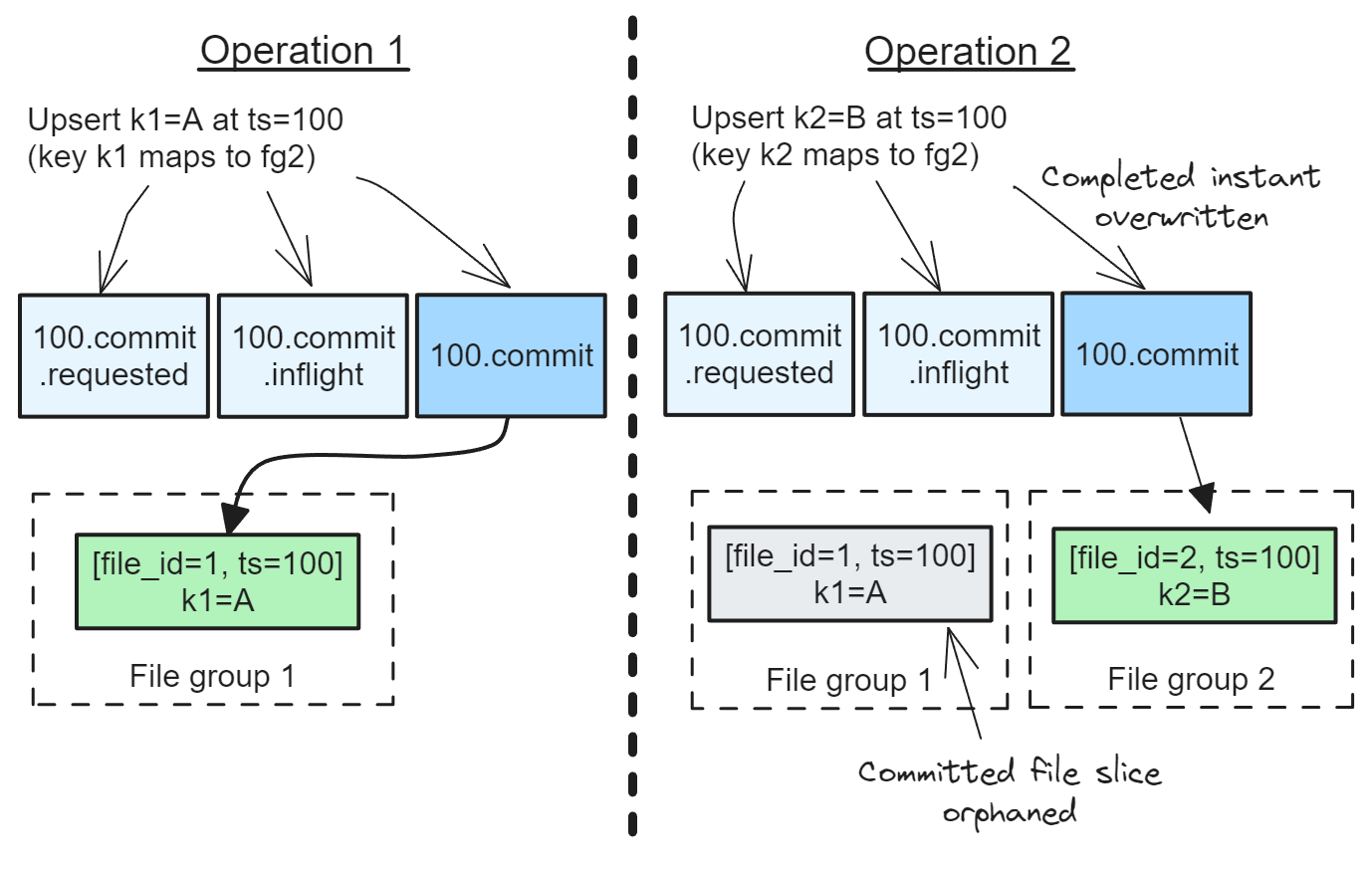
Understanding Apache Hudi's Consistency Model Part 1April 24, 2024 by Jack Vanlightlytable formatacidcowconcurrency controltla specification
Understanding Apache Hudi's Consistency Model Part 2April 24, 2024 by Jack Vanlightlyacidconcurrency control
Understanding Apache Hudi's Consistency Model Part 3April 24, 2024 by Jack Vanlightlytla specificationacidconcurrency control
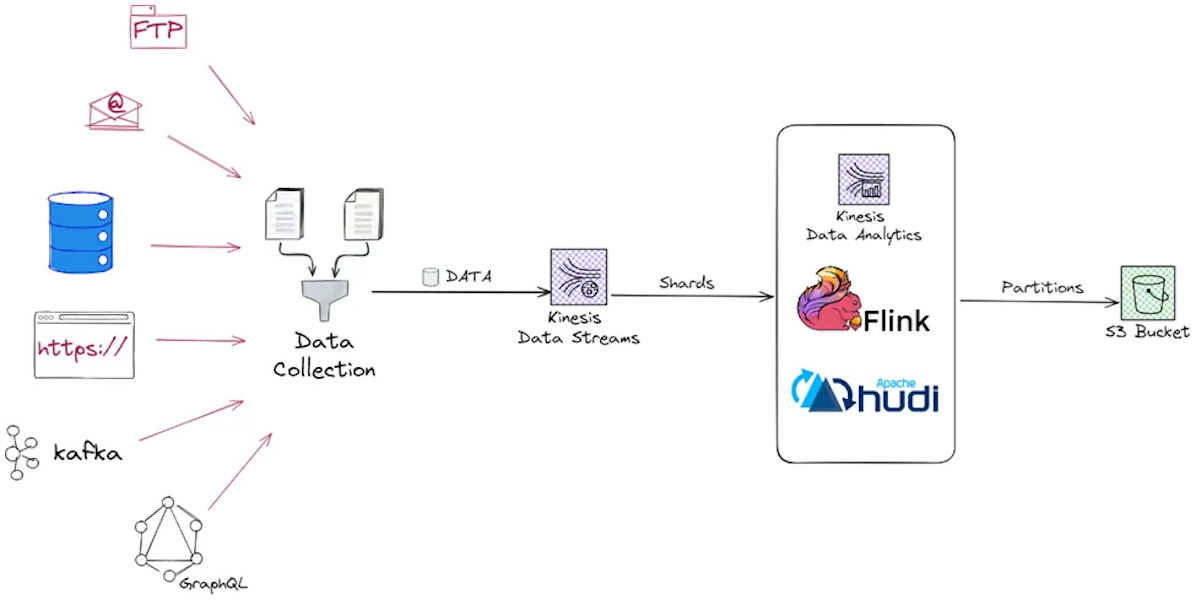
Build Real Time Streaming Pipeline with Kinesis, Apache Flink and Apache Hudi with Hands-onApril 21, 2024 by Md Shahid Afridi Papache flinkawsstreamingdata lakehouseincremental processing
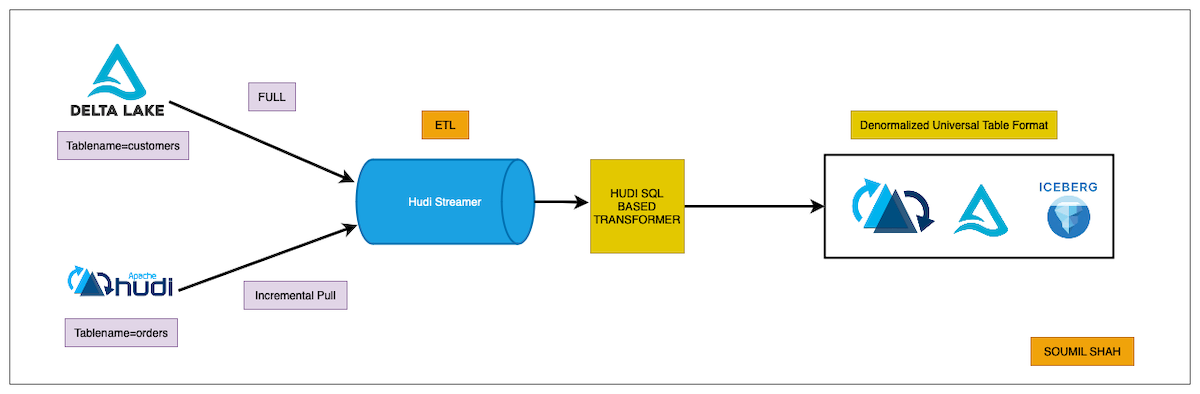
Hands-On Guide: Reading Data from Hudi Tables Incrementally, Joining with Delta Tables using HudiStreamer and SQL-Based TransformerApril 3, 2024 by Soumil Shahhudi streamerdelta lakesql transformer
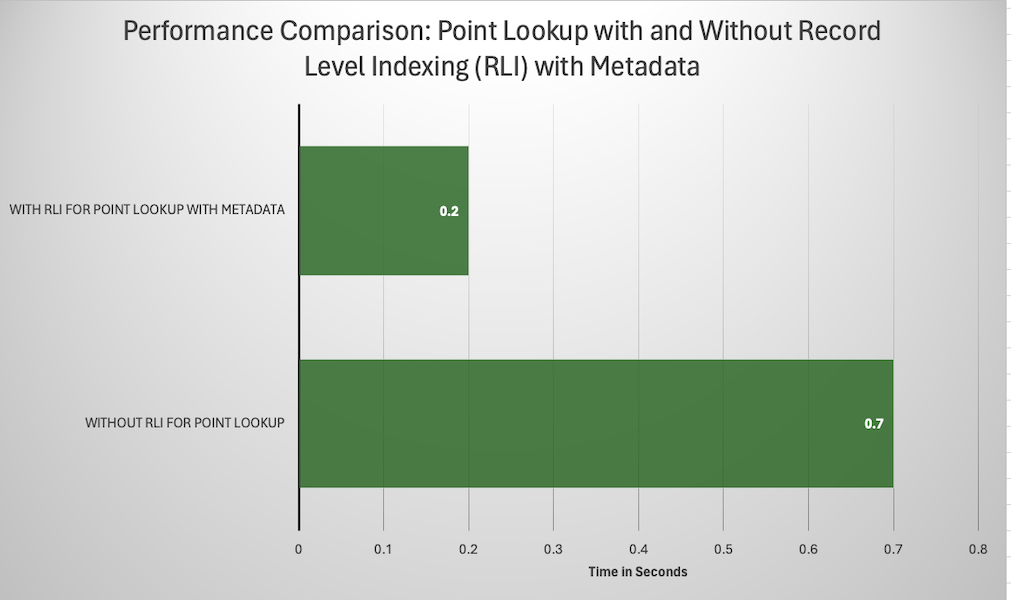
Record Level Indexing in Apache Hudi Delivers 70% Faster Point LookupsMarch 30, 2024 by Soumil Shahindexingperformance
Options on Kafka sink to open table Formats: Apache Iceberg and Apache HudiMarch 23, 2024 by Albert Wongapache icebergapache kafkastarrocks