1. Introduction
Apache Zeppelin is a web-based notebook that provides interactive data analysis. It is convenient for you to make beautiful documents that can be data-driven, interactive, and collaborative, and supports multiple languages, including Scala (using Apache Spark), Python (Apache Spark), SparkSQL, Hive, Markdown, Shell, and so on. Hive and SparkSQL currently support querying Hudi’s read-optimized view and real-time view. So in theory, Zeppelin’s notebook should also have such query capabilities.
2. Achieve the effect
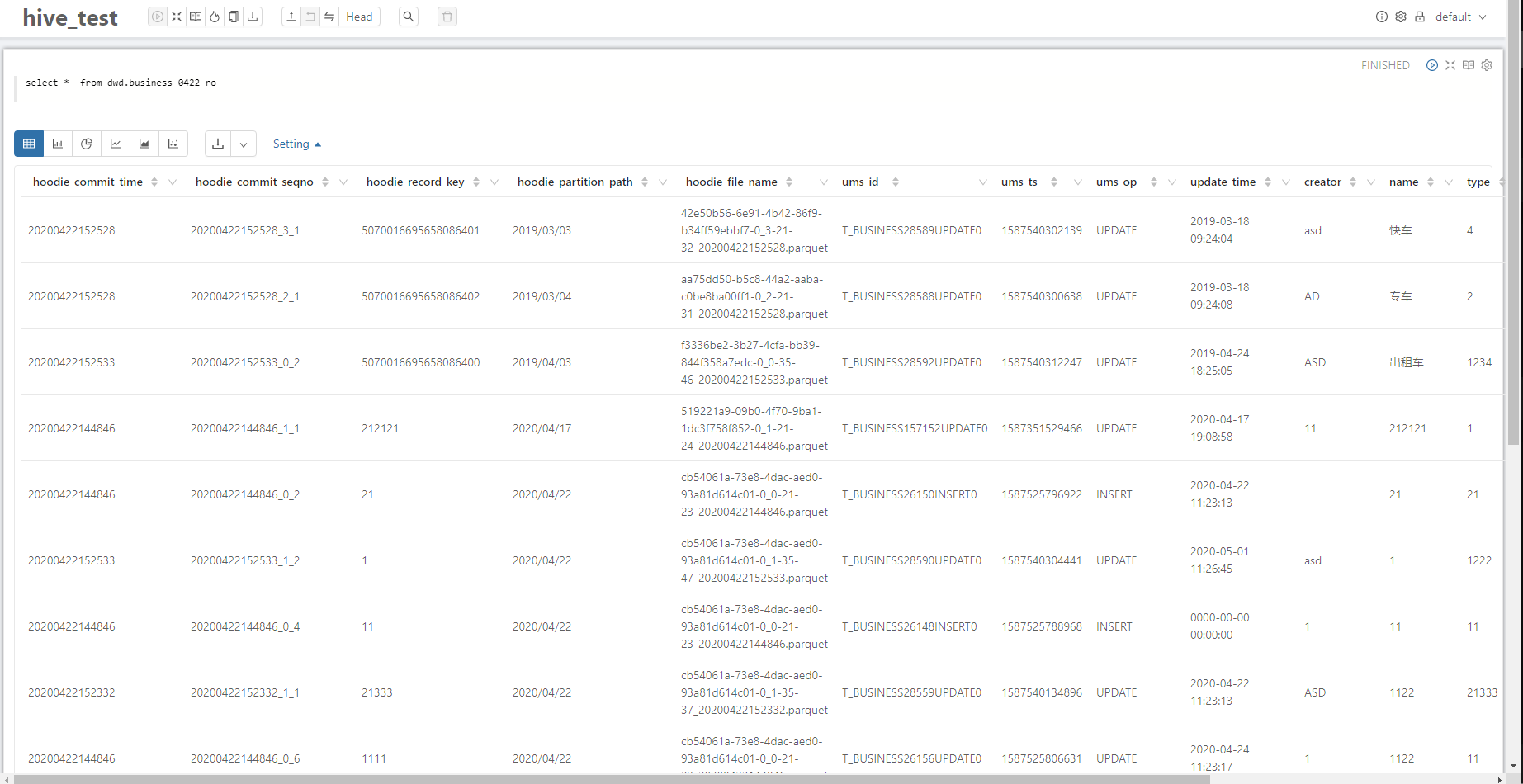
2.1 Hive
2.1.1 Read optimized view
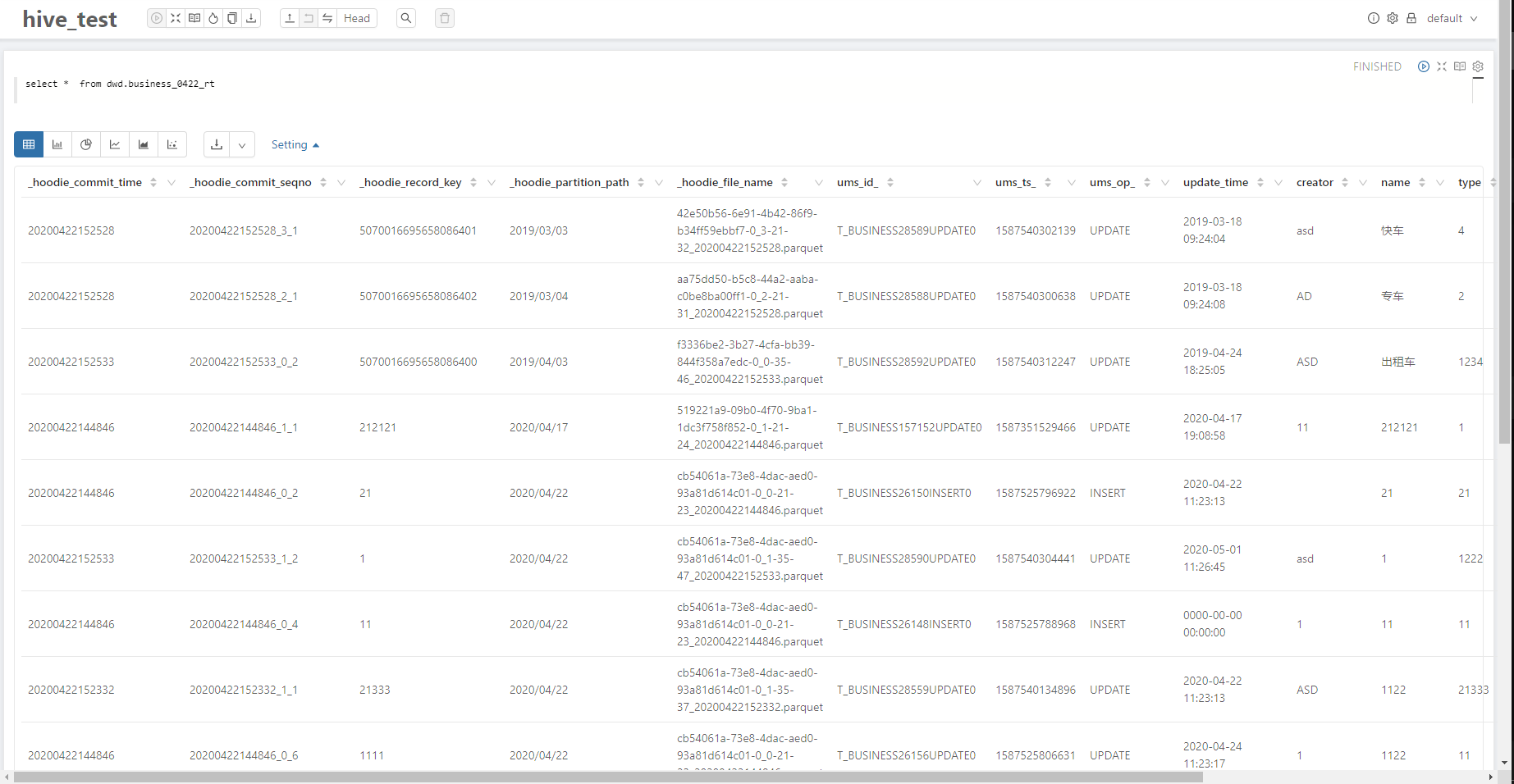
2.1.2 Real-time view
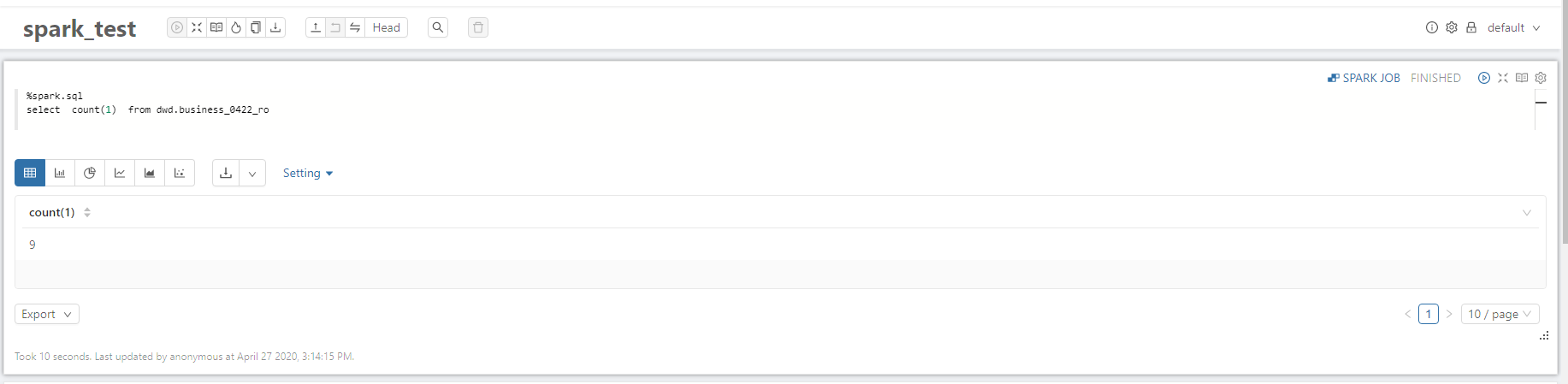
2.2 Spark SQL
2.2.1 Read optimized view
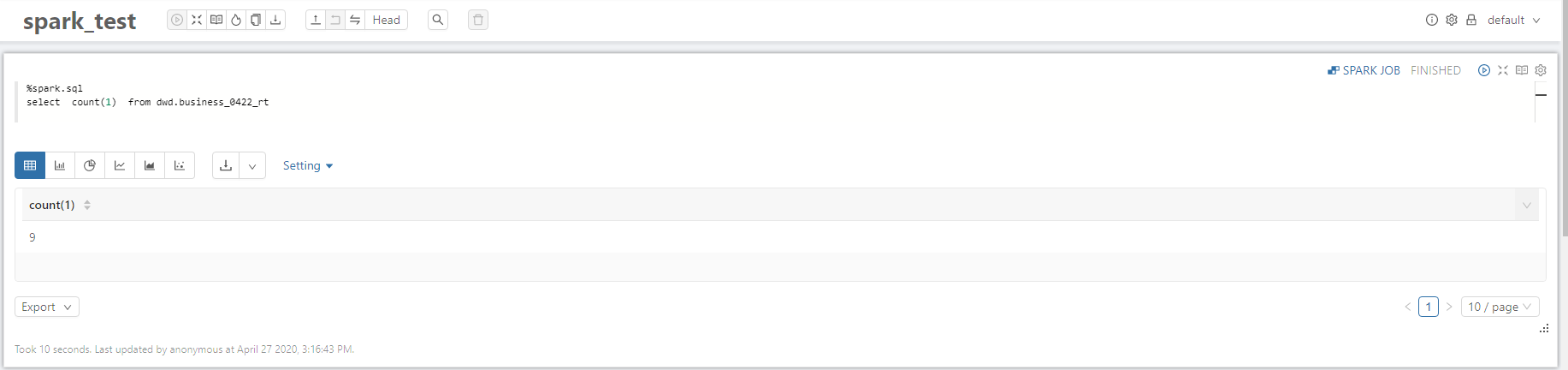
2.2.2 Real-time view
3. Common problems
3.1 Hudi package adaptation
Zeppelin will load the packages under lib by default when starting. For external dependencies such as Hudi, it is suitable to be placed directly under zeppelin / lib to avoid Hive or Spark SQL not finding the corresponding Hudi dependency on the cluster.
3.2 Parquet jar package adaptation
The parquet version of the Hudi package is 1.10, and the current parquet version of the CDH cluster is 1.9, so when executing the Hudi table query, many jar package conflict errors will be reported.
Solution: upgrade the parquet package to 1.10 in the spark / jars directory of the node where zepeelin is located. Side effects: The tasks of saprk jobs other than zeppelin assigned to the cluster nodes of parquet 1.10 may fail. Suggestions: Clients other than zeppelin will also have jar conflicts. Therefore, it is recommended to fully upgrade the spark jar, parquet jar and related dependent jars of the cluster to better adapt to Hudi’s capabilities.
3.3 Spark Interpreter adaptation
The same SQL using Spark SQL query on Zeppelin will have more records than the hive query.
Cause of the problem: When reading and writing Parquet tables to the Hive metastore, Spark SQL will use the Parquet SerDe (SerDe: Serialize / Deserilize for short) for Spark serialization and deserialization, not the Hive’s SerDe, because Spark SQL’s own SerDe has better performance.
This causes Spark SQL to only query Hudi’s pipeline records, not the final merge result.
Solution: set spark.sql.hive.convertMetastoreParquet=false
- Method 1: Edit properties directly on the page**

- Method 2: Edit
zeppelin / conf / interpreter.jsonand add**
"spark.sql.hive.convertMetastoreParquet": {
"name": "spark.sql.hive.convertMetastoreParquet",
"value": false,
"type": "checkbox"
}
4. Hudi incremental view
For Hudi incremental view, currently only supports pulling by writing Spark code. Considering that Zeppelin has the ability to execute code and shell commands directly on the notebook, later consider packaging these notebooks to query Hudi incremental views in a way that supports SQL.