54 posts tagged with "how-to"
View All Tags
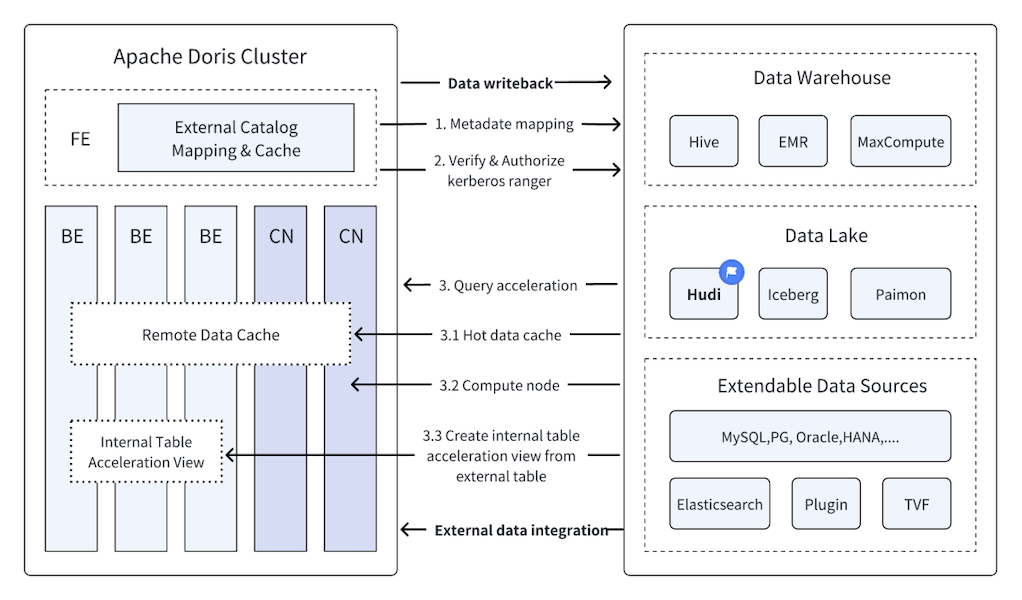
How to Use the New Hudi Streamer with Hudi 1.0.0 on EMR Serverless 7.5.0 | Hands-on Labs
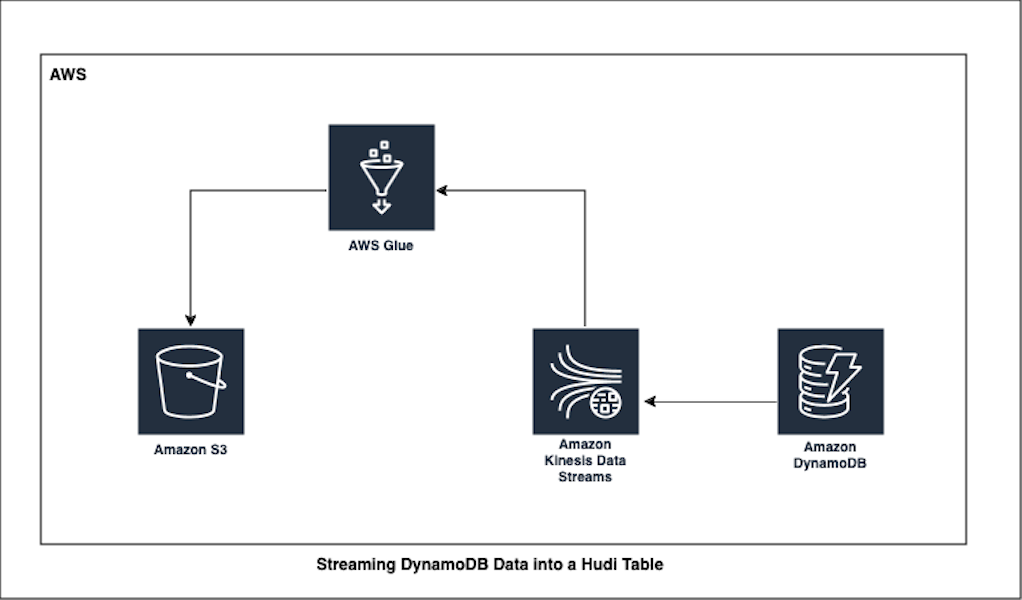
Streaming DynamoDB Data into a Hudi Table: AWS Glue in Action

Apache Hudi, Spark and Minio: Hands-on Lab in Docker
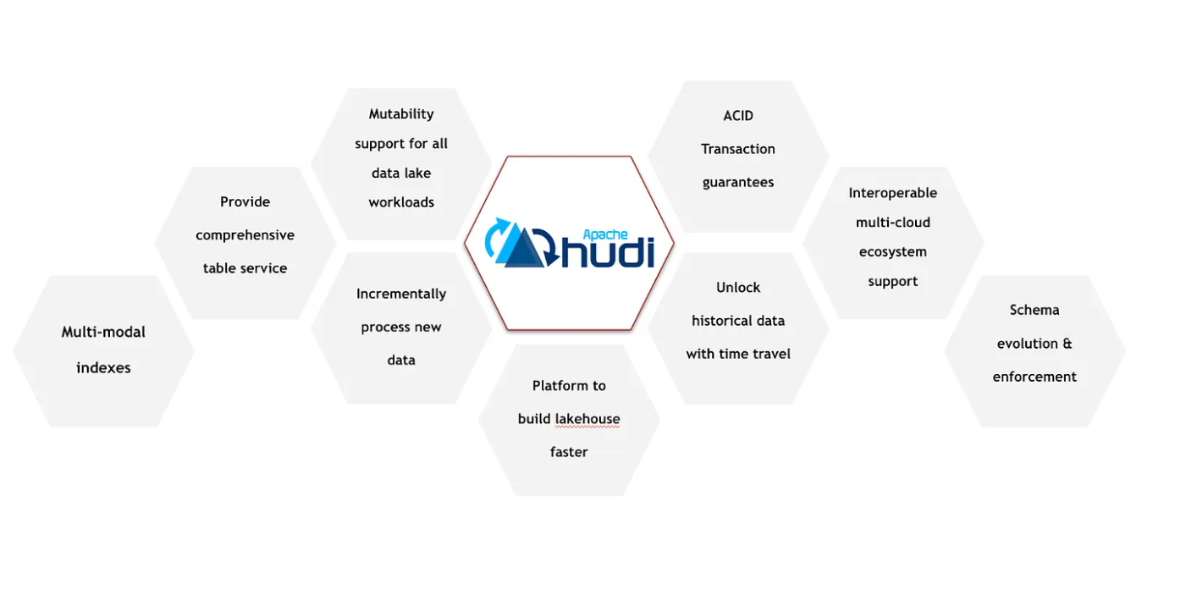
Getting started with Apache Hudi

Mastering Data Lakes: A Deep Dive into MINIO, Hudi, and Delta Streamer
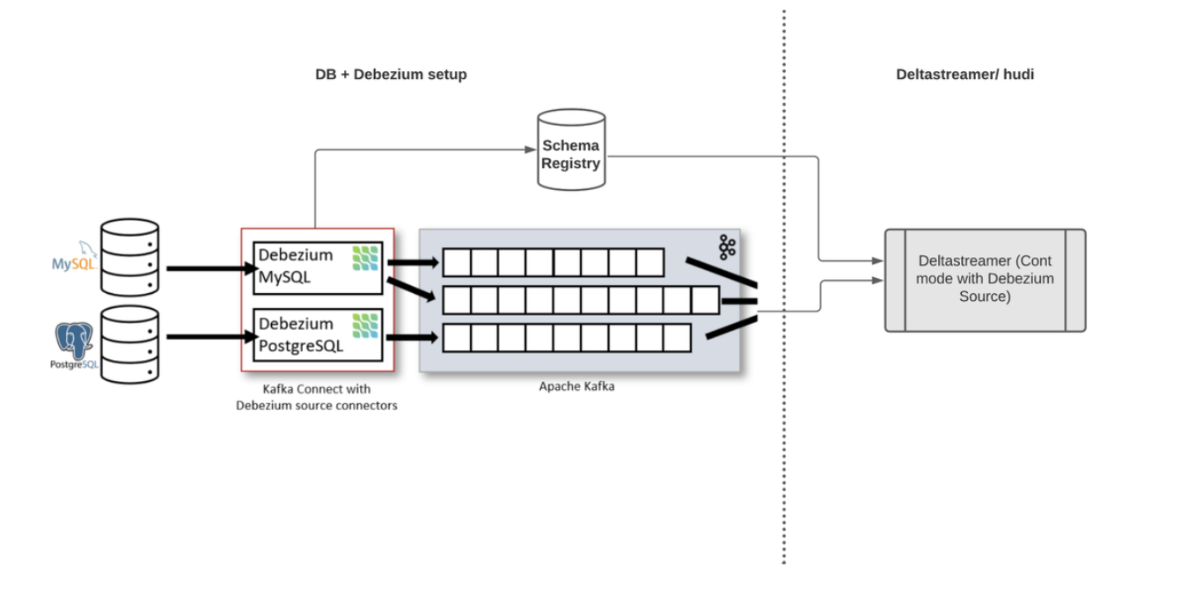
Real-Time Data Processing with Postgres, Debezium, Kafka, Schema Registry, and Delta Streamer Guide for Begineers

Introducing Apache Hudi support with AWS Glue crawlers

Hudi Streamer (Delta Streamer) Hands-On Guide: Local Ingestion from Parquet Source
Load data incrementally from transactional data lakes to data warehouses
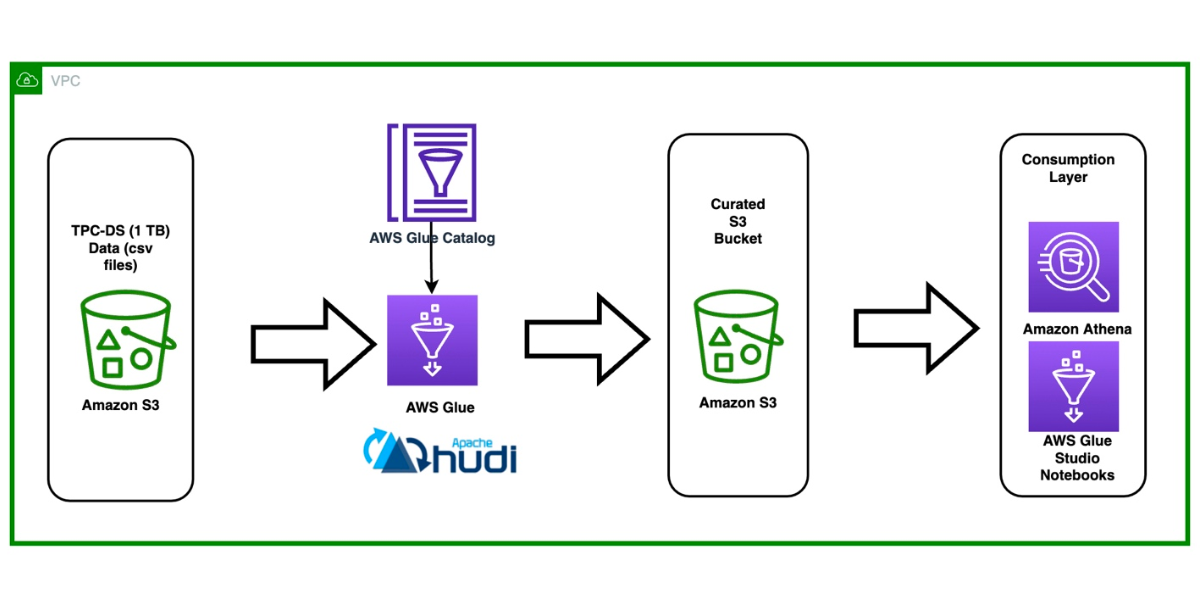
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1
