34 posts tagged with "Amazon"
View All Tags
Use open table format libraries on AWS Glue 5.0 for Apache Spark

Using Apache Hudi with Apache Flink
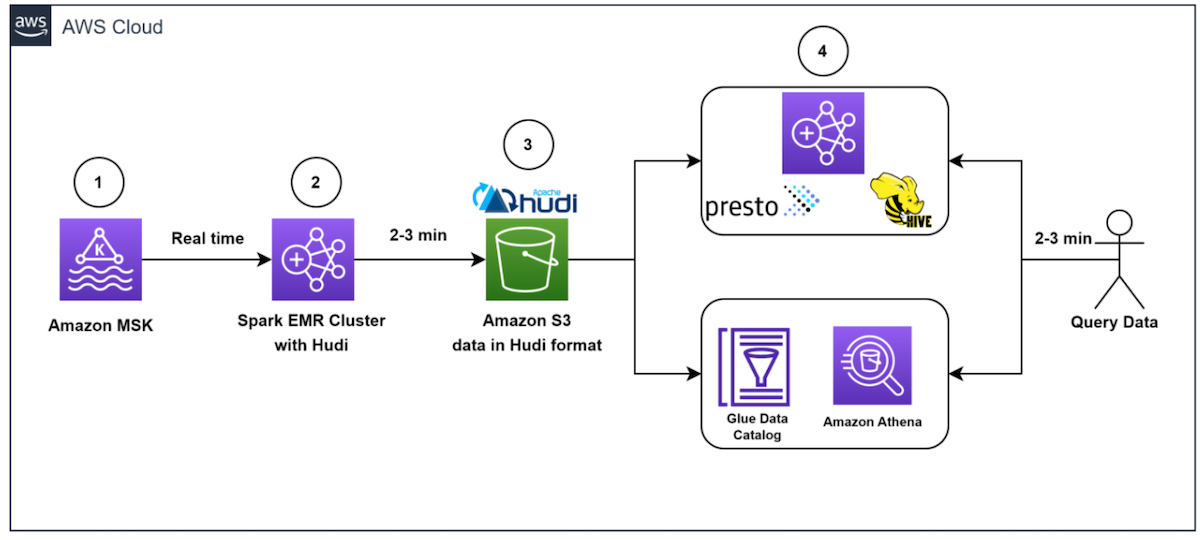
Use Apache Hudi tables in Athena for Spark
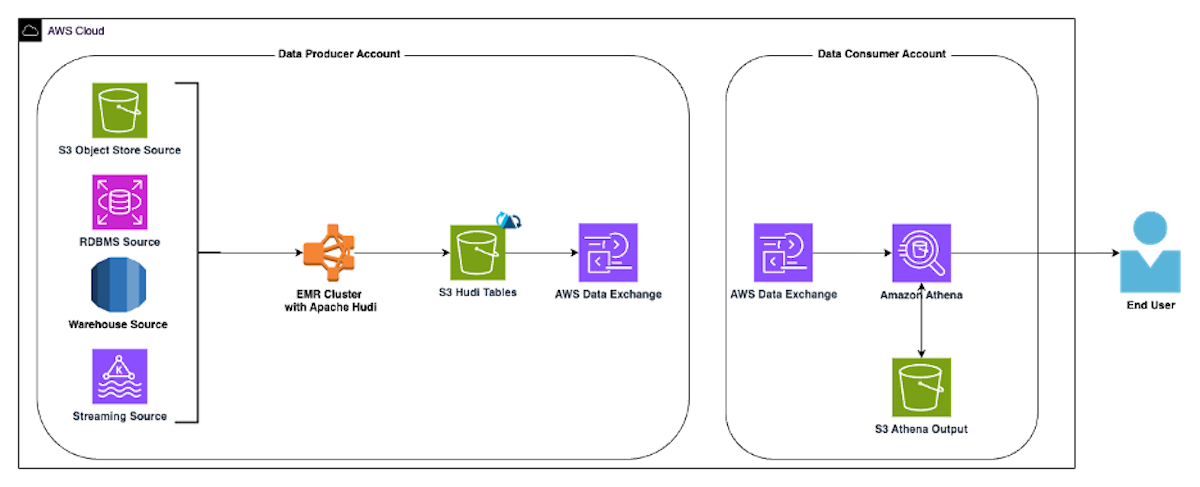
Use AWS Data Exchange to seamlessly share Apache Hudi datasets

Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for success

Tipico Facilitates Faster Data Access with a Modern Data Strategy on AWS
Load data incrementally from transactional data lakes to data warehouses
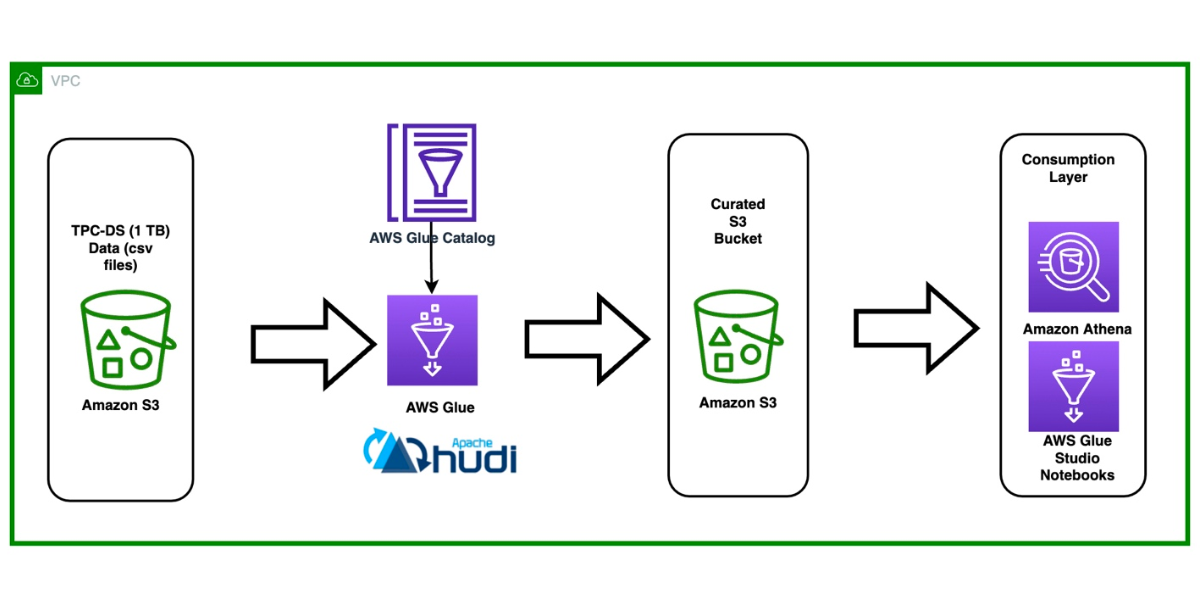
Get started with Apache Hudi using AWS Glue by implementing key design concepts – Part 1
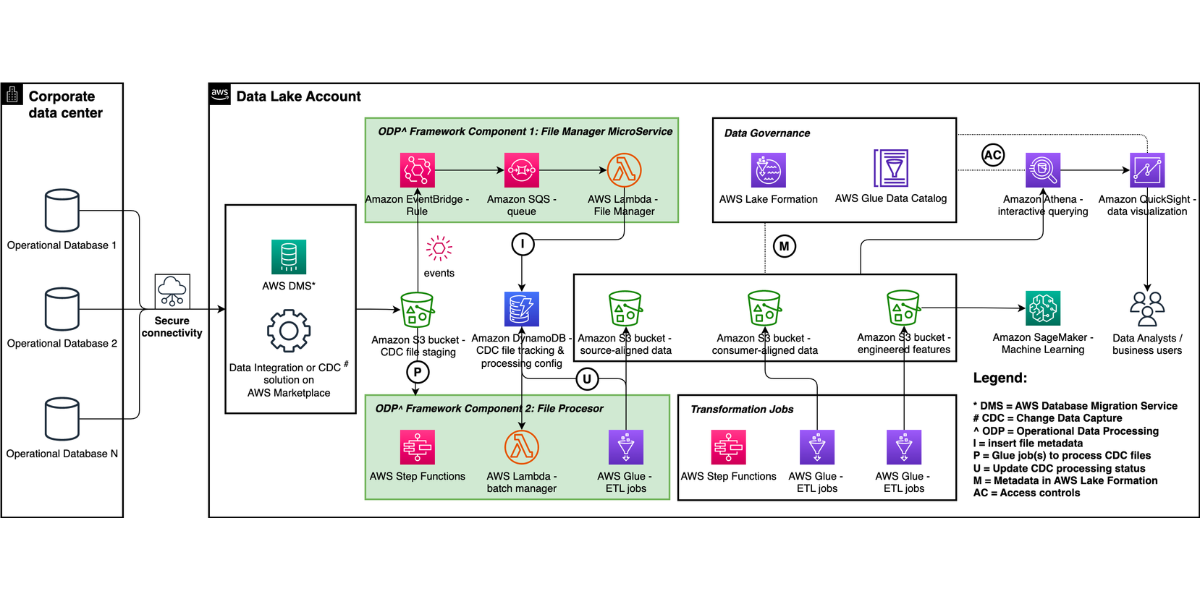
Simplify operational data processing in data lakes using AWS Glue and Apache Hudi
Create an Apache Hudi-based-near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight