Build Open Lakehouse using Apache Hudi & dbt
The focus of this blog is to show you how to build an open lakehouse leveraging incremental data processing and performing field-level updates. We are excited to announce that you can now use Apache Hudi + dbt for building open data lakehouses.
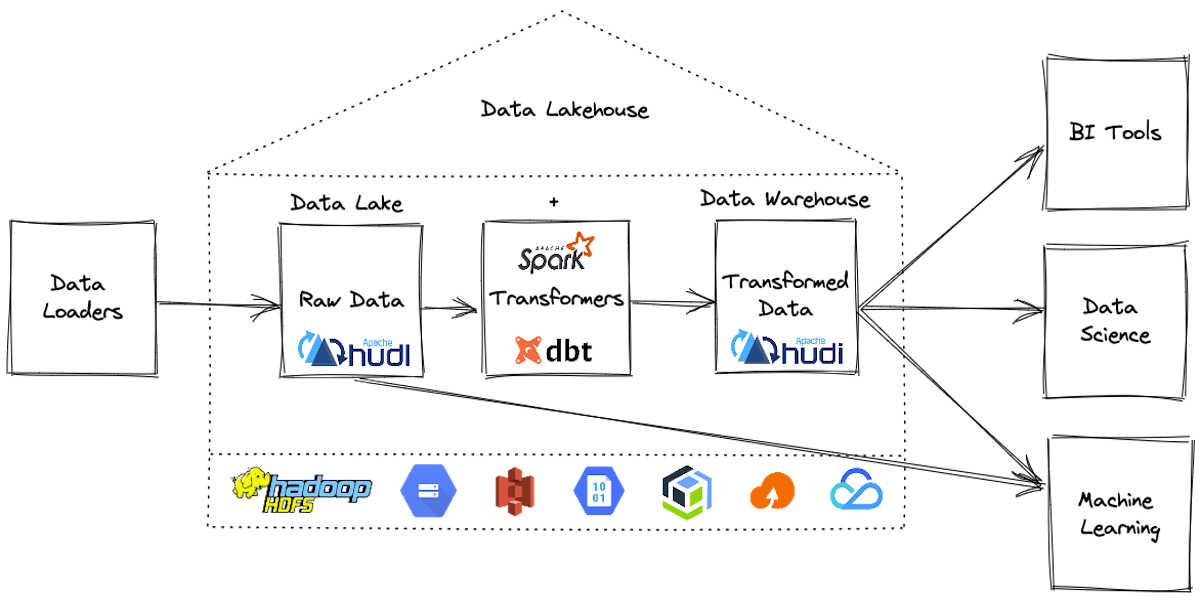
Let's first clarify a few terminologies used in this blog before we dive into the details.
What is Apache Hudi?
Apache Hudi brings ACID transactions, record-level updates/deletes, and change streams to data lakehouses.
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development. This framework more efficiently manages business requirements like data lifecycle and improves data quality.
What is dbt?
dbt (data build tool) is a data transformation tool that enables data analysts and engineers to transform, test, and document data in the cloud data warehouses.
dbt enables analytics engineers to transform data in their warehouses by simply writing select statements. dbt handles turning these select statements into tables and views.
dbt does the T in ELT (Extract, Load, Transform) processes – it doesn’t extract or load data, but it’s extremely good at transforming data that’s already loaded into your warehouse.
What is a Lakehouse?
A lakehouse is a new, open architecture that combines the best elements of data lakes and data warehouses. Lakehouses are enabled by a new system design: implementing transaction management and data management features similar to those in a data warehouse directly on top of low-cost cloud storage in open formats. They are what you would get if you had to redesign data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available.
In other words, while data lakes historically have been viewed as a bunch of files added to cloud storage folders, lakehouse tables support transactions, updates, deletes, and in the case of Apache Hudi, even database-like functionality like indexing or change capture.
How to build an open lakehouse?
Now, we know what is a lakehouse, so let's build one, In order to build an open lakehouse, you need a few components:
- Open table format which supports ACID transactions
- Apache Hudi (integrated with dbt)
- Delta Lake (proprietary features locked to Databricks runtime)
- Apache Iceberg (currently not integrated with dbt)
- Data transformation tool
- Open source dbt is the de-facto popular choice for transformation layer
- Distributed data processing engine
- Apache Spark is the de-facto popular choice for compute engine
- Cloud Storage
- You can choose any of the cost-effective cloud stores or HDFS
- Bring your favorite query engine
To build the lakehouse you need a way to extract and load the data into Hudi table format and then transform in-place using dbt.
DBT supports Hudi out of the box with the dbt-spark adapter package. When creating modeled datasets using dbt you can choose Hudi as the format for your tables.
You can follow the instructions on this page to learn how to install and configure dbt+hudi.
Step 1: How to extract & load the raw data datasets?
This is the first step in building your data lake and there are many choices here to load the data into our open lakehouse. I’m going to go with one of the Hudi’s native tools called Delta Streamer since all the ingestion features are pre-built and battle-tested in production at scale.
Hudi’s DeltaStreamer does the EL in ELT (Extract, Load, Transform) processes – it’s extremely good at extracting, loading, and optionally transforming data that’s already loaded into your lakehouse.
Step 2: How to configure hudi with the dbt project?
To use the Hudi with your dbt project, all you need to do is choose the file format as Hudi. The file format config can either be specified in specific models, or for all the models in your dbt_project.yml file:
models:
+file_format: hudi
or:
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
…
) }}
After choosing hudi as the file_format you can create materialized datasets using dbt, which offers additional benefits that are unique to the Hudi table format such as field-level upserts/deletes.
Step 3: How to read the raw data incrementally?
Before we learn how to build incremental materialization, let’s quickly learn, What are materializations in dbt? Materializations are strategies for persisting dbt models in a lakehouse. There are four types of materializations built into dbt. They are:
- table
- view
- incremental
- ephemeral
Among all the materialization types, only incremental models allow dbt to insert or update records into a table since the last time that dbt was run, which unlocks the powers of Hudi, we will dive into the details.
To use incremental models, you need to perform these two activities:
- Tell dbt how to filter the rows on the incremental executions
- Define the uniqueness constraint of the model (required when using >= Hudi 0.10.1 version)
How to apply filters on an incremental run?
dbt provides you a macro is_incremental() which is very useful to define the filters exclusively for incremental materializations.
Often, you'll want to filter for "new" rows, as in, rows that have been created since the last time dbt ran this model. The best way to find the timestamp of the most recent run of this model is by checking the most recent timestamp in your target table. dbt makes it easy to query your target table by using the "{}" variable.
{{
config(
materialized='incremental',
file_format='hudi',
)
}}
select
*
from raw_app_data.events
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where event_time > (select max(event_time) from {{ this }})
{% endif %}
How to define the uniqueness constraint?
A unique_key is the primary key of the dataset, which determines whether a record has new values and should be updated/deleted, or inserted.
You can define the unique_key in the configuration block at the top of your model. This unique_key will act as the primaryKey (hoodie.datasource.write.recordkey.field) on the hudi table.
Step 4: How to use the upsert feature while writing datasets?
dbt offers multiple load strategies when loading the transformed datasets, such as:
- append (default)
- insert_overwrite (optional)
- merge (optional, Only available for Hudi and Delta formats)
By default dbt uses the append strategy, which may cause duplicate rows when you execute dbt run command multiple times on the same payload.
When you choose the insert_overwrite strategy, dbt will overwrite the entire partition or full table load for every dbt run, which causes unnecessary overheads and is very expensive.
In addition to all the existing strategies to load the data, with hudi you can use the exclusive merge strategy when using incremental materialization. Using the merge strategy you can perform field-level updates/deletes on your data lakehouse which is performant and cost-efficient. As a result, you will get access to fresher data and accelerated insights.
How to perform field-level updates?
If you are using the merge strategy and have specified a unique_key, by default, dbt will entirely overwrite matched rows with new values.
Since Apache Spark adapter supports the merge strategy, you may optionally pass a list of column names to a merge_update_columns config. In that case, dbt will update only the columns specified by the config, and keep the previous values of other columns.
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
merge_update_columns = ['msg', 'updated_ts'],
) }}
How to configure additional hoodie custom configs?
When you want to specify additional hudi configs, you can do that with the options config:
{{ config(
materialized='incremental',
file_format='hudi',
incremental_strategy='merge',
options={
'type': 'mor',
'primaryKey': 'id',
'precombineKey': 'ts',
},
unique_key='id',
partition_by='datestr',
pre_hook=["set spark.sql.datetime.java8API.enabled=false;"],
)
}}
Hope you understood the benefits of using Apache Hudi with dbt to build your next open lakehouse, good luck!