Modernizing Upstox's Data Platform with Apache Hudi, dbt, and EMR Serverless
Introduction
In this community sharing session, Manish Gaurav from Upstox shared insights into the complexities of managing data ingestion at scale. Drawing from the company’s experience as a leading online trading platform in India, the discussion highlighted challenges around file-level upserts, ensuring atomic operations, and handling small files effectively. Upstox shared how they built a modern data platform using Apache Hudi and dbt to address these issues. In this blog post, we’ll break down their solution and why it matters.
Upstox is a leading online trading platform that enables millions of users to invest in equities, commodities, derivatives, and currencies. With over 12 million customers generating 300,000 data requests daily, the company's data team is responsible for delivering the real-time insights that power key products, including:
- Search functionality
- A customer service chatbot (powered by OpenAI)
- Personalized portfolio recommendations
Data Sources
Upstox ingests 250–300 GB of structured and semi-structured data per day from a variety of sources:
- Order and transaction data from exchanges
- Microservice telemetry from Cloudflare
- Customer support data from platforms like Freshdesk and SquadStack
- Behavioral analytics from Mixpanel
- Data from operational databases (MongoDB, MySQL, and MS SQL) via AWS DMS
The Challenges with Initial Data Platform
As Upstox grew, so did the complexity of its data operations. Here are some of the early bottlenecks the company faced:
Data Ingestion Issues
Prior to 2023, Upstox relied on no-code ingestion platforms like Hevo. While easy to adopt, these platforms introduced several limitations, including high licensing costs and a lack of fine-grained control over ingestion logic. File-level upserts required complex joins between incoming CDC (change data capture) datasets and target tables. Additionally, a lack of atomicity often led to inconsistent data writes, and small-file issues were rampant. To combat these problems, the team had to implement time-consuming re-partitioning and coalescing, along with complex salting strategies to distribute data evenly.
Downstream Consumption Struggles
Analytics queries were primarily served through Amazon Athena, which presented several key limitations. For instance, it frequently timed out when querying large datasets and often exceeded the maximum number of partitions it could handle. Additionally, Athena's lack of support for stored procedures made it challenging to manage and reuse complex query logic. Attempts to improve performance with bucketing often created more small files, and the lack of native support for incremental queries further complicated their analytics workflow.
The Modern Lakehouse Architecture
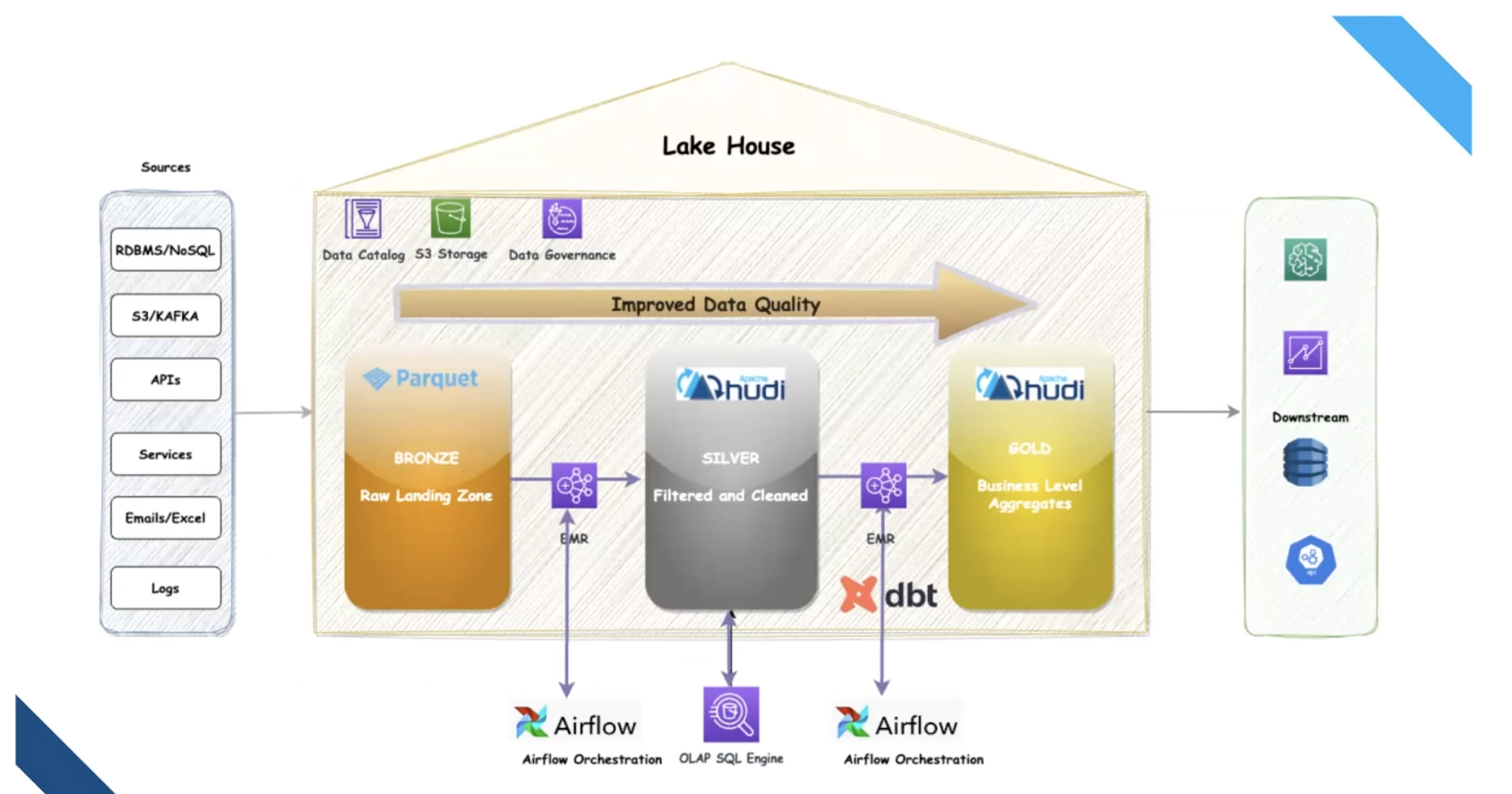
To tackle these problems, Upstox implemented a medallion architecture, organizing data into bronze, silver, and gold layers:
- Bronze (Raw Data): Data is ingested and stored in its raw format as Parquet files.
- Silver (Cleaned and Filtered): Data is cleaned, filtered, and stored in Apache Hudi tables, which are updated incrementally.
- Gold (Business-Ready): Data is aggregated for specific business use cases, modeled with dbt, and stored in Hudi.
The Solution: A Modern Stack with Hudi, dbt, and EMR Serverless
Upstox re-architected its platform using Apache Hudi as the core data lake technology, dbt for transformations, and EMR Serverless for scalable compute. Airflow was used to orchestrate the entire workflow. Here's how this new stack addressed their challenges:
Simplified Data Updates: Hudi provides built-in support for record-level upserts with atomic guarantees and snapshot isolation. This helped Upstox overcome the challenge of ensuring consistent updates to their fact and dimension tables.
Improved Upsert Performance: To optimize upsert performance, the team leveraged Bloom index, especially for transaction-heavy fact tables. Indexing strategies were chosen based on data characteristics to balance latency and efficiency.
Resolved Small-File Issues: Small files, which are common in streaming workloads, were mitigated using clustering jobs supported by Hudi. This process was scheduled to run weekly and ensured efficient file sizes and reduced storage overhead without manual intervention.
Enabled Incremental Processing: Incremental joins allowed Upstox to process only new data daily. This enabled timely updates to the aggregated tables in the gold layer that power user-facing dashboards—a task that was not feasible with traditional Athena queries.
Managed Metadata Growth: The accumulation of commit and metadata files in the Hudi table’s `.hoodie/` directory increased S3 listing costs and slowed down operations. Hudi's archival feature helped manage this by archiving older commits after a certain threshold, keeping metadata lean and efficient.
Streamlined Data Modeling: The team used dbt on EMR Serverless to create materialized views over the Hudi datasets. This enabled the creation of efficient transformation layers (silver and gold) using familiar SQL workflows and managed compute.
Flexible Data Materialization: dbt supported a variety of model types, including tables, views, and ephemeral models (Common Table Expressions, or CTEs). This gave teams the flexibility to optimize for performance, reuse, or simplicity, depending on the use case.
Out-of-the-Box Lineage and Documentation: dbt helps visualize how data flows from one table to another, making it easier to debug and understand dependencies. The glossary feature allows teams to document column meanings and transformations clearly.
Enforced Data Quality: With dbt, specific data quality rules can be added to individual tables or pipelines. This adds an extra layer of validation beyond the basic checks performed during data ingestion.
CI/CD and Orchestration
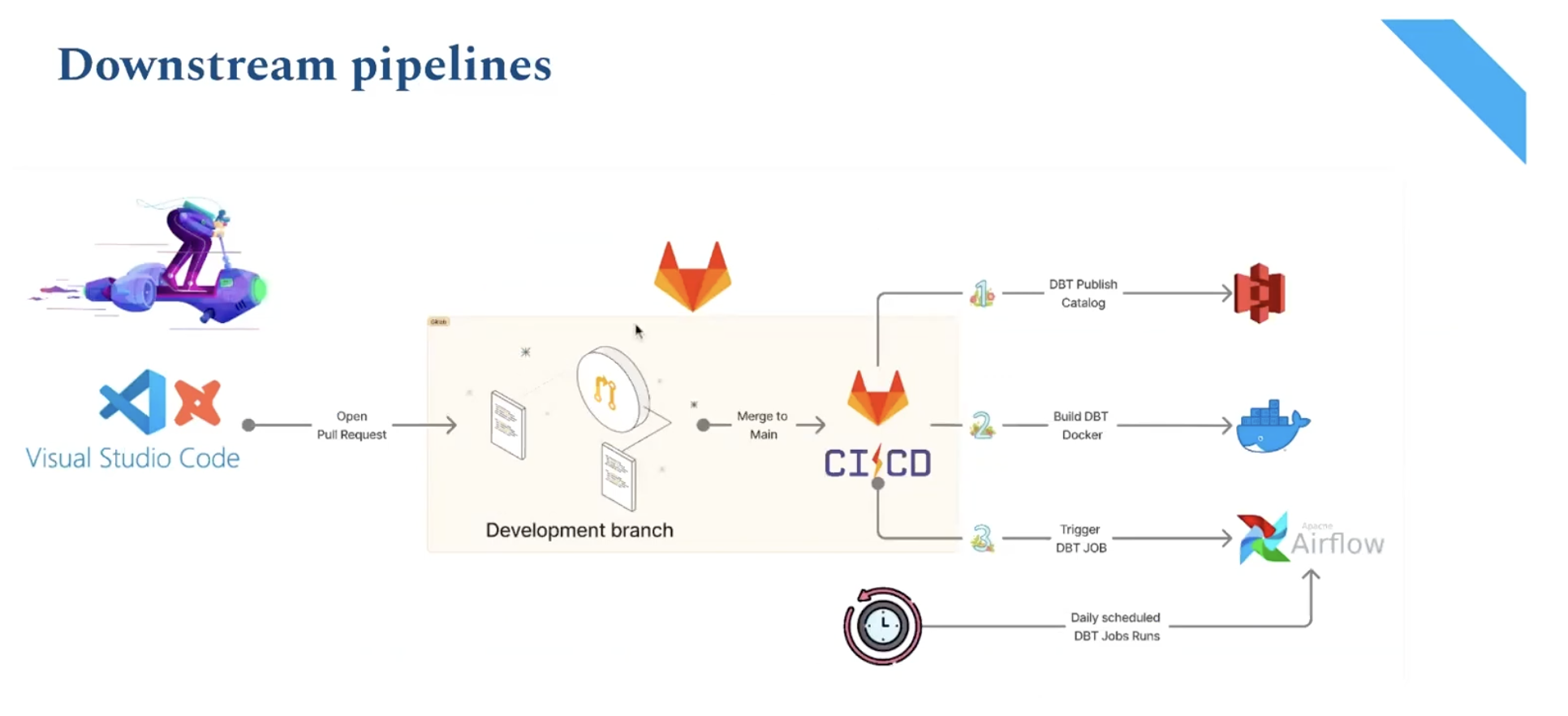
Upstox uses Apache Airflow for orchestration, with dbt pipelines deployed via a Git-based CI/CD process. Merging a pull request in GitLab triggers the CI/CD pipeline, which automatically builds a new dbt image and publishes the updated data catalog. Airflow then runs the corresponding dbt jobs daily or on-demand, automating the entire transformation workflow.
The Impact
The adoption of this modern data stack had a significant impact on Upstox's data platform. The company achieved extremely high data availability and consistency for critical datasets, reducing SLA breaches for complex joins by 70%. Furthermore, pipeline costs dropped by 40%, and query performance improved drastically thanks to Hudi's clustering and optimized joins.
Conclusion
By leveraging Apache Hudi, dbt, and EMR Serverless, Upstox built a robust and cost-efficient data platform to serve its 12M+ customers, overcoming the significant challenges of data ingestion and analytics at scale. This transformation resolved critical issues like inconsistent data writes, small-file problems, and query timeouts, leading to tangible improvements in both performance and efficiency. With a 70% reduction in SLA breaches and a 40% drop in pipeline costs, the new architecture has empowered their BI and ML teams to move faster. Ultimately, this success story demonstrates how a modern data stack can not only solve immediate technical bottlenecks but also lay the groundwork for a scalable, self-service future that enables continued innovation.