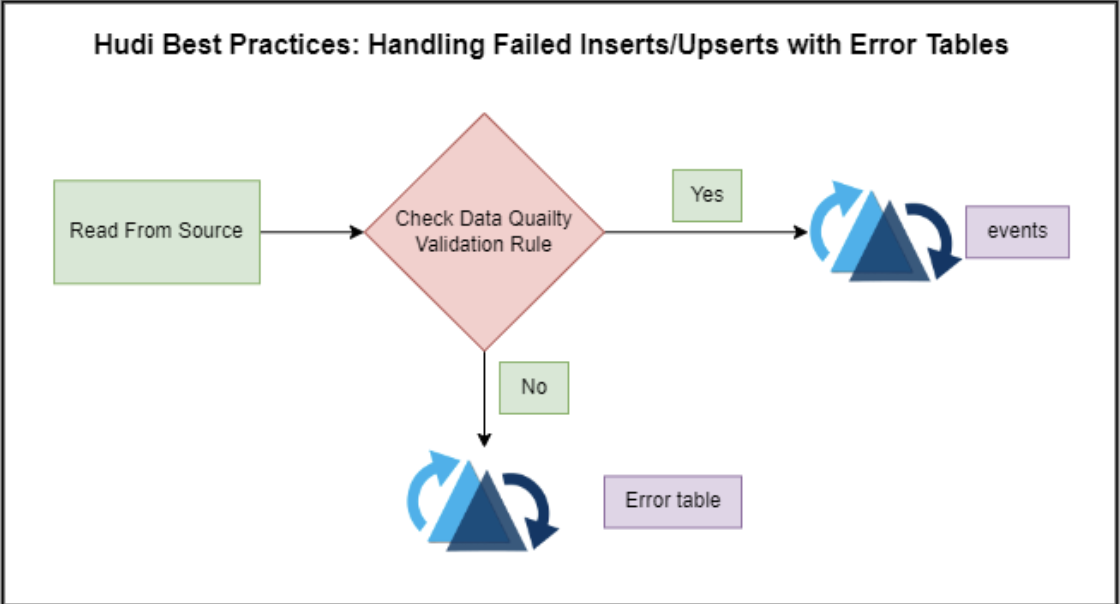

Monitoring Table Size stats

What about Apache Hudi, Apache Iceberg, and Delta Lake?

Unlimited Big Data Exchange: A Wonderful Review of Apache DolphinScheduler & Hudi Hangzhou Meetup
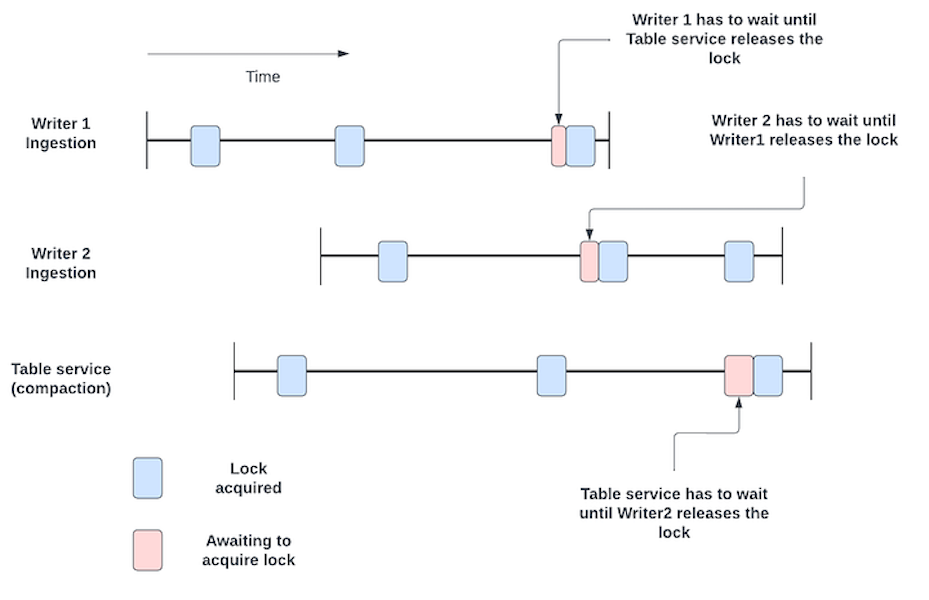
Multi-writer support with Apache Hudi

How to query data in Apache Hudi using StarRocks
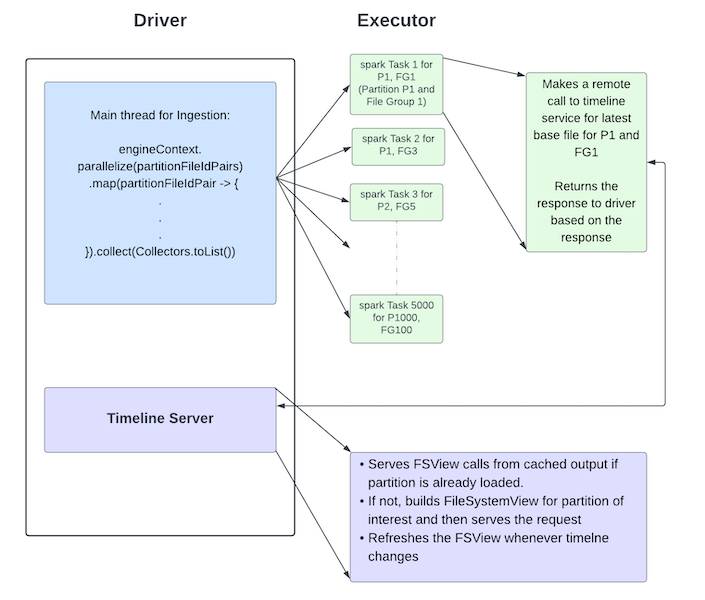
Timeline Server in Apache Hudi

Exploring New Frontiers: How Apache Flink, Apache Hudi and Presto Power New Insights at Scale
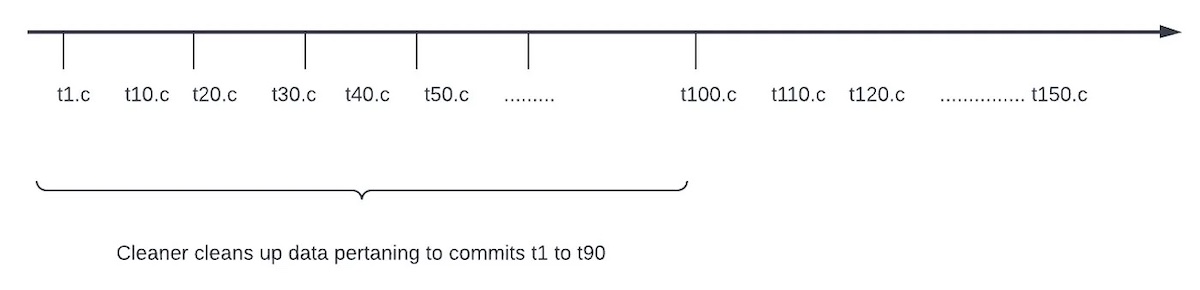
Cleaner and Archival in Apache Hudi

Text-Based Search: From Elastic Search to Vector Search
Different Query types with Apache Hudi
