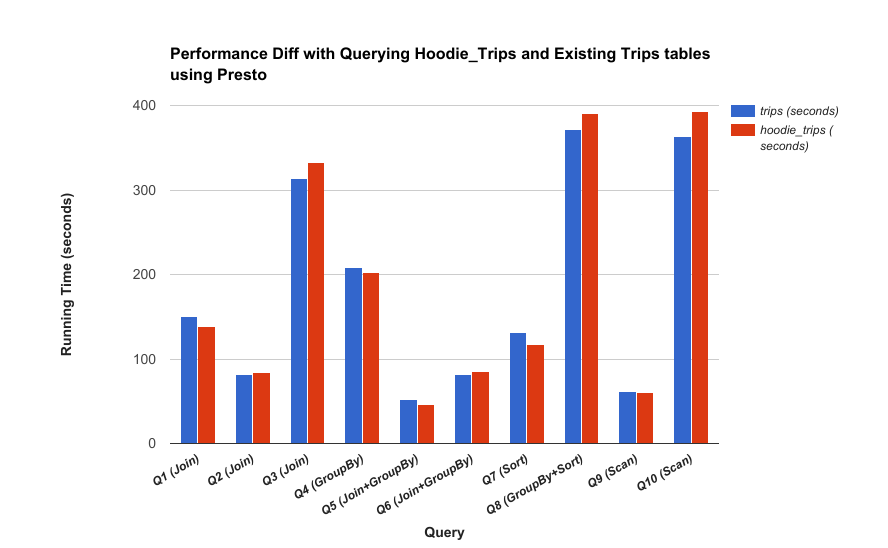
Performance
Optimized DFS Access
Hudi also performs several key storage management functions on the data stored in a Hudi table. A key aspect of storing data on DFS is managing file sizes and counts and reclaiming storage space. For e.g HDFS is infamous for its handling of small files, which exerts memory/RPC pressure on the Name Node and can potentially destabilize the entire cluster. In general, query engines provide much better performance on adequately sized columnar files, since they can effectively amortize cost of obtaining column statistics etc. Even on some cloud data stores, there is often cost to listing directories with large number of small files.
Here are some ways to efficiently manage the storage of your Hudi tables.
- The small file handling feature in Hudi, profiles incoming workload and distributes inserts to existing file groups instead of creating new file groups, which can lead to small files.
- Cleaner can be configured to clean up older file slices, more or less aggressively depending on maximum time for queries to run & lookback needed for incremental pull
- User can also tune the size of the base/parquet file, log files & expected compression ratio, such that sufficient number of inserts are grouped into the same file group, resulting in well sized base files ultimately.
- Intelligently tuning the bulk insert parallelism, can again in nicely sized initial file groups. It is in fact critical to get this right, since the file groups once created cannot be deleted, but simply expanded as explained before.
- For workloads with heavy updates, the merge-on-read table provides a nice mechanism for ingesting quickly into smaller files and then later merging them into larger base files via compaction.
Performance Gains
In this section, we go over some real world performance numbers for Hudi upserts, incremental pull and compare them against the conventional alternatives for achieving these tasks.
Upserts
Following shows the speed up obtained for NoSQL database ingestion, from incrementally upserting on a Hudi table on the copy-on-write storage, on 5 tables ranging from small to huge (as opposed to bulk loading the tables)
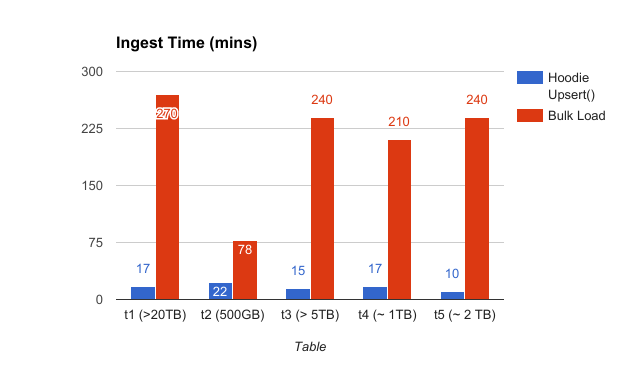
Given Hudi can build the table incrementally, it opens doors for also scheduling ingesting more frequently thus reducing latency, with significant savings on the overall compute cost.
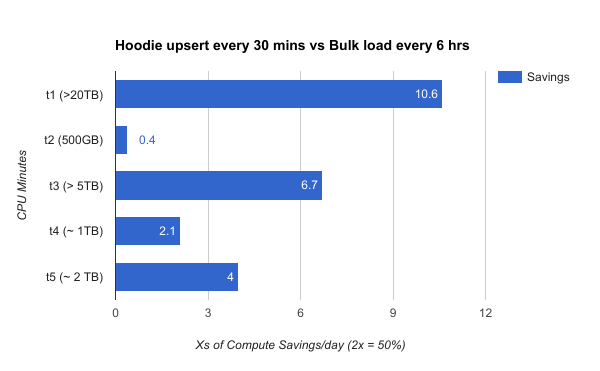
Hudi upserts have been stress tested upto 4TB in a single commit across the t1 table. See here for some tuning tips.
Indexing
In order to efficiently upsert data, Hudi needs to classify records in a write batch into inserts & updates (tagged with the file group it belongs to). In order to speed this operation, Hudi employs a pluggable index mechanism that stores a mapping between recordKey and the file group id it belongs to. By default, Hudi uses a built in index that uses file ranges and bloom filters to accomplish this, with upto 10x speed up over a spark join to do the same.
Hudi provides best indexing performance when you model the recordKey to be monotonically increasing (e.g timestamp prefix), leading to range pruning filtering out a lot of files for comparison. Even for UUID based keys, there are known techniques to achieve this. For e.g , with 100M timestamp prefixed keys (5% updates, 95% inserts) on a event table with 80B keys/3 partitions/11416 files/10TB data, Hudi index achieves a ~7X (2880 secs vs 440 secs) speed up over vanilla spark join. Even for a challenging workload like an '100% update' database ingestion workload spanning 3.25B UUID keys/30 partitions/6180 files using 300 cores, Hudi indexing offers a 80-100% speedup.
Snapshot Queries
The major design goal for snapshot queries is to achieve the latency reduction & efficiency gains in previous section, with no impact on queries. Following charts compare the Hudi vs non-Hudi tables across Hive/Presto/Spark queries and demonstrate this.
Hive
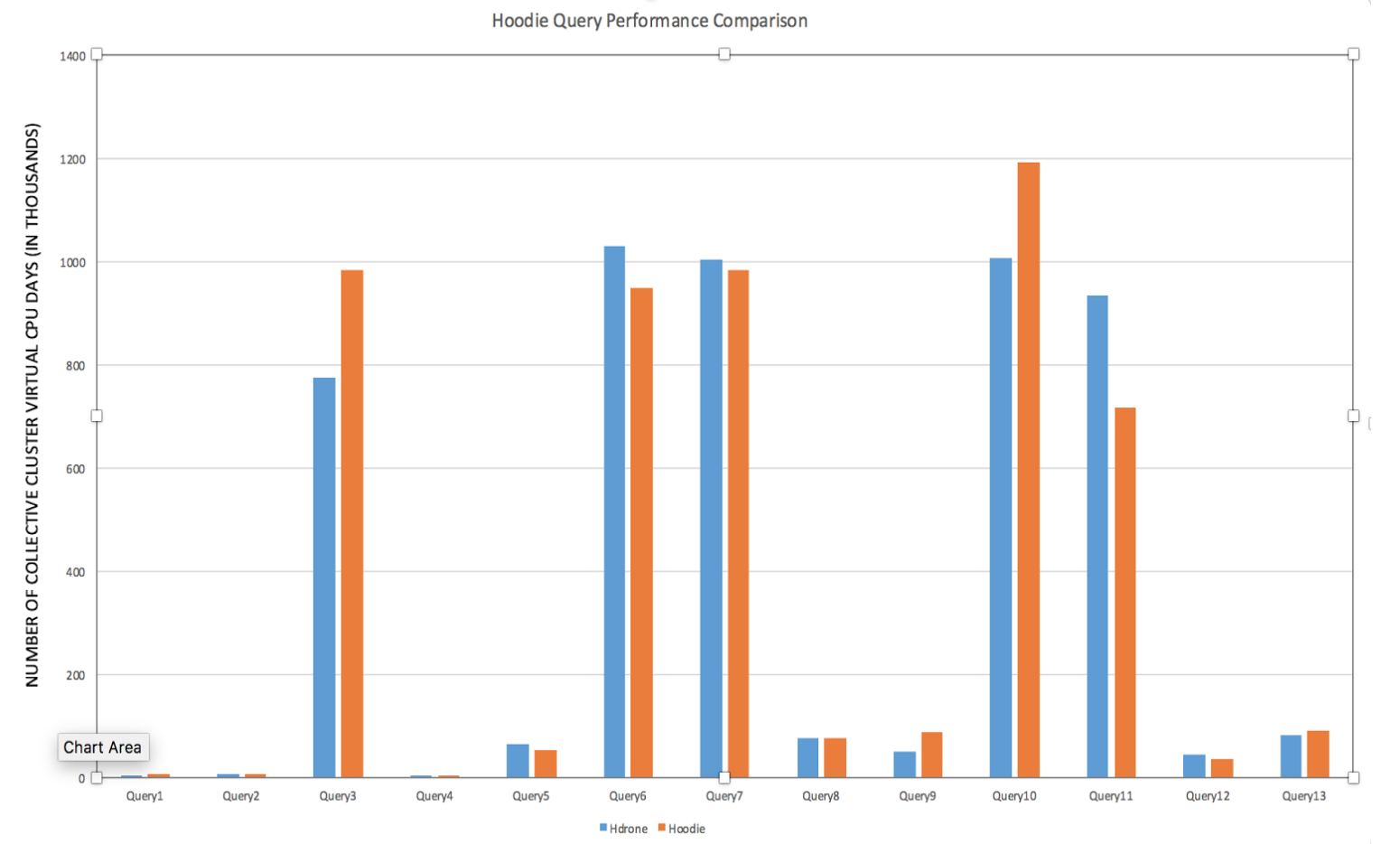
Spark
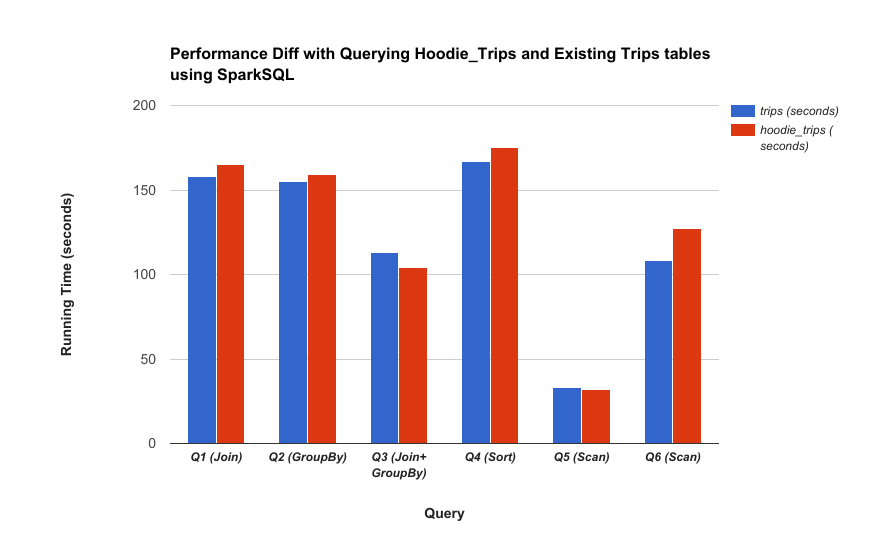
Presto