性能
在本节中,我们将介绍一些有关Hudi插入更新、增量提取的实际性能数据,并将其与实现这些任务的其它传统工具进行比较。
插入更新
下面显示了从NoSQL数据库摄取获得的速度提升,这些速度提升数据是通过在写入时复制存储上的Hudi数据集上插入更新而获得的, 数据集包括5个从小到大的表(相对于批量加载表)。
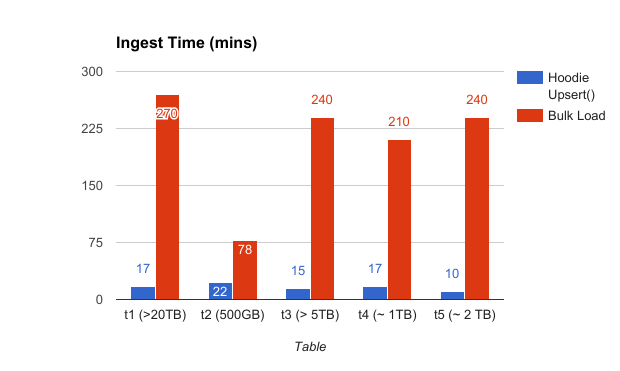
由于Hudi可以通过增量构建数据集,它也为更频繁地调度摄取提供了可能性,从而减少了延迟,并显著节省了总体计算成本。
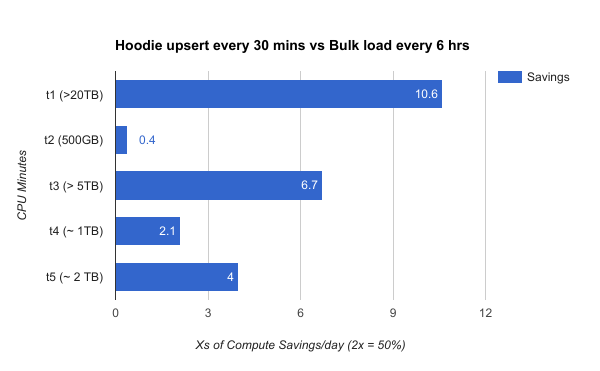
Hudi插入更新在t1表的一次提交中就进行了高达4TB的压力测试。 有关一些调优技巧,请参见这里。
索引
为了有效地插入更新数据,Hudi需要将要写入的批量数据中的记录分类为插入和更新(并标记它所属的文件组)。 为了加快此操作的速度,Hudi采用了可插拔索引机制,该机制存储了recordKey和它所属的文件组ID之间的映射。 默认情况下,Hudi使用内置索引,该索引使用文件范围和布隆过滤器来完成此任务,相比于Spark Join,其速度最高可提高10倍。
当您将recordKey建模为单调递增时(例如时间戳前缀),Hudi提供了最佳的索引性能,从而进行范围过滤来避免与许多文件进行比较。 即使对于基于UUID的键,也有已知技术来达到同样目的。 例如,在具有80B键、3个分区、11416个文件、10TB数据的事件表上使用100M个时间戳前缀的键(5%的更新,95%的插入)时, 相比于原始Spark Join,Hudi索引速度的提升约为7倍(440秒相比于2880秒)。 即使对于具有挑战性的工作负载,如使用300个核对3.25B UUID键、30个分区、6180个文件的“100%更新”的数�据库摄取工作负载,Hudi索引也可以提供80-100%的加速。
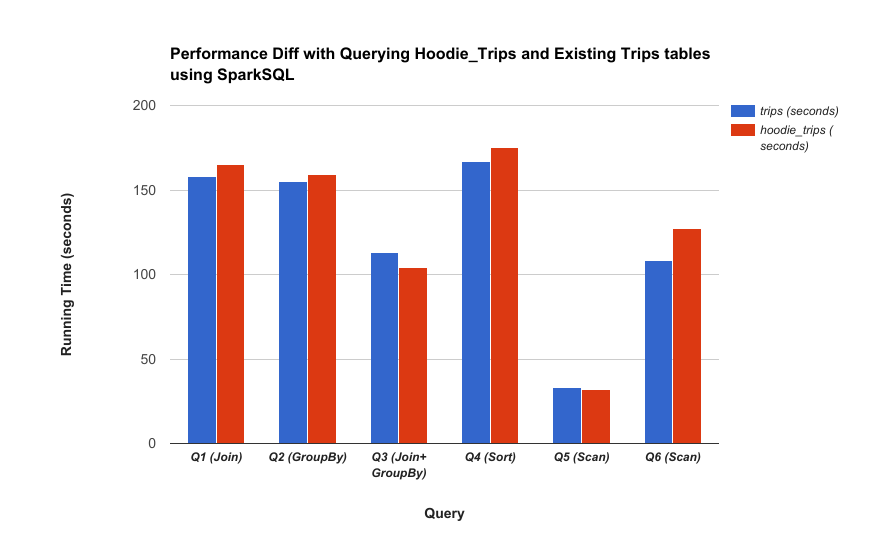
读优化查询
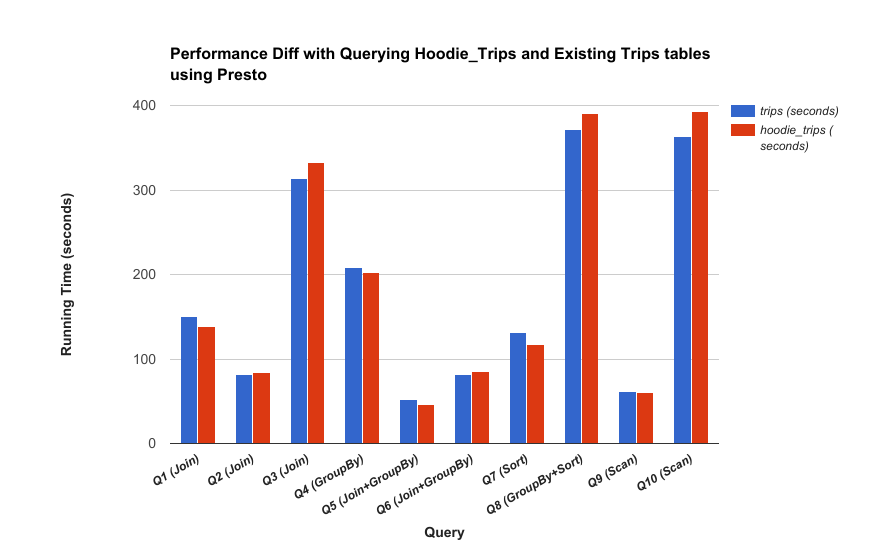
读优化视图的主要设计目标是在不影响查询的情况下实现上一节中提到的延迟减少和效率提高。 下图比较了对Hudi和非Hudi数据集的Hive、Presto、Spark查询,并对此进行说明。
Hive
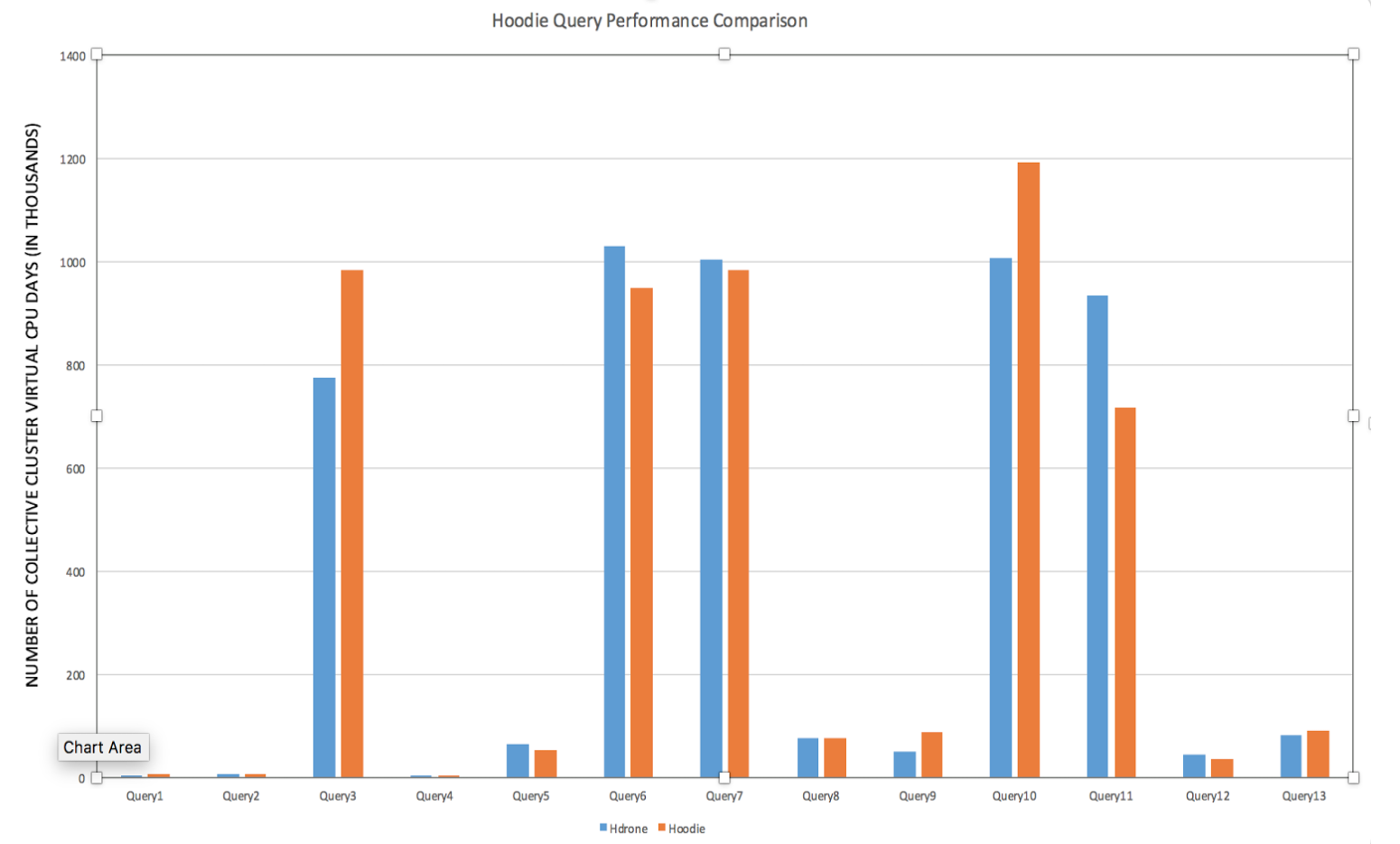
Spark
Presto