Clustering
Background
Apache Hudi brings stream processing to big data, providing fresh data while being an order of magnitude efficient over traditional batch processing. In a data lake/warehouse, one of the key trade-offs is between ingestion speed and query performance. Data ingestion typically prefers small files to improve parallelism and make data available to queries as soon as possible. However, query performance degrades poorly with a lot of small files. Also, during ingestion, data is typically co-located based on arrival time. However, the query engines perform better when the data frequently queried is co-located together. In most architectures each of these systems tend to add optimizations independently to improve performance which hits limitations due to un-optimized data layouts. This doc introduces a new kind of table service called clustering [RFC-19] to reorganize data for improved query performance without compromising on ingestion speed.
Clustering Architecture
At a high level, Hudi provides different operations such as insert/upsert/bulk_insert through it’s write client API to be able to write data to a Hudi table. To be able to choose a trade-off between file size and ingestion speed, Hudi provides a knob hoodie.parquet.small.file.limit to be able to configure the smallest allowable file size. Users are able to configure the small file soft limit to 0 to force new data to go into a new set of filegroups or set it to a higher value to ensure new data gets “padded” to existing files until it meets that limit that adds to ingestion latencies.
To be able to support an architecture that allows for fast ingestion without compromising query performance, we have introduced a ‘clustering’ service to rewrite the data to optimize Hudi data lake file layout.
Clustering table service can run asynchronously or synchronously adding a new action type called “REPLACE”, that will mark the clustering action in the Hudi metadata timeline.
Overall, there are 2 parts to clustering
- Scheduling clustering: Create a clustering plan using a pluggable clustering strategy.
- Execute clustering: Process the plan using an execution strategy to create new files and replace old files.
Scheduling clustering
Following steps are followed to schedule clustering.
- Identify files that are eligible for clustering: Depending on the clustering strategy chosen, the scheduling logic will identify the files eligible for clustering.
- Group files that are eligible for clustering based on specific criteria. Each group is expected to have data size in multiples of ‘targetFileSize’. Grouping is done as part of ‘strategy’ defined in the plan. Additionally, there is an option to put a cap on group size to improve parallelism and avoid shuffling large amounts of data.
- Finally, the clustering plan is saved to the timeline in an avro metadata format.
Running clustering
- Read the clustering plan and get the ‘clusteringGroups’ that mark the file groups that need to be clustered.
- For each group, we instantiate appropriate strategy class with strategyParams (example: sortColumns) and apply that strategy to rewrite the data.
- Create a “REPLACE” commit and update the metadata in HoodieReplaceCommitMetadata.
Clustering Service builds on Hudi’s MVCC based design to allow for writers to continue to insert new data while clustering action runs in the background to reformat data layout, ensuring snapshot isolation between concurrent readers and writers.
NOTE: Clustering can only be scheduled for tables / partitions not receiving any concurrent updates. In the future, concurrent updates use-case will be supported as well.
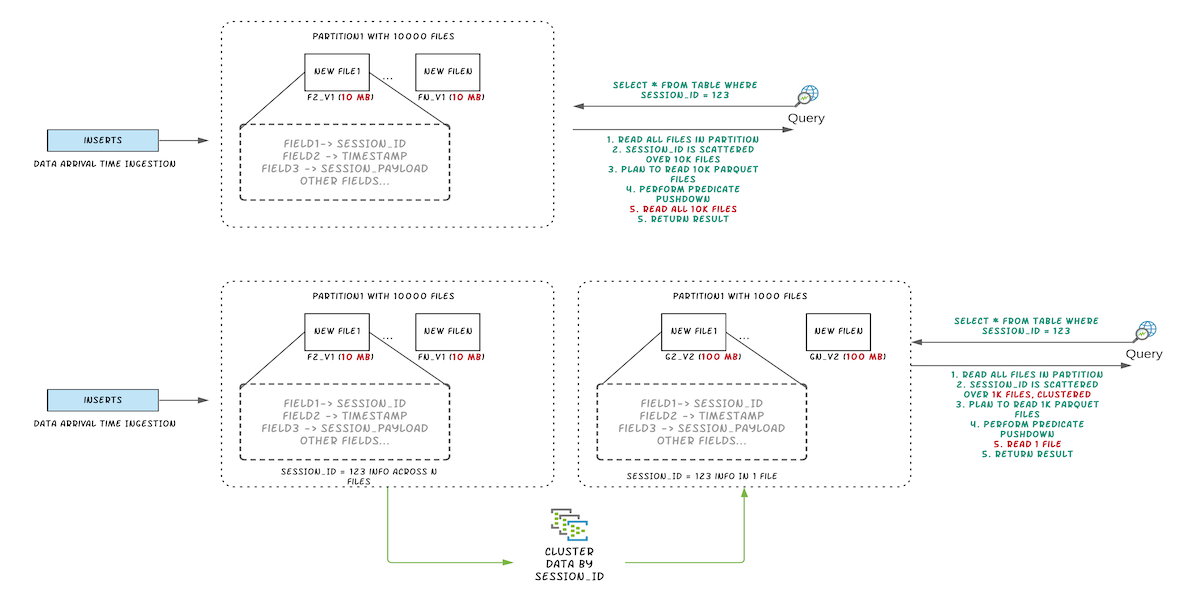 Figure: Illustrating query performance improvements by clustering
Figure: Illustrating query performance improvements by clustering
Setting up clustering
Inline clustering can be setup easily using spark dataframe options. See sample below
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val df = //generate data frame
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, "tableName").
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "4").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "column1,column2"). //optional, if sorting is needed as part of rewriting data
mode(Append).
save("dfs://location");
Async Clustering - Strategies
For more advanced usecases, async clustering pipeline can also be setup. See an example here.
On a high level, clustering creates a plan based on a configurable strategy, groups eligible files based on specific criteria and then executes the plan. Hudi supports multi-writers which provides snapshot isolation between multiple table services, thus allowing writers to continue with ingestion while clustering runs in the background.
As mentioned before, clustering plan as well as execution depends on configurable strategy. These strategies can be broadly classified into three types: clustering plan strategy, execution strategy and update strategy.
Plan Strategy
This strategy comes into play while creating clustering plan. It helps to decide what file groups should be clustered. Let's look at different plan strategies that are available with Hudi. Note that these strategies are easily pluggable using this config.
SparkSizeBasedClusteringPlanStrategy: It selects file slices based on the small file limit of base files and creates clustering groups upto max file size allowed per group. The max size can be specified using this config. This strategy is useful for stitching together medium-sized files into larger ones to reduce lot of files spread across cold partitions.SparkRecentDaysClusteringPlanStrategy: It looks back previous 'N' days partitions and creates a plan that will cluster the 'small' file slices within those partitions. This is the default strategy. It could be useful when the workload is predictable and data is partitioned by time.SparkSelectedPartitionsClusteringPlanStrategy: In case you want to cluster only specific partitions within a range, no matter how old or new are those partitions, then this strategy could be useful. To use this strategy, one needs to set below two configs additionally (both begin and end partitions are inclusive):
hoodie.clustering.plan.strategy.cluster.begin.partition
hoodie.clustering.plan.strategy.cluster.end.partition
All the strategies are partition-aware and the latter two are still bound by the size limits of the first strategy.
Execution Strategy
After building the clustering groups in the planning phase, Hudi applies execution strategy, for each group, primarily based on sort columns and size. The strategy can be specified using this config.
SparkSortAndSizeExecutionStrategy is the default strategy. Users can specify the columns to sort the data by, when
clustering using
this config. Apart from
that, we can also set max file size
for the parquet files produced due to clustering. The strategy uses bulk insert to write data into new files, in which
case, Hudi implicitly uses a partitioner that does sorting based on specified columns. In this way, the strategy changes
the data layout in a way that not only improves query performance but also balance rewrite overhead automatically.
Now this strategy can be executed either as a single spark job or multiple jobs depending on number of clustering groups
created in the planning phase. By default, Hudi will submit multiple spark jobs and union the results. In case you want
to force Hudi to use single spark job, set the execution strategy
class config
to SingleSparkJobExecutionStrategy.
Update Strategy
Currently, clustering can only be scheduled for tables/partitions not receiving any concurrent updates. By default, the config for update strategy is set to SparkRejectUpdateStrategy. If some file group has updates during clustering then it will reject updates and throw an exception. However, in some use-cases updates are very sparse and do not touch most file groups. The default strategy to simply reject updates does not seem fair. In such use-cases, users can set the config to SparkAllowUpdateStrategy.
We discussed the critical strategy configurations. All other configurations related to clustering are listed here. Out of this list, a few configurations that will be very useful are:
| Config key | Remarks | Default |
|---|---|---|
hoodie.clustering.async.enabled | Enable running of clustering service, asynchronously as writes happen on the table. | False |
hoodie.clustering.async.max.commits | Control frequency of async clustering by specifying after how many commits clustering should be triggered. | 4 |
hoodie.clustering.preserve.commit.metadata | When rewriting data, preserves existing _hoodie_commit_time. This means users can run incremental queries on clustered data without any side-effects. | False |
Asynchronous Clustering
Users can leverage HoodieClusteringJob to setup 2-step asynchronous clustering.
HoodieClusteringJob
By specifying the scheduleAndExecute mode both schedule as well as clustering can be achieved in the same step.
The appropriate mode can be specified using -mode or -m option. There are three modes:
schedule: Make a clustering plan. This gives an instant which can be passed in execute mode.execute: Execute a clustering plan at a particular instant. If no instant-time is specified, HoodieClusteringJob will execute for the earliest instant on the Hudi timeline.scheduleAndExecute: Make a clustering plan first and execute that plan immediately.
Note that to run this job while the original writer is still running, please enable multi-writing:
hoodie.write.concurrency.mode=optimistic_concurrency_control
hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider
A sample spark-submit command to setup HoodieClusteringJob is as below:
spark-submit \
--class org.apache.hudi.utilities.HoodieClusteringJob \
/path/to/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.9.0-SNAPSHOT.jar \
--props /path/to/config/clusteringjob.properties \
--mode scheduleAndExecute \
--base-path /path/to/hudi_table/basePath \
--table-name hudi_table_schedule_clustering \
--spark-memory 1g
A sample clusteringjob.properties file:
hoodie.clustering.async.enabled=true
hoodie.clustering.async.max.commits=4
hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824
hoodie.clustering.plan.strategy.small.file.limit=629145600
hoodie.clustering.execution.strategy.class=org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
hoodie.clustering.plan.strategy.sort.columns=column1,column2
HoodieDeltaStreamer
This brings us to our users' favorite utility in Hudi. Now, we can trigger asynchronous clustering with DeltaStreamer.
Just set the hoodie.clustering.async.enabled config to true and specify other clustering config in properties file
whose location can be pased as —props when starting the deltastreamer (just like in the case of HoodieClusteringJob).
A sample spark-submit command to setup HoodieDeltaStreamer is as below:
spark-submit \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
/path/to/hudi-utilities-bundle/target/hudi-utilities-bundle_2.12-0.9.0-SNAPSHOT.jar \
--props /path/to/config/clustering_kafka.properties \
--schemaprovider-class org.apache.hudi.utilities.schema.SchemaRegistryProvider \
--source-class org.apache.hudi.utilities.sources.AvroKafkaSource \
--source-ordering-field impresssiontime \
--table-type COPY_ON_WRITE \
--target-base-path /path/to/hudi_table/basePath \
--target-table impressions_cow_cluster \
--op INSERT \
--hoodie-conf hoodie.clustering.async.enabled=true \
--continuous
Spark Structured Streaming
We can also enable asynchronous clustering with Spark structured streaming sink as shown below.
val commonOpts = Map(
"hoodie.insert.shuffle.parallelism" -> "4",
"hoodie.upsert.shuffle.parallelism" -> "4",
DataSourceWriteOptions.RECORDKEY_FIELD.key -> "_row_key",
DataSourceWriteOptions.PARTITIONPATH_FIELD.key -> "partition",
DataSourceWriteOptions.PRECOMBINE_FIELD.key -> "timestamp",
HoodieWriteConfig.TBL_NAME.key -> "hoodie_test"
)
def getAsyncClusteringOpts(isAsyncClustering: String,
clusteringNumCommit: String,
executionStrategy: String):Map[String, String] = {
commonOpts + (DataSourceWriteOptions.ASYNC_CLUSTERING_ENABLE.key -> isAsyncClustering,
HoodieClusteringConfig.ASYNC_CLUSTERING_MAX_COMMITS.key -> clusteringNumCommit,
HoodieClusteringConfig.EXECUTION_STRATEGY_CLASS_NAME.key -> executionStrategy
)
}
def initStreamingWriteFuture(hudiOptions: Map[String, String]): Future[Unit] = {
val streamingInput = // define the source of streaming
Future {
println("streaming starting")
streamingInput
.writeStream
.format("org.apache.hudi")
.options(hudiOptions)
.option("checkpointLocation", basePath + "/checkpoint")
.mode(Append)
.start()
.awaitTermination(10000)
println("streaming ends")
}
}
def structuredStreamingWithClustering(): Unit = {
val df = //generate data frame
val hudiOptions = getClusteringOpts("true", "1", "org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy")
val f1 = initStreamingWriteFuture(hudiOptions)
Await.result(f1, Duration.Inf)
}