Troubleshooting
Troubleshooting
Section below generally aids in debugging Hudi failures. Off the bat, the following metadata is added to every record to help triage issues easily using standard Hadoop SQL engines (Hive/PrestoDB/Spark)
- _hoodie_record_key - Treated as a primary key within each DFS partition, basis of all updates/inserts
- _hoodie_commit_time - Last commit that touched this record
- _hoodie_file_name - Actual file name containing the record (super useful to triage duplicates)
- _hoodie_partition_path - Path from basePath that identifies the partition containing this record
For performance related issues, please refer to the tuning guide
Missing records
Please check if there were any write errors using the admin commands above, during the window at which the record could have been written. If you do find errors, then the record was not actually written by Hudi, but handed back to the application to decide what to do with it.
Duplicates
First of all, please confirm if you do indeed have duplicates AFTER ensuring the query is accessing the Hudi table properly .
- If confirmed, please use the metadata fields above, to identify the physical files & partition files containing the records .
- If duplicates span files across partitionpath, then this means your application is generating different partitionPaths for same recordKey, Please fix your app
- if duplicates span multiple files within the same partitionpath, please engage with mailing list. This should not happen. You can use the
records deduplicatecommand to fix your data.
Spark failures
Typical upsert() DAG looks like below. Note that Hudi client also caches intermediate RDDs to intelligently profile workload and size files and spark parallelism. Also Spark UI shows sortByKey twice due to the probe job also being shown, nonetheless its just a single sort.
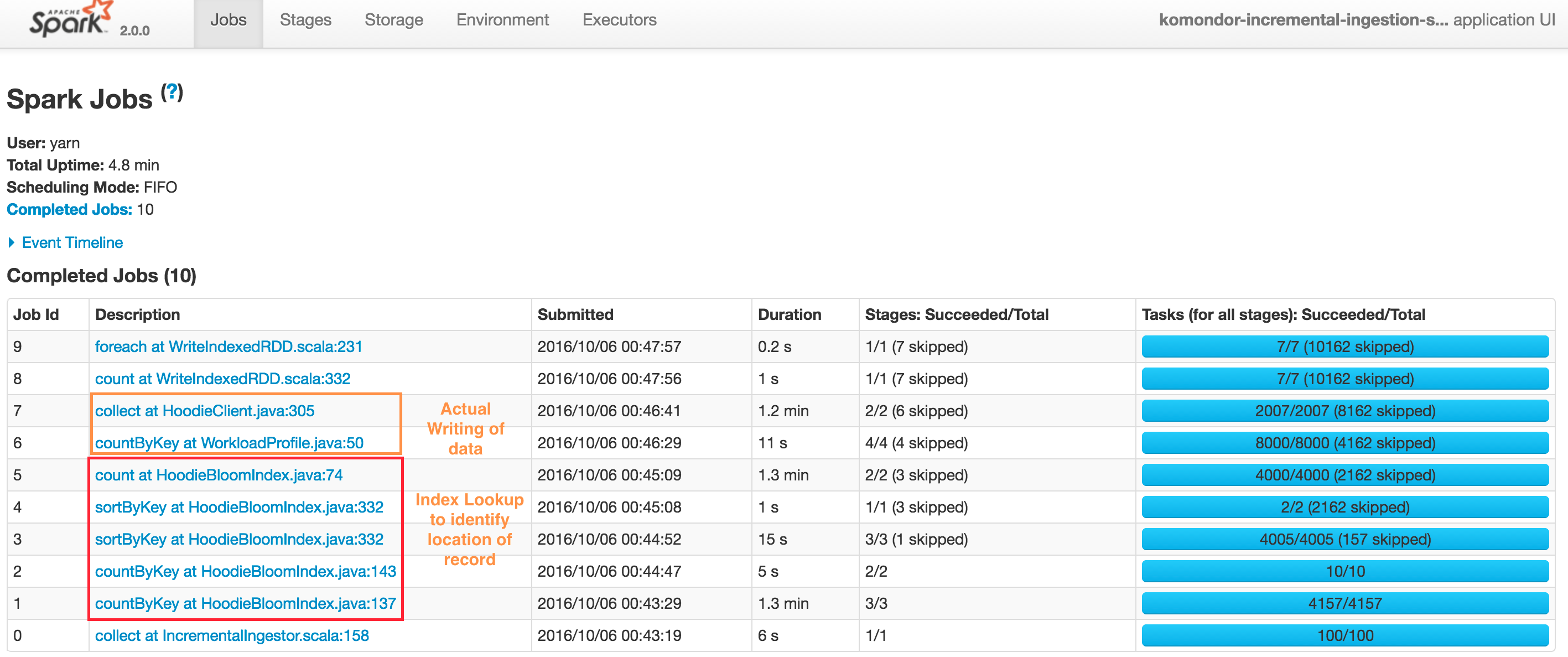
At a high level, there are two steps
Index Lookup to identify files to be changed
- Job 1 : Triggers the input data read, converts to HoodieRecord object and then stops at obtaining a spread of input records to target partition paths
- Job 2 : Load the set of file names which we need check against
- Job 3 & 4 : Actual lookup after smart sizing of spark join parallelism, by joining RDDs in 1 & 2 above
- Job 5 : Have a tagged RDD of recordKeys with locations
Performing the actual writing of data
- Job 6 : Lazy join of incoming records against recordKey, location to provide a final set of HoodieRecord which now contain the information about which file/partitionpath they are found at (or null if insert). Then also profile the workload again to determine sizing of files
- Job 7 : Actual writing of data (update + insert + insert turned to updates to maintain file size)
Depending on the exception source (Hudi/Spark), the above knowledge of the DAG can be used to pinpoint the actual issue. The most often encountered failures result from YARN/DFS temporary failures. In the future, a more sophisticated debug/management UI would be added to the project, that can help automate some of this debugging.
Common Issues
This section lists down all the common issues that users have faced while using Hudi. Contributions are always welcome to improve this section.
Writing Data
Caused by: org.apache.parquet.io.InvalidRecordException: Parquet/Avro schema mismatch: Avro field 'col1' not found
It is recommended that schema should evolve in backwards compatible way while using Hudi. Please refer here for more information on avro schema resolution - https://avro.apache.org/docs/1.8.2/spec.html. This error generally occurs when the schema has evolved in backwards incompatible way by deleting some column 'col1' and we are trying to update some record in parquet file which has alredy been written with previous schema (which had 'col1'). In such cases, parquet tries to find all the present fields in the incoming record and when it finds 'col1' is not present, the mentioned exception is thrown.
The fix for this is to try and create uber schema using all the schema versions evolved so far for the concerned event and use this uber schema as the target schema. One of the good approaches can be fetching schema from hive metastore and merging it with the current schema.
Sample stacktrace where a field named "toBeDeletedStr" was omitted from new batch of updates : https://gist.github.com/nsivabalan/cafc53fc9a8681923e4e2fa4eb2133fe
Caused by: java.lang.UnsupportedOperationException: org.apache.parquet.avro.AvroConverters$FieldIntegerConverter
This error will again occur due to schema evolutions in non-backwards compatible way. Basically there is some incoming update U for a record R which is already written to your Hudi dataset in the concerned parquet file. R contains field F which is having certain data type, let us say long. U has the same field F with updated data type of int type. Such incompatible data type conversions are not supported by Parquet FS.
For such errors, please try to ensure only valid data type conversions are happening in your primary data source from where you are trying to ingest.
Sample stacktrace when trying to evolve a field from Long type to Integer type with Hudi : https://gist.github.com/nsivabalan/0d81cd60a3e7a0501e6a0cb50bfaacea
org.apache.hudi.exception.SchemaCompatabilityException: Unable to validate the rewritten record <record> against schema <schema> at org.apache.hudi.common.util.HoodieAvroUtils.rewrite(HoodieAvroUtils.java:215)
This can possibly occur if your schema has some non-nullable field whose value is not present or is null. It is recommended to evolve schema in backwards compatible ways. In essence, this means either have every newly added field as nullable or define default values for every new field. In case if you are relying on default value for your field, as of Hudi version 0.5.1, this is not handled.
hudi consumes too much space in a temp folder while upsert
When upsert large input data, hudi will spills part of input data to disk when reach the max memory for merge. if there is enough memory, please increase spark executor's memory and "hoodie.memory.merge.fraction" option, for example
option("hoodie.memory.merge.fraction", "0.8")
Ingestion
Caused by: java.io.EOFException: Received -1 when reading from channel, socket has likely been closed. at kafka.utils.Utils$.read(Utils.scala:381) at kafka.network.BoundedByteBufferReceive.readFrom(BoundedByteBufferReceive.scala:54)
This might happen if you are ingesting from Kafka source, your cluster is ssl enabled by default and you are using some version of Hudi older than 0.5.1. Previous versions of Hudi were using spark-streaming-kafka-0-8 library. With the release of 0.5.1 version of Hudi, spark was upgraded to 2.4.4 and spark-streaming-kafka library was upgraded to spark-streaming-kafka-0-10. SSL support was introduced from spark-streaming-kafka-0-10. Please see here for reference.
The workaround can be either use Kafka cluster which is not ssl enabled, else upgrade Hudi version to at least 0.5.1 or spark-streaming-kafka library to spark-streaming-kafka-0-10.
Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
Caused by: java.lang.IllegalArgumentException: Could not find a 'KafkaClient' entry in the JAAS configuration. System property 'java.security.auth.login.config' is not set
This might happen when you are trying to ingest from ssl enabled kafka source and your setup is not able to read jars.conf file and its properties. To fix this, you need to pass the required property as part of your spark-submit command something like
--files jaas.conf,failed_tables.json --conf 'spark.driver.extraJavaOptions=-Djava.security.auth.login.config=jaas.conf' --conf 'spark.executor.extraJavaOptions=-Djava.security.auth.login.config=jaas.conf'
com.uber.hoodie.exception.HoodieException: created_at(Part -created_at) field not found in record. Acceptable fields were :[col1, col2, col3, id, name, dob, created_at, updated_at]
Happens generally when field marked as recordKey or partitionKey is not present in some incoming record. Please cross verify your incoming record once.
If it is possible to use a nullable field that contains null records as a primary key when creating hudi table
No, will throw HoodieKeyException
Caused by: org.apache.hudi.exception.HoodieKeyException: recordKey value: "null" for field: "name" cannot be null or empty.
at org.apache.hudi.keygen.SimpleKeyGenerator.getKey(SimpleKeyGenerator.java:58)
at org.apache.hudi.HoodieSparkSqlWriter$$anonfun$1.apply(HoodieSparkSqlWriter.scala:104)
at org.apache.hudi.HoodieSparkSqlWriter$$anonfun$1.apply(HoodieSparkSqlWriter.scala:100)
IOException: Write end dead or CIRCULAR REFERENCE while writing to GCS
If you encounter below stacktrace, please set the spark config as suggested below.
--conf 'spark.hadoop.fs.gs.outputstream.pipe.type=NIO_CHANNEL_PIPE'
at org.apache.hudi.io.storage.HoodieAvroParquetWriter.close(HoodieAvroParquetWriter.java:84)
Suppressed: java.io.IOException: Upload failed for 'gs://bucket/b0ee4274-5193-4a26-bcff-d60654fd7b24-0_0-42-671_20230228055305900.parquet'
at com.google.cloud.hadoop.repackaged.gcs.com.google.cloud.hadoop.util.BaseAbstractGoogleAsyncWriteChannel.waitForCompletionAndThrowIfUploadFailed(BaseAbstractGoogleAsyncWriteChannel.java:260)
at com.google.cloud.hadoop.repackaged.gcs.com.google.cloud.hadoop.util.BaseAbstractGoogleAsyncWriteChannel.write(BaseAbstractGoogleAsyncWriteChannel.java:121)
at java.base/java.nio.channels.Channels.writeFullyImpl(Channels.java:74)
at java.base/java.nio.channels.Channels.writeFully(Channels.java:97)
at java.base/java.nio.channels.Channels$1.write(Channels.java:172)
at java.base/java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:81)
at java.base/java.io.BufferedOutputStream.flush(BufferedOutputStream.java:142)
at java.base/java.io.FilterOutputStream.close(FilterOutputStream.java:182)
... 44 more
Caused by: java.io.IOException: Write end dead
at java.base/java.io.PipedInputStream.read(PipedInputStream.java:310)
at java.base/java.io.PipedInputStream.read(PipedInputStream.java:377)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.util.ByteStreams.read(ByteStreams.java:172)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.media.MediaHttpUploader.buildContentChunk(MediaHttpUploader.java:610)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.media.MediaHttpUploader.resumableUpload(MediaHttpUploader.java:380)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.media.MediaHttpUploader.upload(MediaHttpUploader.java:308)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.services.AbstractGoogleClientRequest.executeUnparsed(AbstractGoogleClientRequest.java:539)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.services.AbstractGoogleClientRequest.executeUnparsed(AbstractGoogleClientRequest.java:466)
at com.google.cloud.hadoop.repackaged.gcs.com.google.api.client.googleapis.services.AbstractGoogleClientRequest.execute(AbstractGoogleClientRequest.java:576)
at com.google.cloud.hadoop.repackaged.gcs.com.google.cloud.hadoop.util.AbstractGoogleAsyncWriteChannel$UploadOperation.call(AbstractGoogleAsyncWriteChannel.java:85)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
... 3 more
Caused by: [CIRCULAR REFERENCE: java.io.IOException: Write end dead]
We have an active patch(https://github.com/apache/hudi/pull/7245) on fixing the issue. Until we land this, you can use above config to bypass the issue.
Hive Sync
Caused by: java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Unable to alter table. The following columns have types incompatible with the existing columns in their respective positions : __col1,__col2
This will usually happen when you are trying to add a new column to existing hive table using our HiveSyncTool.java class. Databases usually will not allow to modify a column datatype from a higher order to lower order or cases where the datatypes may clash with the data that is already stored/will be stored in the table. To fix the same, try setting the following property -
set hive.metastore.disallow.incompatible.col.type.changes=false;
com.uber.hoodie.hive.HoodieHiveSyncException: Could not convert field Type from <type1> to <type2> for field col1
This occurs because HiveSyncTool currently supports only few compatible data type conversions. Doing any other incompatible change will throw this exception. Please check the data type evolution for the concerned field and verify if it indeed can be considered as a valid data type conversion as per Hudi code base.
Caused by: org.apache.hadoop.hive.ql.parse.SemanticException: Database does not exist: test_db
This generally occurs if you are trying to do Hive sync for your Hudi dataset and the configured hive_sync database does not exist. Please create the corresponding database on your Hive cluster and try again.
Caused by: org.apache.thrift.TApplicationException: Invalid method name: 'get_table_req'
This issue is caused by hive version conflicts, hudi built with hive-2.3.x version, so if still want hudi work with older hive version
Steps: (build with hive-2.1.0)
1. git clone git@github.com:apache/incubator-hudi.git
2. rm hudi-hadoop-mr/src/main/java/org/apache/hudi/hadoop/hive/HoodieCombineHiveInputFormat.java
3. mvn clean package -DskipTests -DskipITs -Dhive.version=2.1.0
Caused by : java.lang.UnsupportedOperationException: Table rename is not supported
This issue could occur when syncing to hive. Possible reason is that, hive does not play well if your table name has upper and lower case letter. Try to have all lower case letters for your table name and it should likely get fixed. Related issue: https://github.com/apache/hudi/issues/2409
Running from IDE
"java.lang.IllegalArgumentException: Unsupported class file major version 56"
Please use java 8, and not java 11