Using Kafka Connect
Kafka Connect is a popularly used framework for integrating and moving streaming data between various systems. Hudi provides a sink for Kafka Connect, that can ingest/stream records from Apache Kafka to Hudi Tables. To do so, while providing the same transactional features the sink implements transaction co-ordination across the tasks and workers in the Kafka Connect framework.
See readme for a full demo, build instructions and configurations.
Design
At a high level, the sink treats the connect task/worker owning partition 0 of the source topic as the transaction coordinator. The transaction coordinator implements a safe two-phase commit protocol that periodically commits data into the table. Transaction co-ordination between the coordinator and workers reading messages from source topic partitions and writing to Hudi file groups happens via a special kafka control topic, that all processes are listening to.
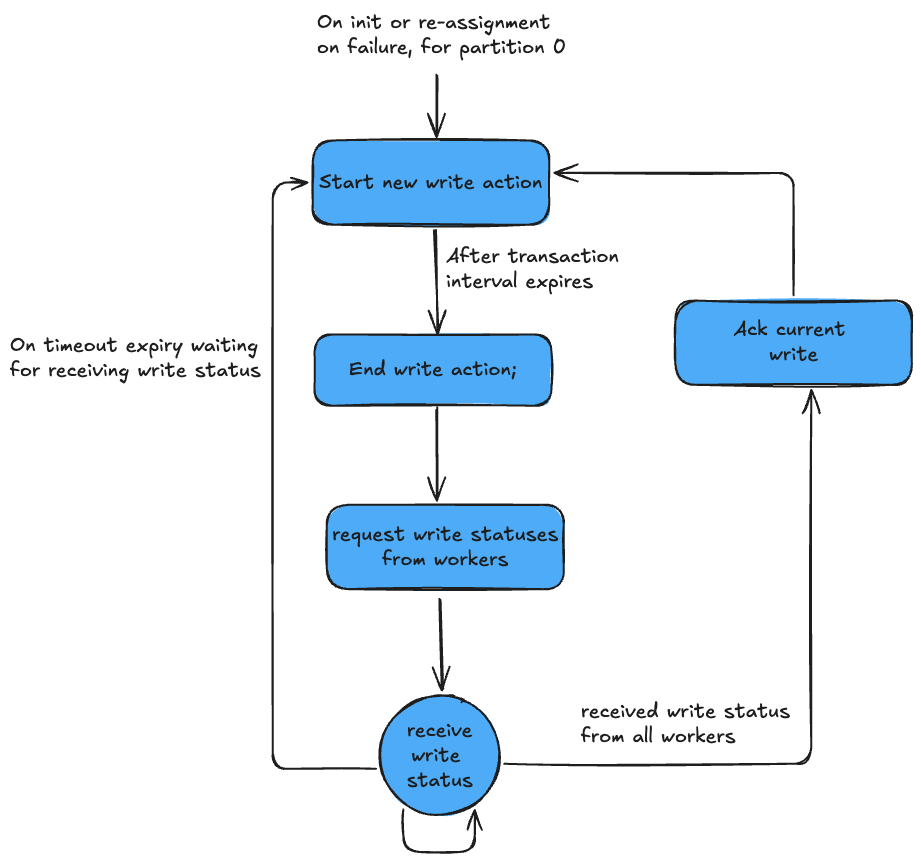
Figure: Transaction Coordinator State Machine
This distributed coordination helps the sink achieve high throughput, low-latency while still limiting the number of write actions on the timeline to just 1 every commit interval. This helps scale table metadata even in the face large volume of writes, compared to approaches where each worker commits a separate action independently leading to 10s-100s of commits per interval.
The Hudi Kafka Connect sink uses Merge-On-Read by default to reduce memory pressure of writing columnar/base files (typical scaling/operational problem with the
Kafka Connect parquet sink) and inserts/appends the kafka records directly to the log file(s). Asynchronously, compaction service can be executed to merge the log files
into base file (Parquet format). Alternatively, users have the option to reconfigure the table type to COPY_ON_WRITE in config-sink.json if desired.
Configs
To use the Hudi sink, use connector.class=org.apache.hudi.connect.HudiSinkConnector in Kafka Connect. Below lists additional configurations for the sink.
| Config Name | Default | Description |
|---|---|---|
| target.base.path | Required | base path of the Hudi table written. |
| target.table.name | Required | name of the table |
| hoodie.kafka.control.topic | hudi-control-topic (optional) | topic used for transaction co-ordination |
| hoodie.kafka.commit.interval.secs | 60 (optional) | The frequency at which the Sink will commit data into the table |
See RFC for more details.
Current Limitations
-
Only append-only or insert operations are supported at this time.
-
Limited support for metadata table (file listings) with no support for advanced indexing during write operations.