Write Operations
It may be helpful to understand the different write operations supported by Hudi and how best to leverage them. These operations can be chosen/changed across writes issued against the table. Each write operation maps to an action type on the timeline.
At its core, Hudi provides a high-performance storage engine that efficiently implements these operations, on top of the timeline and the storage format. Write operations can be classified into two types, for ease of understanding.
-
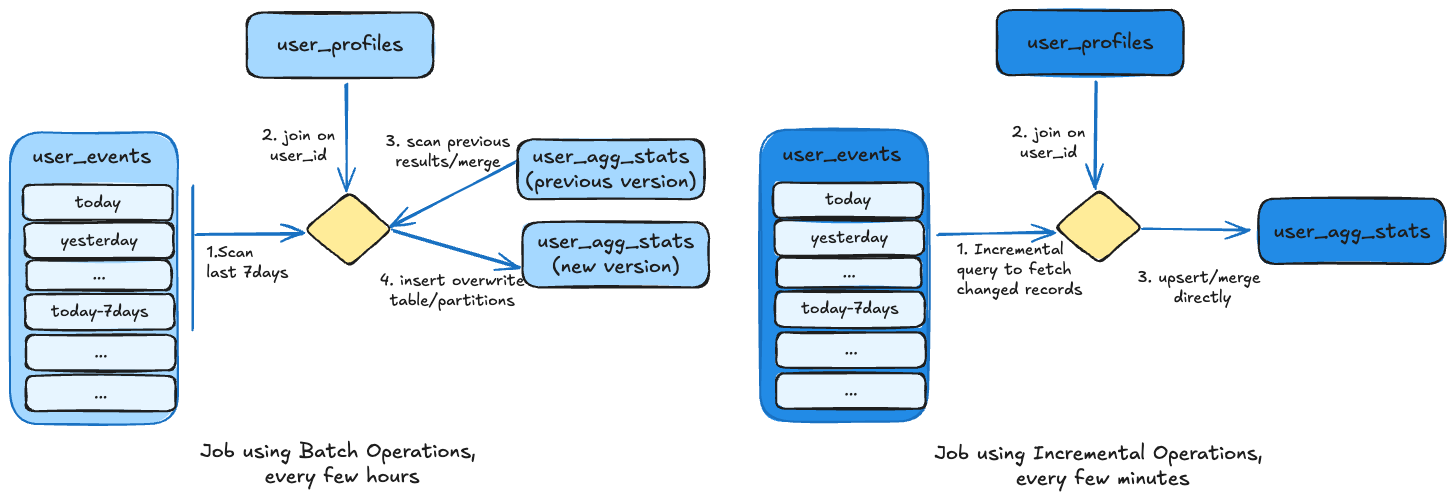
Batch/Bulk operations: Without functionality provided by Hudi, the most common way for writing data relies on overwriting entire tables and/or partitions entirely every few hours. For e.g. a job computing aggregates for the given week, will scan the entire data periodically and recompute the results from scratch and publish output by an
insert_overwriteoperation. Hudi supports all such bulk or typical "batch processing" write operations, while providing atomicity and other storage features discussed here. -
Incremental operations: However, Hudi is purpose built to change this processing model into a more incremental approach, as illustrated below. To do so, the storage engine implements incremental write operations that excel at applying incremental changes to a table. For e.g. the same processing can be now performed by just obtaining changed records from upstream system or a Hudi incremental query, and then directly updating the aggregates on the target table only for specific records that changed.
Operation Types
UPSERT
Type: Incremental, Action: COMMIT (CoW), DELTA_COMMIT (MoR)
This is the default operation where the input records are first tagged as inserts or updates by looking up the index. The records are ultimately written after heuristics are run to determine how best to pack them on storage to optimize for things like file sizing. This operation is recommended for use-cases like database change capture where the input almost certainly contains updates. The target table will never show duplicates.
INSERT
Type: Incremental, Action: COMMIT (CoW), DELTA_COMMIT (MoR)
This operation is very similar to upsert in terms of heuristics/file sizing but completely skips the index lookup step. Thus, it can be a lot faster than upserts for use-cases like log de-duplication (in conjunction with options to filter duplicates mentioned below) by skipping the index tagging step. This is also suitable for use-cases where the table can tolerate duplicates, but just need the transactional writes/incremental query/storage management capabilities of Hudi.
BULK_INSERT
Type: Batch, Action: COMMIT (CoW), DELTA_COMMIT (MoR)
Both upsert and insert operations keep input records in memory to speed up storage heuristics computations faster (among other things) and thus can be cumbersome for initial loading/bootstrapping large amount of data at first. Bulk insert provides the same semantics as insert, while implementing a sort-based data writing algorithm, which can scale very well for several hundred TBs of initial load. However, this just does a best-effort job at sizing files vs guaranteeing file sizes like inserts/upserts do.
DELETE
Type: Incremental, Action: COMMIT (CoW), DELTA_COMMIT (MoR)
Hudi supports implementing two types of deletes on data stored in Hudi tables, by enabling the user to specify a different record payload implementation.
- Soft Deletes : Retain the record key and just null out the values for all the other fields. This can be achieved by ensuring the appropriate fields are nullable in the table schema and simply upserting the table after setting these fields to null.
- Hard Deletes : This method entails completely eradicating all evidence of a record from the table, including any duplicates. There are three distinct approaches to accomplish this:
- Using DataSource, set
"hoodie.datasource.write.operation"to"delete". This will remove all the records in the DataSet being submitted. - Using DataSource, set
PAYLOAD_CLASS_OPT_KEYto"org.apache.hudi.EmptyHoodieRecordPayload". This will remove all the records in the DataSet being submitted. - Using DataSource or Hudi Streamer, add a column named
_hoodie_is_deletedto DataSet. The value of this column must be set totruefor all the records to be deleted and eitherfalseor left null for any records which are to be upserted.
- Using DataSource, set
BOOTSTRAP
Hudi supports migrating your existing large tables into a Hudi table using the bootstrap operation. There are a couple of ways to approach this. Please refer to
bootstrapping page for more details.
INSERT_OVERWRITE
Type: Batch, Action: REPLACE_COMMIT (CoW + MoR)
This operation is used to rewrite the all the partitions that are present in the input. This operation can be faster
than upsert for batch ETL jobs, that are recomputing entire target partitions at once (as opposed to incrementally
updating the target tables). This is because, we are able to bypass indexing, precombining and other repartitioning
steps in the upsert write path completely. This comes in handy if you are doing any backfill or any such type of use-cases.
INSERT_OVERWRITE_TABLE
Type: Batch, Action: REPLACE_COMMIT (CoW + MoR)
This operation can be used to overwrite the entire table for whatever reason. The Hudi cleaner will eventually clean up the previous table snapshot's file groups asynchronously based on the configured cleaning policy. This operation is much faster than issuing explicit deletes.
DELETE_PARTITION
Type: Batch, Action: REPLACE_COMMIT (CoW + MoR)
In addition to deleting individual records, Hudi supports deleting entire partitions in bulk using this operation.
Deletion of specific partitions can be done using the config
hoodie.datasource.write.partitions.to.delete.
Configs
Here are the basic configs relevant to the write operations types mentioned above. Please refer to Write Options for more Spark based configs and Flink options for Flink based configs.
Spark based configs:
| Config Name | Default | Description |
|---|---|---|
| hoodie.datasource.write.operation | upsert (Optional) | Whether to do upsert, insert or bulk_insert for the write operation. Use bulk_insert to load new data into a table, and there on use upsert/insert. bulk insert uses a disk based write path to scale to load large inputs without need to cache it.Config Param: OPERATION |
| hoodie.datasource.write.precombine.field | ts (Optional) | Field used in preCombining before actual write. When two records have the same key value, we will pick the one with the largest value for the precombine field, determined by Object.compareTo(..)Config Param: PRECOMBINE_FIELD |
| hoodie.combine.before.insert | false (Optional) | When inserted records share same key, controls whether they should be first combined (i.e de-duplicated) before writing to storage.Config Param: COMBINE_BEFORE_INSERT |
| hoodie.datasource.write.insert.drop.duplicates | false (Optional) | If set to true, records from the incoming dataframe will not overwrite existing records with the same key during the write operation. This config is deprecated as of 0.14.0. Please use hoodie.datasource.insert.dup.policy instead.Config Param: INSERT_DROP_DUPS |
| hoodie.bulkinsert.sort.mode | NONE (Optional) | org.apache.hudi.execution.bulkinsert.BulkInsertSortMode: Modes for sorting records during bulk insert.
Config Param: BULK_INSERT_SORT_MODE |
| hoodie.bootstrap.base.path | N/A (Required) | Applicable only when operation type is bootstrap. Base path of the dataset that needs to be bootstrapped as a Hudi tableConfig Param: BASE_PATHSince Version: 0.6.0 |
| hoodie.bootstrap.mode.selector | org.apache.hudi.client.bootstrap.selector.MetadataOnlyBootstrapModeSelector (Optional) | Selects the mode in which each file/partition in the bootstrapped dataset gets bootstrapped Possible values:
Config Param: MODE_SELECTOR_CLASS_NAMESince Version: 0.6.0 |
| hoodie.datasource.write.partitions.to.delete | N/A (Required) | Applicable only when operation type is delete_partition. Comma separated list of partitions to delete. Allows use of wildcard *Config Param: PARTITIONS_TO_DELETE |
Flink based configs:
| Config Name | Default | Description |
|---|---|---|
| write.operation | upsert (Optional) | The write operation, that this write should doConfig Param: OPERATION |
| precombine.field | ts (Optional) | Field used in preCombining before actual write. When two records have the same key value, we will pick the one with the largest value for the precombine field, determined by Object.compareTo(..)Config Param: PRECOMBINE_FIELD |
| write.precombine | false (Optional) | Flag to indicate whether to drop duplicates before insert/upsert. By default these cases will accept duplicates, to gain extra performance: 1) insert operation; 2) upsert for MOR table, the MOR table deduplicate on readingConfig Param: PRE_COMBINE |
| write.bulk_insert.sort_input | true (Optional) | Whether to sort the inputs by specific fields for bulk insert tasks, default trueConfig Param: WRITE_BULK_INSERT_SORT_INPUT |
| write.bulk_insert.sort_input.by_record_key | false (Optional) | Whether to sort the inputs by record keys for bulk insert tasks, default falseConfig Param: WRITE_BULK_INSERT_SORT_INPUT_BY_RECORD_KEY |
Write path
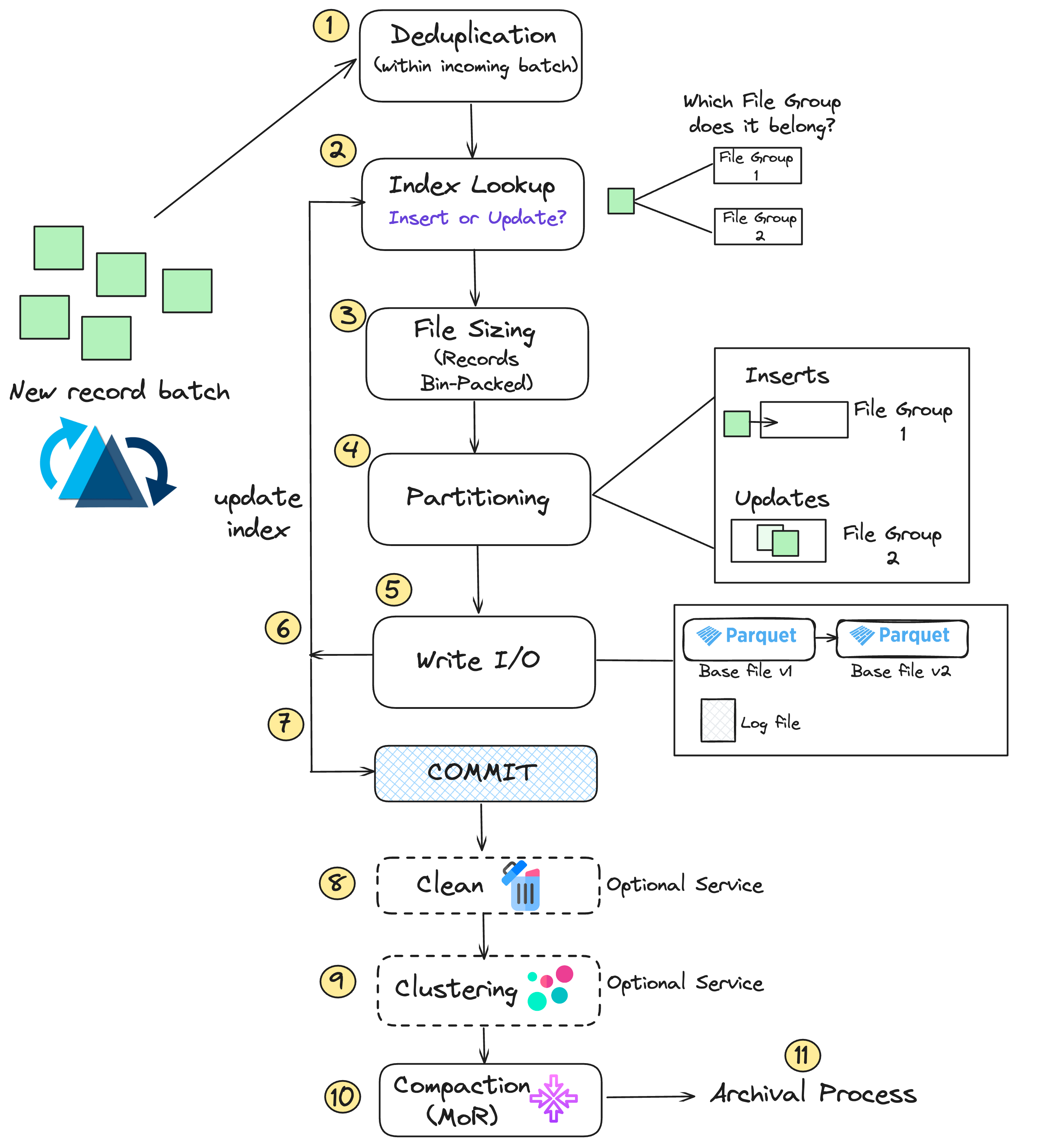
The following is an inside look on the Hudi write path and the sequence of events that occur during a write.
- Deduping : First your input records may have duplicate keys within the same batch and duplicates need to be combined or reduced by key.
- Index Lookup : Next, an index lookup is performed to try and match the input records to identify which file groups they belong to.
- File Sizing: Then, based on the average size of previous commits, Hudi will make a plan to add enough records to a small file to get it close to the configured maximum limit.
- Partitioning: We now arrive at partitioning where we decide what file groups certain updates and inserts will be placed in or if new file groups will be created
- Write I/O :Now we actually do the write operations which is either creating a new base file, appending to the log file, or versioning an existing base file.
- Update Index: Now that the write is performed, we will go back and update the index.
- Commit: Finally we commit all of these changes atomically. (Post-commit callback can be configured.)
- Clean (if needed): Following the commit, cleaning is invoked if needed.
- Compaction: If you are using MOR tables, compaction will either run inline, or be scheduled asynchronously
- Archive : Lastly, we perform an archival step which moves old timeline items to an archive folder.
Here is a diagramatic representation of the flow.