Record Payload
Background
One of the core features of Hudi is the ability to incrementally upsert data, deduplicate and merge records on the fly. Additionally, users can implement their custom logic to merge the input records with the record on storage. Record payload is an abstract representation of a Hudi record that allows the aforementioned capability. As we shall see below, Hudi provides out-of-box support for different payloads for different use cases. But, first let us understand how record payload is used in the Hudi upsert path.
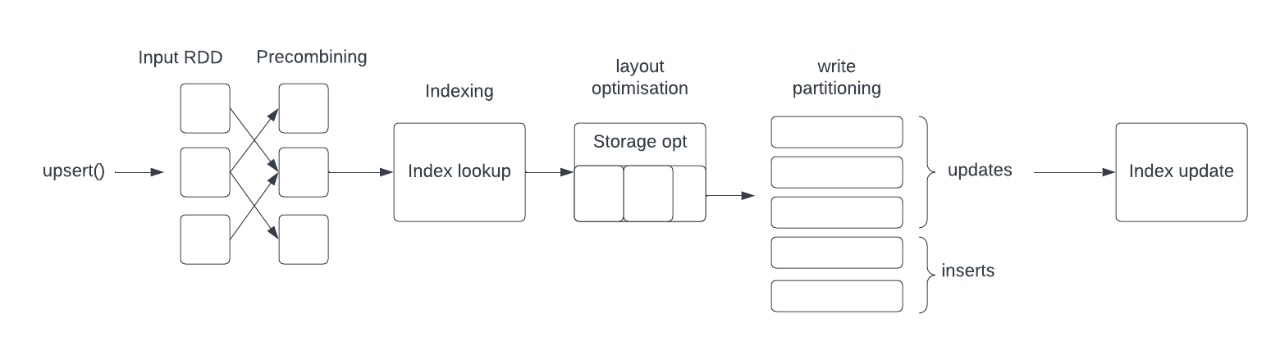
Figure above shows the main stages that records go through while being written to the Hudi table. In the precombining stage, Hudi performs any deduplication based on the payload implementation and precombine key configured by the user. Further, on index lookup, Hudi identifies which records are being updated and the record payload implementation tells Hudi how to merge the incoming record with the existing record on storage.
Configs
Payload class can be specified using the below configs. For more advanced configs refer here
Spark based configs;
| Config Name | Default | Description |
|---|---|---|
| hoodie.datasource.write.payload.class | org.apache.hudi.common.model.OverwriteWithLatestAvroPayload (Optional) | Payload class used. Override this, if you like to roll your own merge logic, when upserting/inserting. This will render any value set for PRECOMBINE_FIELD_OPT_VAL in-effectiveConfig Param: WRITE_PAYLOAD_CLASS_NAME |
Flink based configs:
| Config Name | Default | Description |
|---|---|---|
| payload.class | org.apache.hudi.common.model.EventTimeAvroPayload (Optional) | Payload class used. Override this, if you like to roll your own merge logic, when upserting/inserting. This will render any value set for the option in-effectiveConfig Param: PAYLOAD_CLASS_NAME |
Existing Payloads
OverwriteWithLatestAvroPayload
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
This is the default record payload implementation. It picks the record with the greatest value (determined by calling
.compareTo() on the value of precombine key) to break ties and simply picks the latest record while merging. This gives
latest-write-wins style semantics.
DefaultHoodieRecordPayload
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.DefaultHoodieRecordPayload
While OverwriteWithLatestAvroPayload precombines based on an ordering field and picks the latest record while merging,
DefaultHoodieRecordPayload honors the ordering field for both precombinig and merging. Let's understand the difference with an example:
Let's say the ordering field is ts and record key is id and schema is:
{
[
{"name":"id","type":"string"},
{"name":"ts","type":"long"},
{"name":"name","type":"string"},
{"name":"price","type":"string"}
]
}
Current record in storage:
id ts name price
1 2 name_2 price_2
Incoming record:
id ts name price
1 1 name_1 price_1
Result data after merging using OverwriteWithLatestAvroPayload (latest-write-wins):
id ts name price
1 1 name_1 price_1
Result data after merging using DefaultHoodieRecordPayload (always honors ordering field):
id ts name price
1 2 name_2 price_2
EventTimeAvroPayload
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.EventTimeAvroPayload
This is the default record payload for Flink based writing. Some use cases require merging records by event time and thus event time plays the role of an ordering field. This payload is particularly useful in the case of late-arriving data. For such use cases, users need to set the payload event time field configuration.
OverwriteNonDefaultsWithLatestAvroPayload
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload
This payload is quite similar to OverwriteWithLatestAvroPayload with slight difference while merging records. For
precombining, just like OverwriteWithLatestAvroPayload, it picks the latest record for a key, based on an ordering
field. While merging, it overwrites the existing record on storage only for the specified fields that don't equal
default value for that field.
PartialUpdateAvroPayload
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.PartialUpdateAvroPayload
This payload supports partial update. Typically, once the merge step resolves which record to pick, then the record on
storage is fully replaced by the resolved record. But, in some cases, the requirement is to update only certain fields
and not replace the whole record. This is called partial update. PartialUpdateAvroPayload provides out-of-box support
for such use cases. To illustrate the point, let us look at a simple example:
Let's say the ordering field is ts and record key is id and schema is:
{
[
{"name":"id","type":"string"},
{"name":"ts","type":"long"},
{"name":"name","type":"string"},
{"name":"price","type":"string"}
]
}
Current record in storage:
id ts name price
1 2 name_1 null
Incoming record:
id ts name price
1 1 null price_1
Result data after merging using PartialUpdateAvroPayload:
id ts name price
1 2 name_1 price_1
Summary
In this document, we highlighted the role of record payload to support fast incremental ETL with updates and deletes. We
also talked about some payload implementations readily provided by Hudi. There are quite a few other implementations
and developers would be interested in looking at the hierarchy of HoodieRecordPayload interface. For
example, MySqlDebeziumAvroPayload
and PostgresDebeziumAvroPayload
provides support for seamlessly applying changes captured via Debezium for MySQL and PostgresDB.
AWSDmsAvroPayload
provides support for applying changes captured via Amazon Database Migration Service onto S3.
Record payloads are tunable to suit many use cases. Please check out the configurations listed here. Moreover, if users want to implement their own custom merge logic, please check out this FAQ. In a separate document, we will talk about a new record merger API for optimized payload handling.