
199 posts tagged with "apache hudi"
View All Tags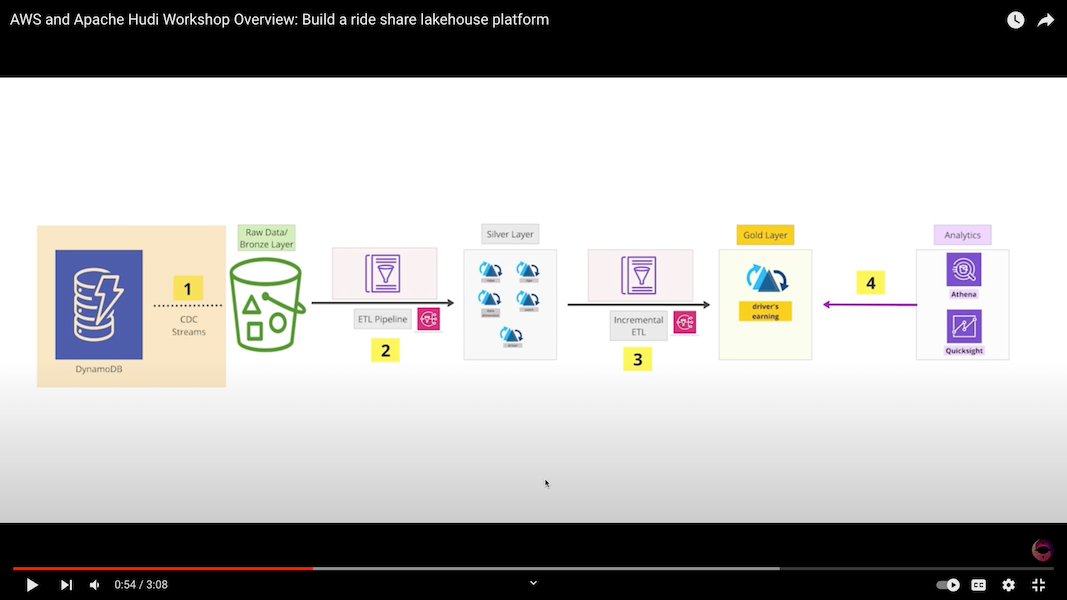
AWS and Apache Hudi Workshop Overview: Build a ride share lakehouse platform

How to Set Up AWS Glue Locally with Docker: Accessing Glue Database & Table in Your LocalEnvironment

Mastering File Sizing in Hudi: Boosting Performance and Efficiency

Hands-On Lab: Unleashing Efficiency and Flexibility with Partial Updates in Apache Hudi

Unify Your Event Data:Guide to Mapping Events to Standardized Format with Incremental ETL using Hudi

EMR Serverless Made Easy: Submitting Hive SQL Queries for Beginners with NYC Taxi Dataset

EMR Serverless for Beginners: | Ingest Data incrementally | Submit Spark Job with EMR-CLI |Data lake

Maximizing Efficiency DataLake(Hudi) Glue ETL Jobs with Templated Approach &Serverless Architecture
