Indexing
Indexing
Hudi provides efficient upserts, by mapping a given hoodie key (record key + partition path) consistently to a file id, via an indexing mechanism. This mapping between record key and file group/file id, never changes once the first version of a record has been written to a file. In short, the mapped file group contains all versions of a group of records.
For Copy-On-Write tables, this enables fast upsert/delete operations, by avoiding the need to join against the entire dataset to determine which files to rewrite. For Merge-On-Read tables, this design allows Hudi to bound the amount of records any given base file needs to be merged against. Specifically, a given base file needs to merged only against updates for records that are part of that base file. In contrast, designs without an indexing component (e.g: Apache Hive ACID), could end up having to merge all the base files against all incoming updates/delete records:
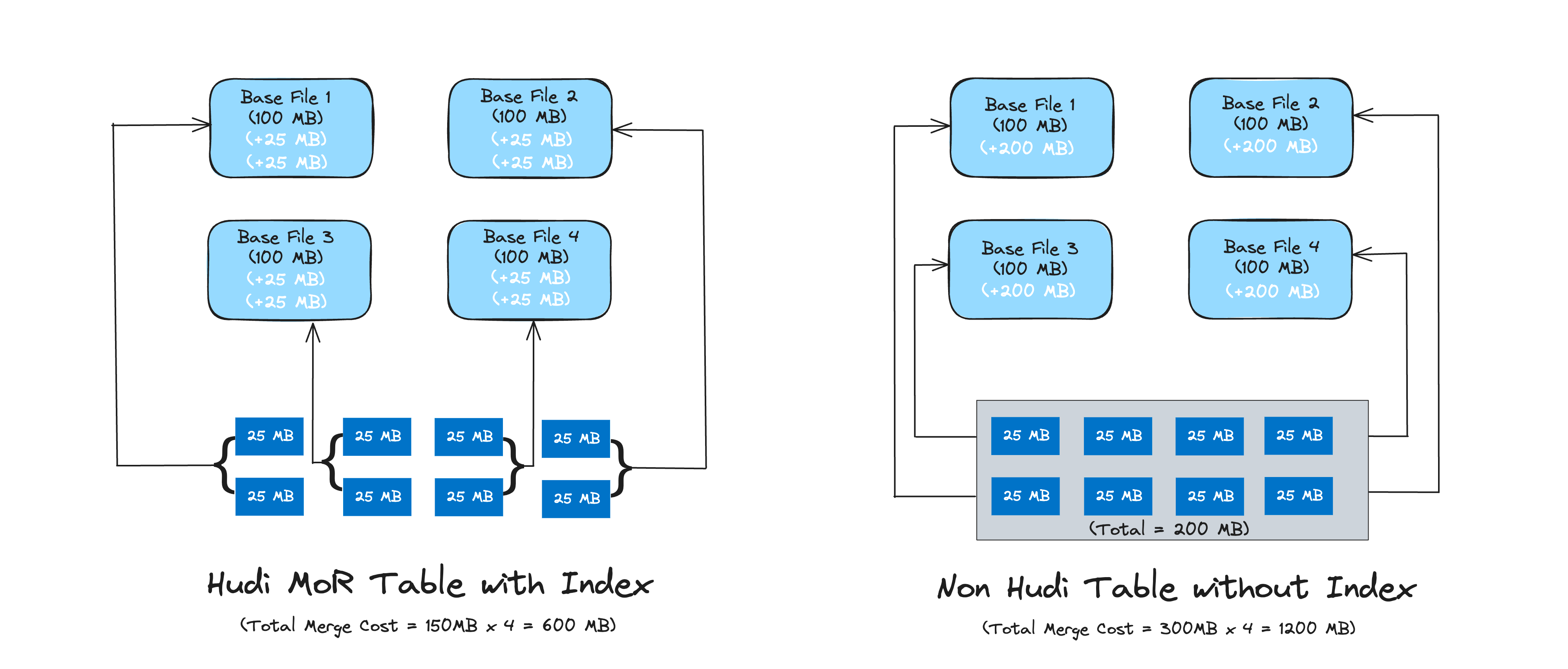
Figure: Comparison of merge cost for updates (dark blue blocks) against base files (light blue blocks)
Index Types in Hudi
Currently, Hudi supports the following index types. Default is SIMPLE on Spark engine, and INMEMORY on Flink and Java engines.
- BLOOM: Employs bloom filters built out of the record keys, optionally also pruning candidate files using record key ranges.Key uniqueness is enforced inside partitions.
- GLOBAL_BLOOM: Employs bloom filters built out of the record keys, optionally also pruning candidate files using record key ranges. Key uniqueness is enforced across all partitions in the table.
- SIMPLE (default for Spark engines): Default index type for spark engine. Performs a lean join of the incoming records against keys extracted from the table on storage. Key uniqueness is enforced inside partitions.
- GLOBAL_SIMPLE: Performs a lean join of the incoming records against keys extracted from the table on storage. Key uniqueness is enforced across all partitions in the table.
- HBASE: Manages the index mapping in an external Apache HBase table.
- INMEMORY (default for Flink and Java): Uses in-memory hashmap in Spark and Java engine and Flink in-memory state in Flink for indexing.
- BUCKET: Employs bucket hashing to locates the file group containing the records. Particularly beneficial in
large scale. Use
hoodie.index.bucket.engineto choose bucket engine type, i.e., how buckets are generated;SIMPLE(default): Uses a fixed number of buckets for file groups per partition which cannot shrink or expand. This works for both COW and MOR tables. Since the num of buckets cannot be changed and design of one-on-one mapping between buckets and file groups, this index might not suit well for highly skewed partitions.CONSISTENT_HASHING: Supports dynamic number of buckets with bucket resizing to properly size each bucket. This solves potential data skew problem where partitions with high volume of data can be dynamically resized to have multiple buckets that are reasonably sized in contrast to the fixed number of buckets per partition in SIMPLE bucket engine type. This only works with MOR tables.
- RECORD_INDEX: Index which saves the record key to location mappings in the HUDI Metadata Table. Record index is a global index, enforcing key uniqueness across all partitions in the table. Supports sharding to achieve very high scale.
- Bring your own implementation: You can extend this public API to implement custom indexing.
Writers can pick one of these options using hoodie.index.type config option. Additionally, a custom index implementation can also be employed
using hoodie.index.class and supplying a subclass of SparkHoodieIndex (for Apache Spark writers)
Global and Non-Global Indexes
Another key aspect worth understanding is the difference between global and non-global indexes. Both bloom and simple index have
global options - hoodie.index.type=GLOBAL_BLOOM and hoodie.index.type=GLOBAL_SIMPLE - respectively. Record index and
HBase index are by nature a global index.
- Global index: Global indexes enforce uniqueness of keys across all partitions of a table i.e guarantees that exactly
one record exists in the table for a given record key. Global indexes offer stronger guarantees, but the update/delete
cost can still grow with size of the table
O(size of table), since the record could belong to any partition in storage. In case of non-global index, lookup involves file groups only for the matching partitions from the incoming records and so its not impacted by the total size of the table. These global indexes(GLOBAL_SIMPLE or GLOBAL_BLOOM), might be acceptable for decent sized tables, but for large tables, a newly added index (0.14.0) called Record Level Index (RLI), can offer pretty good index lookup performance compared to other global indices(GLOBAL_SIMPLE or GLOBAL_BLOOM) or Hbase and also avoids the operational overhead of maintaining external systems. - Non Global index: On the other hand, the default index implementations enforce this constraint only within a specific partition.
As one might imagine, non global indexes depends on the writer to provide the same consistent partition path for a given record key during update/delete,
but can deliver much better performance since the index lookup operation becomes
O(number of records updated/deleted)and scales well with write volume.
Configs
Spark based configs
For Spark DataSource, Spark SQL, DeltaStreamer and Structured Streaming following are the key configs that control indexing behavior. Please refer to Advanced Configs for more details. All these, support the index types mentioned above.
| Config Name | Default | Description |
|---|---|---|
| hoodie.index.type | N/A (Required) | org.apache.hudi.index.HoodieIndex$IndexType: Determines how input records are indexed, i.e., looked up based on the key for the location in the existing table. Default is SIMPLE on Spark engine, and INMEMORY on Flink and Java engines. Possible Values:
Config Param: INDEX_TYPE |
| hoodie.index.bucket.engine | SIMPLE (Optional) | org.apache.hudi.index.HoodieIndex$BucketIndexEngineType: Determines the type of bucketing or hashing to use when hoodie.index.type is set to BUCKET. Possible Values:
Config Param: BUCKET_INDEX_ENGINE_TYPESince Version: 0.11.0 |
| hoodie.index.class | (Optional) | Full path of user-defined index class and must be a subclass of HoodieIndex class. It will take precedence over the hoodie.index.type configuration if specifiedConfig Param: INDEX_CLASS_NAME |
| hoodie.bloom.index.update.partition.path | true (Optional) | Only applies if index type is GLOBAL_BLOOM. When set to true, an update including the partition path of a record that already exists will result in inserting the incoming record into the new partition and deleting the original record in the old partition. When set to false, the original record will only be updated in the old partition, ignoring the new incoming partition if there is a mis-match between partition value for an incoming record with whats in storage.Config Param: BLOOM_INDEX_UPDATE_PARTITION_PATH_ENABLE |
| hoodie.record.index.update.partition.path | false (Optional) | Similar to Key: 'hoodie.bloom.index.update.partition.path' , Only applies if index type is RECORD_INDEX. When set to true, an update including the partition path of a record that already exists will result in inserting the incoming record into the new partition and deleting the original record in the old partition. When set to false, the original record will only be updated in the old partition, ignoring the new incoming partition if there is a mis-match between partition value for an incoming record with whats in storage. Config Param: RECORD_INDEX_UPDATE_PARTITION_PATH_ENABLE |
| hoodie.simple.index.update.partition.path | true (Optional) | Similar to Key: 'hoodie.bloom.index.update.partition.path' , Only applies if index type is GLOBAL_SIMPLE. When set to true, an update including the partition path of a record that already exists will result in inserting the incoming record into the new partition and deleting the original record in the old partition. When set to false, the original record will only be updated in the old partition, ignoring the new incoming partition if there is a mis-match between partition value for an incoming record with whats in storage. Config Param: SIMPLE_INDEX_UPDATE_PARTITION_PATH_ENABLE |
| hoodie.hbase.index.update.partition.path | false (Optional) | Only applies if index type is HBASE. When an already existing record is upserted to a new partition compared to whats in storage, this config when set, will delete old record in old partition and will insert it as new record in new partition.Config Param: UPDATE_PARTITION_PATH_ENABLE |
Flink based configs
For Flink DataStream and Flink SQL only support Bucket Index and internal Flink state store backed in memory index. Following are the basic configs that control the indexing behavior. Please refer here for advanced configs.
| Config Name | Default | Description |
|---|---|---|
| index.type | FLINK_STATE (Optional) | Index type of Flink write job, default is using state backed index. Possible values:
Config Param: INDEX_TYPE |
| hoodie.index.bucket.engine | SIMPLE (Optional) | org.apache.hudi.index.HoodieIndex$BucketIndexEngineType: Determines the type of bucketing or hashing to use when hoodie.index.type is set to BUCKET. Possible Values:
|
Indexing Strategies
Since data comes in at different volumes, velocity and has different access patterns, different indices could be used for different workload types. Let’s walk through some typical workload types and see how to leverage the right Hudi index for such use-cases. This is based on our experience and you should diligently decide if the same strategies are best for your workloads.
Workload 1: Late arriving updates to fact tables
Many companies store large volumes of transactional data in NoSQL data stores. For eg, trip tables in case of ride-sharing, buying and selling of shares, orders in an e-commerce site. These tables are usually ever growing with random updates on most recent data with long tail updates going to older data, either due to transactions settling at a later date/data corrections. In other words, most updates go into the latest partitions with few updates going to older ones.
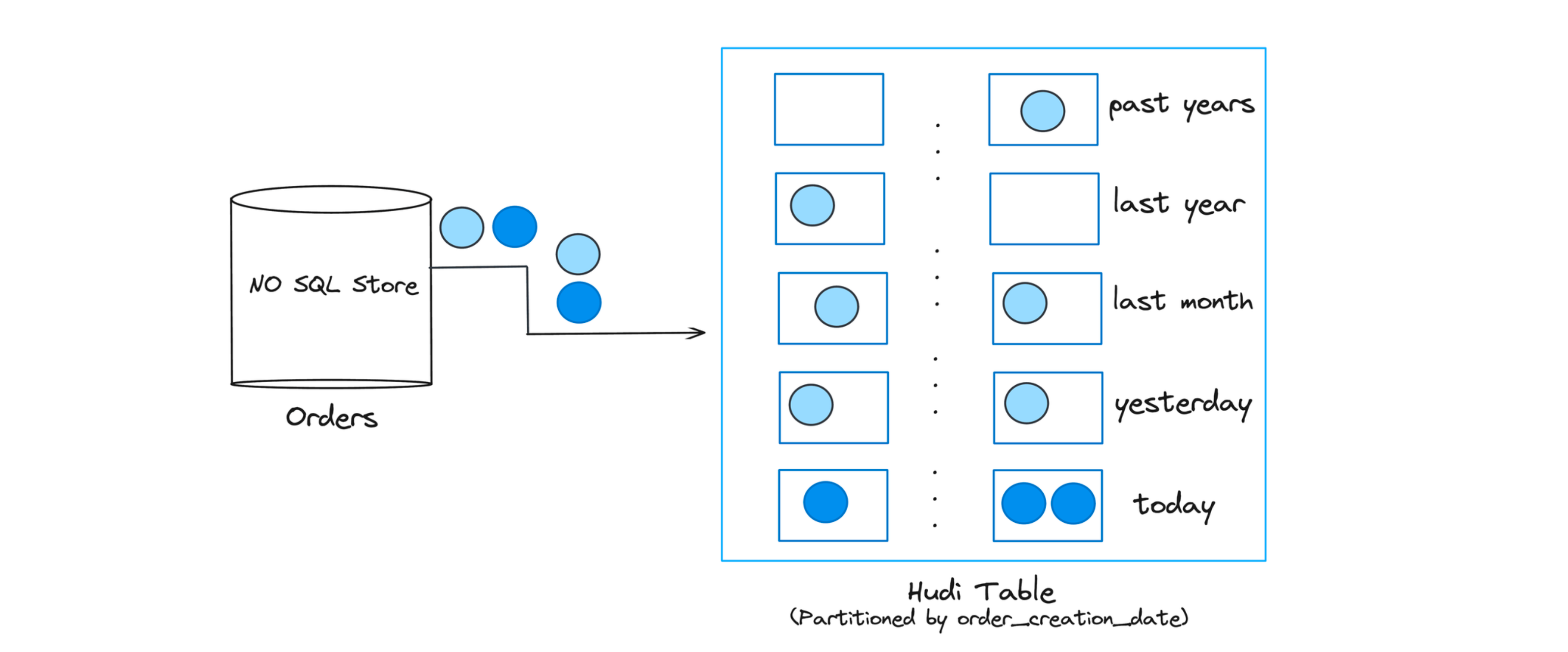
Figure: Typical update pattern for Fact tables
For such workloads, the BLOOM index performs well, since index look-up will prune a lot of data files based on a well-sized bloom filter.
Additionally, if the keys can be constructed such that they have a certain ordering, the number of files to be compared is further reduced by range pruning.
Hudi constructs an interval tree with all the file key ranges and efficiently filters out the files that don't match any key ranges in the updates/deleted records.
In order to efficiently compare incoming record keys against bloom filters i.e with minimal number of bloom filter reads and uniform distribution of work across
the executors, Hudi leverages caching of input records and employs a custom partitioner that can iron out data skews using statistics. At times, if the bloom filter
false positive ratio is high, it could increase the amount of data shuffled to perform the lookup. Hudi supports dynamic bloom filters
(enabled using hoodie.bloom.index.filter.type=DYNAMIC_V0), which adjusts its size based on the number of records stored in a given file to deliver the
configured false positive ratio.
Workload 2: De-Duplication in event tables
Event Streaming is everywhere. Events coming from Apache Kafka or similar message bus are typically 10-100x the size of fact tables and often treat "time" (event's arrival time/processing time) as a first class citizen. For eg, IoT event stream, click stream data, ad impressions etc. Inserts and updates only span the last few partitions as these are mostly append only data. Given duplicate events can be introduced anywhere in the end-end pipeline, de-duplication before storing on the data lake is a common requirement.
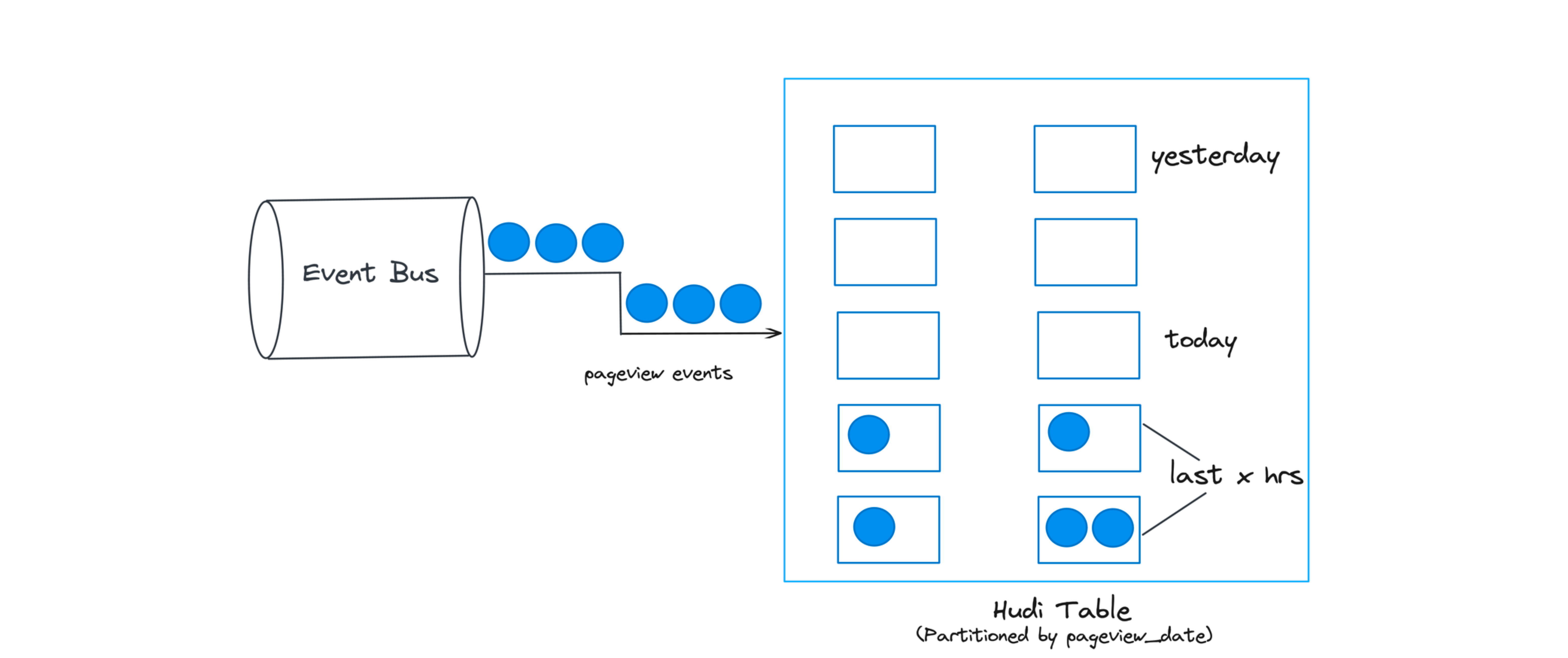
Figure showing the spread of updates for Event table.
In general, this is a very challenging problem to solve at lower cost. Although, we could even employ a key value store to perform this de-duplication with HBASE index, the index storage
costs would grow linear with number of events and thus can be prohibitively expensive. In fact, BLOOM index with range pruning is the optimal solution here. One can leverage the fact
that time is often a first class citizen and construct a key such as event_ts + event_id such that the inserted records have monotonically increasing keys. This yields great returns
by pruning large amounts of files even within the latest table partitions.
Workload 3: Random updates/deletes to a dimension table
These types of tables usually contain high dimensional data and hold reference data e.g user profile, merchant information. These are high fidelity tables where the updates are often small but also spread across a lot of partitions and data files ranging across the dataset from old to new. Often times, these tables are also un-partitioned, since there is also not a good way to partition these tables.
Figure showing the spread of updates for Dimensions table.
As discussed before, the BLOOM index may not yield benefits if a good number of files cannot be pruned out by comparing ranges/filters. In such a random write workload, updates end up touching
most files within in the table and thus bloom filters will typically indicate a true positive for all files based on some incoming update. Consequently, we would end up comparing ranges/filter, only
to finally check the incoming updates against all files. The SIMPLE Index will be a better fit as it does not do any upfront pruning based, but directly joins with interested fields from every data file.
HBASE index can be employed, if the operational overhead is acceptable and would provide much better lookup times for these tables.
When using a global index, users should also consider setting hoodie.bloom.index.update.partition.path=true or hoodie.simple.index.update.partition.path=true to deal with cases where the
partition path value could change due to an update e.g users table partitioned by home city; user relocates to a different city. These tables are also excellent candidates for the Merge-On-Read table type.